1 전체 구조
1) 완전 연결 계층(Affine 계층)으로 이루어진 Network
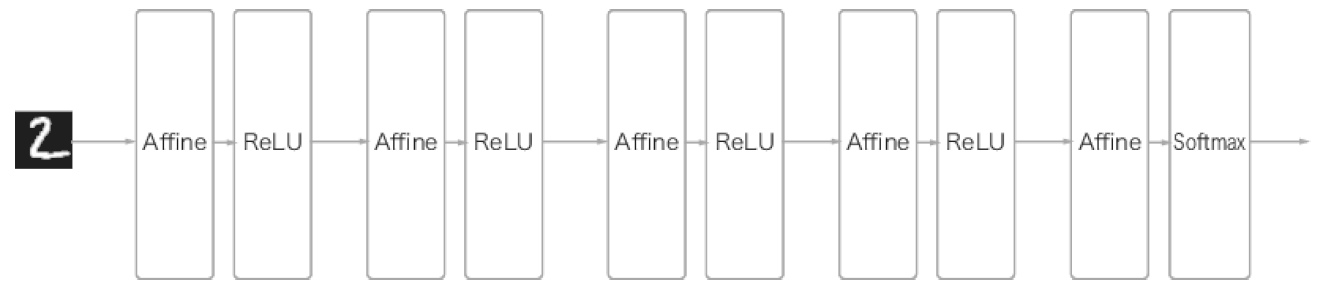
2) CNN(Convolutional Neural Network)

2 합성곱 계층
2.1 완전 연결계층의 문제점
→ 데이터의 형상 무시
- MNIST 데이터를 완전연결계층에 input으로 넣게 되면, (28, 28, 1) → (784, ) 로 변환하여 넣게됨
- 이 과정에서 이미지의 공간적 정보(픽셀들의 상관관계, 컬러 채널의 특성, 거리 등 )를 제대로 담지 못함
반면, 합성곱 계층은 input을 3차원 데이터로 받고, 다음 계층에도 3차원으로 전달하기 때문에 이미지처럼 형상을 가진 데이터를 제대로 이해할 가능성이 있음
-
CNN에서 합성곱 계층의 입/출력 데이터를 feature map이라고 한다.
입출력 데이터 = 특징 맵(feature map)
2.2 합성곱 연산
합성곱 계층에서 합성곱 연산을 수행함. 이는 이미지 처리에서 말하는 필터 연산에 해당한다.
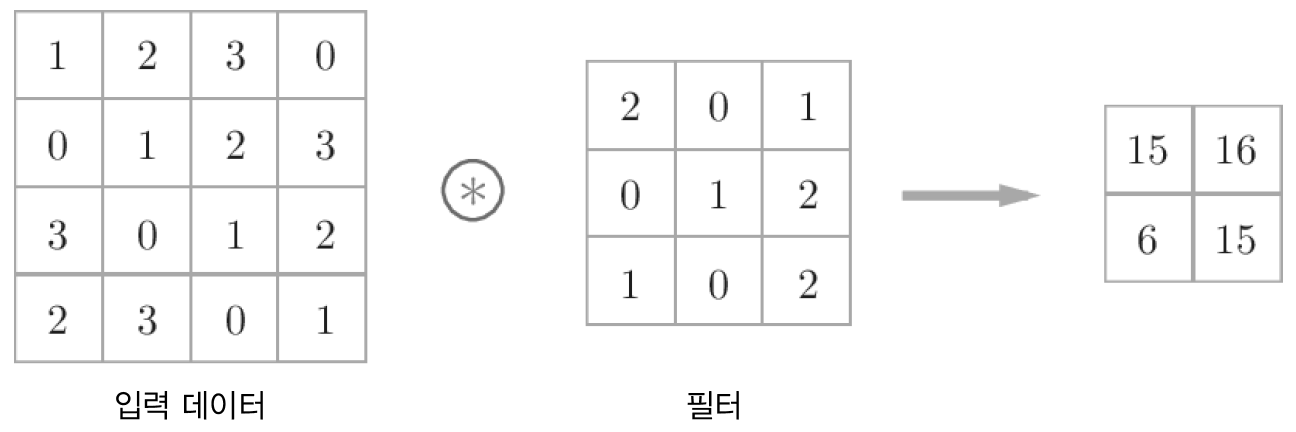
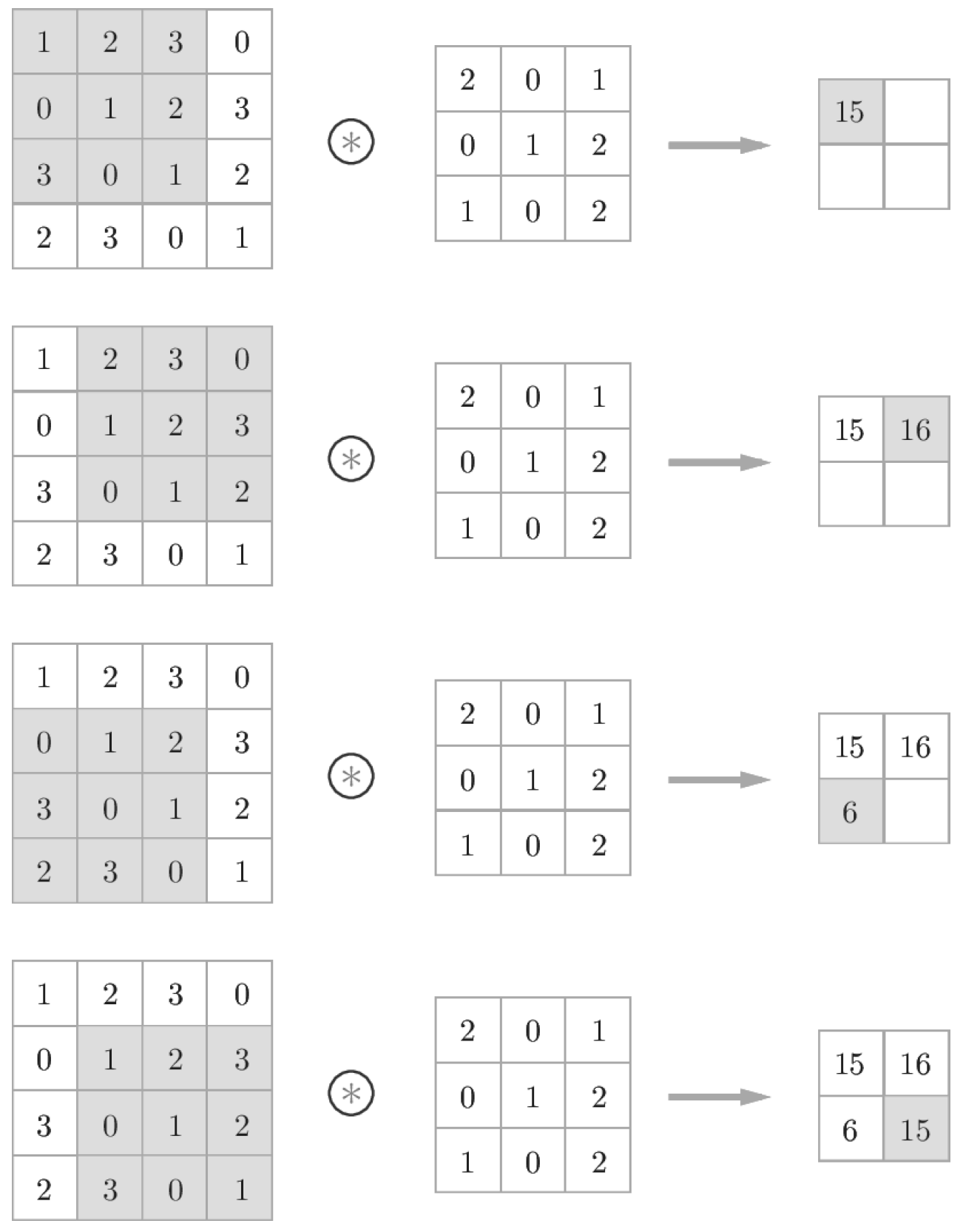
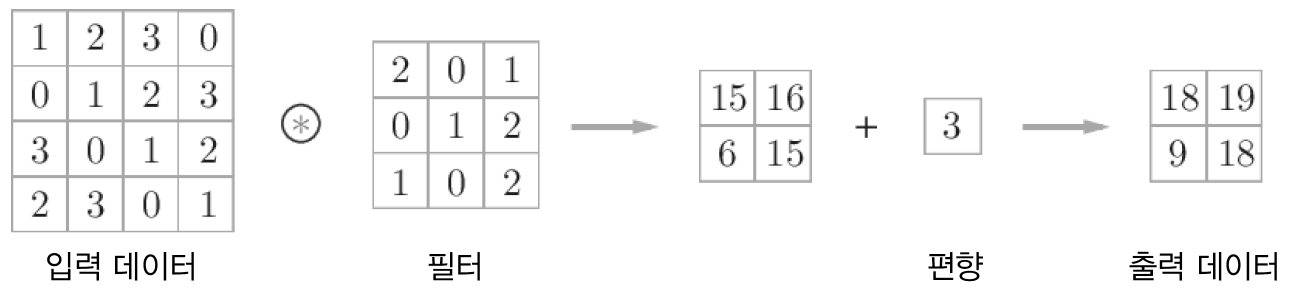
2.3 패딩
→ 합성곱 연산을 수행하기 전 입력 데이터 ****주변을 특정 값으로 채우는 것
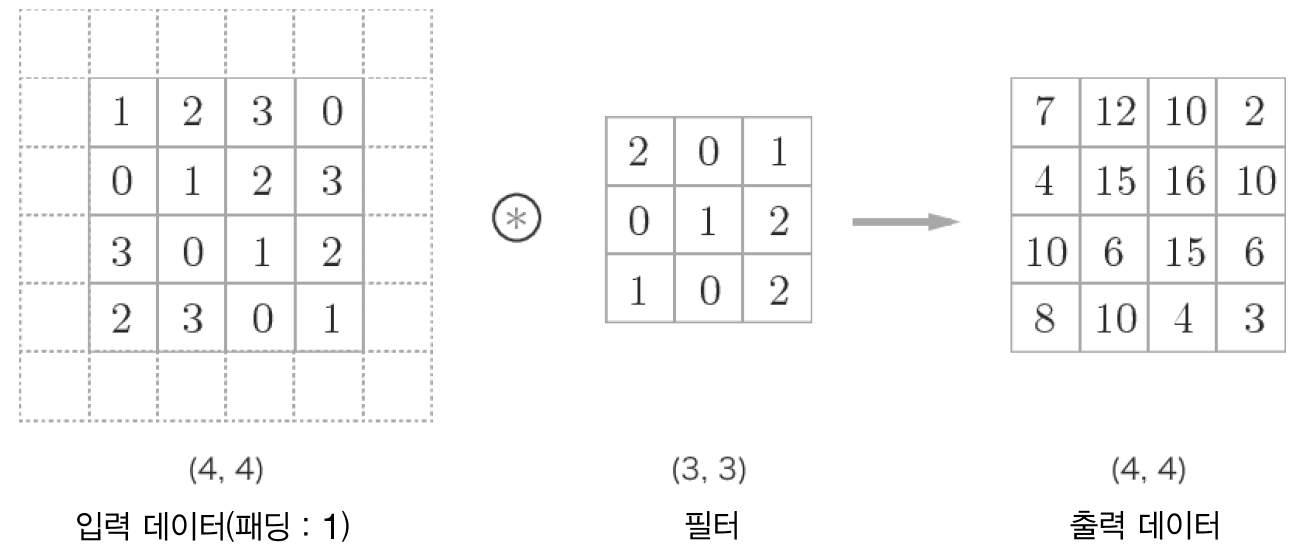
- output size를 조정할 목적으로 사용
- Conv Layer를 통과할수록 output size가 작아지기 때문에 이를 보정해주기 위해 사용
→ 입력 데이터의 공간적 크기를 고정한 채로 다음 계층에 전달할 수 있음
2.4 스트라이드
→ 필터를 적용하는 위치의 간격
- stride = 2인경우의 convolution 연산
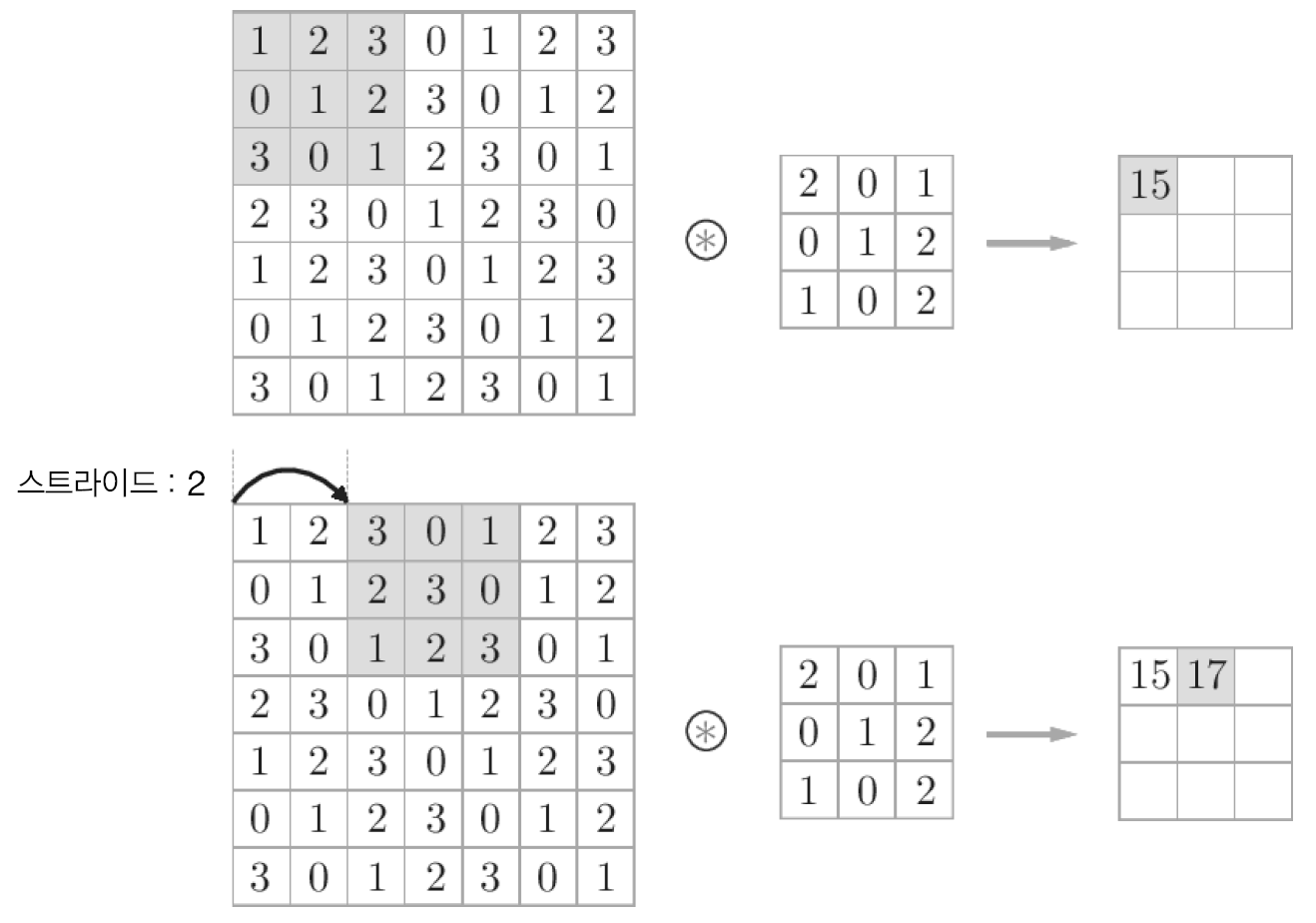
입력 크기 , 필터 크기 , 출력 크기 , 패딩 , 스트라이드
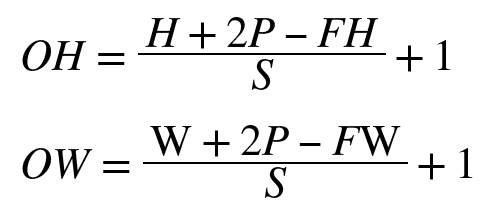
2.5 3차원 데이터의 합성곱 연산
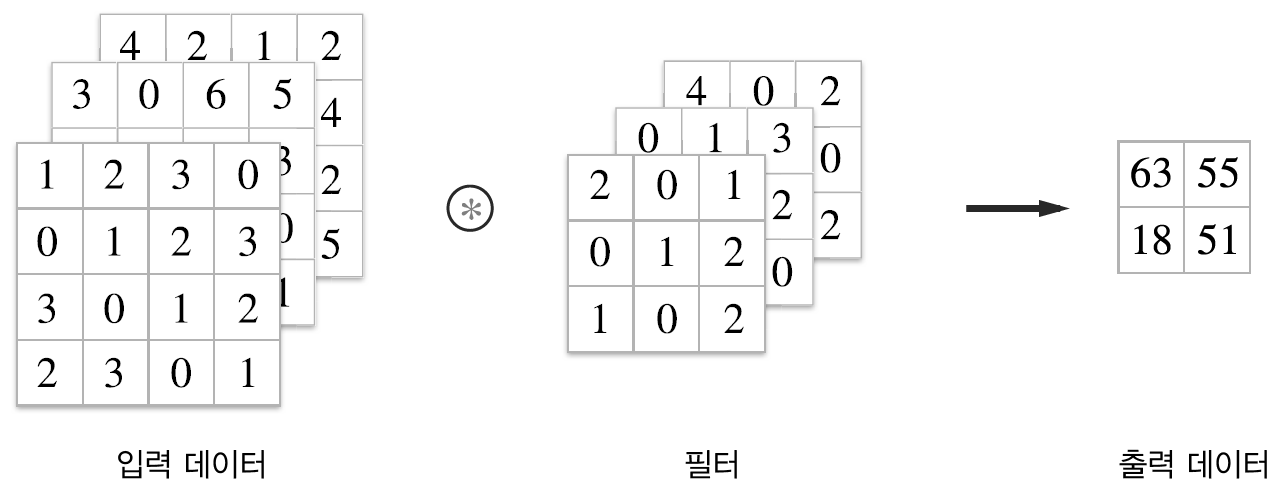
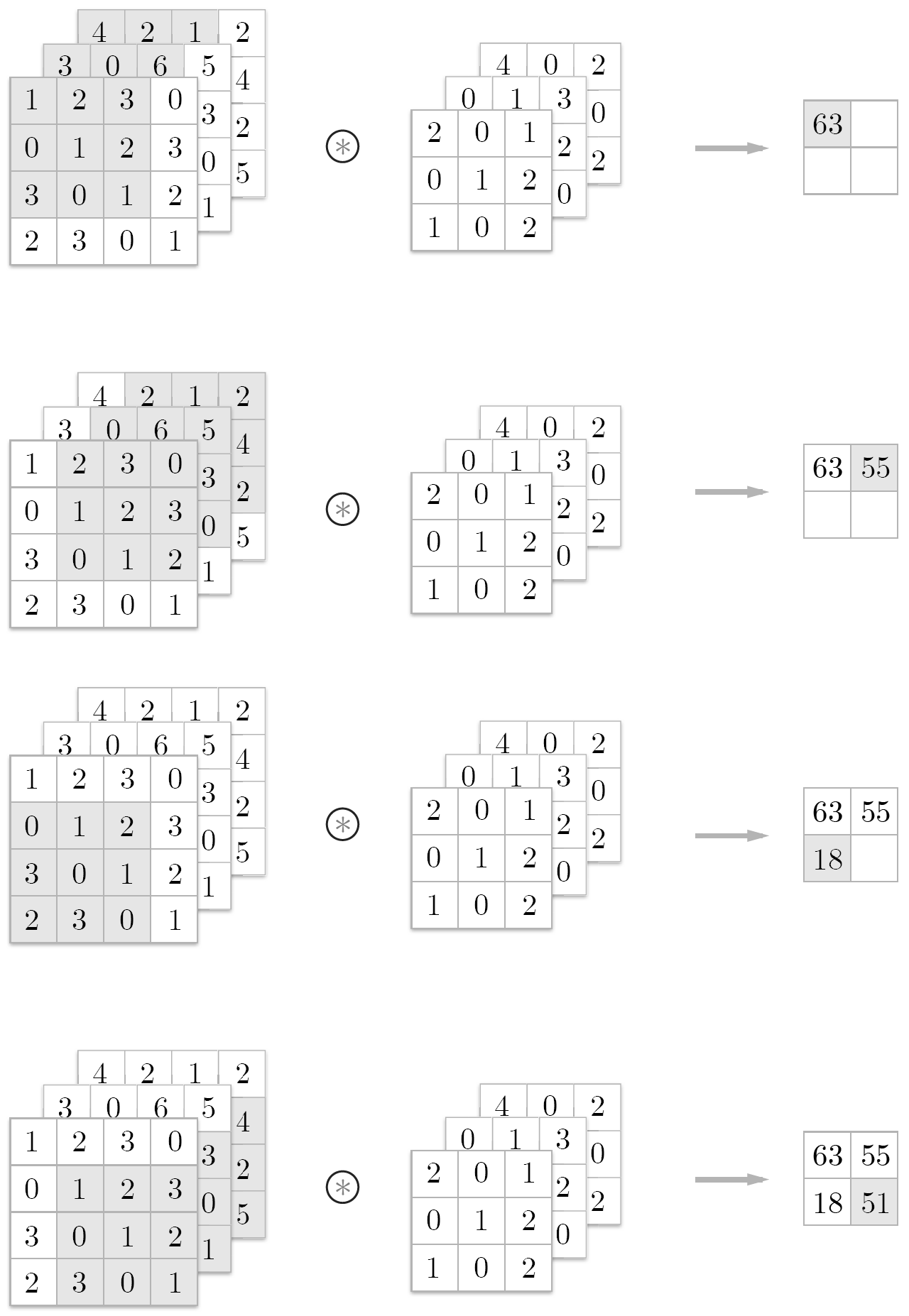
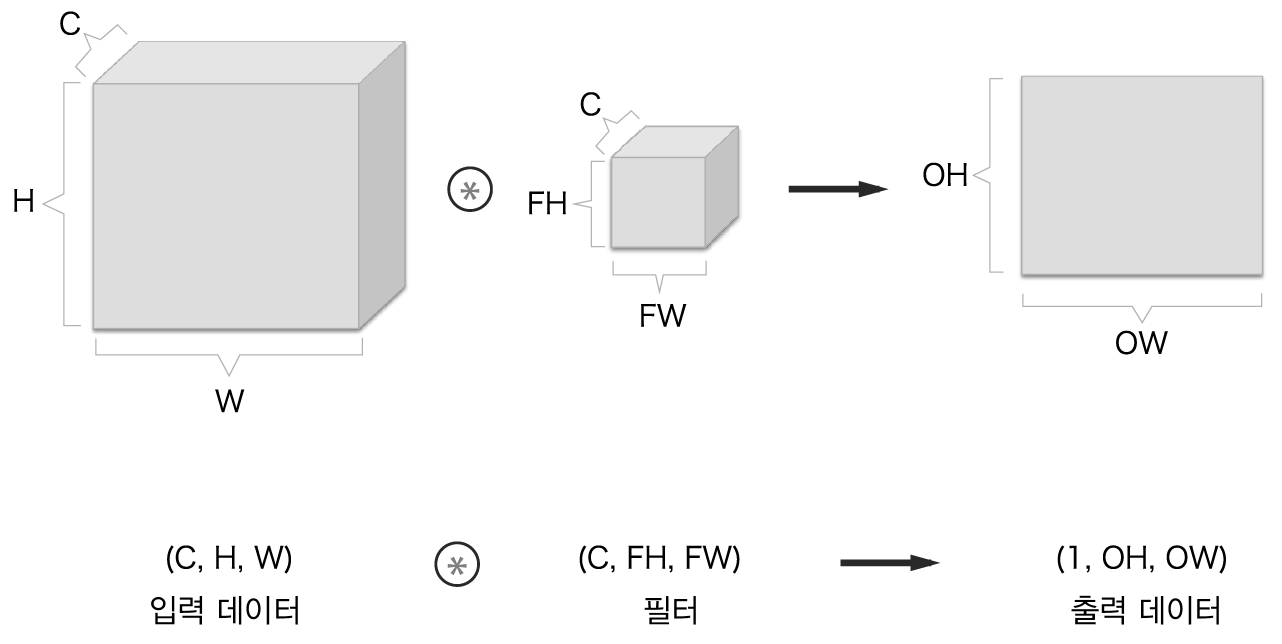
2.6 블록으로 생각하기
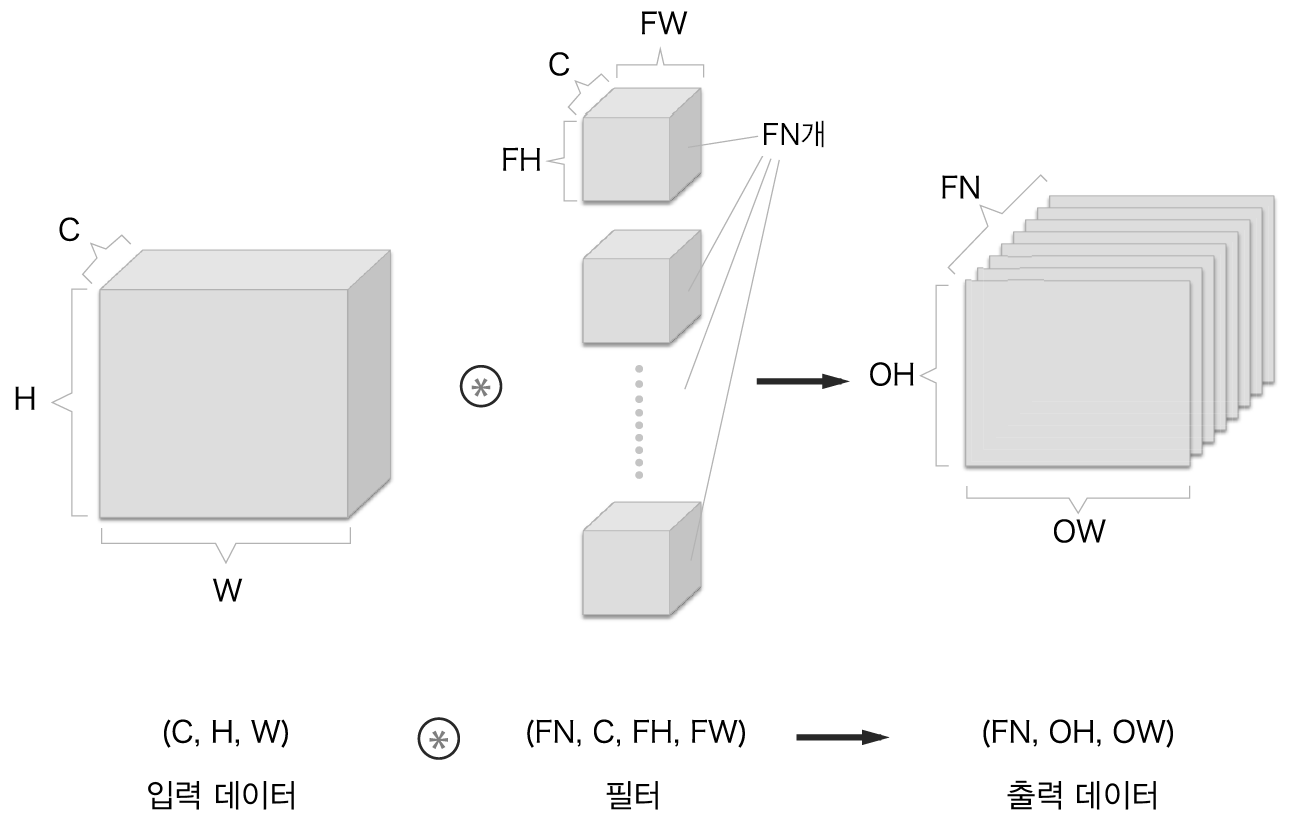
여러 필터를 사용한 합성곱 연산
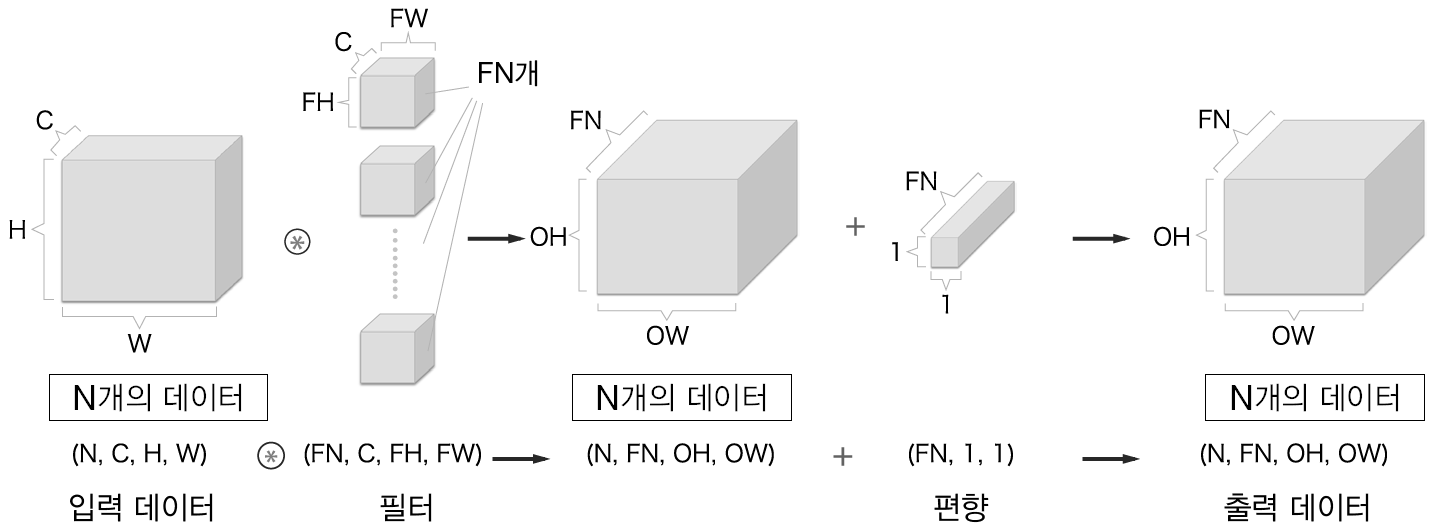
2.7 배치처리
3 풀링 계층
→ 세로/가로 방향의 공간을 줄이는 연산
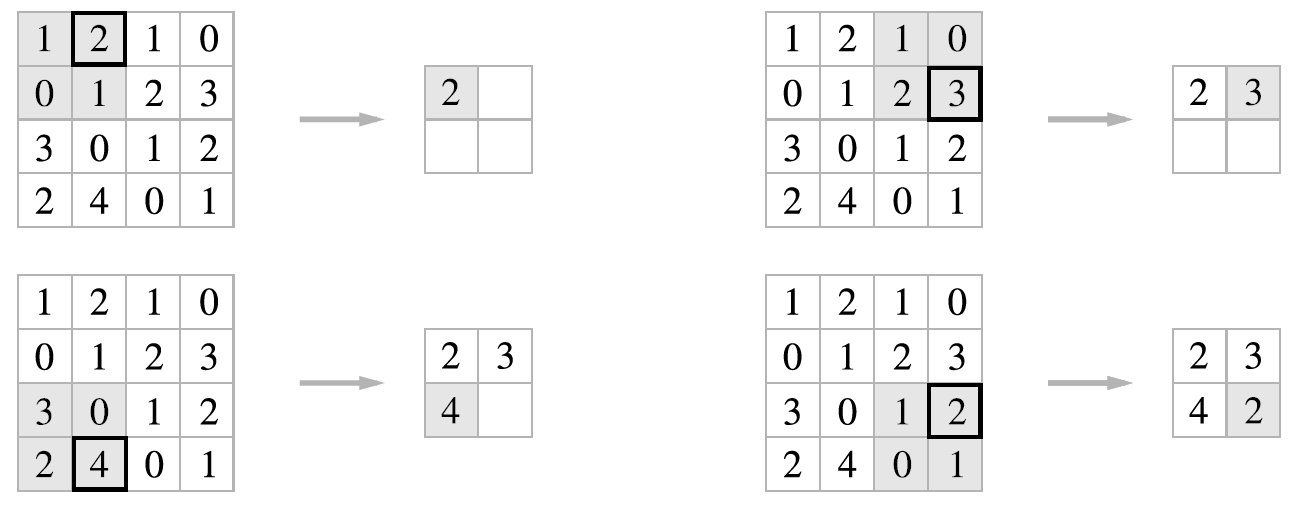
max pooling, average pooling, 등 여러 pooling 방법이 있다.
- 이미지 분야에서는 주로 max pooling 사용
3.1 풀링 계층의 특징
- 학습해야 할 매개변수가 없음 → 풀링은 단순히 최댓값이나 평균을 취해 통과시켜주는 것이므로, 학습할 것이 없음
- 채널 수가 변하지 않음 → 입력 데이터의 채널 수 그대로 출력 데이터로 내보내므로 채널마다 독립적으로 계산됨
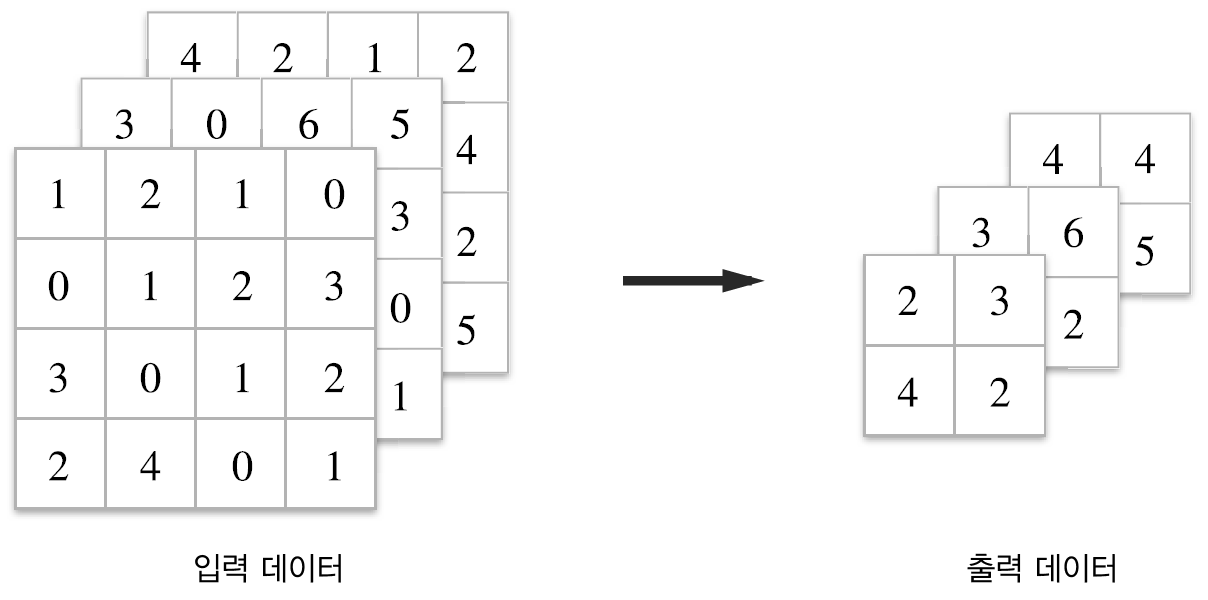
- 입력의 변화에 영향을 적게 받는다(robust) → 입력데이터가 조금 변해도 풀링의 결과는 잘 변하지 않음
4 합성곱/풀링 계층 구현하기
4.1 4차원 배열
4.2 im2col로 데이터 전개하기
-
합성곱 연산을 직접 구현하려면 for문을 여러 겹 써야함
→ Convolution 연산의 시간 복잡도
ex) pad=0, stride=1인 경우,
out_w = w - fw + 1, out_h = h - fh + 1
이 때, 이미지 크기 h, w에 대하여 단 한 장의 2차원 이미지 연산을 위해서
out_w * out_h 만큼의 element-wise multiplication 연산이 필요
MNIST dataset의 이미지 크기가 28*28 이므로, (3, 3)필터를 사용하였을 때
단 한장의 이미지에 대한 convolution을 위해 26*26번의 element-wise multiplication 수행
→ 50000개의 이미지 전체를 한다면 262650000, 즉 33,800,000회의 연산 수행
만약 channel이 더 늘어난다면, n_channel 만큼 더 곱해짐
이러한 높은 복잡도를 줄이기 위해,
- numpy에서는 원소에 접근할 때 for문을 사용하지 않는 것이 바람직(성능이 떨어짐)
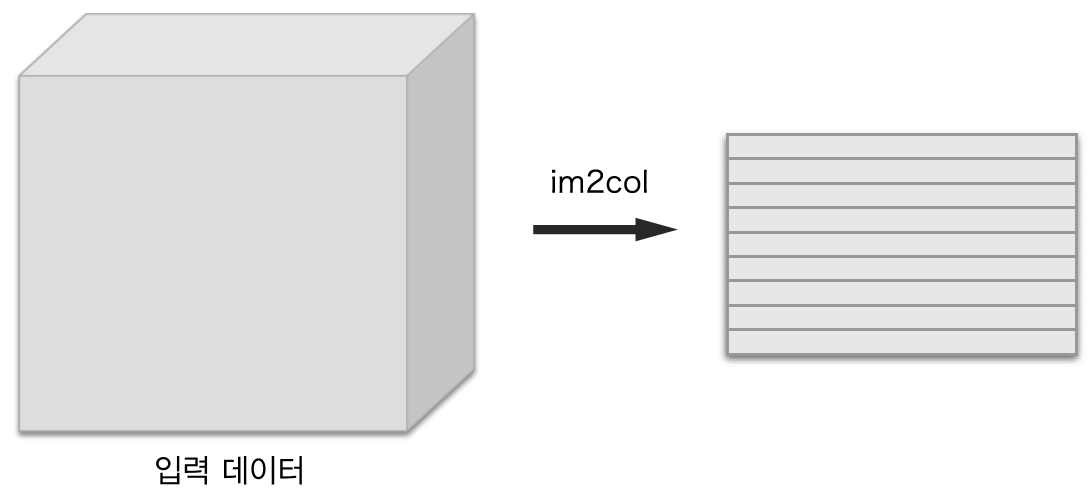
- im2col은 필터링하기 좋게 입력 데이터를 전개
- 입력 데이터에서 필터를 적용하는 영역(3차원 블록)을 한 줄로 늘어놓음
- 이러한 전개를 필터를 적용하는 모든 영역에 대해 수행
4.3 합성곱 계층 구현하기
im2col(input_data, filter_h, filter_w, stride=1, pad=0)# im2col 직접 구현해보기
import numpy as np
def im2col(input_data, filter_h, filter_w, stride=1, pad=0):
N, C, H, W = input_data.shape
out_h = (H + 2 * pad - filter_h)//stride + 1
out_w = (W + 2 * pad - filter_w)//stride + 1
img = np.pad(input_data, [(0, 0), (0, 0), (pad, pad), (pad, pad)], 'constant')
col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))
for y in range(filter_h):
y_max = y + stride * out_h
for x in range(filter_w):
x_max = x + stride * out_w
col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]
col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N * out_h * out_w, -1)
return coldef col2im(col, input_shape, filter_h, filter_w, stride=1, pad=0):
N, C, H, W = input_shape
out_h = (H + 2*pad - filter_h) // stride + 1
out_w = (W + 2*pad - filter_W) // stride + 1
col = col.reshape(N, out_h, out_w, C, filter_h, filter_w).transpose(0, 3, 4, 5, 1, 2)
img = np.zeros((N, C, H + 2*pad + stride - 1, W + 2*pad + stride - 1))
for y in range(filter_h):
y_max = y + stride*out_h
for x in range(filter_w):
x_max = x + stride*out_w
img[:, :, y:y_max:stride, x:x_max:stride] += col[:, :, y, x, :, :]
return img[:, :, pad:H + pad, pad:W + pad]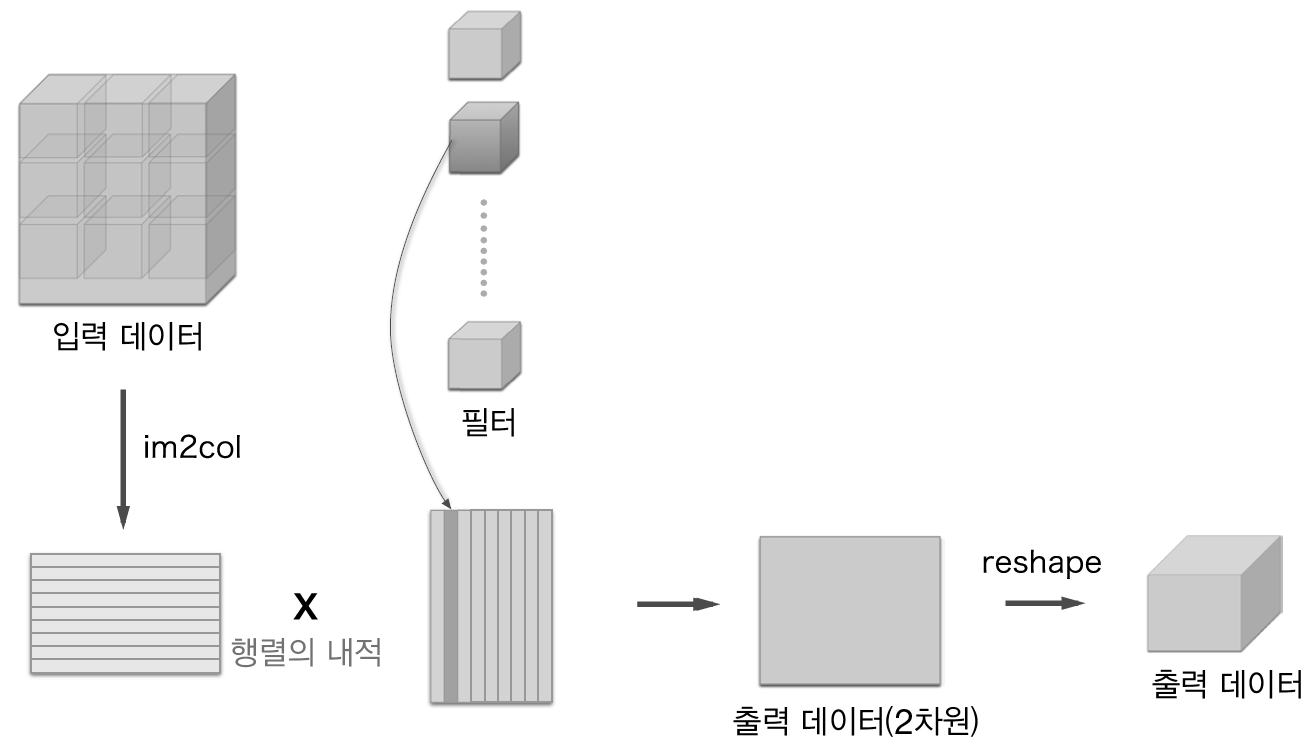
import sys, os
sys.path.append(os.pardir)
from common.util import im2col
x1 = np.random.rand(1, 3, 7, 7) # (데이터 수, 채널 수, 높이, 너비)
col1 = im2col(x1, 5, 5, stride=1, pad=0)
print(col1.shape) # (9, 75)
x2 = np.random.rand(10, 3, 7, 7)
col2 = im2col(x2, 5, 5, stride=1, pad=0)
print(col2.shape) # (90, 75)- FN : 필터 개수
- C : 채널
- FH : 필터 높이
- FW : 필터 너비
class Convolution:
def __init__(self, W, b, stride=1, pad=0):
self.W = W
self.b = b
self.stride = stride
self.pad = pad
def forward(self, x):
FN, C, FH, FW = self.W.shape
N, C, H, W = x.shape
out_h = int(1 + (H + 2*self.pad - FH) / self.stride)
out_w = int(1 + (W + 2*self.pad - FW) / self.stride)
col = im2col(x, FH, FW, self.stride, self.pad)
col_W = self.W.reshape(FN, -1).T # 필터 전개
out = np.dot(col, col_W) + self.b
out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)
return out4.4 풀링 계층 구현하기
class Pooling:
def __init__(self, pool_h, pool_w, stride=1, pad=0):
self.pool_h = pool_h
self.pool_w = pool_w
self.stride = stride
self.pad = pad
def forward(self, x):
N, C, H, W = x.shape
out_h = int(1 + (H - self.pool_h) / self.stride)
out_w = int(1 + (W - self.pool_w) / self.stride)
# unfold
col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
col = col.reshape(-1, self.pool_h*self.pool_w)
# max pool
out = np.max(col, axis=1)
# reshape
out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)
return out5 CNN 구현하기
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *
from common.gradient import numerical_gradient
class SimpleConvNet:
"""단순한 합성곱 신경망
conv - relu - pool - affine - relu - affine - softmax
Parameters
----------
input_size : 입력 크기(MNIST의 경우엔 784)
hidden_size_list : 각 은닉층의 뉴런 수를 담은 리스트(e.g. [100, 100, 100])
output_size : 출력 크기(MNIST의 경우엔 10)
activation : 활성화 함수 - 'relu' 혹은 'sigmoid'
weight_init_std : 가중치의 표준편차 지정(e.g. 0.01)
'relu'나 'he'로 지정하면 'He 초깃값'으로 설정
'sigmoid'나 'xavier'로 지정하면 'Xavier 초깃값'으로 설정
"""
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))
# 가중치 초기화
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \
np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# 계층 생성
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""손실 함수를 구한다.
Parameters
----------
x : 입력 데이터
t : 정답 레이블
"""
y = self.predict(x)
return self.last_layer.forward(y, t)
def accuracy(self, x, t, batch_size=100):
if t.ndim != 1 : t = np.argmax(t, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i*batch_size:(i+1)*batch_size]
tt = t[i*batch_size:(i+1)*batch_size]
y = self.predict(tx)
y = np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def numerical_gradient(self, x, t):
"""기울기를 구한다(수치미분).
Parameters
----------
x : 입력 데이터
t : 정답 레이블
Returns
-------
각 층의 기울기를 담은 사전(dictionary) 변수
grads['W1']、grads['W2']、... 각 층의 가중치
grads['b1']、grads['b2']、... 각 층의 편향
"""
loss_w = lambda w: self.loss(x, t)
grads = {}
for idx in (1, 2, 3):
grads['W' + str(idx)] = numerical_gradient(loss_w, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_w, self.params['b' + str(idx)])
return grads
def gradient(self, x, t):
"""기울기를 구한다(오차역전파법).
Parameters
----------
x : 입력 데이터
t : 정답 레이블
Returns
-------
각 층의 기울기를 담은 사전(dictionary) 변수
grads['W1']、grads['W2']、... 각 층의 가중치
grads['b1']、grads['b2']、... 각 층의 편향
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 결과 저장
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):
self.layers[key].W = self.params['W' + str(i+1)]
self.layers[key].b = self.params['b' + str(i+1)]# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
# from simple_convnet import SimpleConvNet
from common.trainer import Trainer
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
# 시간이 오래 걸릴 경우 데이터를 줄인다.
#x_train, t_train = x_train[:5000], t_train[:5000]
#x_test, t_test = x_test[:1000], t_test[:1000]
max_epochs = 20
network = SimpleConvNet(input_dim=(1,28,28),
conv_param = {'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},
hidden_size=100, output_size=10, weight_init_std=0.01)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=max_epochs, mini_batch_size=100,
optimizer='Adam', optimizer_param={'lr': 0.001},
evaluate_sample_num_per_epoch=1000)
trainer.train()
# 매개변수 보존
network.save_params("params.pkl")
print("Saved Network Parameters!")
# 그래프 그리기
markers = {'train': 'o', 'test': 's'}
x = np.arange(max_epochs)
plt.plot(x, trainer.train_acc_list, marker='o', label='train', markevery=2)
plt.plot(x, trainer.test_acc_list, marker='s', label='test', markevery=2)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()reference : Deep Learning from scratch, chapter 7
