

이 글은 드림코딩엘리 프론트엔드 필수 브라우저 101을 듣고 작성한 글입니다 ~,~
4. DOM 완전 정복
4.1 DOM 큰 그림 이해하기

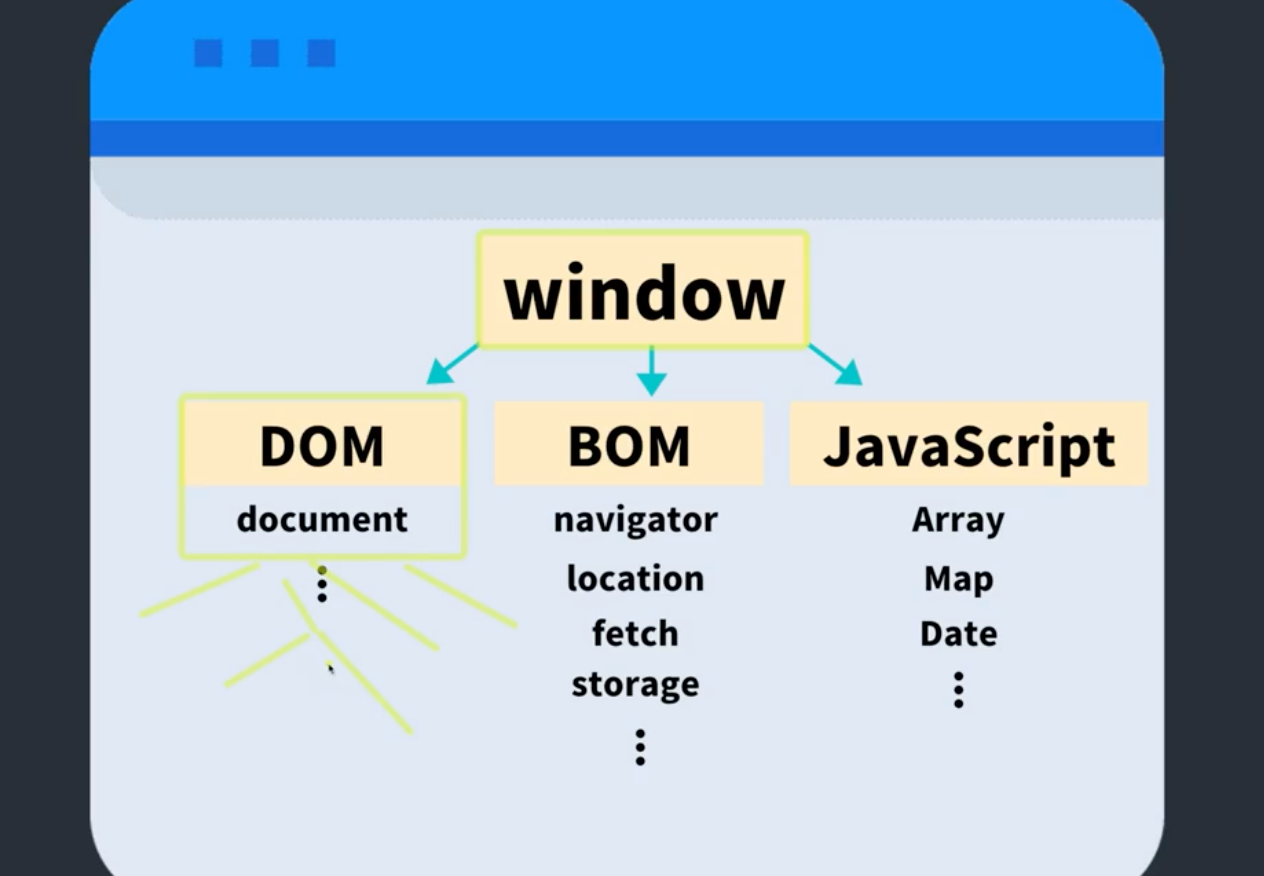
DOM은 Document Object Model의 약자이다. 우리가 간단한 웹페이지를 만들때 Html 파일을 브라우저에서 읽게된다. 브라우저는 body, section 등의 태그들을 분석해서 node로 변환하게 된다.
브라우저가 이해할 수 있는 자신들만의 object로 변환한다는 것이다.
이 node안에는 class, text 등 모든 정보들을 모두 포함하고 있다.
document도 node를 상속하기 때문에, 즉 document도 node이기 때문에, 또 node는 EventTarget이기 때문에 document에서도 Event가 발생할 수 있는 것이다!
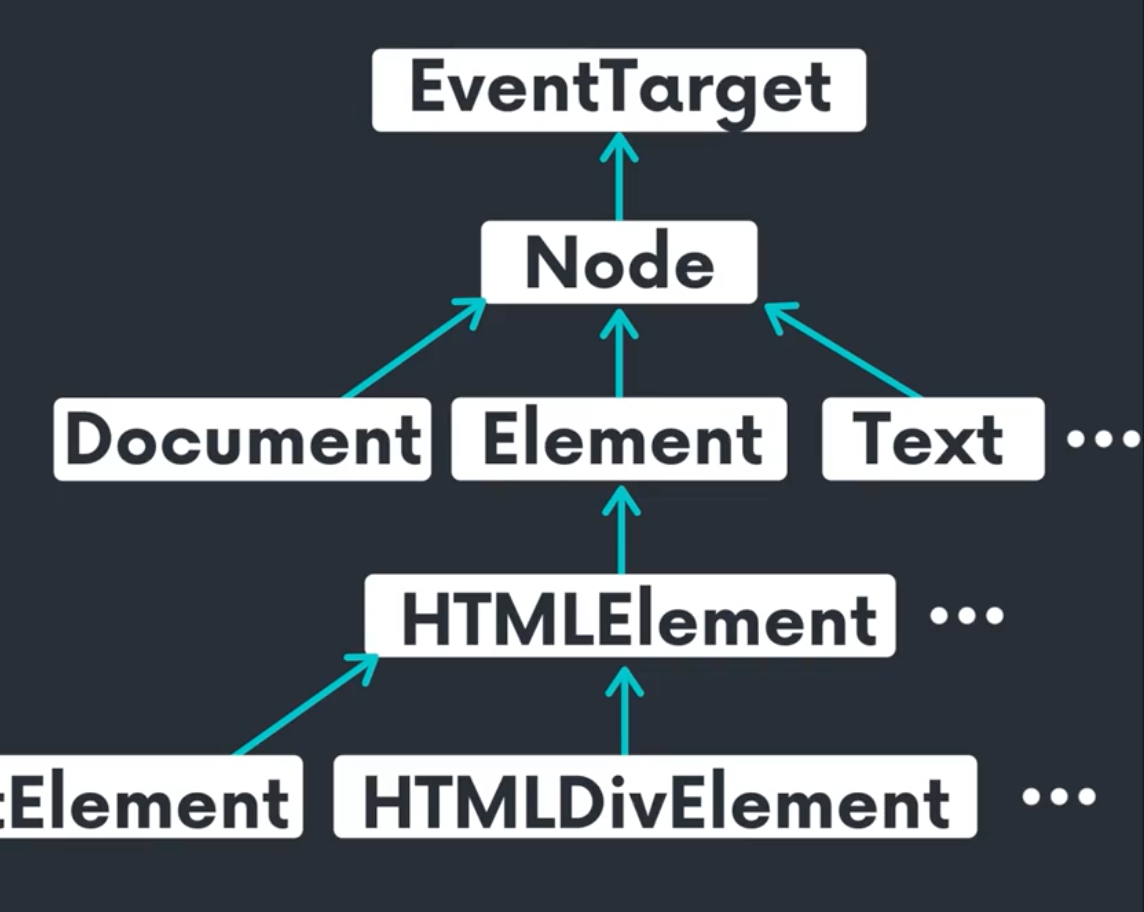
또한 이미지나 html 요소들은 element로 변환하게 되고, 똑같이 이것도 node, node는 eventtarget이기 때문에 event 발생이 가능하다!
element 안에서도 다양한 element들이 존재한다!
4.2 우리의 조상 이벤트 타겟
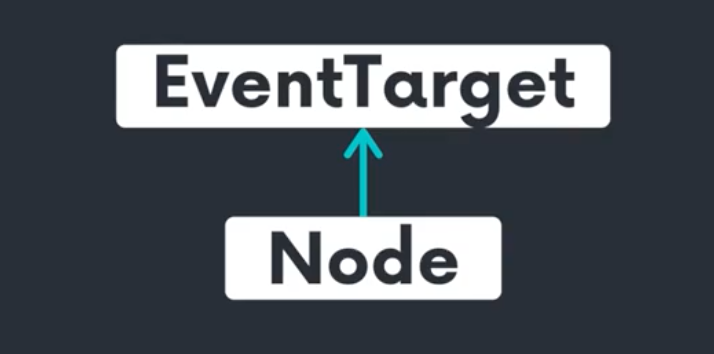
모든 node는 EventTarget을 상속한다.
EventTarget은 총 3가지의 메소드를 가지고 있다.

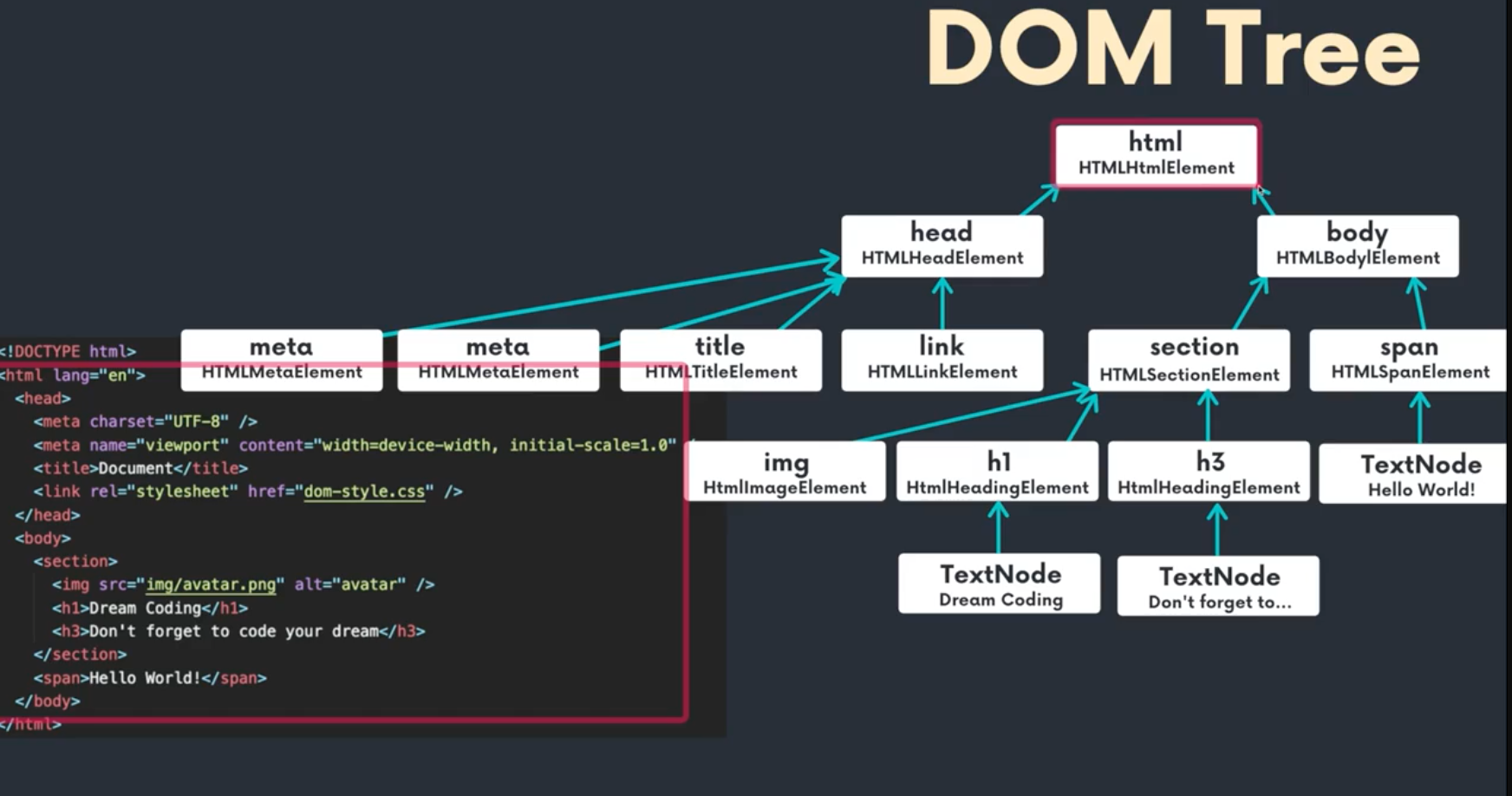
결국 브라우저가 html 파일을 이해할 수 있도록 자신들만의 오브젝트 나무로 만들어 나간다. 위 그림은 그러한 오브젝트를 tree 형태로 표현한 것이다.
처음 윈도우가 읽히면 DOM이 트리 형태로 존재하며 순차적으로 읽히게 되는 것이다.
4.3 웹페이지 요소 분석
브라우저가 HTML 파일을 읽었을 때
모든 노드는 EventTarget이고, node에는 html 부터 시작해서 다양한 요소가 존재한다.
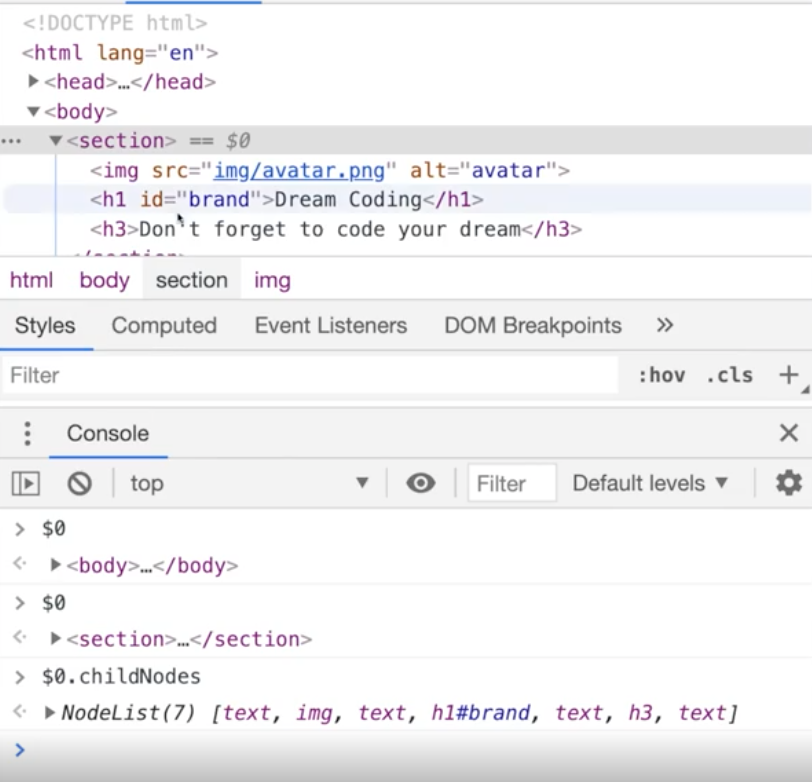
페이지 검사 창을 통해 html 부분을 확인 하는 경우
특정 요소를 클릭하면 그에 해당하는 부분을 화면에서 표시해준다. 이 특정 요소를 클릭했을 때, 옆에 보이는 == $0 이 있다. 이건 해당 요소가 현재 선택되었다는 뜻이고 콘솔창에서 이 $0를 입력하고 현재 선택된 요소의 다양한 속성들을 확인해볼 수 있다.
(약간 visual studio에서의 디버깅 툴을 보는 기분이었음!)
4.4 알면 유용한 CSSOM
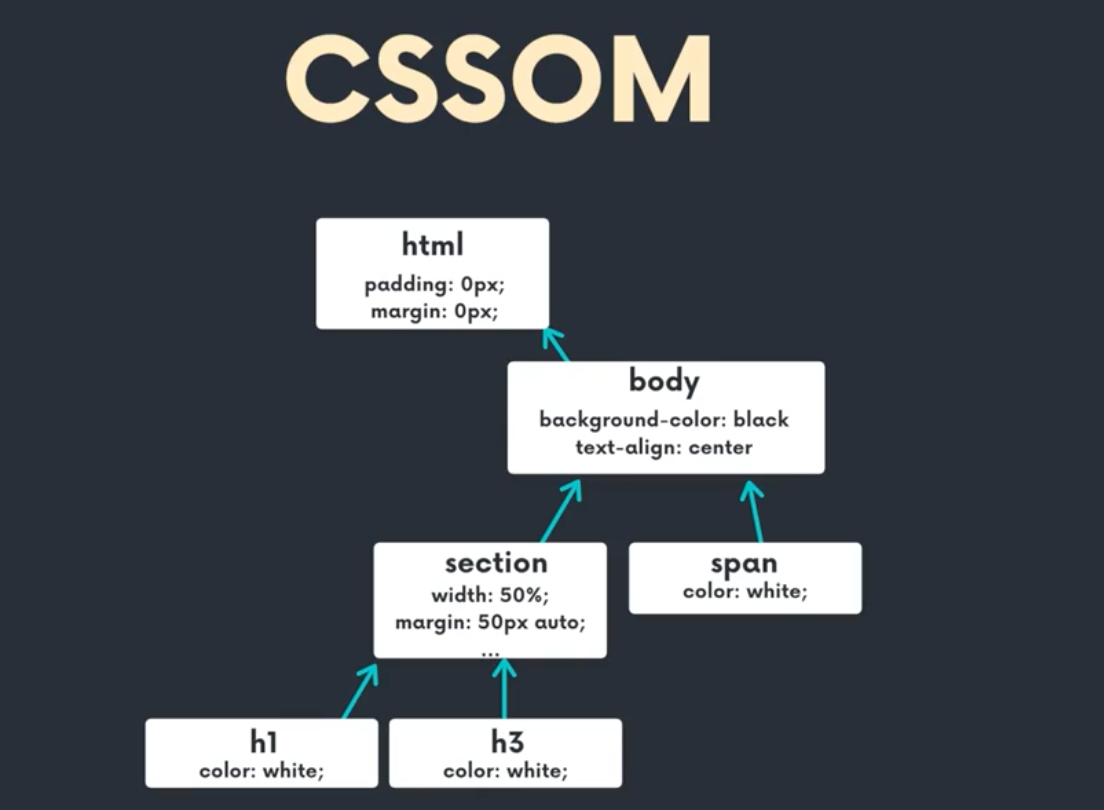
브라우저에서 DOM을 만들게 되면 우리가 정의한 CSS 를 병합해서 CSSOM으로 만들게 된다. HTML 파일안에 들어있는 embedded된 style 이나, Css 파일이나, 브라우저 상에서 기본적으로 가지고 있는 stlye 등 모든 정보를 합해서
HTML(DOM) + CSS = CSSOM을 만든다.
computed styles based on CSS cascading rules
이후
DOM + CSS 를 합하여 최종적으로 브라우저에서만 표현할 Render Tree를 만든다.
display 값이 none 인 경우 등 사용자에게 보여주지 않는 요소들을 모두 정리하고 선별하여 최종적으로 계산된 Render Tree를 만들어 보여주게 된다.
4.5 성능 보장 렌더링 순서
이 과정을 잘 이해해야 성능이 좋은 웹을 만들 수 있다.
브라우저에서 URL을 입력하면 이 순서를 따르게 된다!
request/response -> loading -> scripting -> rendering -
이는 construction과 operation 과정으로 나눌 수 있다.
DOM - CSSDOM - RenderTree - layout - paint - composition
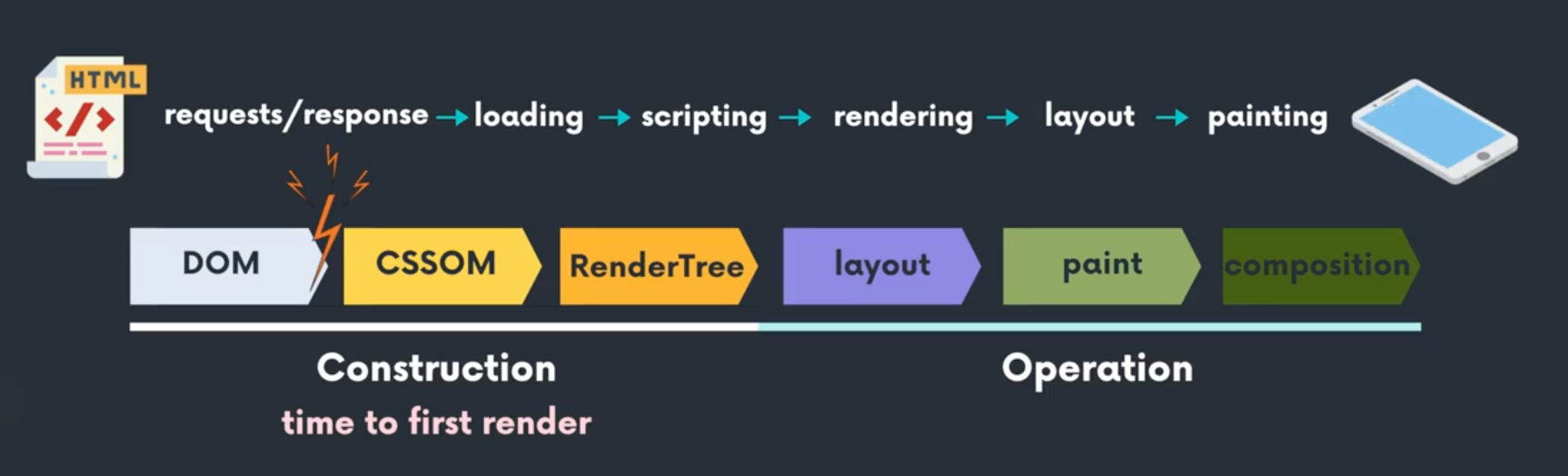
DOM - CSSDOM - RenderTree (construction)
layout - paint - composition (operation)
이 때 paint 과정에서는 바로 브라우저에 그려내는 것이 아니라 이 요소들을 어떻게 배치했냐(layout)에 따라서 각각 부분부분을 잘게 나누어서 이미지를 준비해 놓는다. 이 이미지는 컴퓨터가 읽을 수 있는 bitmap 형태로 변환하여
layout 별로 성능개선을 위해 스스로 준비 해놓는 것이다.
예를 들어 특정 부분에 투명도를 조절했다면 웹 전체를 업데이트해야하고 불러와야하지만 레이어를 나누고 변경사항이 적용되었다면 그 부분만 업데이트가 되기에 훨씬 효율적인 동기화가 될 수 있다.
4.6 모르면 후회하는 레이어 데모
will-change를 사용하면 브라우저가 다른 레이어로 표기하여 따로 만들어낸다. 그렇기에 조그마한 부분이 변경될때 will-change를 사용하면 그만큼의 레이어만 변경이 되므로 브라우저 성능을 개선시킬 수 있다.
4.7 즐겨찾기 하면 좋은 사이트
https://www.lmame-geek.com/css-triggers/
이 사이트를 통해 해당 셀렉터가 어떠한 렌더트리 과정이 필요한지를 확인 할 수 있다.
4.8 성능개선 실습
좌표 찾는 실습에서 left와 top을 이용하여 이벤트가 발생할 때마다 해당 값을
불러왔었다.
하지만 위에 사이트에서 top과 left는 무려 layout까지 바뀌면서 불러오고 있었기 때문에 너무 많은 렌더링을 일으킨다...
따라서 composition 단계에서의 변화만 발생하는 transform을 이용하여 좌표값을 불러오는 것으로 코드를 바꿔보았다!
4.9 보너스 - 퍼포먼스 개발 툴 사용하기

개발자 도구에서 performance 를 클릭
record라는 버튼을 눌러 측정하고 싶은 동작을 하면 된다.
그럼 이에 대한 profiling이 일어난다. 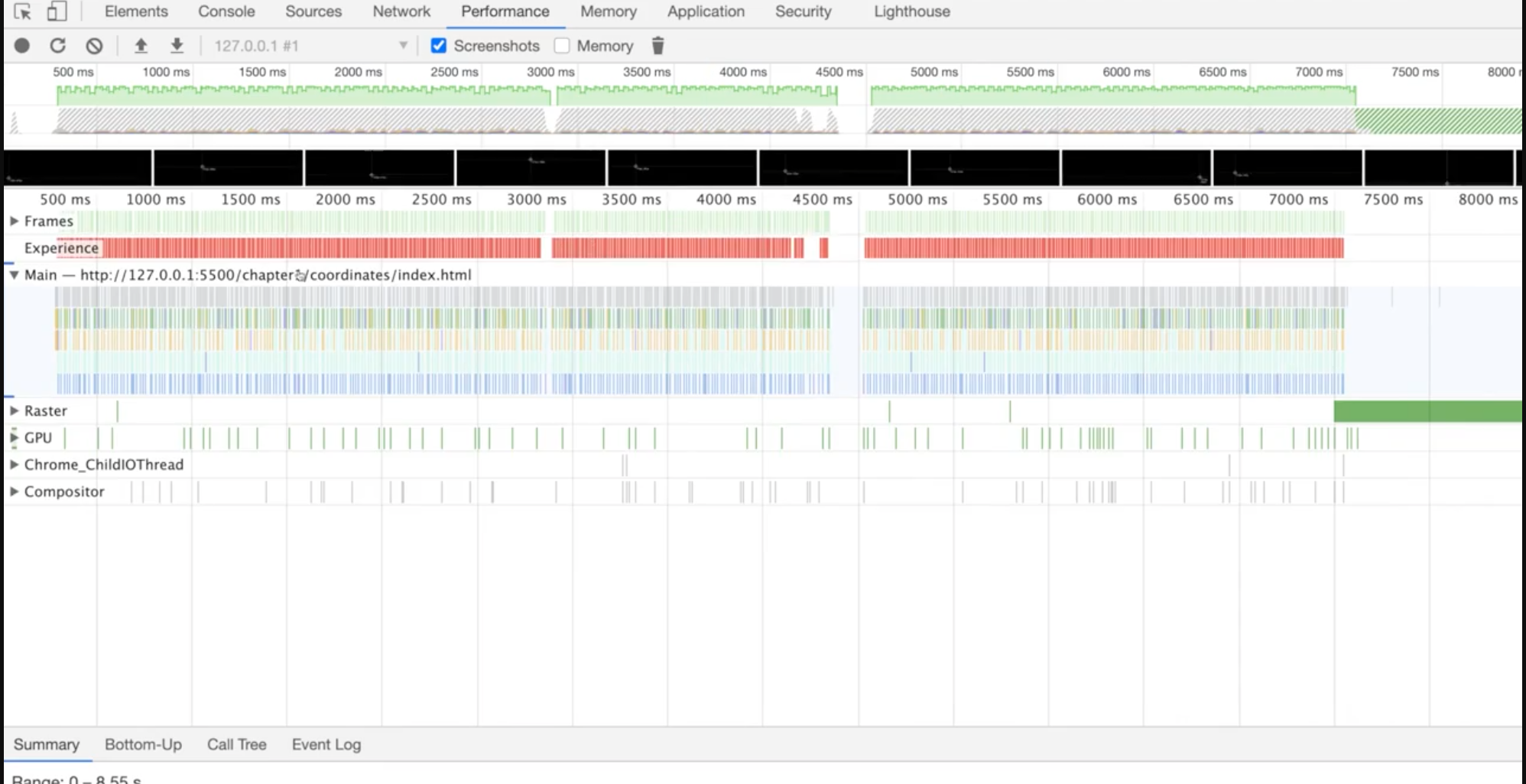
위와 같이 빨간색이 나오면 성능이 좋지 않다는 것을 의미한다.
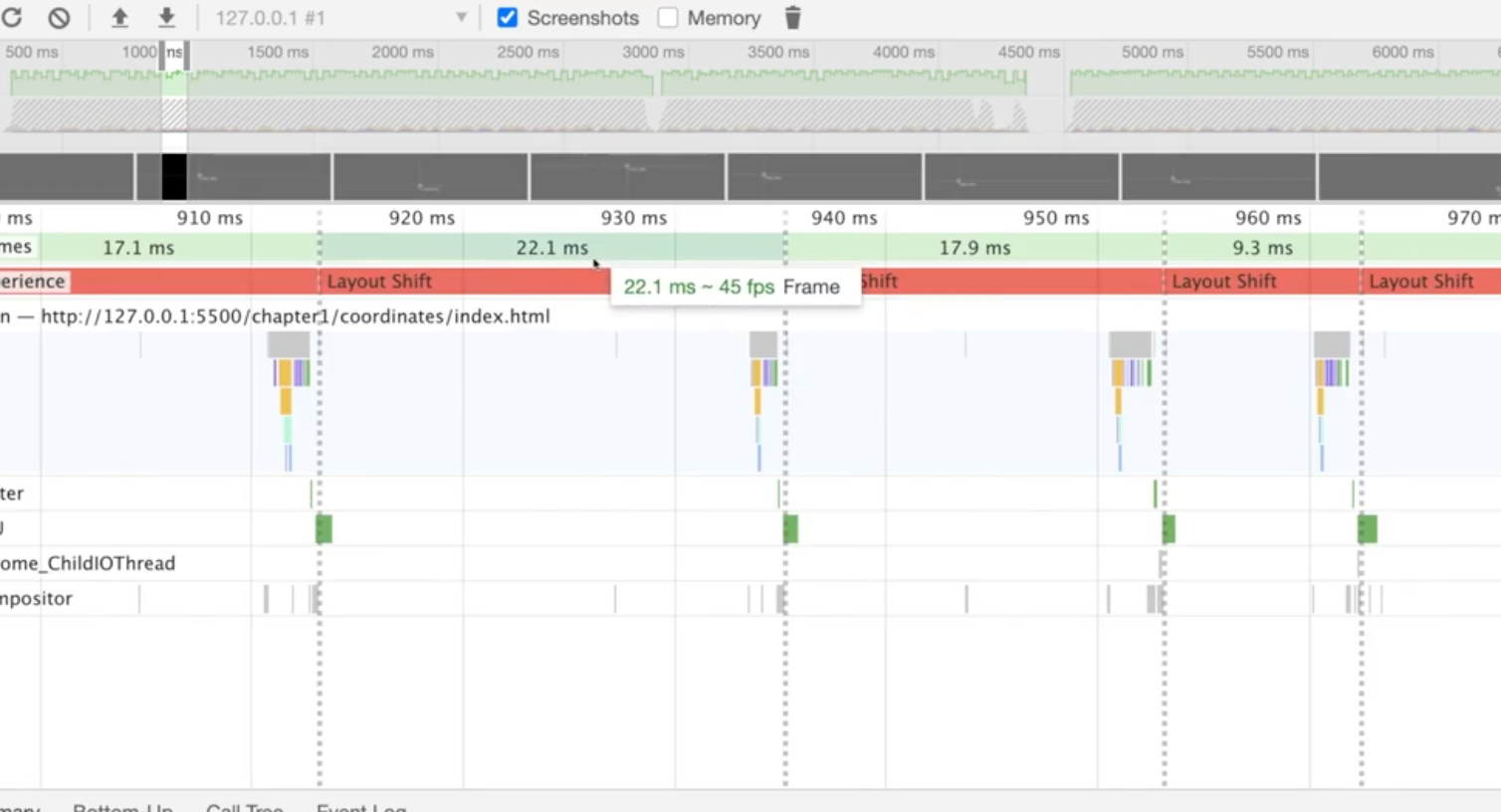
저 막대기에 커서를 가져다대면 총 어떤 일들이 발생하고, 얼마나 시간이 걸렸는지 확인해볼 수 있다. 부분적으로 마우스를 클릭하고 드래깅 하면 세부적으로 어떤 일이 발생했는지 볼 수 있다.
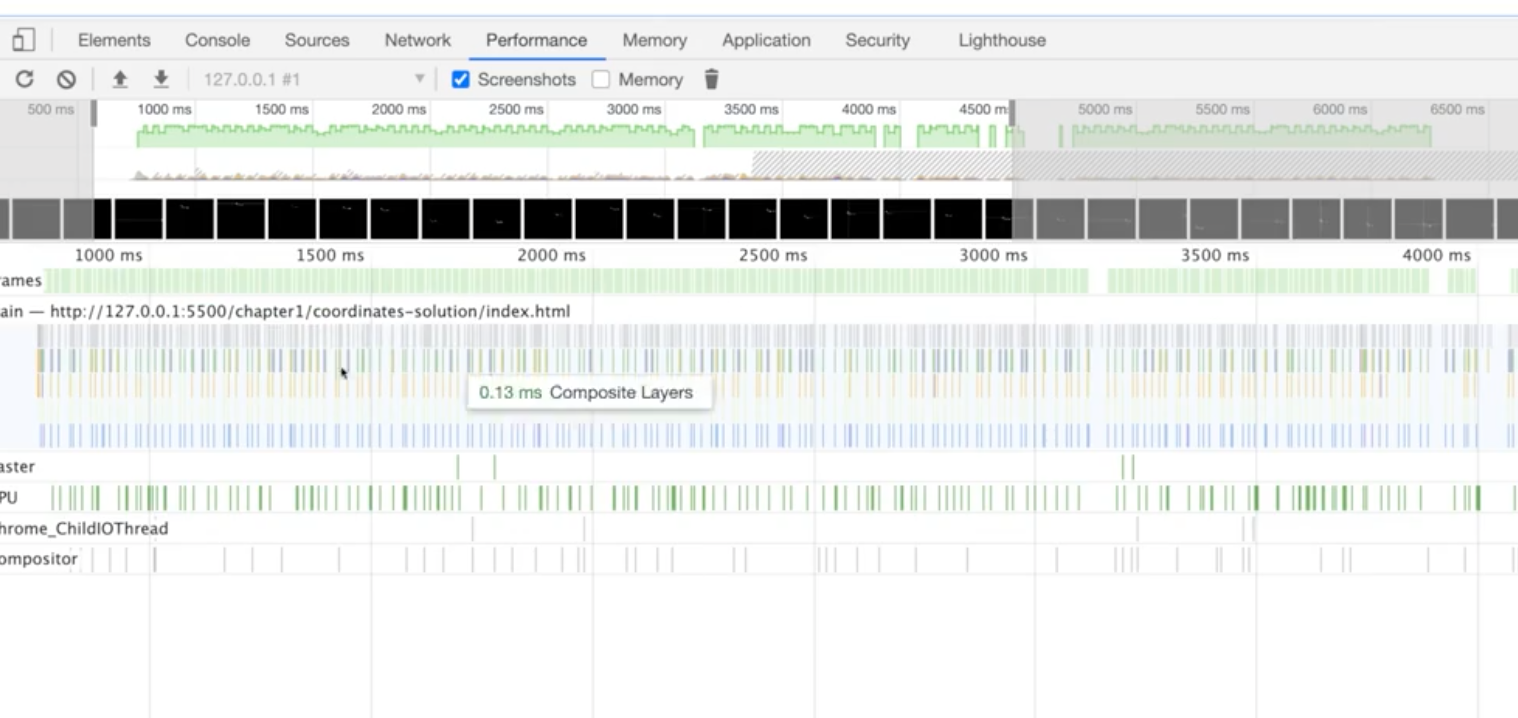
성능 개선을 통해 green field를 만드는 것이 좋다 ><
performance툴을 사용하는 것은 다음에 더 자세히 다룰 듯 하다.
4.10 DOM 조작하기
<script>
const image = document.querySelector('img');
</script>이때 querySelector는 처음에 찾아진 element를 return 한다.
이 element를 찾지 못하면 null을 리턴한다.
const image = document.getElementByID('img');원래는 주로 요 녀석을 사용해왔지만 최근에는 쿼리 셀렉터를 사용하는 것이 일반적이다.
이렇게 쓰게 되면 만약 받아올 것이 무엇인지에 따라서 매번 바꿔줘야했다.
하지만 querySelector 는 뭘 쓰는지 상관없이 동일한 api를 사용하고, 문자열에서 더 막강하며 클래스라면 '.클래스이름' , 아이디라면 '#아이디이름', 그리고 조금 더 복잡하게 'img[src="img/avatar.png"]' 식으로 해당하는 태그를 가져오기도 한다.
어쨌든 가장 처음으로 발견된 것을 가져온다.
querySelectAll()을 사용하면 가져오고 싶은 document의 모든 요소를 가져온다!
const h2=document.createElement('h2');
h2.setAttribute('class', 'title'); //<h2 class="title"><h/2>
h2.textContent = 'This is a title; //<h2 class="title">This is a title</h2>
section.appendChild(h2);
setAttribute를 이용하여 새로운 속성을 직접 세팅할 수도 있고, textContent와 같이 그 값을 지정하여 입력해줄 수도 있다.
이 값들을 appendChild()를 써주면 그냥 값을 넣어주는 거나 마찬가지다...
또한 section.insertBefore(h2, h3) 를 사용하면 우리가 추가하고자 하는 Parent container box에 새로 추가할노드, 참조노드 파라미터로 전달해주면 새로추가되는 노드가 지금 있는 태그 앞에 들어오게 할 수있다. 즉, h3전에 h2가 들어온다는 것이다.
4.11 innerHtml vs Element 뭘 쓰지?
innerHtml

소스 검사에서 $0를 이용해 innerHTML을 확인하면 section안에 들어간 모든 태그들이 다 보인다.
innerHtml을 사용하면 element를 사용하여 setAttribute, insertBefore 등을 사용하지 않고도 그때 그때 태그를 추가해줄 수 있지만 부분적으로 반영해야할 때만 사용하는게 효율적이다.
~~ 캡처이미지는 문제시 삭제 ~~
