머신러닝을 공부하기 시작하면, 여러가지 용어들이 나오는데, 이 용어들이 정확히 무엇을 지칭하는 것인지 헷갈릴 수 있다. (내가 그랬었다.)
먼저 용어들에 대해 정확히 집어놓고, 공부를 해나가면 공부를 하면서 헤메는 시간이 줄어들 것이다.
머신러닝 모델들을 배우기 위한 사전지식들도 간략하게 핵심들로 정리해 보았다.
Machine Learning
사람이 만든 기술을 구축하는 기술
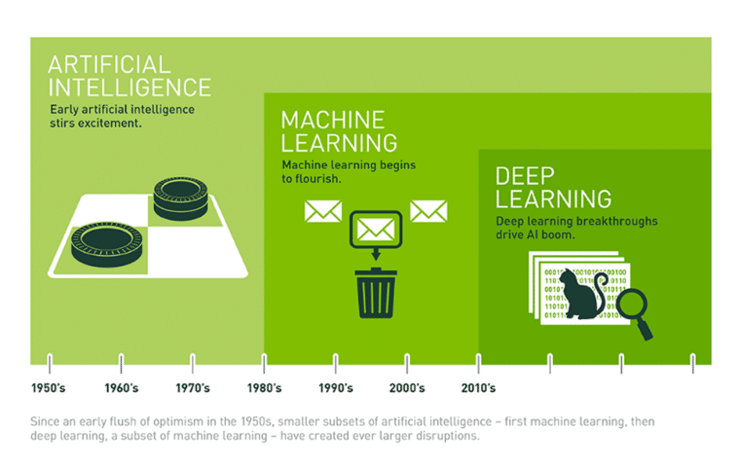
이미지 출처: https://blogs.nvidia.co.kr
🤔 이제야 머신러닝/딥러닝이 뜨는 이유?
-
기계가 발전하면서 분산저장시스템이 발달
-
GPU를 사용하면서 대용량데이터를 처리할 기술이 생김
feature
feature = attribute = 열 = 차원
즉, 머신러닝에서 feature을 늘린다는 말은 차원을 늘린다는 말과 동일하다고 봐도 된다.
일반적으로 label 개수 (= class 개수) < feature 개수 < data 개수 이다.
머신러닝 학습시에 feature 선택은 매우 중요하다.
특히, feature에 대한 도메인 지식(전문지식)이 요구된다는 점을 유의해야 한다.
e.g.) 일본어 문장에 대한 감정 분석시, 일본어에 대한 전문지식이 요구된다.
feature에 비해 데이터가 너무 적으면 overfitting 과적합 발생 가능성이 증가한다.
=> overfitting이란, 학습데이터에만 과도하게 학습이 되어 새로운 테스트 데이터에 대해 잘못된 예측을 할 가능성이 커지는 것이다.
=> 이러한 현상을 curse of dimensionality; 차원의 저주 라고도 한다.
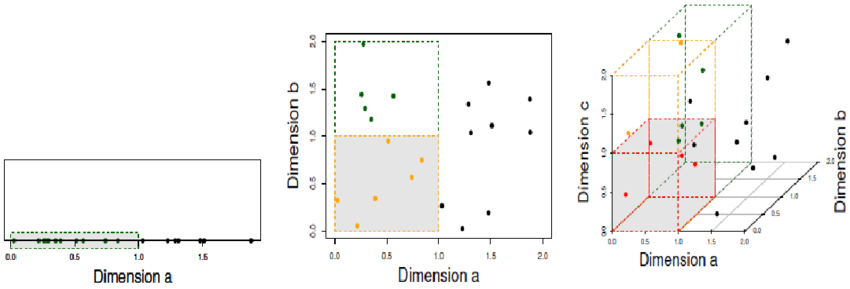
이미지 출처: www.researchgate.net
이러한 머신러닝과 다르게 딥러닝은 feature을 자동으로 정의 해준다.
따라서, 딥러닝은 어떤 식으로 학습하여 좋은 결과가 나오는지 해석하기가 힘들다.
이러한 현상 때문에, Black box라고도 한다.
반대로 학습과정이 해석되는 것은 White box라고 한다.
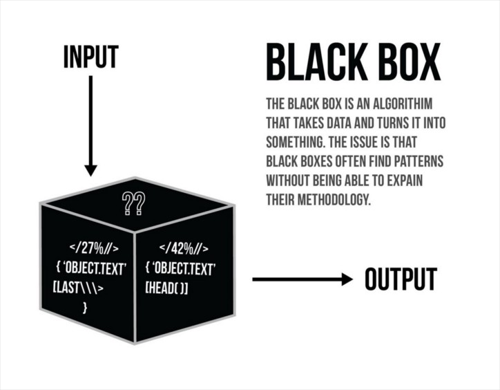
이미지 출처: https://ichi.pro/ko
model
model = method = algorithm = hypothesis
(hypothesis; 임의의 목적을 달성하기 위한 증명되지 않은 사실을 기반으로한 아이디어, 탐구)
🖋 computational complexity는 낮을수록, data sample complexity는 높을수록 좋다.
computational complexity: 데이터가 증가할 때 계산량이 얼마나 많아 지는가
data sample complexity: 데이터가 증가할 때 정답의 품질이 얼마나 증가하는가
🖋 비지도학습은 parametric, Non-parametric으로 나눌 수 있다.
parametric: 데이터가 어떤 분포로부터 생성된건지 임의로 가정하고 접근하는 방식이다. 즉, 모델을 가정하여 파라미터를 통해 문제에 접근한다.
표본의 수가 30개 이상일 때 중심극한 정리에 의해 정규분포를 따르므로 모수적 방법론을 사용할 수 있다.
Non-parametric: 어떤 분포인지 가정이 없고, 파라미터 개수가 변하기도 하는 방식이다.
표본의 수가 30개 미만이거나 정규성 검정에서 정규 분포를 따르지 않는다고 증명되는 경우 사용한다.
e.g.) KNN 알고리즘, Decision Tree 등
🖋 Discriminative model와 Generative model
Discriminative model : Conditional Probaility(조건부확률) P(xㅣy) 학습. class들의 경계선 찾기. 즉, classification이 목표
e.g.) 선형회귀, SVM
Generative model: Joint Probability인 P(x, y) = P(x∩y) 를 학습. 데이터 범주의 분포를 학습
e.g.) 가우시안, 나이브베이즈

이미지 출처: https://stanford.edu
머신러닝 모델 선정과 관련된 유명한 말
No Free Lunch: “모든 것에 최선인 알고리즘은 없다”
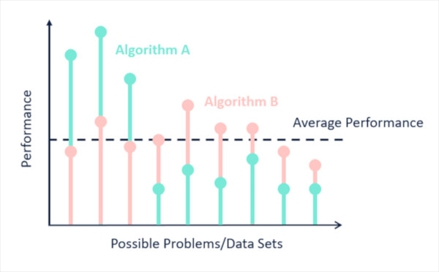
이미지 출처 : www.kdnuggets.com
Occam’s Razor (오컴의 면도날): “단순함이 의외로 진리일 수 있다”

이미지 출처: www.chrismadden.co.uk
모델 평가
Accuracy (정확도): 1 - Error
Precision (정밀도): 예측이 정답인 것 중 실제로도 정답인 비율
Recall (재현율): 실제 정답인 것 중 예측도 정답인 비율
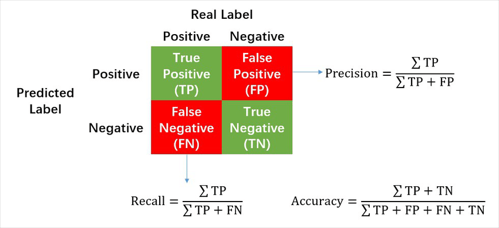
이미지 출처: www.researchgate.net
e.g.) 총 10명 중 실제 마피아 2명 일 때, 이 중 4명을 마피아로 예상하였다. 그 4명 중 실제 마피아는 1명 이었다고 하자.
이때, Precision은 1/4 (마피아라고 예측한 사람 중 실제 마피아인 비율)
Recall은 1/2 (실제 마피아 중 예측도 마피아였던 비율)
그러나 정밀도와 재현율의 점수를 각각으로 판단하는 것은 전반적인 데이터의 성능을 평가하기에 정확하지 않을 수 있다. 예를 들어, 재현율의 경우에는 전부 예측을 정답으로 하면 재현율은 만점인 것이다.
따라서 정밀도와 재현율을 같이 고려하여 점수를 매기는 조화평균 (f1-score)가 쓰인다.
AUC (Area Under the Curve): ROC curve에서 그래프 아래 면적 (값이 클수록 성능이 좋은 것)
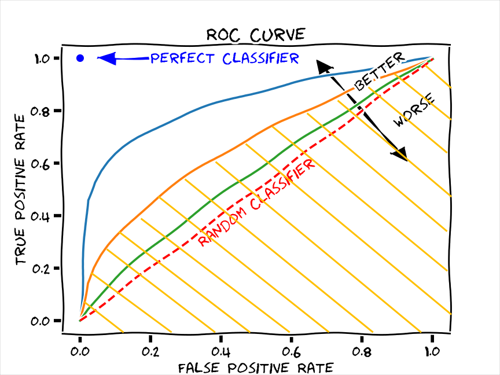
이미지 출처: https://glassboxmedicine.com
ROC curve는 False Positive Rate(FPR)이 x축이고, True Positive Rate(TPR)이 y축인 그래프
False Positive Rate (FPR): 실제 negative 중에서 알고리즘 예측값은 positive인 것
True Positive Rate (TPR): 실제 postive 중에서 알고리즘 예측값도 postive인 것 (TRP는 Sensitivity 또는 Recall이라고도 불린다.)
++ Validation?
연습용 테스트 데이터 (훈련 데이터에서 떼어내어 마치 테스트 데이터인 양 쓰는 것)
=> 이를 이용하여 test accuracy를 가늠할 수 있다.
따라서 좋은 성능을 내는지 확인 후, 실제 새로운 데이터에 대해 모델 사용 가능
Bias VS Variance
Bias
예측값이 평균에서 멀어진 것
Variance
어떤 예측을 할 때 결과가 다양하게 나오는 것
=> 예측값들의 분산이 큰 것
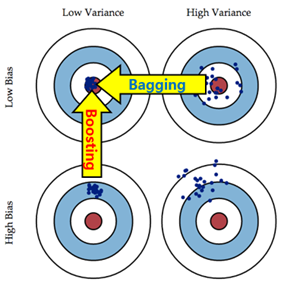
오버피팅이 되면, Bias는 작지만 variance는 커지게 된다.
Q. test data의 Variance가 커서 과적합(오버피팅)됐다면?
- 데이터 수 늘리기
- 모델 경량화 (더 단순하게; 오컴의 면도날)
Q. test data가 Bias가 커서 과소적합(언더피팅)됐다면?
- 모델 복잡도 높이기
Model Training
머신러닝에서의 학습이란 모델이 가진 파라미터를 최적화(최소화 or 최대화)하는 것이다.
파라미터를 최적화하기 위한 함수들 정리
Loss function: 하나의 input 데이터의 오차 계산
Cost function: Loss를 총 데이터에 대해 평균 낸 것
Objective function: 가장 일반화된 용어. 학습을 통해 최적화하려는 모든 종류의 함수
