위키북스의 파이썬 머신러닝 완벽 가이드 책을 토대로 공부한 내용입니다.
1. 로지스틱 회귀
로지스틱 회귀는 선형 회귀 방식을 분류에 적용한 알고리즘이다. 회귀가 선형인지 비선형인지는 독립 변수가 아닌 가중치(weight)가 선형인지 비선형인지를 따른다. 로지스틱 회귀가 선형 회귀와 다른 점은 학습을 통해 선형 함수의 회귀 최적선을 찾는 것이 아니라 시그모이드(Sigmoid) 함수 최적선을 찾고 이 시그모이드 함수의 반환값을 확률로 간주해 확률에 따라 분류를 결정한다는 것이다. 많은 자연, 사회 현상에서 특정 변수의 확률 값은 선형이 아니라 시그모이드 함수와 같은 S자 커브 형태를 가진다. 시그모이드 함수는 항상 0~1 사이의 값을 가지며, x값이 커지면 1에 근사하고, x값이 작아지면 0에 근사한다. 따라서 로지스틱 회귀는 회귀 문제를 분류 문제로 적용하기 위해 선형 회귀 방식과 시그모이드 함수를 이용하여 결과 값이 1과 0을 예측하도록 수행한다.
Sigmoid Function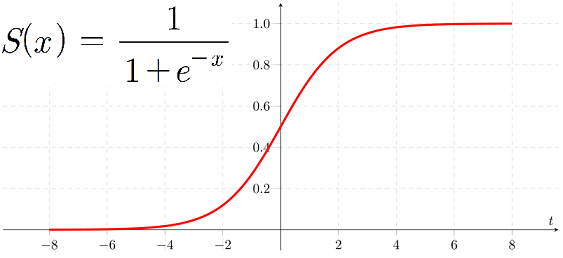
위스콘신 유방암 dataset을 이용하여 로지스틱 회귀로 암 여부를 판단해보며, 정확도와 ROC-AUC 값을 구해 보겠다.
import pandas as pd import matplotlib.pyplot as plt %matplotlib inline from sklearn.datasets import load_breast_cancer from sklearn.linear_model import LogisticRegression from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, roc_auc_score cancer = load_breast_cancer() # StandardScaler( )로 평균이 0, 분산 1로 데이터 분포도 변환 scaler = StandardScaler() data_scaled = scaler.fit_transform(cancer.data) X_train , X_test, y_train , y_test = train_test_split(data_scaled, cancer.target, test_size=0.3, random_state=0) # 로지스틱 회귀를 이용하여 학습 및 예측 수행. lr_clf = LogisticRegression() lr_clf.fit(X_train, y_train) lr_preds = lr_clf.predict(X_test) # accuracy와 roc_auc 측정 print('accuracy: {:0.3f}'.format(accuracy_score(y_test, lr_preds))) print('roc_auc: {:0.3f}'.format(roc_auc_score(y_test , lr_preds)))[output]
사이킷런 LogisticRegression 클래스의 주요 hyper parameter로 panalty와 C가 있다. penalty는 Regularization의 유형을 설정하고, default는 'l2'로 되어 있다. C는 규제 강도를 조절하는 alpha값의 역수이다. GridSearchCV를 이용해 위스콘신 dataset에서 이 hyper parameter를 최적화해 보겠다.
from sklearn.model_selection import GridSearchCV params={'penalty':['l2', 'l1'], 'C':[0.01, 0.1, 1, 1, 5, 10]} grid_clf = GridSearchCV(lr_clf, param_grid=params, scoring='accuracy', cv=3 ) grid_clf.fit(data_scaled, cancer.target) print('최적 하이퍼 파라미터:{0}, 최적 평균 정확도:{1:.3f}'.format(grid_clf.best_params_, grid_clf.best_score_))[output]
로지스틱 회귀는 가볍고 빠르지만, 이진 분류 예측 성능도 뛰어나다. 그래서 로지스틱 회귀를 이진 분류의 기본 모델로 사용하는 경우가 많고, 희소한 dataset 분류에도 뛰어난 성능을 보여서 텍스트 분류에서도 자주 사용된다.
