먼저, 데이터 분석에 들어가기 이전에 본인은 Docker에서 Ubuntu Container를 사용하여 하둡을 설치하고 환경 설정을 하였다. 또한, Pseudo-distributed Mode이다. 아래 코드는 Github에 업로드할 것이다. 그리고 간단한 테스트 및 실행이므로 root 계정으로 실행했다.
1. 미국 항공편 운항 통계 데이터 분석
데이터 다운로드 및 압축 해제
http://stat-computing.org/dataexpo/2009 에서 데이터를 가져오도록 한다. 여기서는 1987년 ~ 2008년의 데이터를 다운로드 받을 수 있는데, 일일히 다운받아야 한다. 상당히 번거로운 작업이므로 shell script를 작성하여 한 번에 다운로드 받을 수 있도록 한다. 아래 코드로 작성했다. 아래 코드는 데이터는 이미 존재하고, 압축을 풀 때 일일히 풀지 않기 위한 코드이다.
다만, 해당 데이터를 찾을 수가 없어서 위키북스에 문의해 데이터셋을 찾았다.
#!/bin/bash
for ((i=1987; i <= 2008; i++)) ; do
bzip2 -d $i.csv.bz2
sed -e '1d' $i.csv > $i_temp.csv
mv $i_temp.csv $i.csv
done데이터 HDFS에 업로드
./bin/hadoop dfs -mkdir input
./bin/hadoop dfs -put /root/hadoop/dataexpo/*.csv input
JAVA Class 구현
java 코드는 intellij로 작성하여 JAR 파일로 추출한다. 항공 출발 지연 데이터를 분석하도록 한다. 얼마나 많은 항공기가 출발이 지연됐는지를 계산하는 맵리듀스 프로그램을 작성하도록 한다.
Parser
import org.apache.hadoop.io.Text;
public class AirlinePerformanceParser {
private int year; // 운항 연도
private int month; // 운항 월
private int arriveDelayTime = 0; // 항공기 도착 지연 시간
private int departureDelayTime = 0; // 항공기 출발 지연 시간
private int distance = 0; // 거리
private boolean arriveDelayAvailable = true;
private boolean departureDelayAvailable = true;
private boolean distanceAvailable = true;
private String uniqueCarrier; // 항공사 코드
public AirlinePerformanceParser(Text text) {
try {
String[] colums = text.toString().split(","); // csv 파일은 ,를 구분자로 사용하기 때문에 이를 분리한다.
year = Integer.parseInt(colums[0]); // 운항 연도 설정
month = Integer.parseInt(colums[1]); // 운항 월 설정
uniqueCarrier = colums[8]; // 항공사 코드 설정
if(!colums[15].equals("NA")) // 출발 지연 시간 설정
departureDelayTime = Integer.parseInt(colums[15]);
else
departureDelayAvailable = false;
if(!colums[14].equals("NA")) // 도착 지연 시간 설정
arriveDelayTime = Integer.parseInt(colums[14]);
else
arriveDelayAvailable = false;
if(!colums[18].equals("NA"))
distance = Integer.parseInt(colums[18]);
else
distanceAvailable = false;
// 출발 지연 시간과 도착 지연 시간, 거리에는 NA값이 들어가 있는 경우가 있으므로, Exception을 미리 방지하기 위해 위 조건문처럼 처리하도록 한다.
}
catch (Exception e) {
System.out.println("Error parsing a record : " + e.getMessage());
}
}
public int getYear() { return year; }
public int getMonth() { return month; }
public int getArriveDelayTime() { return arriveDelayTime; }
public int getDepartureDelayTime() { return departureDelayTime; }
public boolean isArriveDelayAvailable() { return arriveDelayAvailable; }
public boolean isDepartureDelayAvailable() { return departureDelayAvailable; }
public String getUniqueCarrier() { return uniqueCarrier; }
public int getDistance() { return distance; }
public boolean isDistanceAvailable() { return distanceAvailable; }
}Mapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class DepartureDelayCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// 얼마나 많은 항공기가 출발이 지연되었는지를 계산하는 MapReduce Program
/*
mapper의 경우 입력키는 offset이고, 입력값은 항공 운항 통계 데이터(csv)가 될 것이다.
또한, 출력키는 운항연도, 운항월이고 출력값은 출발 지연 건수가 될 것이다.
WordCount 예제와 유사한 예제이다.
*/
private final static IntWritable outputValue = new IntWritable(1); // 출력값
private Text outputKey = new Text(); // 출력키
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
AirlinePerformanceParser parser = new AirlinePerformanceParser(value);
outputKey.set(parser.getYear() + "," + parser.getMonth()); // 출력키(운항연도,운항월) 설정
if(parser.getDepartureDelayTime() > 0) // 출발 지연이 발생한 경우, context.write 호출
context.write(outputKey, outputValue);
}
}
Reducer
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class DelayCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable value : values)
sum += value.get();
result.set(sum);
context.write(key, result);
}
}Driver Program
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class DepartureDelayCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
if(args.length != 2) {
System.err.println("Usage : DepartureDelayCount <input> <output>");
System.exit(2);
}
Job job = new Job(conf, "DepartureDelayCount");
job.setJarByClass(DepartureDelayCount.class);
job.setMapperClass(DepartureDelayCountMapper.class);
job.setReducerClass(DelayCountReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean success = job.waitForCompletion(true);
System.out.println(success);
}
}실행 및 결과 확인
./bin/hadoop jar AirlinePerformanceParser.jar DepartureDelayCount input dep_delay_count데이터가 상당히 크기 때문에 MapReduce가 동작하고 결과값을 출력하는 데 약 3분 정도가 소요됐다.
21/01/29 17:41:30 INFO mapred.JobClient: Map-Reduce Framework
21/01/29 17:41:30 INFO mapred.JobClient: Spilled Records=131001126
21/01/29 17:41:30 INFO mapred.JobClient: Map output materialized bytes=640406428
21/01/29 17:41:30 INFO mapred.JobClient: Reduce input records=48310901
21/01/29 17:41:30 INFO mapred.JobClient: Virtual memory (bytes) snapshot=341211439104
21/01/29 17:41:30 INFO mapred.JobClient: Map input records=118924389
21/01/29 17:41:30 INFO mapred.JobClient: SPLIT_RAW_BYTES=20455
21/01/29 17:41:30 INFO mapred.JobClient: Map output bytes=543783522
21/01/29 17:41:30 INFO mapred.JobClient: Reduce shuffle bytes=640406428
21/01/29 17:41:30 INFO mapred.JobClient: Physical memory (bytes) snapshot=45236703232
21/01/29 17:41:30 INFO mapred.JobClient: Reduce input groups=247
21/01/29 17:41:30 INFO mapred.JobClient: Combine output records=0
21/01/29 17:41:30 INFO mapred.JobClient: Reduce output records=247
21/01/29 17:41:30 INFO mapred.JobClient: Map output records=48310901
21/01/29 17:41:30 INFO mapred.JobClient: Combine input records=0
21/01/29 17:41:30 INFO mapred.JobClient: CPU time spent (ms)=601670
21/01/29 17:41:30 INFO mapred.JobClient: Total committed heap usage (bytes)=37261672448
21/01/29 17:41:30 INFO mapred.JobClient: File Input Format Counters
21/01/29 17:41:30 INFO mapred.JobClient: Bytes Read=11575211599
21/01/29 17:41:30 INFO mapred.JobClient: FileSystemCounters
21/01/29 17:41:30 INFO mapred.JobClient: HDFS_BYTES_READ=11575232054
21/01/29 17:41:30 INFO mapred.JobClient: FILE_BYTES_WRITTEN=1745010712
21/01/29 17:41:30 INFO mapred.JobClient: FILE_BYTES_READ=1094436536
21/01/29 17:41:30 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=3520
21/01/29 17:41:30 INFO mapred.JobClient: Job Counters
21/01/29 17:41:30 INFO mapred.JobClient: Launched map tasks=184
21/01/29 17:41:30 INFO mapred.JobClient: Launched reduce tasks=1
21/01/29 17:41:30 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=336625
21/01/29 17:41:30 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
21/01/29 17:41:30 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=658576
21/01/29 17:41:30 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
21/01/29 17:41:30 INFO mapred.JobClient: Data-local map tasks=184
21/01/29 17:41:30 INFO mapred.JobClient: File Output Format Counters
21/01/29 17:41:30 INFO mapred.JobClient: Bytes Written=3520
true프로그램이 정상적으로 실행되고 끝마쳤다. 그렇다면 이제 결과 파일을 확인해 보도록 하자.

위와 같이 결과 파일이 정상적으로 생성되었음을 알 수 있다.
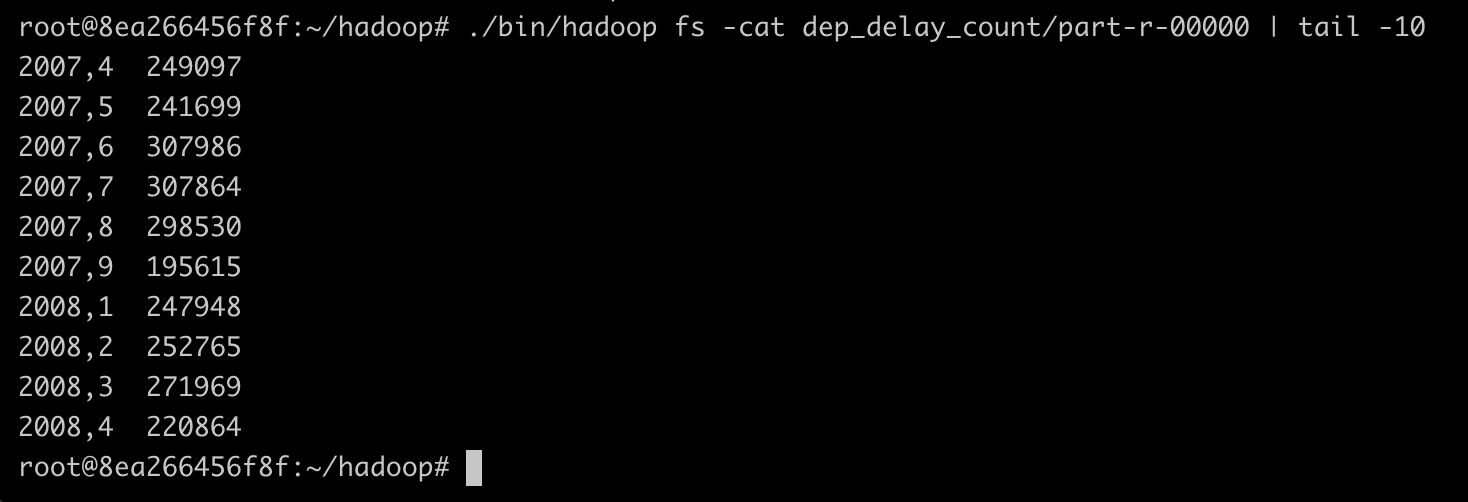
위와 같이 출력값을 정상적으로 가져왔음을 알 수 있다.
프로그램의 구조
MapReduce 프로그램의 구조는 WordCount와 상당히 유사하다.
Mapper에 입력한 데이터는 입력키가 Offset, 입력값은 항공 운항 통계 데이터이다. 출력 키는 (운항연도,운항월)이며 출력값은 출발 지연 건수이다.
Reducer의 입력키와 입력값은 Mapper의 출력키, 출력값과 동일하며 Reducer의 출력키는 (운항연도,운항월) 이고 출력값은 출발 지연 건수 합계가 된다.
총 csv 파일의 압축 해제 용량은 약 16GB이다. 그럼에도 불구하고 이 전체 데이터를 처리하여 연산하고 결과를 출력하는데 3분 남짓인 것을 확인한다면, 굉장히 효율적인 알고리즘임을 알 수 있다.
