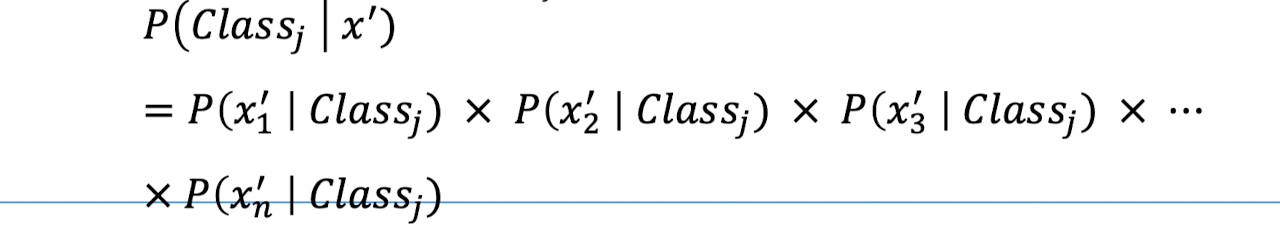
조건부 확률

사건 A가 발생했을 때, 사건 B가 발생할 확률


-> COVID-99의 발병률이 10%로 알려져있다. COVID-99에 실제로 걸렸을 때 검진될 확률은 99%, 실제로 걸리지 않았을 때 오검진될 확률이 1%라고 할 때,어떤 사람이 질병에 걸렸다고 검진결과가 나왔을때 정말로 COVID-99에 감염되었을 확률은?


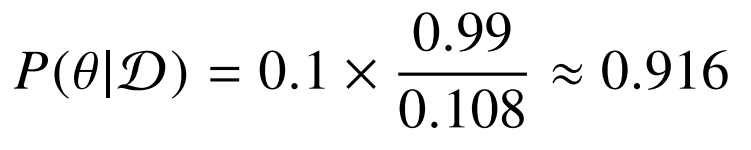
- 사전확률 : 현재 정보를 바탕으로 정한 확률
- 사후확률 : 사건 B가 사건 A로부터 발생했다는 가정하에 사건 A의 확률 업데이트
베이즈 정리를 통해 새로운 데이터가 들어왔을 때 앞서 계산한 사후확률을 사전확률로 사용하여 갱신된 사후확률을 계산할 수 있다.
조건부확률은 유용한 통계적해석을 제공하지만 인과관계(causality)를 추론할 때 함부로 사용해서는 안된다. 조건부확률만 가지고 인과관계를 추론하는 것은 불가능하다.
인과관계는 데이터 분포의 변화에 강건한 예측모형을 만들 때 필요하다.

단, 인과관계만으로 높은 예측 정확도를 담보하기는 어렵다.
인과관계를 알아내기 위해서는 중첩요인(confoundingfactor)의 효과를 제거하고 원인에 해당하는 변수만의 인과관계를 계산해야 한다.
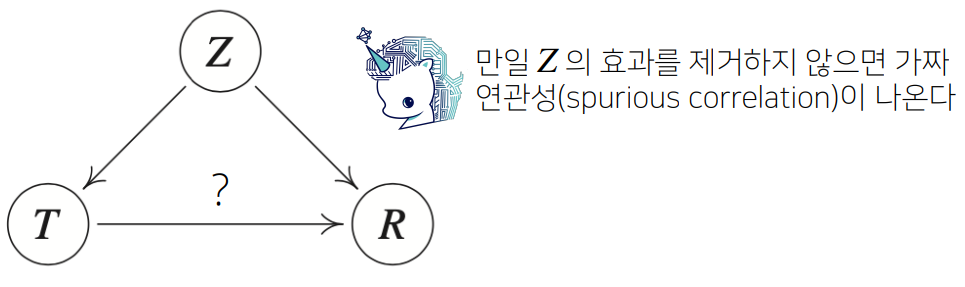
ex) T : 키, R : 지능지수, Z : 연령
나이브 베이즈 분류기
- 베이즈 정리에 의한 통계기반 분류 알고리즘
- 특징
- 아이템의 특징끼리 서로 독립
- 데이터 셋이 커도 모델 예측에 관계 없다
- Continuous Variable 보다 Discrete Variable에 더 잘맞는다
- 딥러닝을 제외하면 텍스트 데이터에 가장 적합
- 간단하고, 계산량이 많지 않은 모델
- 데이터의 차원이 높아질 수록 모든 클래스에 대해 확률이 0으로 수렴 가능
- Laplace smoothing 활용
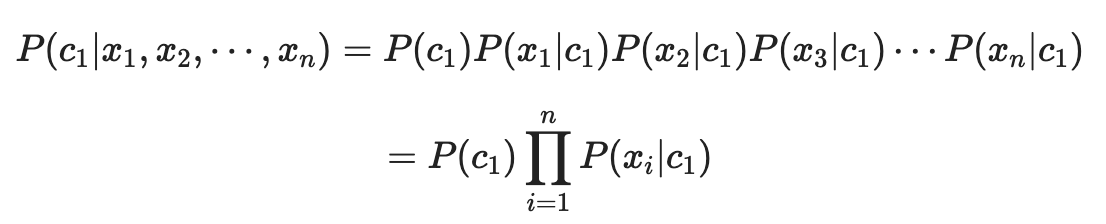
나이브 베이즈 활용한 예측 예시 (Feat. NLP)
X = data['text'] #리뷰 텍스트
y = data['stars'] #별점from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
cv.fit(X)
X = cv.transform(X)CountVectorizer : 단어별 빈도를 계산하여 데이터 프레임으로 정리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 100)from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB()
model.fit(X_train, y_train)
pred = model.predict(X_test)from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
accuracy_score(y_test, pred)
confusion_matrix(y_test, pred)
print(classification_report(y_test, pred))
Frontend & Artificial Intelligence