(딥러닝 전공하기 전에 쓴 글인데 귀엽네)
기계학습은 컴퓨터에게 코딩하지 않은 동작을 배우고 실행할 수 있도록 하는 능력(Arthur Samuel:1959) 이라고 정의 되었다.
어떻때 기계학습이 사용되는가?
이메일 스팸 필터를 생각해보자. 어떤 이메일이 스팸인지 알아내기 위해, 특정 단어가 들어가면 스팸이라고 판단하게 할 수 있다.
즉, 블랙리스트 기법으로 간단하게 구현이 가능하다.
my $email="안녕 이건 광고가 없는 이메일이야";
print "이건 광고야!!" if($email=~/(광고)/g);$>perl main.pl
이건 광고야!!바로 위와 같이 말이다. 하지만 위의 예시는 광고가 없는 이메일이라고 한건데, 스팸필터에 걸렸고 정작 진짜 광고는 다음과 같이 온다.
my $email="광.고 서대문구에서 파는 짝퉁 금시계가 단돈 38900원!!";이건 잡아 내지도 못한다.
따라서 우리는 기계학습으로 이러한 문제를 해결해야 한다. 광고인 메일들과 광고가 아닌 메일들을 나누어, 기계보고 스스로 학습시키는 것이다.
이런 데이터를 training data 라고 하는데, 이 메일필터같은 경우는 학습할때 각 메일이 스팸인지 아닌지를 구분해야하므로
데이터 X->Y 에 대응되는것, 즉! 라벨(Y)가 주어저야 한다. 이러한 학습 기법을 supervised learning 이라고 한다.
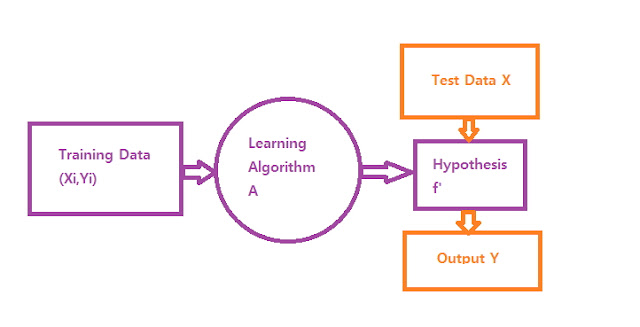
이러한 기계 학습이 하는일은 주어진 데이터 X 와 각 데이터에 대응하는 실제 현상 Y 에 대한 관계 함수 f 를 찾는 과정과 같다.
f 와 최대한 비슷한 함수 f'을 찾기 위해 입력 데이터들에 대해 가정을 하고, 그 가정에 따라 주어진 데이터를 잘 설명하는 f'를 찾는다.
이런 f'을 Hypothesis 라고 한다.
기계학습을 하기위해선 아래의 것들이 필요하다.
- Set of possible instance(domain):X
- Output : Y
- Unknown target function f: X -> Y
- Set of hypothesis function space H ⊂ {h|h:X->Y}
Input
- Training data {xi,yi}
Output
- h ∈ H that best approximates target function f with some performance measure
위 설명을 간단하게 그림으로 표기하면 아래와 같다.
반면 사진분류를 생각해보자 이는 비슷한 사진끼리 군집을 모은다.(Clustering)
이는 고양이 사진마다 전부 이건 고양이야!! 라고 라벨을 지정할 수 없으므로, 비슷한 군집끼리 모으는 작업이 필요하다.
이렇듯 라벨이 없는 학습 기법을 unsupervised learning 이라고 한다.
대표적 예시는 아래 그림과 같은 클러스터링이다.

이렇듯 기계학습에는 다음과 같은 종류들이 있다.
- Supervised Learning (지도학습)
- Unsupervised Learning (비지도학습)
- Semi-supervised Learning (준지도학습)
- Reinforcement Learning (강화학습)
변경 이력
- 2016년 6월 10일: 글 등록
References
