0. 준비
ubuntu 3(master, worker1, 2)개를 준비하고, Network는 NAT로 설정
1. 컴퓨터 설정
0) 노드
- 마스터 노드 : 192.168.66.10
- 워커 노드 : 192.168.66.20 / 192.168.66.30
1) 컴퓨터 이름 변경
(1) 마스터 노드
vi /etc/hostname #이름을 master로 변경
(2) 워커 노드
vi /etc/hostname #이름을 worker1과 2로 변경
2) 다른 컴퓨터 이름 설정
vi /etc/hosts에
192.168.66.10 master
192.168.66.20 worker1
192.168.66.30 worker2를 모든 컴퓨터 추가
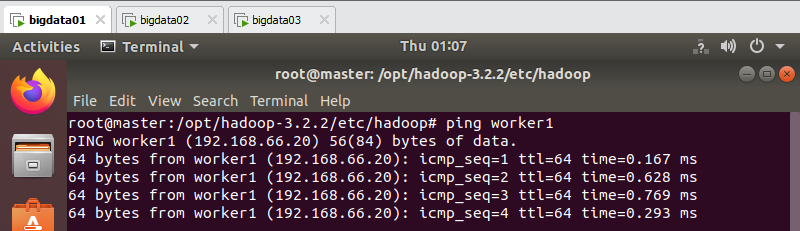
만약 잘 기입했다면 패킷이 이동하는 모습을 확인할 수 있음
2. 자바 설정
1) 자바 설치
Hadoop은 자바 기반 오픈소스프레임워크이기 때문에 자바를 설치해야함
apt update #현재 설치되어있는 패키지 전부 최신화
apt install -y openjdk-8-jdk #자바 설치
3. 사용자 계정 설정
1) 마스터 노드
addgroup --gid 2001 hdfsuseradd --create-home --shell /bin/bash --uid 2001 --gid 2001 hdfs
hdfs 서비스 계정 생성 > nameNode & dataNode등 HDFS와 관련된 서비스 실행passwd hdfs #hdfs 비밀번호 변경
addgroup --gid 2002 yarnuseradd --create-home --shell /bin/bash --uid 2002 --gid 2002 yarn
yarn 서비스 계정 생성 > resourceManager & nodeManager 등 YARN과 관련된 서비스 실행passwd yarn #yarn 비밀번호 변경
Master Node의 Data Directory 생성 및 Worker Node의 Data Directory 생성
mkdir -p /data/hdfs/namenode #mkdir -p /data/hdfs/jornalnodechown -R hdfs:hdfs /data/hdfsmkdir -p /data/yarnchown -R yarn:yarn /data/yarn
4. SSH 설정
1) SSH 설치
apt install openssh-serverapt install openssh-client
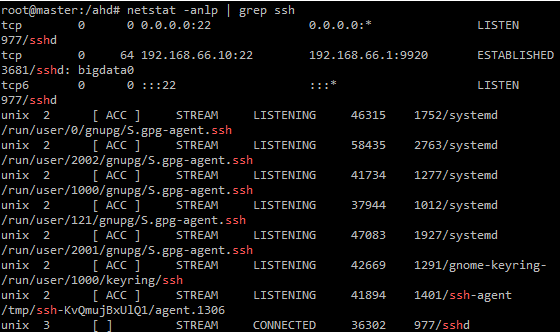
잘 설치가 되었는지 확인하려면
systemctl status ssh
netstat -anlp | grep ssh를 통해 확인하면 됨
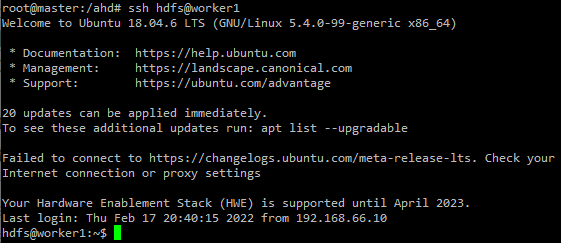
마지막으로 master에서 worker1,2로 접속이 되는지 확인

2) SSH 키 설정
1) 마스터 노드
hdfs로 로그인 후 ssh-keygen 공개키 생성
yarn로 로그인 후 ssh-keygen 공개키 생성
ssh-keygen #공개키 생성
ssh-copy-id hdfs@master
ssh-copy-id hdfs@worker1
패스워드 입력
ssh-copy-id hdfs@worker2
패스워드 입력
ssh-keygen #공개키 생성
ssh-copy-id yarn@master
ssh-copy-id yarn@worker1
패스워드 입력
ssh-copy-id yarn@worker2
패스워드 입력
마지막으로 master에서 worker1,2가 비밀번호 입력없이 접속이 되는지 확인
5. 하둡 다운 및 압축 해제
1) 하둡 다운로드(모든 컴퓨터 동일)
hadoop 다운로드 링크
혹은 wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1-src.tar.gz을 쳐서 다운로드
2) 압축 해제 및 이동(모든 컴퓨터 동일)
tar zxvf hadoop-3.2.2.tar.gz 파일 해제 후,
mv hadoop-3.2.2 /opt/hadoop-3.2.2로 이동
3) 디렉토리 생성(모든 컴퓨터 동일)
mkdir /opt/hadoop-3.2.2/pids
mkdir /opt/hadoop-3.2.2/logs
chown -R hdfs:hdfs /opt/hadoop-3.2.2
chmod 757 /opt/hadoop-3.2.2/pids
chmod 757 /opt/hadoop-3.2.2/logs
6. 하둡 설정
- 설정 파일들은 전부
/opt/hadoop-3.2.2/etc/hadoop에 존재함1) 설정
(1) 마스터 노드
- hadoop-env.sh(맨 아래에 저장)
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64 export HADOOP_HOME=/opt/hadoop-3.2.2 export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_MAPRED_HOME=${HADOOP_HOME} export HADOOP_COMMON_HOME=${HADOOP_HOME} export HADOOP_LOG_DIR=${HADOOP_HOME}/logs export HADOOP_PID_DIR=${HADOOP_HOME}/pids export HDFS_NAMENODE_USER="hdfs" export HDFS_DATANODE_USER="hdfs" export YARN_RESOURCEMANAGER_USER="yarn" export YARN_NODEMANAGER_USER="yarn"
- core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> <description>NameNode URI</description> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> <description>Buffer size</description> </property> <!-- HA Configuration --> <property> <name>ha.zookeeper.quorum</name> <value>zookeeper-001:2181,zookeeper-002:2181,zookeeper-003:2181</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hdfs/.ssh/id_rsa</value> </property> </configuration>
- hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.namenode.http.address</name> <value>master:9870</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/data/hdfs/namenode</value> </property> </configuration>
- mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
- yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>1024</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>1</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
- workers
master worker1 worker2
(2) 워커 노드
- hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64 export HADOOP_HOME=/opt/hadoop-3.2.2 export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_MAPRED_HOME=${HADOOP_HOME} export HADOOP_COMMON_HOME=${HADOOP_HOME} export HADOOP_LOG_DIR=${HADOOP_HOME}/logs export HADOOP_PID_DIR=${HADOOP_HOME}/pids export HDFS_NAMENODE_USER="hdfs" export HDFS_SECONDARYNAMENODE_USER="hdfs" export HDFS_DATANODE_USER="hdfs" export YARN_RESOURCEMANAGER_USER="yarn" export YARN_NODEMANAGER_USER="yarn"
- core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration>
- hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.datanode.name.dir</name> <value>file:/data/hdfs/datanode</value> </property> </configuration>
- mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
- yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>1024</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>1</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
7. 하둡 실행
1) 실행
(1) 마스터 노드
/opt/hadoop-3.2.2/bin/hdfs namenode -format /opt/hadoop-3.2.2/sbin/start-all.sh
2) 확인
(1) 마스터 노드
jps 실행시
P.S. 만약 NameNode가 뜨지 않는다면, 다음 코드 실행 후
chown -R hdfs:hdfs /data/hdfs chown -R yarn:yarn /data/yarn init 6jps 명령어 실행

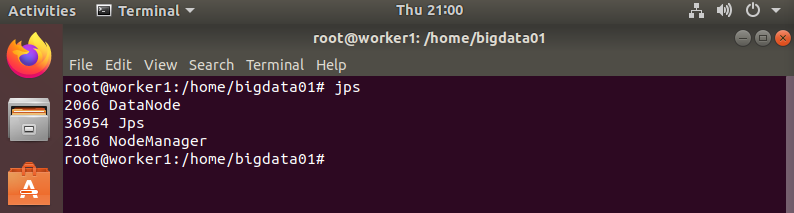
(2) 워커 노드
jps 실행시
(3) 본체 컴퓨터에서 웹브라우저 확인
http://마스터노드의IP주소:9870/

3) 에러 확인
cd /opt/hadoop-3.2.2/logs/에서 .log파일들을 확인
