위키북스의 파이썬 머신러닝 완벽 가이드 책을 토대로 공부한 내용입니다.
1. 군집 평가
iris dataset의 target과 군집화 결과를 비교하여 군집화가 얼마나 효율적으로 됬는지 확인하였다. 하지만 대부분의 군집화 dataset은 target label을 가지고 있지 않으며, 군집화는 분류와 유사해 보일 수 있으나 성격이 많이 다르다. 데이터 내의 숨어 있는 별도의 그룹을 찾아서 의미를 부여하거나 동일한 분류 값에 속하더라도 그 안에서 더 세분화된 군집화를 추구하거나 서로 다른 분류 값의 데이터도 더 넓은 군집화 레벨화 등의 영역을 가지고 있다. 따라서 군집화를 평가하는 지표로는 label을 사용하지 않으며, 실루엣 분석이라는 방법을 대표적으로 사용한다.
2. 실루엣 분석의 개요
군집화 평가 방법 중 하나인 실루엣 분석은 각 군집 간의 거리가 얼마나 효율적으로 분리돼 있는지를 나타낸다. 여기서 효율적으로 분리되어 있다는 것은 다른 군집과의 거리는 떨어져 있고 동일 군집끼리의 데이터는 서로 가깝게 잘 뭉쳐 있다는 의미이다. 실루엣 분석은 실루엣 계수(silhouette coefficient)를 기반으로 하고, 개별 데이터가 가지는 군집화 지표이다. 개별 데이터가 가지는 실루엣 계수는 해당 데이터가 같은 군집 내의 데이터와 얼마나 가깝게 군집화돼 있고, 다른 군집에 있는 데이터와는 얼마나 멀리 분리돼 있는지를 나타내는 지표이다.
특정 데이터 포인트의 실루엣 계수 값은 해당 데이터 포인트와 같은 군집 내에 있는 다른 데이터 포인트와의 거리를 평균한 값 a(i)와 해당 데이터 포인트가 속하지 않은 군집 중 가장 가까운 군집과의 평균 거리 b(i)를 기반으로 계산된다. 두 군집 간의 거리는 b(i) - a(i)이며 이 값을 정규화하기 위해 MAX(a(i), b(i)) 로 나눈다. 이렇게 i번째 데이터 포인트의 실루엣 계수 값 s(i)를 계산한다.
실루엣 계수는 -1에서 1 사이의 값을 가지며, 1로 가까워질수록 근처 군집과 더 멀리 떨어져 있는 것이고 0에 가까워질수록 근처 군집과 가까운 것이다. - 값은 아예 다른 군집에 데이터 포인트가 할당된 것을 의미한다.
사이킷런은 이러한 실루엣 분석을 위해 제공하는 method가 있다.
- sklearn.metrics.silhouette_samples(x, labels, metric='euclidean', **kwds): 인자로 x feature dataset과 각 feature dataset이 속한 군집 labels 데이터를 입력해주면 각 데이터 포인트의 실루엣 계수를 계산하여 반환한다.
- sklearn.metrics.silhouette_score(x, labels, metric='euclidean', sample_size=None, **kwds): 인자로 x feature dataset과 각 feature dataset이 속한 군집 label 데이터를 입력해주면 전체 데이터의 실루엣 계수 값을 평균해 반환한다. 즉 np.mean(silhouette_samplesa())를 의미한다. 일반적으로 이 값이 높을수록 군집화가 어느정도 잘 됬다고 판단할 수 있지만 무조건 이 값이 높다고 해서 군집화가 잘 됬다고 판단할 수는 없다.
- 좋은 군집화가 되기 위한 기준 조건
- 전체 실루엣 계수의 평균값, 즉 사이킷런의 silhouette_score() 값은 0~1 사이의 값을 가지며, 1에 가까울수록 좋다.
- 하지만 전체 실루엣 계수의 평균값과 더불어 개별 군집의 평균값의 편차가 크지 않아야 한다. 즉, 개별 군집의 실루엣 계수 평균값이 전체 실루엣 계수의 평균값에서 크게 벗어나지 않는 것이 중요하다. 만약 전체 실루엣 계수의 평균값은 높지만, 특정 군집의 실루엣 계수 평균값만 유난히 높고 다른 군집들의 실루엣 계수 평균값은 낮으면 좋은 군집화 조건이 아니다.
3. iris dataset을 이용한 군집 평가
iris dataset의 군집화 결과를 실루엣 분석으로 평가해 보겠다.
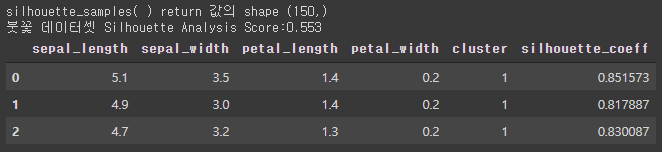
from sklearn.preprocessing import scale from sklearn.datasets import load_iris from sklearn.cluster import KMeans # 실루엣 분석 metric 값을 구하기 위한 API 추가 from sklearn.metrics import silhouette_samples, silhouette_score import matplotlib.pyplot as plt import numpy as np import pandas as pd %matplotlib inline iris = load_iris() feature_names = ['sepal_length','sepal_width','petal_length','petal_width'] irisDF = pd.DataFrame(data=iris.data, columns=feature_names) kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=300,random_state=0).fit(irisDF) irisDF['cluster'] = kmeans.labels_ # iris 의 모든 개별 데이터에 실루엣 계수값을 구함. score_samples = silhouette_samples(iris.data, irisDF['cluster']) print('silhouette_samples( ) return 값의 shape' , score_samples.shape) # irisDF에 실루엣 계수 컬럼 추가 irisDF['silhouette_coeff'] = score_samples # 모든 데이터의 평균 실루엣 계수값을 구함. average_score = silhouette_score(iris.data, irisDF['cluster']) print('붓꽃 데이터셋 Silhouette Analysis Score:{0:.3f}'.format(average_score)) irisDF.head(3)[output]
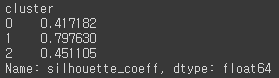
평균 실루엣 계수 값이 약 0.553이다. 이번에는 군집 별로 평균 실루엣 계수 값을 알아보겠다.irisDF.groupby('cluster')['silhouette_coeff'].mean()[output]
1번 군집의 실루엣 계수 평균 값이 약 0.79인 반면, 나머지 군집의 실루엣 계수 평균 값이 상대적으로 낮다.
4. 군집별 평균 실루엣 계수의 시각화를 통한 군집 개수 최적화 방법
전체 데이터의 평균 실루엣 계수 값이 높다고 반드시 최적의 군집 개수로 군집화가 잘 됬다고 볼수는 없다. 특정 군집 내의 실루엣 계수 값만 너무 높고, 다른 군집은 내부 데이터끼리의 거리가 너무 떨어져 있어 실루엣 계수 값이 낮아져도 평균적으로 높은 값을 가질 수 있다. 개별 군집별로 적당히 분리된 거리를 유지하면서도 군집 내의 데이터가 서로 뭉쳐 있는 경우에 K-평균의 적절한 군집 개수가 설정됬다고 판단할 수 있다.
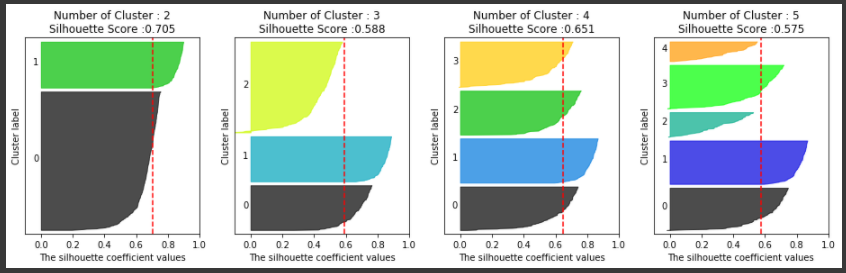
이러한 방법을 시각적으로 지원헤주는 좋은 예제 소스 코드가 있다. 하지만 그전에 여러 개의 군집 개수가 주어졌을 때 이를 분석한 도표를 참고해 평균 실루엣 계수로 군집 개수를 최적화하는 방법을 알아보겠다.
첫 번째 경우는 위 그림과 같이 주어진 데이터에 대해 군집의 개수를 2개로 정했을 때이다. 이때 평균 실루엣 계수는 약 0.704로 매우 높게 나타난다. 왼쪽 그림은 개별 군집에 속하는 데이터의 실루엣 계수를 2차원으로 나타낸 것이다. 점선은 전체 평균 실루엣 계수 값을 나타내며, 이로 판단해 볼 때 1번 군집의 모든 데이터는 평균 실루엣 계수 값 이상이지만, 2번 군집의 경우는 평균보다 적은 데이터 값이 매우 많다. 오른쪽 그림으로 이유를 알 수 있는데 1번 군집에 비해 0번 군집은 내부 데이터끼리 많이 떨어져 있는 모습이다.
다음은 군집이 3개일 경우이다. 전체 데이터의 평균 실루엣 값이 약 0.588이다. 1번, 2번 군집의 경우 평균보다 높은 실루엣 계수 값을 가지고 있지만 0번의 경우 모두 평균보다 낮다. 오른쪽 그림에서도 0번 군집의 내부 데이터 간의 거리가 멀게 있는 것을 알 수 있다.
다음으로 군집이 4개인 경우이다. 이때 평균 실루엣 계수 값은 약 0.65이다. 왼쪽 그림에서 보듯이 개별 군집의 평균 실루엣 계수 값이 비교적 균일하게 위치하고 있다. 1번 군집의 경우 모든 데이터가 평균보다 높은 계수 값을 가지고 있으며, 0번, 2번 군집은 절반 이상이 평균보다 높고, 3번 군집은 1/3 이상이 평균보다 높은 계수 값을 가지고 있다. 2개의 군집으로 정한 경우보다 평균 실루엣 계수 값은 작지만 4개의 군집으로 정한 경우가 가장 이상적인 군집화 개수로 판단할 수 있다.
소스 코드는 위 예제의 이미지 중 왼쪽 그림의 평균 실루엣 계수 값을 구하는 부분만 별도의 함수를 만들어 시각화한 것이다.
### 여러개의 클러스터링 갯수를 List로 입력 받아 각각의 실루엣 계수를 면적으로 시각화한 함수 작성 def visualize_silhouette(cluster_lists, X_features): from sklearn.datasets import make_blobs from sklearn.cluster import KMeans from sklearn.metrics import silhouette_samples, silhouette_score import matplotlib.pyplot as plt import matplotlib.cm as cm import math # 입력값으로 클러스터링 갯수들을 리스트로 받아서, 각 갯수별로 클러스터링을 적용하고 실루엣 개수를 구함 n_cols = len(cluster_lists) # plt.subplots()으로 리스트에 기재된 클러스터링 수만큼의 sub figures를 가지는 axs 생성 fig, axs = plt.subplots(figsize=(4*n_cols, 4), nrows=1, ncols=n_cols) # 리스트에 기재된 클러스터링 갯수들을 차례로 iteration 수행하면서 실루엣 개수 시각화 for ind, n_cluster in enumerate(cluster_lists): # KMeans 클러스터링 수행하고, 실루엣 스코어와 개별 데이터의 실루엣 값 계산. clusterer = KMeans(n_clusters = n_cluster, max_iter=500, random_state=0) cluster_labels = clusterer.fit_predict(X_features) sil_avg = silhouette_score(X_features, cluster_labels) sil_values = silhouette_samples(X_features, cluster_labels) y_lower = 10 axs[ind].set_title('Number of Cluster : '+ str(n_cluster)+'\n' \ 'Silhouette Score :' + str(round(sil_avg,3)) ) axs[ind].set_xlabel("The silhouette coefficient values") axs[ind].set_ylabel("Cluster label") axs[ind].set_xlim([-0.1, 1]) axs[ind].set_ylim([0, len(X_features) + (n_cluster + 1) * 10]) axs[ind].set_yticks([]) # Clear the yaxis labels / ticks axs[ind].set_xticks([0, 0.2, 0.4, 0.6, 0.8, 1]) # 클러스터링 갯수별로 fill_betweenx( )형태의 막대 그래프 표현. for i in range(n_cluster): ith_cluster_sil_values = sil_values[cluster_labels==i] ith_cluster_sil_values.sort() size_cluster_i = ith_cluster_sil_values.shape[0] y_upper = y_lower + size_cluster_i color = cm.nipy_spectral(float(i) / n_cluster) axs[ind].fill_betweenx(np.arange(y_lower, y_upper), 0, ith_cluster_sil_values, \ facecolor=color, edgecolor=color, alpha=0.7) axs[ind].text(-0.05, y_lower + 0.5 * size_cluster_i, str(i)) y_lower = y_upper + 10 axs[ind].axvline(x=sil_avg, color="red", linestyle="--") # make_blobs 을 통해 clustering 을 위한 4개의 클러스터 중심의 500개 2차원 데이터 셋 생성 from sklearn.datasets import make_blobs X, y = make_blobs(n_samples=500, n_features=2, centers=4, cluster_std=1, \ center_box=(-10.0, 10.0), shuffle=True, random_state=1) # cluster 개수를 2개, 3개, 4개, 5개 일때의 클러스터별 실루엣 계수 평균값을 시각화 visualize_silhouette([ 2, 3, 4, 5], X)[output]
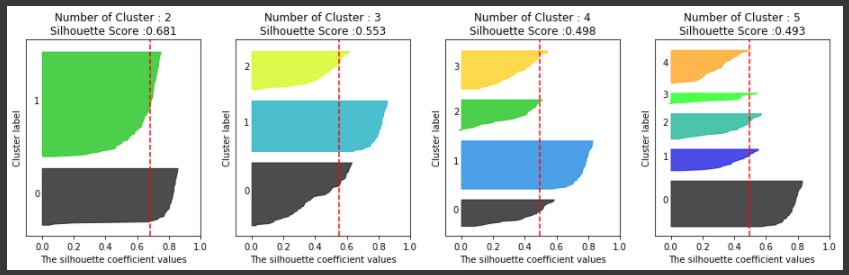
iris dataset을 이용하여 K-평균 수행 시 최적의 군집 개수를 알아보겠다.
from sklearn.datasets import load_iris iris=load_iris() visualize_silhouette([ 2, 3, 4,5 ], iris.data)[output]
iris dataset의 경우 2개의 군집 개수를 사용하는 것이 가장 좋아보인다. 실루엣 계수를 통한 K-평균 군집 평가 방법은 직관적으로 이해하기 쉽지만, 각 데이터 별로 다른 데이터와의 거릴를 반복적으로 계산해야 하므오 데이터 양이 늘어나면 수행 시간이 크게 늘어난다. 특히, 몇 만 건 이상의 데이터에 대해 사이킷런의 실루엣 계수 평가 API를 개인용 PC에서 수행할 경우 메모리 부족 등의 에러가 발생하기 쉽다. 이 경우 군집별로 임의의 데이터를 샘플링하여 실루엣 계수를 평가하는 방안을 고민해야 한다.