링크드 리스트에 대해 모르는 사람은 이 글을 읽기 힘들 수 있다.
리스트 구현법애 대해 소개하므로, 소스코드가 매우 많이 나오게 된다.
컴공과 학부생 2학년이면 배우는 내용이므로 누구나 배우지만, 누구나 제대로 써먹지 못하는 자료구조인 링크드 리스트에 대해 심도 있게 깊게 공부해보자!.
링크드 리스트는 크게 4가지 연산이 있고 (추가,삽입,삭제,검색) 이러한 연산은 Array List와 항상 대조 된다.
(ArrayList, vector, DynamicArray 모두 같은 말이다. 나는 이러한 배열 기반 선형 자료구조를 앞으로 벡터라고 칭하겠다.)
아래 표는 링크드 리스트와 벡터의 시간복잡도 표이다.
| 구분 | 추가 | 삽입 | 삭제 |
|---|---|---|---|
| vector | O(1) | O(n) | O(n) |
| Linked List | O(1) | O(1) | O(1) |
단순히 표만 보자면 리스트가 벡터에 비해 압도적이다, 하지만 실제로 벡터가 더 많이 사용된다.
벡터의 장점은 벡터의 파트에서 알아보도록 하고, 이번 포스팅에서는 벡터와 리스트의 비교와 리스트의 장 단점에 대해 알아볼 것이다.
이 장에서는 리스트를 이용한 스택,큐,덱 등은 이후에 살펴보고 리스트의 단점을 보완, 어떻게 개선하는지 알아볼것이다.
==단일 연결리스트의 일반적인 구현==
#include<malloc.h> //malloc
#include<stddef.h> //NULL
typedef struct tagNODE NODE;
struct tagNODE{
int data;
NODE* next;
};
void push_back(NODE** head, int value) {
NODE** n = head;
while (*n)
n = &(*n)->next;
*n = (NODE*)malloc(sizeof(NODE));
(*n)->data = value;
(*n)->next = NULL;
}단일 연결리스트에도 물론 tail을 만들순 있다. 실제로 저렇게 멍청하게 복잡도가 O(n)이 되는 추가함수를 구현하지는 않는다.
다만 처음 배울때 저런 알고리즘으로 배우는데, 나는 저런식으로 배웠다.
(멍청하게 head가 NULL일때와 아닐때를 나누어서 코딩을 한 자신을 돌이켜보라는 뜻에 올린다)
tail을 추가한다면 소스는 아래와 같이 바뀌게 된다.
==단일 연결리스트의 tail이 있는 구현==
typedef struct tagNODE NODE;
struct tagNODE{
int data;
NODE* next;
};
typedef struct tagLIST{
NODE* head;
NODE* tail;
}LIST;
void push_back(LIST* list,int value) {
NODE* n = (NODE*)malloc(sizeof(NODE));
n->data = value;
n->next = NULL;
if (list->tail){
list->tail->next = n;
list->tail = list->tail->next;
}
else{
list->head = list->tail = n;
}
}여기서는 tail이 NULL일때와 아닐때를 나눌 수 밖에없다. 더 좋은 방법이 있다면 댓글로 알려주길 바란다.
LIST구조체를 만든 이유는 너무 당연하다. 같이 몰려다니는 데이터를 쉽게 사용하기 위해서 나온게 구조체 struct 아닌가? head와 tail이 따로 다닐 이유가 없기때문에 만들었다.
여기까지만 해도 이해하기 쉽다. 물론 삽입,검색,삭제 등은 구현하지 않았지만 너무 간단하기에 생략한다.
이제 추가의 복잡도가 O(1)이 되었다.
단일 연결 리스트의 단점이 뭘까? 당연하다. 순회알고리즘에서, 뒤로갈수 없다는 뜻이다.
뒤로 이동할수 없다는것은 엄청난 알고리즘적 손해를 가져온다. 가령 삭제에서 복잡도가 O(n)이 나오게 된다던가(삭제 자체에서 검색을 하지 않는경우) , (insert before를 구현할수 없다던지....)
말해봐야 뭐하겠는가, 불편한것은 여간 한 두가지가 아니다.
따라서 뒤로 이동할수 있는 prev를 추가해보자, 아주 간단하다.
==이중 연결리스트의 일반적인 구현==
typedef struct tagNODE NODE;
struct tagNODE{
int data;
NODE* next;
NODE* prev;
};
typedef struct tagLIST{
NODE* head;
NODE* tail;
}LIST;
void push_back(LIST* list,int value) {
NODE* n = (NODE*)malloc(sizeof(NODE));
n->data = value;
n->next = NULL;
n->prev = list->tail;
if (list->tail){
//C언어는 우측항부터 계산한다. n을 먼저 list->tail->next에 넣고 그 값을 list->tail에 넣는다.
//그로 인해 이렇게 한줄로 표현이 가능하다.
list->tail = list->tail->next = n;
}
else{
list->head = list->tail = n;
}
}단 두줄만이 추가되었다. 이것으로 이중연결리스트를 구현하였다. (짝짝짝)
연결 리스트와 벡터의 비교
추가 연산에 대해 어떤 자료구조가 더 빠를까?
답은 당연히 벡터다.(원소의 크기가 작다면)
연결 리스트는 매번 메모리 할당을 해야하고, 이는 속도 저하로 이어진다. 반면 벡터의 시간복잡도는 T(2) 이다.
(이 부분은 벡터의 포스팅에서 설명함)
다만, 벡터의 추가 연산에 대해 알고있겠지만, 메모리복사(이동)의 리스크가 크다.
원소의 크기가 크다면 더 많은 메모리를 복사할테고 이는 곧 다음의 공식을 야기한다.
==벡터는 원소의 크기가 커질수록 재할당시간이 느려진다==
반면 리스트는 재할당을 하지않으므로 언제나 일정한 시간을 가진다.
제네릭? Generic?
제네릭 프로그래밍, C++ 에서는 템플릿 프로그래밍...
C언어에서는 제네릭한 타입을 쓸때 void* 를 사용한다.
간단한 제네릭 버전의 리스트를 살펴 보자.
==제네릭 연결리스트의 멍청한 구현==
#include<malloc.h> //malloc
#include<stddef.h> //NULL , size_t
#include<memory.h> //memcpy
#include<stdio.h> //printf, putchar
#include<stdlib.h> //EXIT_SUCCESS
#pragma pack(push,4)
typedef struct tagNODE NODE;
struct tagNODE{
void* data; //void* 타입의 자료형
NODE* next;
NODE* prev;
}
#if defined(__linux__) || defined(__GNUC__)
__attribute__((aligned(sizeof(long))))
#endif
;
typedef struct tagLIST LIST;
struct tagLIST{
NODE* head;
NODE* tail;
size_t type_size; //타입의 크기를 저장하는 변수
}
#if defined(__linux__) || defined(__GNUC__)
__attribute__((aligned(sizeof(long))))
#endif
;
#pragma pack(pop)
void push_back(LIST* list,void* value) {
NODE* n = (NODE*)malloc(sizeof(NODE));
//데이터를 할당하기 위해서 2번의 malloc
n->data = malloc(list->type_size);
//데이터 복사
memcpy(n->data, value, list->type_size);
n->next = NULL;
n->prev = list->tail;
if (list->tail)
list->tail = list->tail->next = n;
else
list->head = list->tail = n;
}
int main() {
int i;
LIST list = { NULL, NULL ,sizeof(int)};
for (i = 0; i < 10; i++){
//값을 넘겨줄때는 주소로 넘겨준다.(따라서 상수는 전달 불가)
push_back(&list, &i);
}
printf("%lu %lu\n", sizeof(NODE), sizeof(LIST));
NODE* it = list.head;
while (it){
printf("%d ", *(int*)it->data);
it = it->next;
}
putchar('\n');
return EXIT_SUCCESS;
}갑자기 소스가 어려워졌다고 종료창 누르지말자. 알고보면 별거 아니다.
==#pragma pack(push,4)== 는 visual C++에서 구조체의 padding을 4로 지정하겠다는 뜻이다. #pragma pack(4)로 사용했었다면 이젠 그러지 말자.
이유는 간단하다. 우리는 어떤 헤더파일이 먼저 컴파일 되는지 잘 알지 못한다. 물론 따져보면 알수 있겠지만, 내가 원하지 않은 구조체마저 padding이 4로 변경되는건 원치않은 행동이므로, 반드시 #pragma pack(push,4) 와 #pragma pack(pop) 으로 영역을 지정하여 구조체의 패딩을 지정 하도록 하는 습관을 가지자.
==#if defined(__linux__) || defined(__GNUC__)== 는 리눅스OS와 GCC 컴파일러에서 사용하겠다는 뜻이다.
이 블록사이에 있는 구문은 다른 환경(예를들면 VC++) 에서 사용하면 오류가 뜬다.
Q.왜 #pragma pack() 은 그럼 안감쌋나요?
A. 기본적으로 컴파일러는 모르는 전처리기가 나오면 무시하고 넘어가기 때문에 감싸주지 않아도 된다.
컴파일러,운영체제등 에 따른 미리 정의된 매크로를 보려면 http://beefchunk.com/documentation/lang/c/pre-defined-c/ 으로 이동해 볼 수 있다.
이게 내가 말하던 제네릭 프로그래밍은 아니다. 다만 내가 사용하는 VC++, GCC, Linux OS 등의 호환을 위한것이다. 구조체 패딩이 뭐가 중요하냐고 하겠지만, 중요하다. 뒤로 가면 이것을 사용하는곳이 나온다. 무시하지말고 익히고 넘어가자.
==__attribute__((aligned(sizeof(long))))== 이 구문은 Linux 시스템, GCC 컴파일러에서 구조체의 패딩을 지정하는 구문이다.
long의 크기로 맞추어 주었는데, 사실 long에 맞추는것이 아니라 포인터의 크기에 맞춘다고 보면된다.(사실 그게 그거)
앞선 pragma pack 에서는 4로 맞추어 주었는데, Windows에서는 x86 이던지 x64이던지 포인터의 크기가 4바이트이기 때문에 4로 지정하였다.
장점은 모든 데이터타입을 지원한다는 점이며, 그게 끝이고
단점은 상수(예를들면 숫자 4) 같은건 넣을수 없다.
또한 가장 큰 단점은 노드를 만드는데 2번의 malloc을 한다는 점이다.
이건 문제가 조금 심각하다. 한번의 malloc도 속도가 느린데 이걸 2번이나 하면 2배로 느려지고 메모리 페이징도 있기때문에 메모리 낭비도 더 크다.
아주 간단한 문제이고, 우리는 이 문제를 간단하게 해결할 수 있다.
==제네릭 연결리스트의 over alloc 구현==
#include<malloc.h> //malloc
#include<stddef.h> //NULL , size_t
#include<memory.h> //memcpy
#include<stdio.h> //printf, putchar
#include<stdlib.h> //EXIT_SUCCESS
#pragma pack(push,4)
typedef struct tagNODE NODE;
struct tagNODE{ //데이터를 담아두는 변수를 따로 저장하지 않는다.
NODE* next;
NODE* prev;
}
#if defined(__linux__) || defined(__GNUC__)
__attribute__((aligned(sizeof(long))))
#endif
;
typedef struct tagLIST LIST;
struct tagLIST{
NODE* head;
NODE* tail;
size_t type_size; //타입의 크기를 저장하는 변수
}
#if defined(__linux__) || defined(__GNUC__)
__attribute__((aligned(sizeof(long))))
#endif
;
#pragma pack(pop)
void push_back(LIST* list,void* value) {
//원소를 같이 추가해서 할당
NODE* n = (NODE*)malloc(sizeof(NODE) + list->type_size);
memcpy(n+1, value, list->type_size);
n->next = NULL;
n->prev = list->tail;
if (list->tail)
list->tail = list->tail->next = n;
else
list->head = list->tail = n;
}
int main() {
int i;
LIST list = { NULL, NULL ,sizeof(int)};
for (i = 0; i < 10; i++){
push_back(&list, &i);
}
printf("%lu %lu\n", sizeof(NODE), sizeof(LIST));
NODE* it = list.head;
while (it){
//원소를 가져오는 방식에 유의
printf("%d ", *(int*)(it+1));
it = it->next;
}
putchar('\n');
return EXIT_SUCCESS;
}두번의 malloc을 한번의 malloc으로 바꾸었다. NODE는 prev와 next만을 가지지만, 노드를 할당할시 데이터를 추가로 할당하는 방식이다.
NODE* + 1로 데이터영역에 접근이 가능하며, 오직 C언어에서만 가능한 방법이다.
노드 기반 자료구조에서 제네릭한 방법은 이제 이렇게 사용한다. void*를 사용하지 않는다.
리눅스 커널에서의 제네릭 연결리스트는 이렇게 구현되어있지 않다. 다만 리눅스 커널의 연결리스트는 인터페이스가 색달라 사용하기가 조금 꺼려진다.
두 구현방식 모두 한번의 malloc을 사용한다.

위 그림을 보면 쉽게 이해가 갈 것이다.
이제 잠시 리스트의 함수 구현을 보자.
push_back 과 push_front는 사실 대칭 함수다.
push_back 에 있는 tail을 head로 head는 tail로 , next는 prev로 prev는 next로 바꿔주기만 하면된다.
멍청하게 이런 코드를 따로 짤것인가? 일반화를 시킬것인가? 매크로를 쓰지 않고 단순한 주소 연산으로 이를 구현할 수 있다.
==push_back과 push_front를 일반화 시킴==
#pragma pack(push,4)
typedef struct tagNODE NODE;
struct tagNODE{
NODE* next;
NODE* prev;
#define GETNODEDATA(N,TYPE) *(TYPE*)(N+1)
//노드에서 얼마만큼 점프해 접근할지를 지정
//(반드시 구조체 패딩이 포인터의 배수여야함)
#define NODE_TO(N,TO) *((NODE**)(N)+(TO))
}
#if defined(__linux__) || defined(__GNUC__)
__attribute__((aligned(sizeof(long))))
#endif
;
typedef struct tagLIST LIST;
struct tagLIST{
NODE* head;
NODE* tail;
size_t type_size; //타입의 크기를 저장하는 변수
}
#if defined(__linux__) || defined(__GNUC__)
__attribute__((aligned(sizeof(long))))
#endif
;
#pragma pack(pop)
void push(NODE** head, NODE** tail, size_t type_size, void* value, size_t next, size_t prev) {
NODE* n = (NODE*)malloc(sizeof(NODE)+type_size);
memcpy(n + 1, value, type_size);
NODE_TO(n, next) = NULL;
NODE_TO(n, prev) = *tail;
if (*tail) *tail = NODE_TO(*tail, next) = n;
else *head = *tail = n;
}
void push_back(LIST* list, void* value) {
push(&list->head, &list->tail, list->type_size, value, 0, 1);
}
void push_front(LIST* list, void* value) {
push(&list->tail, &list->head, list->type_size, value, 1, 0);
}매크로를 사용하여 좀더 사용하기 쉽게 접근 하였다.
next를 prev로 바꿔주고 prev를 next로 바꿔주기만 하면 되는 문제인데, 이것을 주소 점프 연산을 통해 일반화 시켰다.
주석에도 써있지만, 원래 주소연산을 다룰려면 (char*)로 형변환을 해야하는데, 구조체 패딩이 포인터의 배수라면 이처럼 0과1로 해도 상관없다.
아마 이 내용을 쉽게 이해하려면 포인터에 대한 깊은 이해가 있어야 한다.
잘 모르겠다면 그림을 그려서 꼭 이해하길 바란다.
push_front는 실제 tail이 head라고 생각하고 프로그래밍 하는걸로 생각하면 이해하기 쉽다.
LIST는 고정객체이기 때문에 위 처럼 2중포인터로 넘겨서 해결이 가능하지만, NODE는 여러개이기 때문에 위처럼 주소점프연산을 통해 해결한다.
여전히 단점은 숫자4 와 같은 기본상수를 인자로 넘길수 없다는 점이다.

템플릿을 이용한 제네릭 방법
미안하다. 사실 C언어에서는 템플릿이란 없다. 템플릿이 무엇인가? 해당 자료형으로 대체하는 소스를 통채로 만드는 C++에서의 제네릭 프로그래밍 기법이다.
C에서는 define 으로 템플릿을 구현할 수 있다.
단순한 define이 아닌 많은 기법들이 들어가 있으니 이해하고 넘어가길 바란다.
- C언어에서는 ## 은 앞과 뒤를 이어주는 역할을 한다.
- 실제 C++의 템플릿과 똑같다.
- ==이제 숫자 4와같은 기본 상수도 인자로 넘길 수 있다.==
- 해당 자료형에 최적화된 소스가 생성된다.
- 매크로를 2줄 이상 쓰려면 끝에 (back slash) 문자를 써준다.
==template 연결 리스트 main.c==
#include<stdio.h>
#include"tlist.h" //template list
#ifndef __TLIST_int
#define __TLIST_int
CREATE_LIST(int)
#endif
int main() {
TLIST_int a = NEW_TLIST_int();
a.push_back(a,2);
a.push_back(a, 5);
a.push_back(a, 1);
a.push_back(a, 3);
a.push_back(a, 4);
TLISTNODE_int* it = a._c->head;
while (it){
printf("%d ", it->data);
it = it->next;
}
putchar('\n');
return 0;
}==template 연결 리스트 tlist.h==
#if !defined(DATA_STRUCTURE_TEMPLATE_LIST_H_7DE_06_0F_INCLUDED)
#define DATA_STRUCTURE_TEMPLATE_LIST_H_7DE_06_0F_INCLUDED
#include<stddef.h> //size_t, NULL
#include<malloc.h> //malloc
#include<memory.h> //memcpy
#undef ATTACH2
#undef ATTACH3
#define ATTACH2(A,B) A##B
#define ATTACH3(A,B,C) A##B##C
typedef struct tagTLISTNODE{
struct tagTLISTNODE* prev;
struct tagTLISTNODE* next;
#define GETNODEDATA(N,TYPE) *((TYPE*)(N+1))
}TLISTNODE;
typedef struct tagTLIST{
TLISTNODE* head;
TLISTNODE* tail;
size_t length;
}TLIST;
#define CREATE_LIST(TYPE)\
typedef struct ATTACH3(tag, TLISTNODE_, TYPE) ATTACH2(TLISTNODE_, TYPE);\
struct ATTACH3(tag, TLISTNODE_, TYPE) {\
ATTACH2(TLISTNODE_, TYPE)* prev;\
ATTACH2(TLISTNODE_, TYPE)* next;\
TYPE data;\
};\
typedef struct ATTACH3(tag, TLISTPRIVATE_, TYPE) ATTACH2(TLISTPRIVATE_,TYPE);\
struct ATTACH3(tag, TLISTPRIVATE_, TYPE) {\
ATTACH2(TLISTNODE_, TYPE)* head;\
ATTACH2(TLISTNODE_, TYPE)* tail;\
size_t length;\
};\
typedef struct ATTACH3(tag, TLIST_, TYPE) ATTACH2(TLIST_, TYPE);\
struct ATTACH3(tag,TLIST_,TYPE){\
ATTACH2(TLISTPRIVATE_, TYPE)* _c; \
void(*push_back)(ATTACH2(TLIST_, TYPE) obj,TYPE value);\
};\
void ATTACH3(TLIST_, TYPE, _push_back)(ATTACH2(TLIST_, TYPE) obj, TYPE value){\
ATTACH2(TLISTNODE_, TYPE)* n = (ATTACH2(TLISTNODE_, TYPE)*)malloc(sizeof(ATTACH2(TLISTNODE_, TYPE))); \
n->data=value;\
n->next=NULL;\
n->prev=obj._c->tail;\
if (obj._c->tail)obj._c->tail = obj._c->tail->next = n; \
else obj._c->head = obj._c->tail=n;\
obj._c->length++;\
}\
ATTACH2(TLIST_, TYPE) ATTACH3(NEW_, TLIST_, TYPE)(){\
ATTACH2(TLIST_, TYPE) list; \
list._c = (ATTACH2(TLISTPRIVATE_, TYPE)*)malloc(sizeof(ATTACH2(TLISTPRIVATE_, TYPE))); \
list._c->head=list._c->tail=NULL;\
list._c->length=0;\
list.push_back = ATTACH3(TLIST_, TYPE, _push_back);\
return list;\
}\
#endif자 이제 해당 tlist.h에 대한 설명을 하겠다.
CREATE_LIST() 라는 매크로 함수에 타입을 넣으면 해당 리스트(구조체 부터 함수까지!!) 모두 생성되는 매크로이다.
또한 구조체 안에 함수포인터를 넣어서 C에서 간단한 객체지향을 구현하였다.
_c인 리스트를 왜 굳이 포인터 타입으로 만들었냐면, 이 리스트를 함수의 파라매터로 넘길때와, 멤버함수의 첫번째 인자로obj를 넣어줘야하는데
(C++에서 this 에 해당함)
매번 주소연산자를 붙이기도 귀찮기 때문에, 이렇게 처리 하였다. 이 아이디어는 Win32api의 HFONT나 HWND등에서 아이디어를 얻어왔다.
windows 프로그래밍을 하다 보면 MS의 기발한 방법들에 감탄할 수 있다. (리누스 토발즈가 이 글을 싫어합니다)
사실 알아보기 힘든것만 빼면 원리는 쉽다. 짜기가 어려워서 그렇지....
- 두 어절로된 자료형은 추가할수 없다 ex) long long 등과 같은...
- typedef long long lld; 로 바꾸어 사용하도록하자.
#ifndef#endif는 생략할 수 없다. (매크로 안에 매크로를 넣을수 없다) 별의 별 방법을 다 해봤는데 안된다.
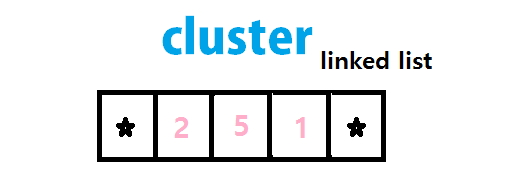
###클러스터를 이용한 개선
만일 리스트의 노드가 여러개의 데이터를 저장할 수 있으면 malloc 횟수가 더 줄어들지 않나?
그렇다 이 발상이 이 아이디어를 생각하게 만들었다. 실제로 이진트리를 이런 방식으로 개선한것이 2-3 트리이다.
어떻게 노드 안에 데이터를 여러개 만들 수 있을까?
앞서 봤던대로
n=(NODE*)malloc(sizeof(NODE) + type_size*3);과 같이 적으면 하나의 노드에 3개의 데이터를 넣을 수 있게되며, 리스트에 데이터를 n개 넣을때 malloc 호출 횟수를 n/3으로 줄일 수 있다.
장점과 단점에 대해 먼저 논의 해 보자.
장점
malloc호출 횟수가 줄어든다. -> 리스트에 추가, 삽입 속도가 빨라진다.
단점
- 미리 할당하기 때문에 메모리 낭비가 생긴다. (그러나 전체 리스트에 비해 매우 적은 낭비이다)
- 일반적인 리스트 알고리즘은 더이상 사용할 수 없다 ㅠㅠ(sort 라던지...)
간단한 원리부터 소개한다. 클러스터가 있으면, 몇개가 차있는지 등의 변수가 필요하다.
하지만 앞에서 말했다. 리스트에 변수가 많아도 리스트는 하나기 때문에 별 상관이 없는데, 노드의 크기가 커지면 많은 메모리 낭비가 생긴다.
그래서!!! 클러스터의 크기는 3이다. 왜 3인지 설명한다.
구조체의 크기가 4의 배수일경우 구조체의 주소역시 4의 배수공간에 할당된다.
주소가 4의 배수일경우 LSB와 그 왼쪽 비트, 즉 맨 오른쪽 2개의 비트는 무조건 00 이다.
따라서 이 공간에 우리는 데이터를 넣을수 있다. 0~3까지 말이다.
next와 prev의 이 남는 공간에 정보를 삽입한다. next쪽은 데이터의 시작번지 begin
prev 쪽은 데이터의 개수 length의 해당되는 정보를 삽입힌다.
그렇게 되면 여전히 struct는 8byte + 3*datasize 가 된다.
이제 생각할 부분은 데이터를 삽입할때 처음부터 삽입할지, 아니면 클러스터의 중간에 삽입할지 결정해야 한다.

사실 처음부터 넣나 가운데 부터 넣나 중요하지 않다. 데이터가 어디서 부터 시작되는지 begin이라는 정보가 있기 때문이다.(변수라고 말하지 않은거에 유의)
그럼 다음 생각할 문제는 클러스터에 정보를 꽉꽉 채워 넣느냐?
아니면 insert를 고려하여 1칸씩 비워 두느냐?

결정을 해야한다.
만일 클러스터를 비워둔다면 insert 작업시 할당을 하지 않는다. 하지만 리스트를 사용할떈 insert 보단 push 연산을 더 많이 하게 된다.
또한, 연속적으로 insert를 할시에는 1/3 만 차있으므로 push와 똑같은 복잡도를 요구한다.
따라서 클러스터를 모두 할당하는 방식을 사용한다.
==cluster를 이용한 연결 리스트(over alloc 포함) main.c==
#include<stdio.h>
#include"clist.h"
int main() {
CLIST c = NEW_CLIST(sizeof(int));
int i;
for (i = 0; i < 10; i++){
push_back(&c, &i);
}
//노드로 순회가 불가능함 begin과 to_next 를 사용하여야 함
CLIST_ITERATOR it = begin(&c);
for (; end(it); it = to_next(it)){
printf("%d\n", GETITDATA(it, int));
}
return 0;
}==cluster를 이용한 연결 리스트(over alloc 포함) clist.h==
#if !defined(DATA_STRUCTURE_CLUSTER_LIST_H_7DE_06_0F_INCLUDED)
#define DATA_STRUCTURE_CLUSTER_LIST_H_7DE_06_0F_INCLUDED
#include<stddef.h> //size_t, NULL
#include<malloc.h> //malloc
#include<memory.h> //memcpy
#include<math.h> //abs
#pragma pack(push,4)
typedef struct tagCLISTNODE CLISTNODE;
struct tagCLISTNODE{
#define GETDEC(C) (C&3)
#define SETDEC(C,D) do{C=((C&~3)|D);}while(0)
#define GETPTR(C) ((unsigned long)C&~3)
#define SETPTR(C,D) do{(unsigned long)C=(unsigned long)D|((unsigned long)C&3);}while(0)
union{
struct tagCLISTNODE* next;
unsigned long begin;
};
union{
struct tagCLISTNODE* prev;
unsigned long length;
};
}
#if defined(__linux__) || defined(__GNUC__)
__attribute__((aligned(sizeof(long))))
#endif
;
typedef struct tagCLIST CLIST;
struct tagCLIST{
CLISTNODE* head;
CLISTNODE* tail;
size_t type_size;
size_t cluster_size;
};
typedef struct{
CLISTNODE* node;
size_t idx;
size_t type_size;
#define GETITDATA(IT,TYPE) *(TYPE*)((char*)((IT).node+1)+((IT).idx*(IT).type_size))
}CLIST_ITERATOR;
#pragma pack(pop)
CLIST NEW_CLIST(size_t type_size) {
CLIST list = { 0 };
list.type_size = type_size;
list.cluster_size = type_size * 3;
list.cluster_size += sizeof(long)-list.cluster_size % sizeof(long);
return list;
}
void push_back(CLIST* list, void* value) {
int idx = 0;
CLISTNODE* n = NULL;
//클러스터가 다 찻다면
if (!list->tail || GETDEC(list->tail->length) == 3){
n = (CLISTNODE*)calloc(1,sizeof(CLISTNODE)+list->cluster_size);
SETPTR(n->next, NULL);
SETPTR(n->prev, list->tail);
if (!list->tail)
list->head = list->tail = n;
else
list->tail = list->tail->next = n;
}
else{
n = list->tail;
idx = (GETDEC(n->begin) + GETDEC(n->length))%3;
}
memcpy((char*)(n + 1) + (idx*list->type_size), value, list->type_size);
SETDEC(n->length,GETDEC(n->length)+1);
}
CLIST_ITERATOR begin(CLIST* list) {
CLIST_ITERATOR it;
it.node = list->head;
it.type_size = list->type_size;
it.idx = GETDEC(it.node->begin);
return it;
}
int end(CLIST_ITERATOR it) {
return (int)it.node;
}
CLIST_ITERATOR to_next(CLIST_ITERATOR it) {
it.idx = (it.idx + 1) % 3;
if (it.idx == GETDEC(it.node->begin) //한바퀴 돌았다는 뜻
|| abs((long)it.idx - (long)GETDEC(it.node->begin)) == GETDEC(it.node->length)) {
it.node = it.node->next;
if (it.node)
it.idx = GETDEC(it.node->begin);
}
return it;
}
#endif설계 설명은 위에서 그림과 함께 설명한 그대로이다. 비트 추출은 잘 보면 이해가 간다
union을 사용하여 직관적이게 코드를 짜보았다.
노드에 데이터가 3개가 있고, 어디가 시작점인지 모르기때문에 순회시 반드시 지정함수를 사용해야 한다.
그래서 iterator 라는 개념이 도입되었다.(C++ STL을 써보았다면 알것이다.)
###Battle Time
위에서 구현한 3개의 리스트 모두 추가연산이나 삽입연산이나 정확하게 똑같은 시간복잡도를 가진다.
따라서 push_back 함수를 통해 간단하게 시간 측정을 해보겠다.
int의 경우 10만,100만,1000만번 추가한 횟수이다.
대용량 struct의 경우 1만,10만,100만이다.
typedef struct BIG{
int a[128];
double b[64];
}BIG;VC++ 2013 DEBUG
push back n=100000, element (int)
cluster list : 0.013700
template list : 0.021900
over alloc list : 0.017100
push back n=1000000, element (int)
cluster list : 0.121800
template list : 0.188600
over alloc list : 0.203000
push back n=10000000, element (int)
cluster list : 1.202500
template list : 1.921000
over alloc list : 2.051600push back n=10000, element (big struct)
cluster list : 0.000000
template list : 0.012500
over alloc list : 0.012500
push back n=100000, element (big struct)
cluster list : 0.047400
template list : 0.059300
over alloc list : 0.054300
push back n=1000000, element (big struct)
cluster list : 0.487500
template list : 0.573500
over alloc list : 0.572000VC++ 2013 RELEASE
push back n=100000, element (int)
cluster list : 0.003100
template list : 0.001600
over alloc list : 0.001600
push back n=1000000, element (int)
cluster list : 0.045400
template list : 0.056200
over alloc list : 0.050000
push back n=10000000, element (int)
cluster list : 0.442100
template list : 0.528700
over alloc list : 0.509400push back n=10000, element (big struct)
cluster list : 0.003200
template list : 0.004600
over alloc list : 0.005000
push back n=100000, element (big struct)
cluster list : 0.040700
template list : 0.045300
over alloc list : 0.043700
push back n=1000000, element (big struct)
cluster list : 0.389000
template list : 0.435800
over alloc list : 0.429300#####Windows GCC -o0 (o1,o2,o3 별반 차이없음)
push back n=100000, element (int)
cluster list : 0.003100
template list : 0.006200
over alloc list : 0.006200
push back n=1000000, element (int)
cluster list : 0.037600
template list : 0.053000
over alloc list : 0.054800
push back n=10000000, element (int)
cluster list : 0.370300
template list : 0.532700
over alloc list : 0.560100push back n=10000, element (big struct)
cluster list : 0.003100
template list : 0.007900
over alloc list : 0.001500
push back n=100000, element (big struct)
cluster list : 0.035900
template list : 0.043700
over alloc list : 0.042300
push back n=1000000, element (big struct)
cluster list : 0.411000
template list : 0.406100
over alloc list : 0.398800리눅스에서 굳이 측정안해도 뻔하다.
측정을 여러번 해봤지만 클러스터링 기법이 빠르긴하나, 거의 차이가 나지 않고.....
셋다 모두 빠르다.(내가 짜서 그런가)
확실한건 void* 로 두번 할당한것보다는 무척 빠르다.
다음 포스팅에서는 리스트의 활용에 대해 알아보자.
변경 사항
- 2016년 6월 15일 글 등록
- 2016년 6월 15일 3:00pm 잘못된 시간 측정 재측정
Reference
- 없음
Copyright 2016. (김봄) all rights reserved.
