하둡은 기본적으로 HDFS, MapReduce로 구성된다. 맵리듀스는 HDFS에 저장된 파일을 분산 배치 분석을 할 수 있게 도와주는 프레임 워크이다. 개발자는 맵리듀스 프로그래밍 모델에 맞게 애플리케이션을 구현한다. 데이터 전송, 분산 처리, 내고장성 등의 복잡한 처리는 맵리듀스 프레임워크가 자동으로 담당하는 Runtime System이다.
1. MapReduce의 개념
맵리듀스 프로그래밍 모델은 Map과 Reduce라는 크게 2가지 단계로 데이터를 처리한다. 맵은 입력 파일을 한 줄씩 읽어 데이터를 변형(Transformation)하며 리듀스는 맵의 결과 데이터를 집계(Aggregation)한다. 다만, 개발자는 맵의 데이터 Transformation 규칙을 자유롭게 구현하여 정의할 수 있다.
이러한 맵리듀스 프로그래밍 모델은 다음과 같이 함수로 표현할 수 있다.
- 맵 :
(key1, value1) => list(key2, value2) - 리듀스 :
(key2, list(value2)) => (key3, list(value3))
2. MapReduce Architecture
맵리듀스 프레임워크는 Runtime System이다. 개발자는 단순하게 분석 로직을 구현하고, 데이터에 대한 분산 및 병렬 처리에 대한 어려운 문제는 프레임워크가 전담한다. 그렇기에 개발자가 맵리듀스 아키텍처를 몰라도 개발은 가능하다. 다만, 아키텍처를 제대로 알지 못한채 개발하게 되면 성능을 고려하지 않게 되므로, 이는 바람직하지 않다.
맵리듀스 시스템은 JobTracker, TaskTracker로 구성되며 이 또한 HDFS와 마찬가지로 master-slaves 구조이다. 클라이언트는 JobTracker에게 Job 실행을 요청하고, Job의 진행 상황 및 완료 결과를 공유받게 된다.
-
클라이언트란, 사용자가 실행한 맵리듀스 프로그램과 하둡에서 제공하는 맵리듀스 API를 말한다. -
클라이언트가 실행을 요청하는 맵리듀스 프로그램은
Job이라고 하는하나의 단위로 관리된다. 이러한Job은 여러 개의 task들로 분산되어 처리된다.Job Tracker는 하둡 클러스터에 있는 전체 Job의 스케줄링을 관리하며 모니터링한다.전체 하둡 클러스터에서는 하나의 JobTracker가 구동되게 된다. 보통Job Tracker는 네임 노드가 구동되는 서버에서 동작한다.
사용자가 맵리듀스 Job을 요청하게 되면JobTracker는 몇 개의 맵과 리듀스를 실행하게 될 지를 계산한다. 이러한 task들을 어떤TaskTracker에서 실행할 것인지를 결정하며, Task를 할당한다.JobTracker와TaskTracker는Heartbeats message를 사용하여TaskTracker의 상태와 작업 실행 정보를 공유한다. -
Task Tracker는 사용자가 설정한 맵리듀스 프로그램을 실행하며, 하둡의 데이터 노드에서 실행되는 데몬이다.JobTracker로부터 작업을 요청받으며, 그러면map task와reduce task를 생성하게 된다. 이러한 task가 생성되면새로운 JVM을 구동해 task를 실행한다. 이 때 task를 실행하기 위한 JVM은 재사용될 수도 있다. 또한, 하나의 데이터 노드이더라도 여러 개의 JVM을 구동하여 데이터를 동시에 분산 처리하게 된다.
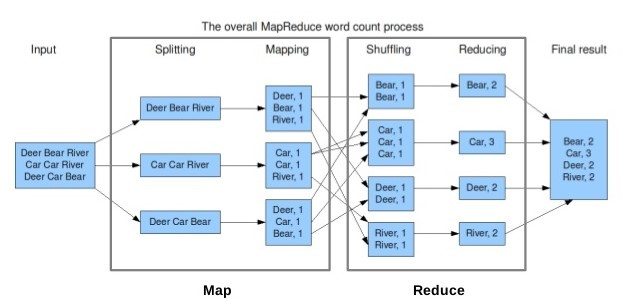
3. MapReduce Work Flow
위 그림을 다시 보도록 하자. 우선 입력 데이터가 들어오게 되면 데이터를 Input Split 단위로 쪼개게 된다. 이 때 Input Split의 크기는 일반적으로 HDFS의 블록 크기와 동일하다. 그 이유는 추후 설명한다. 이 과정을 Splitting 이라고 한다.
그 다음 Mapping 과정을 거친다. 이 때 Input Split의 데이터를 레코드 단위로 한 줄씩 읽어서 사용자가 정의한 Map Function을 적용한다. Input Split은 위 그림에서 1줄로 표현되어 있으나, 실제로는 64MB(하둡 2.0부터는 128MB)이므로 상당히 많은 레코드가 있을 것이다. 즉, Input Split의 레코드 수 만큼 Map Function이 적용되게 되고 하나의 Input Split에 하나의 Mapper Class가 적용된다.
Map Task의 결과로 intermediate Key-Value Pair가 생성된다. 위 그림에서 보듯이 Deer, 1과 같은 Pair가 생성됐음을 알 수 있다. 그러면 Reduce Task는 이 데이터를 내려 받아 Shuffling을 한다. Shuffle 과정은 Map Task의 데이터가 Reduce Task로 전달되는 과정이다. 여기서 네트워크 통신이 가장 많이 일어나게 되며 그에 따라 MapReduce 성능의 저하가 가장 많이 발생하는 구간이다. Shuffle 과정에서는 Partition 과정도 존재한다. Partitioner는 맵의 출력 레코드를 읽어서 출력 키의 해시값을 구한다. 각 해시값은 레코드가 속하는 Partition 번호로 사용되게 된다. 이 때 Partition은 Reduce Task의 개수만큼 생성된다. Partitioner는 개발자가 재정의하여 입맛에 맞게 사용할 수도 있다.
또한, 위 그림에서는 최종 결과가 1개 이므로 Reducer가 1개가 있다는 의미이다. Reducer의 개수에 따라 출력 파일이 그 개수에 맞게 생성되기 때문이다.
4. MapReduce Programming Elements
맵리듀스는 네트워크 통신을 위한 최적화된 객체로 WritableComparable Interface를 제공한다. 맵리듀스 프로그램에서 사용하는 모든 Key와 Value는 반드시 WritableComparable Interface가 구현되어 있어야 한다. 하둡에서 제공하는 데이터 타입은 기본적으로 모두 WritableComparable Interface가 구현되어 있으며, 개발자가 원하는 경우 직접 해당 인터페이스를 사용하여 구현할 수도 있다.
WritableComparable Interface는 Writable Interface와 Comparable Interface를 상속한 인터페이스이다. Comparable Interface의 경우 java.lang 패키지의 인터페이스로 정렬을 처리하기 위해 compareTo 메소드를 제공한다.
Writable Interface의 write 메소드는 데이터 값을 serialization(직렬화)하고, readFields 메소드는 deserialization을 진행한다. 데이터를 전송할 때는 구조화된 객체를 직접적으로 전송할 수 없다. 따라서 이를 바이트 스트림으로 바꿔줘야 하는데 그 과정이 serialization이다. 이것은 구조화된 객체를 네트워크 전송을 위해 바이트 스트림으로 변환하거나, 하드 디스크에 저장하기 위한 것이다. 반대로 deserialization은 네트워크를 통해 전송받은 바이트 스트림을 구조화된 객체로 변환하는 것이다.
맵리듀스 API는 자주 사용하는 데이터 타입에 대한 WritableComparable Interface를 구현한 Wrapper Class를 제공한다. 이 때 제공되는 데이터 타입은 다음과 같다.
| 클래스 이름 | 대상 데이터 타입 |
| BooleanWritable | Boolean |
| ByteWritable | 단일 byte |
| DoubleWritable | Double |
| FloatWritable | Float |
| IntWritable | Integer |
| LongWritable | Long |
| TextWrapper | UTF 형식의 문자열 |
| NullWritable | 데이터 값이 필요 없을 경우에 사용함. |
맵리듀스는 Input Split을 맵 메소드의 입력 파라미터로 사용할 수 있도록 InputFormat이라는 추상 클래스를 제공한다. InputFormat Class는 Input Split을 맵 메소드가 사용할 수 있돌고 getSplits 메소드를 제공한다. 그리고 createRecordReader 메소드는 Input Split을 Key와 List 형태로 사용할 수 있게 RecordReader 객체를 생성한다. 아래 표는 InputFormat 유형 표이다.
| InputFormat | 기능 |
| TextInputFormat | 텍스트 파일을 분석할 때 사용한다. \n(개행 문자)를 기준으로 레코드를 분석하게 된다. Key값은 Offset이며, LongWritable을 사용한다. Value는 line의 내용이며, Text를 사용한다. 사용자가 별도로 설정하지 않을 경우 TextInputFormat이 기본값으로 설정된다. |
| KeyValueTextInputFormat | 텍스트 파일을 입력 파일로 사용할 때, Offset이 아닌 임의의 키 값을 지정하는 것이다. |
| NLineInputFormat | 맵 task가 입력받을 텍스트 파일의 line 수를 제한하고 싶을 때 사용한다. |
| DelegatingInputFormat | 여러 개의 서로 다른 입력 format을 사용하는 경우 각 경로에 대한 작업을 위임한다. |
| CombineFileInputFormat | 이 표에 존재하는 다른 InputFormat은 파일 당 스플릿을 생성한다. 하지만 CombineFileInputFormat은 여러 개의 파일을 스플릿으로 묶어서 사용한다. 이 때 각 노드와 랙의 위치를 고려해 스플릿을 결정하게 된다. |
| SequenceFileInputFormat | Sequence 파일을 Input Data으로 사용할 때 사용한다. Sequence 파일은 바이너리 형태로 Key, Value의 목록으로 구성된 텍스트 파일이다. |
| SequenceFileAsBinaryInputFormat | Sequence 파일의 Key와 Value를 임의의 바이너리 객체로 변환하여 사용한다. |
| SequenceFileAsTextInputFormat | Sequence 파일의 Key와 Value를 Text 객체로 변환하여 사용한다. |
Mapper Class의 소스 코드를 보면 제너릭 파라미터를 이용해 클래스를 정의한다.
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {}위 코드에서 <> 내부 내용은 <입력 키 유형, 입력 값 유형, 출력 키 유형, 출력 값 유형>을 말한다. 그리고 Mapper Class 에서는 Context 객체를 선언하며, 이를 사용해 Job에 대한 정보를 얻어올 수 있게 된다.
protected void map(KEYIN key, VALUEIN value, Context context) {}위 코드는 map 함수이다. MapReduce 프로그램을 개발할 때 위 함수를 재정의하여 사용한다.
Reducer Class의 소스 코드를 보면 Mapper Class와 마찬가지로 제너릭 파라미터를 사용한다.
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {}위 코드에서 <> 내부 내용은 Mapper와 동일하다.
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context) {}위 코드는 reduce 함수이다. map 함수와 마찬가지로 MapReduce 프로그램을 개발할 때 위 함수를 재정의하여 사용한다.
이전에 설명했듯 MapReduce 과정에서 Shuffling 과정은 가장 오버헤드가 크게 발생하는 구간이다. 네트워크 통신이 가장 많이 발생하기 때문이다. 이를 줄이고자 Combiner Class가 등장하게 됐다.
Combiner Class는 Shuffle할 데이터의 크기를 줄이는 것에 도움을 주게 된다. Combiner Class는 Mapper의 출력 데이터를 입력 데이터로 받아 그 크기를 줄이는 것에 목적을 두고 있다. 따라서, 네트워크 비용은 발생하지 않는다. Combiner Class를 적용한 이후에 Shuffle 과정에서 통신할 데이터의 양이 줄었을 것이고, 그럼으로써 비용 감소 및 성능 향상을 이끌어낼 수 있을 것이다.
다만, 주의할 점이 있다. Combiner Class를 적용하지 않아도 MapReduce 알고리즘이 정상적으로 동작하게끔 설계해야 한다는 것이다. 즉, 적용했든 안했든 모두 같은 결과를 출력해야 한다는 것이다.
그렇다면, MapReduce Job의 OutputFormat에 대해서도 알아보도록 하자. 아래 표는 OutputFormat에 관한 표이다.
| OutputFormat | 기능 |
| TextOutputFormat | 텍스트 파일에 레코드를 출력할 때 사용한다. 레코드를 출력할 때 Key와 Value의 구분자는 탭을 사용한다. |
| SequenceFileOutputFormat | Sequence 파일을 출력물로 쓸 때 사용한다. |
| SequenceFileAsBinaryOutputFormat | SequenceFileOutputFormat을 상속받아 구현됐으며, 바이너리 Format의 Key와 Value를 SequenceFile 컨테이너에 쓴다. |
| FilterOutputFormat | OutputFormat 클래스의 래퍼 클래스이다. OutputFormat 클래스를 편리하게 사용할 수 있는 메소드를 제공한다. |
| LazyOutputFormat | FileOutputFormat을 상속받은 클래스는 출력할 내용이 없더라도 Reduce의 출력 파일(part-r- nnnnn)을 생성한다. 하지만 LazyOutputFormat을 사용하면 첫 번째 레코드가 해당 파티션으로 보내질 때만 결과 파일을 생성한다. |
| NullOutputFormat | 출력 데이터가 없는 경우 사용한다. |
5. MapReduce Job Execution
맵리듀스 Job이 실행되는 과정은 다음과 같다.
1. 클라이언트가 Job 실행을 요청
클라이언트는 org.apache.hadoop.mapreduce.Job의 waitForCompletion 메소드를 호출해 Job 실행을 요청한다. 이 때, 클라이언트의 요청은 Job의 내부 컴포넌트인 JobClient에게 전달된다.
JobClient는 JobTracker의 getNewJobID 메소드를 호출해 새로운 Job ID를 요청한다. JobTracker는 Job의 출력 파일 경로가 정상적인지 확인하고 Job ID를 발급한다. 만약 Job의 출력 파일 경로가 비정상적일 경우 에러를 리턴한다. 하둡은 기본적으로 RPC로 통신하며, JobSubmissionProtocol에 정의된 Protocol을 사용한다.
JobClient는 Job을 실행하는 데 필요한 정보를 JobTracker와 TaskTracker에게 공유해야 한다. 그래서 JobClient는 Input Split의 정보, JobConf에 설정된 정보, Job Class 파일 혹은 Job Class가 포함된 JAR 파일을 HDFS에 저장한다. 그러면 하둡 클러스터의 모든 노드에서 위 정보와 파일에 접근할 수 있기 때문이다.
JobClient는 Job Tracker의 submitJob 메소드를 호출해 Job 실행을 요청한다.
2. 해당 Job의 초기화
이제 Job 실행을 요청하게 됐다. JobTracker는 Job을 실행하기 위한 초기 설정 작업을 진행하게 된다.
JobTracker는 Job의 상태와 진행 과정을 모니터링할 수 있는 JobInProgress를 생성한다. 이 때 JobInProgress는 JobClient가 HDFS에 등록한 Job 공통 파일을 로컬 디스크로 복사한 후 Split 정보를 이용해 Map Task 개수와 Reduce Task 개수를 계산한다. 또, Job의 실행 상태를 RUNNING으로 설정한다.
JobTracker는 생성한 JobInProgress 객체를 내부 큐인 jobs에 등록한다. 큐에 등록된 JobInProgress는 스케쥴러에 의해 소비되게 된다.
3. Job을 실행하기 위한 Task 할당
맵리듀스는 Task를 할당하기 위한 스케줄러인 TaskScheduler을 제공한다. TaskScheduler는 추상 클래스이며, 이를 구현한 것은 3가지 이다.
FIFO(First In First Out) 방식의 JobQueueTaskSchedulerFair SchedulerCapacityScheduler
이 때 참고로 , TaskScheduler는 JobTracker 내부에서 운용된다.
TaskTracker는 3초에 1번씩 JobTracker에게 Heartbeats message를 전송한다. 이를 통해 TaskTracker가 실행 중이라는 것과 새로운 Task를 실행할 준비가 됐다는 것을 알려 준다.
Scheduler는 TaskTracker의 Heartbeats message를 확인한 후, 내부 큐(JobInProgress가 들어 있는 jobs)에서 할당할 job을 선택한다. 그리고 해당 job에서 하나의 task를 선택한다. 참고로, 하나의 job은 다수의 task로 구성된다. 이 때 job을 선택하는 기준은 scheduler 마다 그 기준이 다르다.
Scheduler는 Map Task와 Reduce Task를 구분해 Task를 할당한다. 이 때 Task는 Data Locality를 고려하여 할당하게 된다. 하둡의 맵리듀스는 Computing to Data 패러다임을 채택했고, 사용하기 때문이다.
Scheduler는 Task를 선택한 후 해당 TaskTracker에게 Task 할당을 알려 준다. JobTracker는 TaskTracker가 전송한 Heartbeats의 응답으로 HeartbeatResponse를 전송한다. JobTracker는 TaskTracker에게 지시할 내용을 HeartbeatResponse에 담아 설정하게 된다. 그래서 Scheduler는 HeartbeatResponse에 Task 실행을 요청한다. 해당 메시지에는 task 실행 및 종료, job 종료, tasktracker 초기화 재실행, task 완료 등의 작업을 설정할 수 있다.
4. 할당된 Task의 실행
TaskTracker는 할당받은 task를 새로운 JVM에서 실행하게 된다. 맵리듀스는 이를 Child JVM 이라고 표현한다. 이 때 새로운 JVM에서 발생하는 버그는 TaskTracker에게 영향을 끼치지 않기 때문에 안정적으로 TaskTracker를 운영할 수 있다. 또한, Child JVM은 재사용이 가능하다.
TaskTracker 내부의 TaskLauncher는 HeartbeatResponse에서 Task 정보를 꺼내서 Task의 상태와 진행 과정을 모니터링할 수 있는 TIP(TaskInProgress)를 생성한다.
TaskTracker는 HDFS에 저장된 공통 파일을 로컬 디렉토리로 복사한다. 그 다음 TaskInProgress는 Task 실행 결과를 저장할 로컬 디렉토리를 생성한 후 Job JAR 파일을 해당 디렉토리에 풀어 놓는다.
TaskInProgress는 TaskRunner에게 Task 실행을 요청한다.
TaskRunner는 JvmManager에게 Child JVM에서 task를 실행해 줄 것을 요청한다.
JvmManager는 실행할 클래스 명과 옵션을 설정한 후, 커맨드 라인에서 Child JVM을 실행한다. 이 때, Child JVM은 TaskUmbilicalProtocol 인터페이스로 부모 클래스와 통신하게 된다. Child JVM은 Task가 완료될 때까지 Task의 진행 과정을 주기적으로 JvmManager에게 알려 준다. 그러면 TaskTracker는 해당 정보를 공유받아 Task의 진행 과정을 모니터링할 수 있다.
최종적으로 사용자가 정의한 Mapper Class 혹은 Reducer Class가 실행된다.
5. Job 완료
TaskTracker가 JobTracker에 전송하는 Heartbeats에는 완료된 Task의 정보가 포함된다.
JobTracker는 해당 Job이 실행한 전체 Task의 완료 정보를 받게 될 경우 JobInProgress는 Job의 상태를 SUCCEEDED로 변경한다. 만약 장애가 발생하여 Job이 실패했다면 Job의 상태를 FAILED로 변경한다.
Job을 실행한 클라이언트와 JobClient는 Job이 완료될 때 까지 대기하고 있으며 JobClient는 JobTracker의 getJobStatus 메소드를 호출해 job의 상태를 확인한다. JobClient는 job의 상태가 SUCCEED이면 true를, FAILED면 false를 클라이언트에게 전달한다.
클라이언트는 최종 결과를 출력하고, job 실행을 완료한다.
