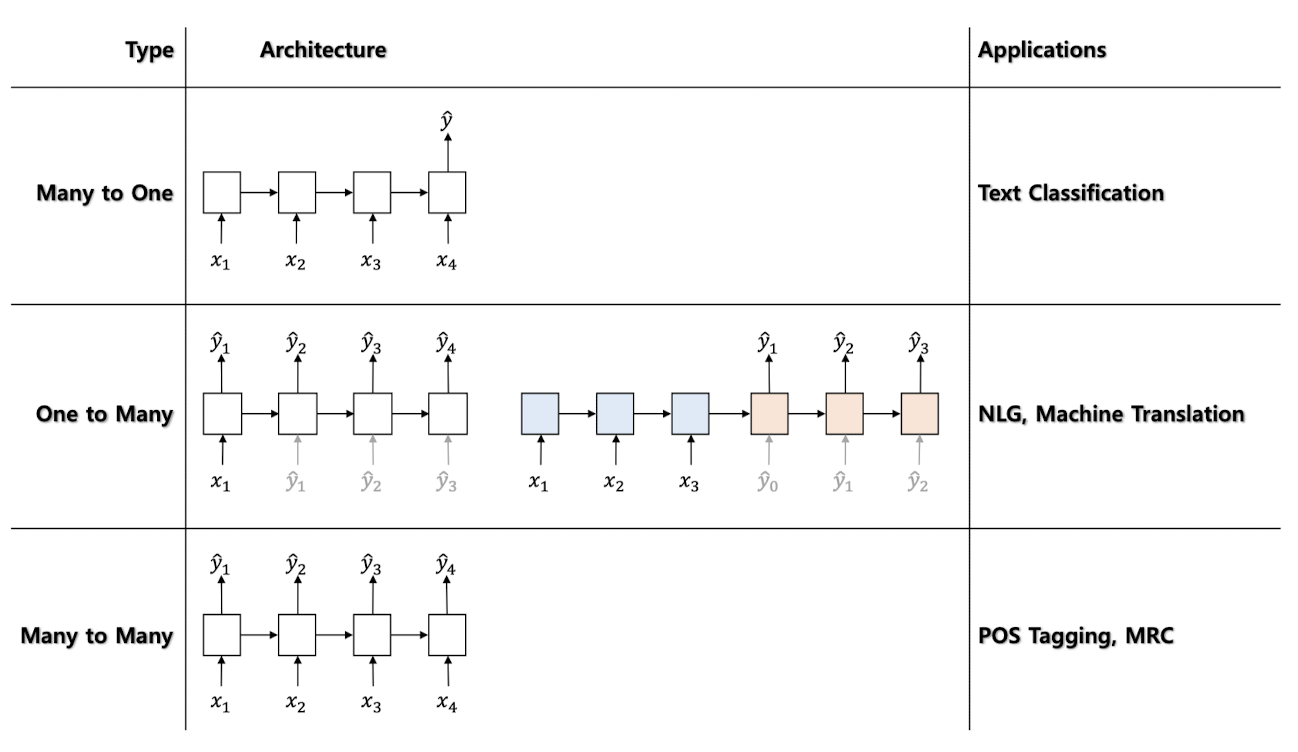
시퀀스 데이터(ex : 소리, 문자열, 주가...)를 다루기 위한, 길이가 가변적인 데이터를 다룰 수 있는 모델 (조건부확률 이용)
시퀀스 데이터는 순서를 바꾸거나 과거 정보에 손실이 발생하면 데이터의 확률분포도 바뀌게 됨
(독립동등분포(i.i.d.)가정을 잘 위배)
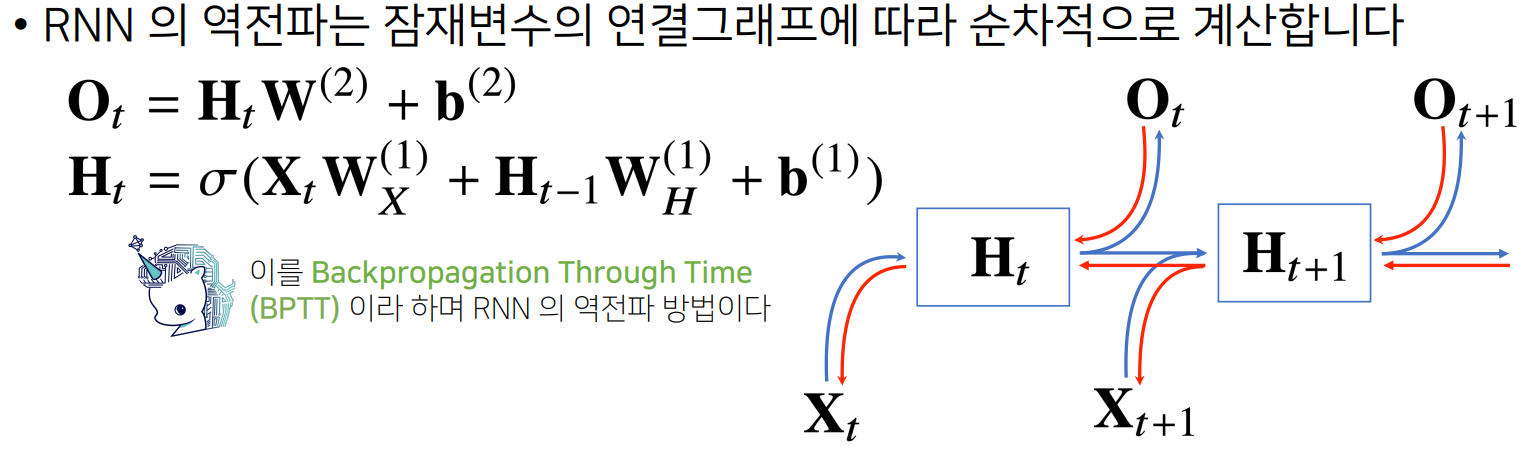
가장 기본적인 RNN 모델은 MLP와 유사한 모양이지만, MLP가 과거의 정보를 다룰 수 없다는 점과 반대로 RNN은 이전 순서의 잠재변수와 현재의 입력을 활용하여 모델링한다. (잠재변수인 Ht 를 복제해서 다음 순서의 잠재변수를 인코딩하는데 사용)
-
MLP

-
RNN
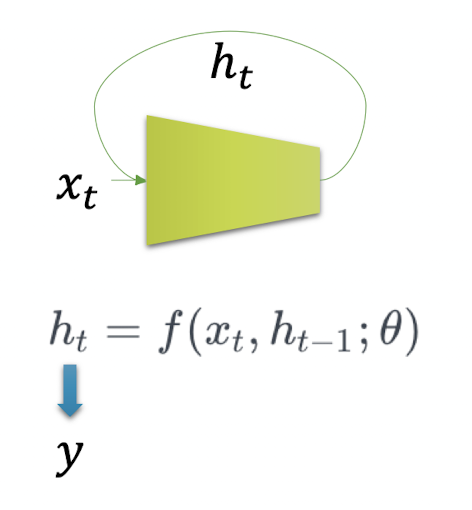
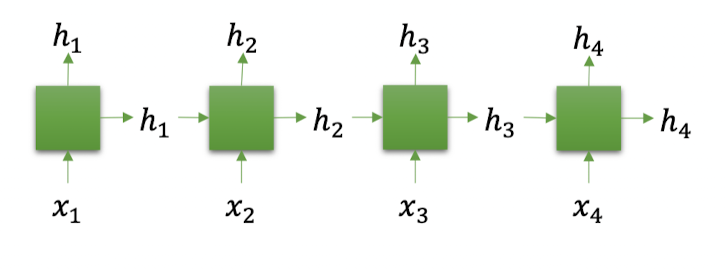
현재 time step의 입력 뿐만 아니라 지난 타입스텝의 출력 또한 입력으로 받는다.
Single layer RNN에서 hidden state는 곧 output이다.
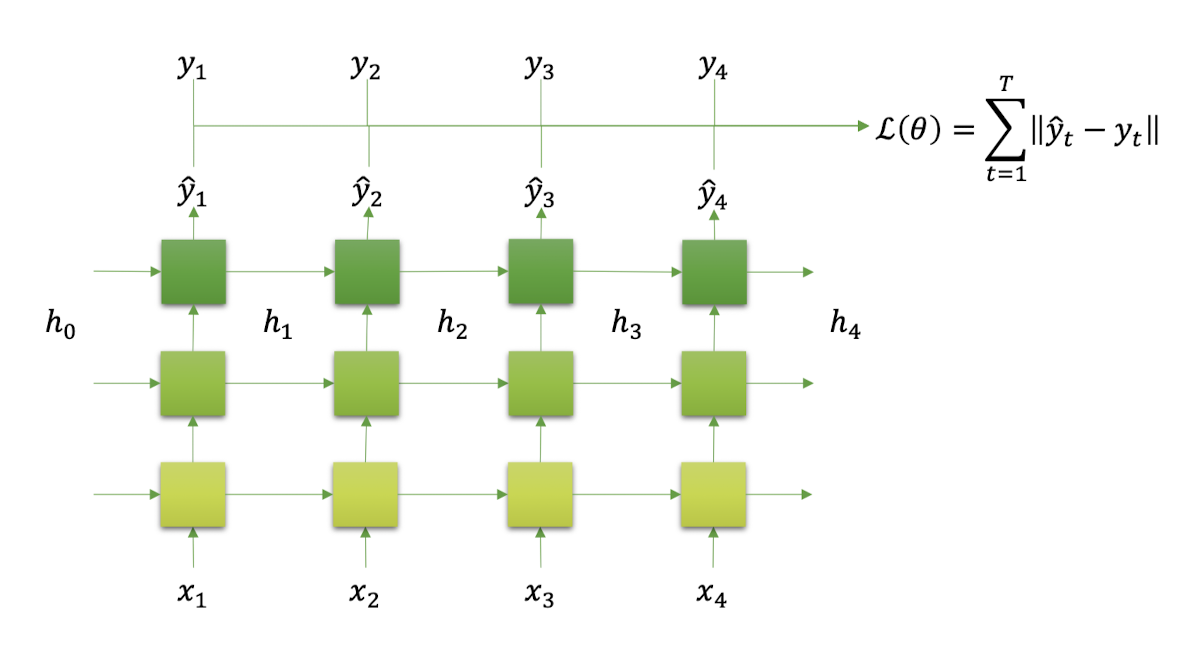
- Multi-layered RNN에서
• Output은 마지막 layer의 모든 time-step의 hidden state이다.
• Hidden state는 마지막 time-step의 모든 layer의 hidden state이다.
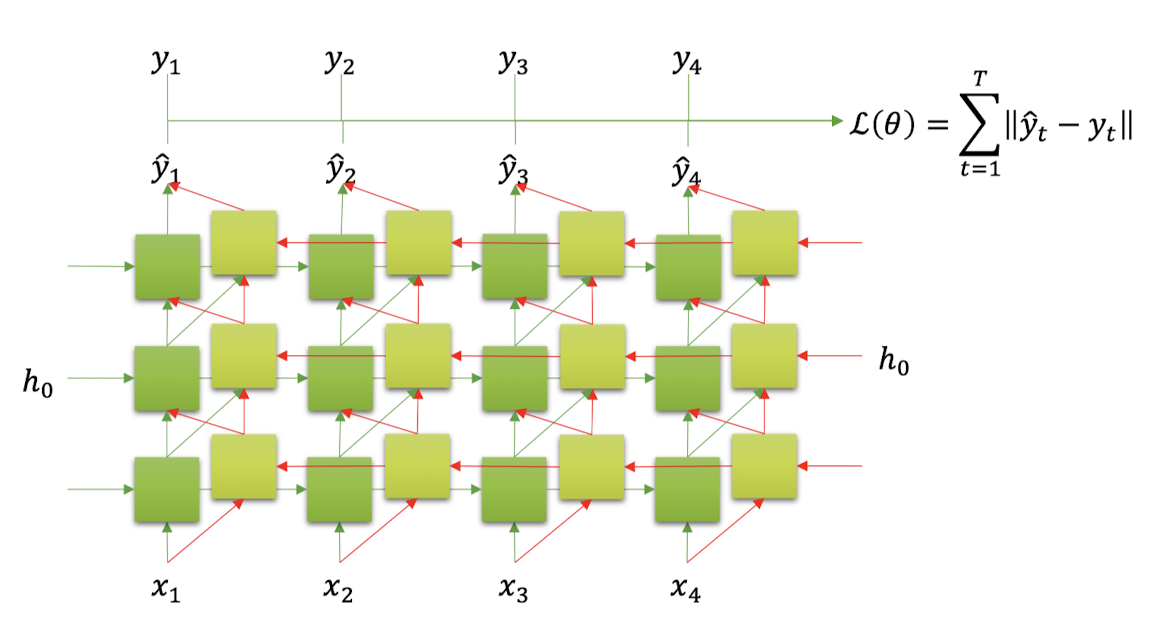
- Bi-directional RNN에서
• Output은 hidden state가 2배가 된다.
• Hidden state는 layer의 갯수가 2배가 된다.
hidden 노드가 방향을 가진 엣지로 연결되어 순환구조를 이루는 인공신경망의 한 종류
input 길이에 상관없이 동일한 파라미터를 가지고 동작하는 모델
input 길이가 길어질수록, 역전파시 그래디언트가 점차 줄어 학습능력이 떨어진다.
활용 사례
Sequential vs Time Series
- Time-stamp의 유무에 따른 차이
- 시퀀셜 데이터는 데이터의 순서 정보가 매우 중요함
• e.g. 텍스트 문장: 단어의 순서 - 추가로 시계열 데이터는 해당 데이터가 발생한 시각 정보가 매우 중요함
• e.g. 주식데이터:가격의순서및발생시점
RNN 계열 모델
Vanilla RNN
Vanilla RNN은 이전 Cell의 output 값이 현 시점의 input과 함께 연산이 되는 방법론이다. 하지만 Vanilla RNN에서는 시퀀스가 매우 길어지면 앞쪽 정보가 뒤에 있는 타임 스텝까지 충분히 전달되지 못하는 장기의존성(Long Term Dependency) 문제를 해결하지 못한다.
LSTM
LSTM(Long Short Term Memory)은 입력(input) 게이트, 망각(forget) 게이트, 출력(Output) 게이트를 활용하여 장기의존성 문제를 해결하고자 한다. 입력게이트는 새로운 정보 중 어떤 것을 저장할지 결정하는 게이트다. 또한, 망각게이트는 과거의 정보 중 어떤 부분을 버릴지 말지 결정하는 게이트이며, 출력게이트는 입력된 데이터 중 정보 어떤 정보를 출력으로 내보낼 지 결정하는 게이트다.
GRU
GRU 는 LSTM의 변형구조로 Update Gate, Reset Gate만 존재하며 Output Gate는 존재하지 않아 LSTM에 비해 파라미터 수가 더 작은 모델이다.
