pandas를 Excel처럼
데이터 규모가 버거워 엑셀 대신 쓰기 시작한 python pandas.
집계는 SQL로 하지만, 경우에 따라서 집계되지 않은 raws들을 data frame으로 선언하고, 필요에 따라서 그때마다 pandas를 활용하여 집계를 하는 것이 더 간단할 때도 자주 있다.
그래서 groupby 매서드를 자주 활용하게 되는데, 조건에 따른 집계 결과를 보려고 서치하고 활용했던 경험을 적어두려고 한다.
data load
import pandas as pd ## 데이터 핸들링 기본, 습관적 라이브러리 호출 1. pandas
import numpy as np ## 데이터 핸들링 기본, 습관적 라이브러리 호출 2. numpy
import seaborn as sns ## 데이터 시각화 기본, 습관적 라이브러리 호출 3. seaborn
import matplotlib.pyplot as plt ## 데이터 시각화 기본, 습관적 라이브러리 호출 4. matplotlib.pyplotdf = sns.load_dataset('titanic') ## 케케묵었지만 그만큼 누구나 경험해봤을 법한 타이타닉 데이터df_info()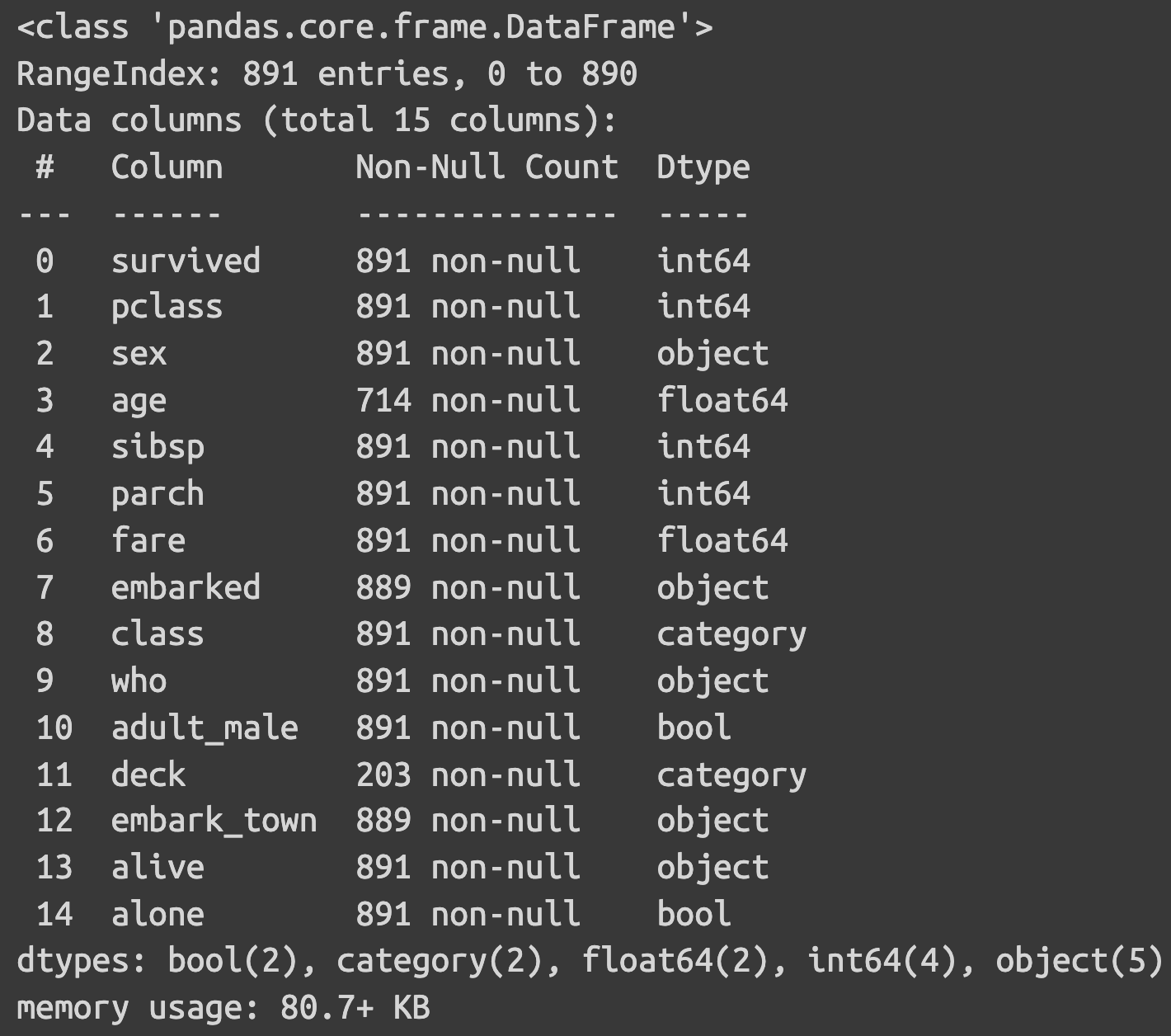
df_head()
단순 groupby
선실 등급마다의 총 승선 인원 수
df.groupby(['선실등급(집계기준)'])\
.agg(
희망하는_집계컬럼_이름 = ('컬럼이름', '집계방법')
).reset_index()
df.groupby(['pclass'])\
.agg(
passenger_count = ('survived', 'count')
).reset_index()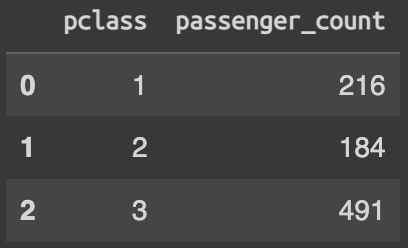
조건부 groupby
선실 등급마다의 총 승선 인원 수 & 선실 등급마다 20세 이하 승선 인원 수
1. groupby 내에서 처리하기
df.groupby(['선실등급(집계기준)']).agg(희망하는_집계컬럼_이름 = ('컬럼이름', '집계방법')).reset_index()
df.groupby(['pclass'])\
.agg(
passenger_count = ('survived', 'count'), ## 총 승선 인원 수
under_age_20 = ('age', lambda x: (x <= 20).sum()), ## 20세 이하 승선 인원 수
over_fare_10_cnt = ('fare', lambda x: (x > 10).sum()), ## fare → 10 초과 지불 승선 수
over_fare_10_amt = ('fare', lambda x: ((x > 10)*x).sum()), ## fare → 10 초과 지불건 총액
over_fare_10_amt_int = ('fare', lambda x: int(((x > 10)*x).sum())), ## fare → 10 초과 지불건 총액, data type 변경
).reset_index()
2. 조건에 부합하는 컬럼 생성하여 처리하기
df['is_under_age_20'] = np.where(df.age <= 20, 1, 0) ## 20세 미만 여부
df['is_over_10_fare'] = np.where(df.fare > 10, 1, 0) ## fare → 10 초과 지불 승선 수
df['only_over_10_fare'] = np.where(df.fare > 10, df.fare, 0) ## fare → 10 초과 지불건 총액
df.groupby(['pclass'])\
.agg(
passenger_count = ('survived', 'count'),
under_20_age = ('is_under_age_20', 'sum'),
over_fare_10_cnt = ('is_over_10_fare', 'sum'),
over_fare_10_amt = ('only_over_10_fare', 'sum')
).reset_index()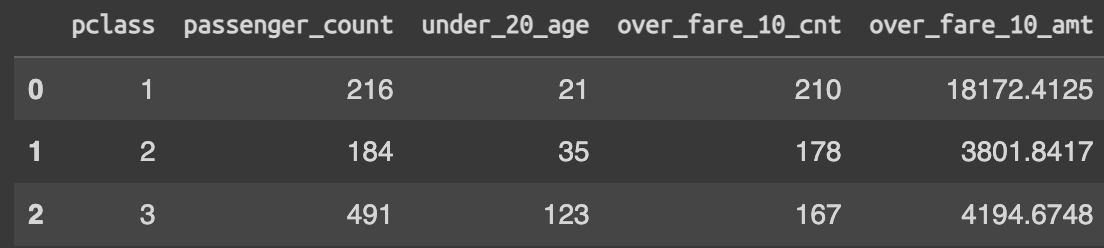
복합조건부 groupby
위에서 사용한 방법은 lambda 함수이다.
pandas에서 lambda 함수로 여러 컬럼 조건을 활용한다면 효율이 좋은 편도 아니었다.
그리고 위의 경우처럼 groupby 내에서 lambda 함수를 활용할 때에는 여러 컬럼을 동시에 활용하려 할 때마다 에러를 반환하였다.
따라서 복합 조건부 groupby는 별도의 방법이 있다기 보다는, 위의 2. 조건에 부합하는 컬럼 생성하여 처리하기 처럼 해당하는 조건에 맞는 구분자 컬럼을 생성하여 우회 적용하는 방법을 활용하고 있다.

분석가