Linked-list

- 배열과 흡사하게 작동하나, 원소들이 메모리상에 연속적으로 위치하지 않는다
- 연속되는 항목들이 포인터로 연결되고, 마지막 항목은 null을 가리킨다
- 배열에 비해 데이터의 추가/삽입 및 삭제가 용이하나 항상 순차적으로 탐색해야 하기 때문에 속도가 떨어질 수 있다
- 탐색 또는 정렬을 자주 하면 배열을, 추가/삭제가 많으면 linked list를 사용
Hash Table
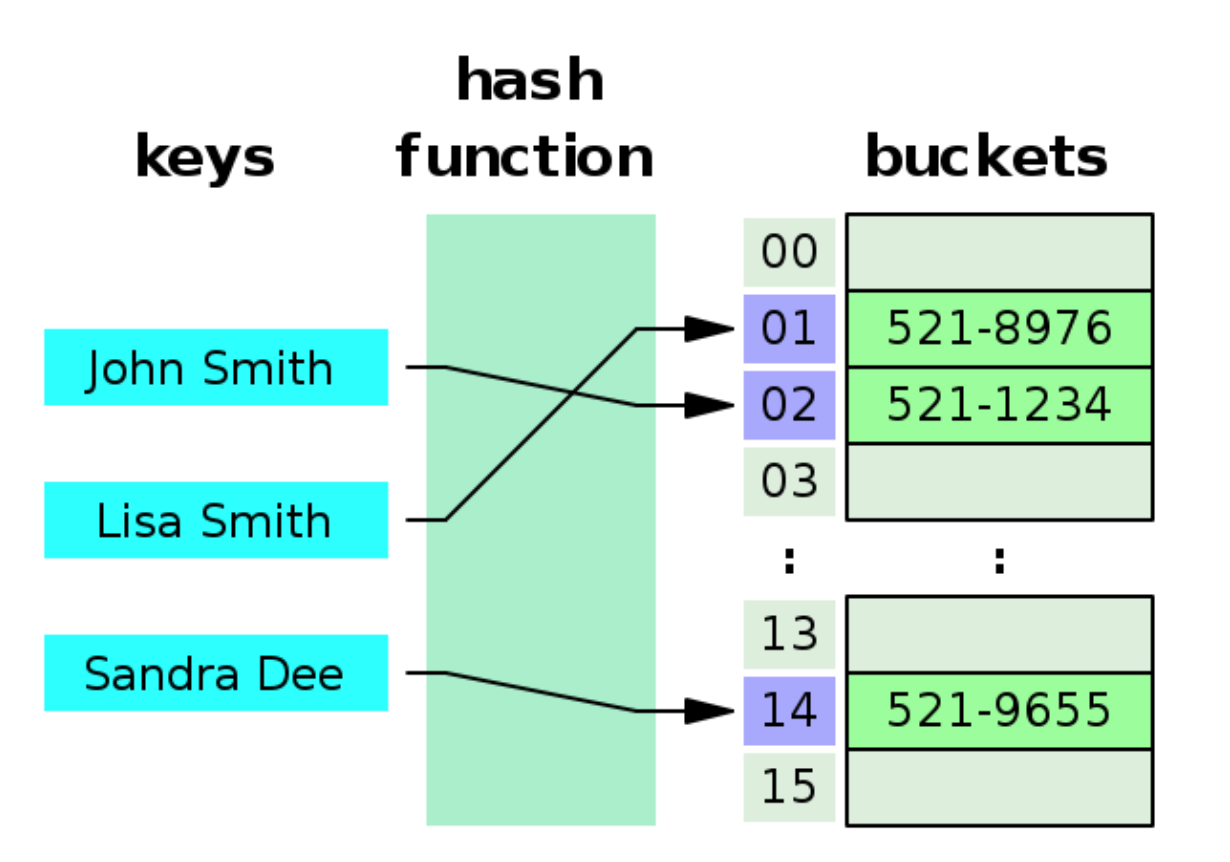
- key와 value로 데이터를 저장하고 관리하는 자료구조
- 빠른 검색 속도 지원 (평균적으로 시간복잡도 O(1))
- 각각의 key값에 hash function를 적용해 배열의 고유한 index를 생성해 bucket이라 불리는 array에 값을 저장
Hash Function
- 대표적인 hash function: 입력값을 저장할 자료의 수로 나눈 나머지를 사용하는 division method, key가 string인 경우 number로 변환하고 합계를 사용하는 digit folding, 여러 hash function을 무작위로 선택하여 나온 값을 사용하는 universal hashing 등
- 좋은 hash function이란 충돌의 가능성을 줄여 hash table의 효과를 극대화하는 함수이다
Collision
- 두 개 이상의 다른 key의 hash값이 같아, 이미 자료가 저장되어 있는 곳에 중복 저장해야 하는 경우
- separate chaining 혹은 open addressing으로 해결
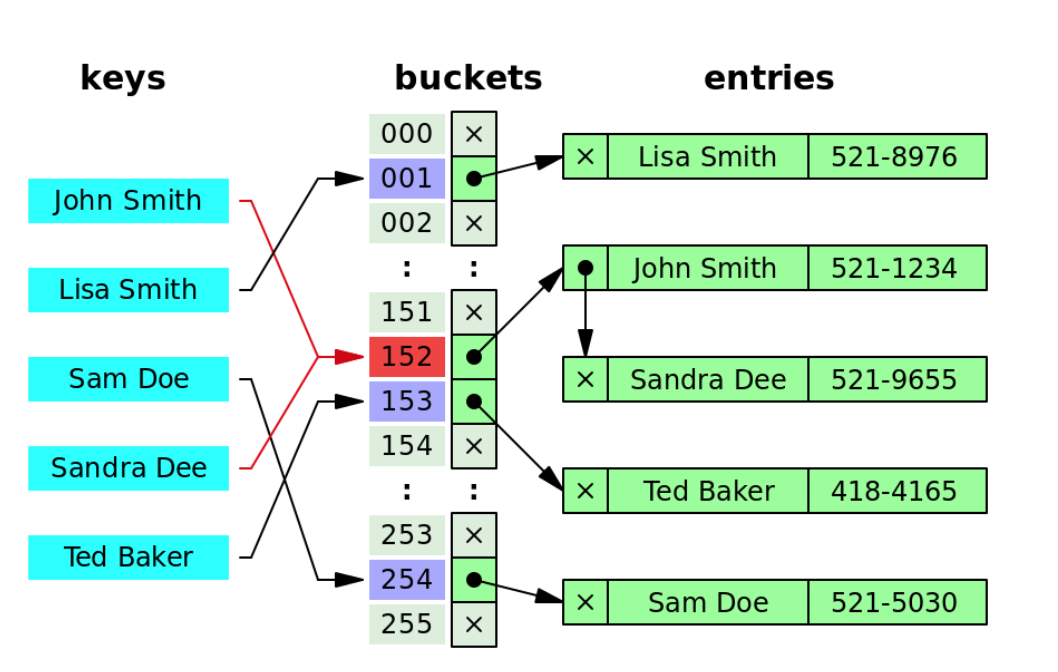
Separate Chaining
- linked list 형식으로 동일한 주소에 저장되어야 할 자료를 연결하여 저장
- 테이블을 확장할 필요가 없고, 구현과 삭제가 손쉽다
- chaining할 때마다 추가적인 메모리 소모가 있고, chaining된 자료의 수가 늘어날수록 효율이 감소한다
.png)
Open Addressing
- hash table에 이미 비어 있는 공간을 활용
- 저장하려 하는 위치에 이미 자료가 존재하는 경우 특정 거리 떨어진 위치를 조회하여 비어 있는 곳에 저장
- 고정 폭 만큼씩 이동하는 linear probing, 이동 폭을 제곱으로 늘려 나가는 quadratic probing (1^2 -> 2^2 -> 3^2 ...), hash된 값을 다시 hash하는 double hashing probing 등이 있다

Codestates Software Engineering Full IM 28th