• 모델 외부의 설정 값으로, 사용자에 의해서 결정됨
• 모델의 성능을 좌우할 수 있음
• 데이터나 상황에 따라 최적의 값이 다르므로, 보통 Heuristic한 방법에 의해서 찾게됨
- vs Model Parameters?
• 모델 내부의 설정 값으로,데이터에 의해서 값이 정해짐. 학습에 의해서 변경
• 사용자에 의해서 조정되지 않음
• 딥러닝에서는 Network Weight Parameter라고 불리우기도 함
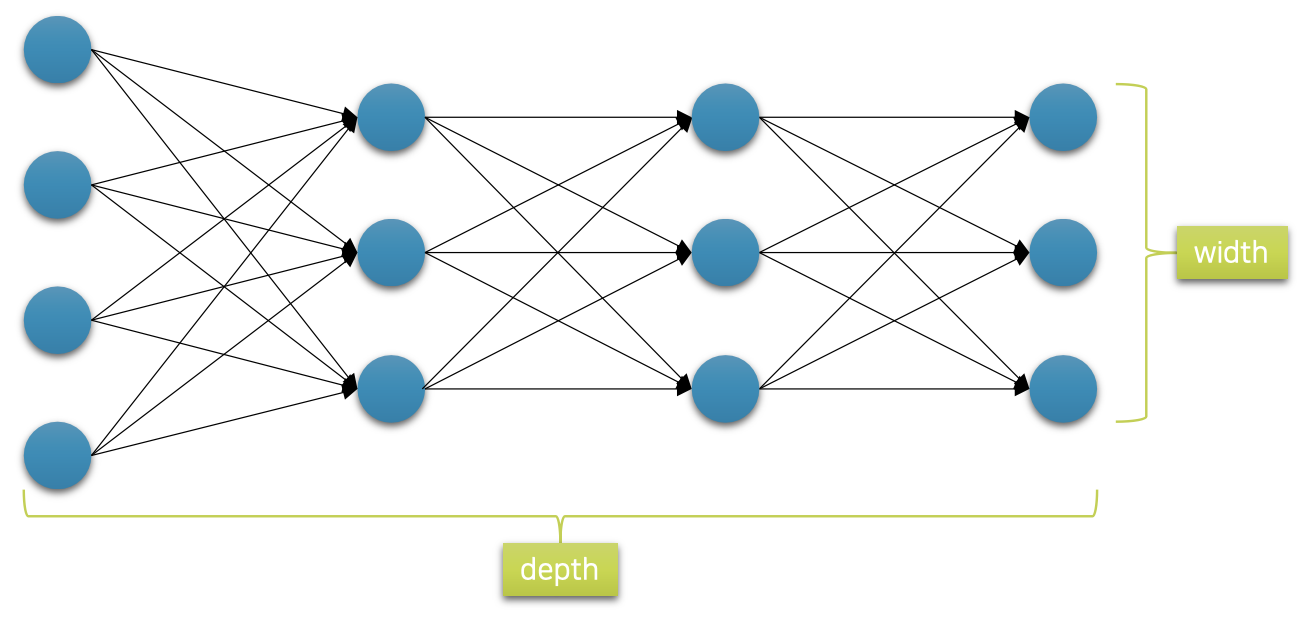
Network Depth & Width
• 네트워크의 capacity를 결정하는 요소
• 너무 깊으면 과적합(overfitting)*의 원인이 되며, 최적화가 어려움
• 너무 얕으면 복잡한 데이터의 관계 또는 함수를 배울 수 없음
• Tuning을 통해 최적의 architecture를 찾아야 함
Learning Rate
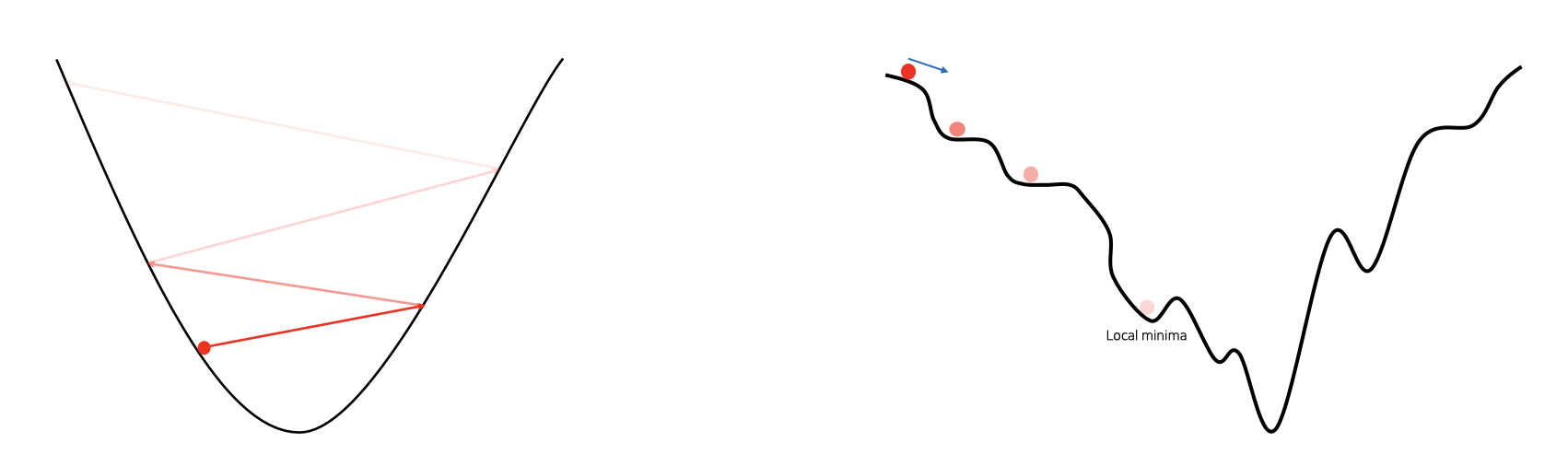
• Gradient Descent에서 기울기에 따른 파라미터의 업데이트 양을 조절
• 너무 큰 learning rate는 loss 값이 발산할 수 있음
• 너무 작은 learning rate는 학습의 진전이 더디거나, 진행되지 않을 수 있음
• 기존의 실습에서 learning rate를 조절해보면 다른 결과가 나오는 것을 알 수 있음
• Tuning을 통해 최적의 learning rate를 찾아야 함
기타...
- 어떤 활성 함수를 사용할 것인가?
• ReLU? LeakyReLU?
• LeakyReLU의 각도는? - 어떤 초기화 방법을 쓸 것인가?
• Weight parameter의 초기화 방법에 따른 편차 - 몇 번의 epoch를 돌릴 것인가?
- 미니배치의 크기는 어떻게 할 것인가?
결론
- Hyper-parameter는 데이터로부터 자동으로 학습할 수 없지만, 모델의 성능에 영향을 끼치는 파라미터를 가리킨다.
• 수동으로 튜닝하거나 다양한 실험을 통해 최적값을 찾아야함
(Grid-search,BayesianOptimization 등) - 많은 실무 경험을 통해,경험적으로 최적값과 비슷한 값을 찾을 수도 있음
• 특히 데이터셋과 모델이 큰 경우, 많은 튜닝이 어렵기 때문
• 일부 파라미터는 문제 해결여부가 달려있을수도 있음
• 하지만 대개 많은 파라미터들은 대개 약간의 성능변화만 야기하기도함 - 따라서 critical한 파라미터를 인지하고 주로 튜닝하는 것이 중요
- 많은 실험이 필요한 만큼, 실험결과를 잘 정리하는 요령이 필요!
Hyper-parameter 별 결과물 관리
- 수많은 튜닝 결과는 어떻게 관리할 것인가?
• 각 hyper-parameter 별 성능(accuracy, loss 등), 실험 마다 나오는 모델(weight) 파일 - 모델 파일 이름에 저장
ex) model.n_layers-10.n_epochs-100.act-leaky_relu.loss-xxx.accuracy-xx.pth
• 하지만 결국 Table로 정리가 필요하다. - 실험 관리를 도와주는 프레임워크
• MLFlow: https://mlflow.org/
• WanDB: https://www.wandb.com/ (일부 유료)

Frontend & Artificial Intelligence