
1. Review - LSTM
- RNN의 grad vanish problem을 해결하기 위한 RNN varient
- 필요한 정보를 그대로(no non-linear activation) 흘려보내는 Cell state 채널
- gate를 사용하여 정보를 필터링
- 필터링 하는 채널마다 별도의 게이트 사용
2. GRU의 핵심 아이디어
2.1. LSTM 한계점
각 채널마다 gate를 따로 사용 → 모델이 너무 복잡해짐
더 컴팩트하게 정보를 처리 할 수 없을까? → GRU
2.2. 대안
- Cell state 삭제 → 와 non-linear 과정을 분리
- gate 수 축소
2.3. GRU flow

- Reset gate (≒ LSTM - forget gate) : 불필요 정보 삭제
- Update gate (≒ LSTM - input gate & output gate) : 하나의 gate로 통합; 가중치로 사용
- : non-linear activation 을 거치지 않음
- 각 step dimension은 모두 와 같다
중요 : Gate가 알아서 학습된다는 믿음!을 가지는 것
3. 결론
3.1. vanishing gradient problem을 해결하였는가?
- non-linear activation 가지가 따로 분리되어 있음 (flow 그림 참조)
→ vanishing gradient problem을 해결
3.2. 성능 차이
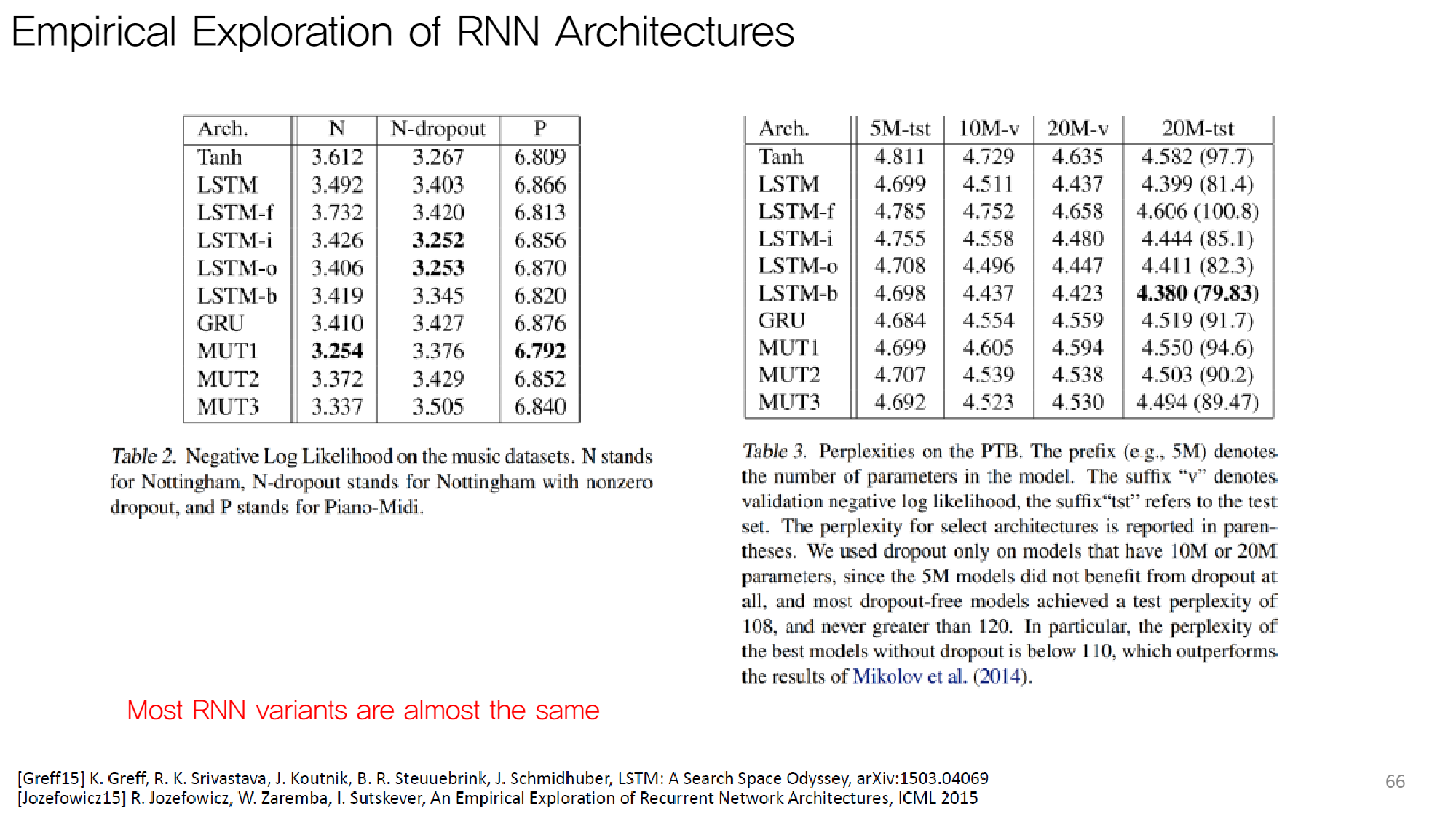
( : Vanilla RNN )
Most RNN varients are almost the same!
- GRU와 LSTM 사이에 엄청나게 유의미한 성능차이는 없다! (GRU 진땀승)
- Vanilla RNN과 RNN variants는 차이가 난다.
3.3. LSTM은 어떻게 강팀이 되었나
GRU 연산 속도가 더 빠른데 LSTM을 더 메이저하게 사용하는 이유
- [강연자 추측]
당시 하드웨어 성능 이슈로 더 컴팩트한 알고리즘이 필요했다
→ 그루 개념 고안
→ 하드웨어 발전이 빨라서 그루 개발 시점엔 굳이 더 컴팩트한 알고리즘의 수요가 없어졌다
참고 & 이미지 출처 : 2019 KAIST 딥러닝 홀로서기 세미나

반갑습니다