
1. Review - RNN
- Task에 따라 여러 RNN 알고리즘이 파생된다
e.g. 인코더/디코더 프레임워크 - 와 을 combine
- : 각 곱한 후 element wise
- : concentrate한 후 곱함
→ algebraic 관점에서는 동일
- combine한 결과에 매트릭스 곱해서 space로 변환
- 한계 : 역전파 단계에서 를 여러번 미분 → 기울기가 빠르게 0으로 수렴
- sequence가 길수록 학습이 안됨
그 대안으로 나온 방안이 LSTM
2. LSTM의 핵심 아이디어
2.1. Standard RNN의 문제점
한 채널에 두 가지 역할을 담아야 한다
1. 이전 step output
2. 다음 step에 넘어가는 정보
2.2. 대안
Cell state(중요한 정보만 흘러가는 information flow)를 추가하자!
어떻게 중요한 정보만 남길 것인가?
Gate를 사용하자!
Hidden state(각 step output)는 Cell state를 적절히 가공해서 내보내자!
(RNN은 hidden state 채널만 존재)
2.3. LSTM Flow
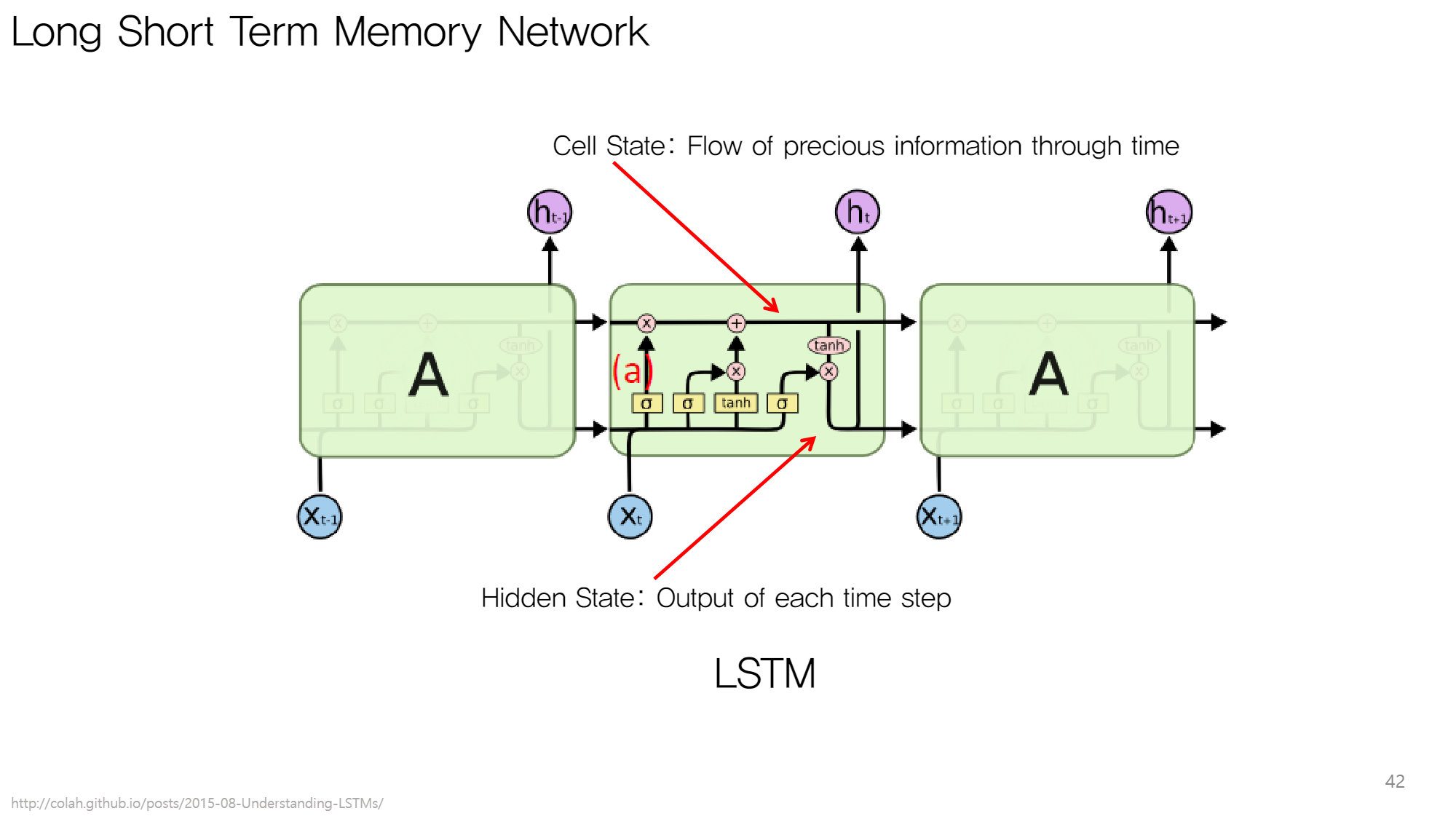
- 에서 불필요한 정보 삭제
- 새로운 input ()를 보고 의 중요한 정보 업데이트 →
- 가공하여 생성
- 다음 step으로 과 전달
2.4. 핵심 개념 : Gate
- 목적 : coefficient로 각각의 정보 중요도 계산하기 위함
- 형태 : 0~1 사이의 값으로 이루어진 벡터
- 필터링 단계에 따라 다른 게이트 사용 (파라미터 구별)
- forget gate : 에서 불필요한 정보 필터링
- input gate : (임시 cell state)에서 중요한 정보만 필터링
- output gate : 를 가공하여 로 만듦
3. 수식
3.1. Gate
- : 0~1의 값으로 Transformation output을 매핑
- : input vector
- : Linear Transformation
(Cell state의 dimension으로 input vector를 바꾸는 값)
- 원하는 정보만 남긴 값 = 게이트 Cell state
3.2. 전체 Flow (2.3. 참조)
-
정보 필터링 : forget gate 구성
-
정보 업데이트 : input gate 구성
(바닐라 RNN과 동일)
-
Cell state
-
가공 : output gate 구성
-
전달
4. 결론
4.1. vanishing gradient problem을 해결하였는가?
정보가 한참 나중 seq에서 사용될 때
- LSTM
- Cell state: non-linear activation function이 없음
→ 정보가 지워지지 않는 한 바로 input으로 들어가 h 만드는 데 사용
- Cell state: non-linear activation function이 없음
- RNN : 계속 가 중첩
∴ 실제로 Sequential Data를 다룰 때 LSTM을 더 많이 쓴다!
4.2. 한계
flow의 각 단계가 중복된다
→ 더 간단하게 forget gate, input gate, output gate를 해결할 수 없을까?
LSTM보다 더 효율적인 방식 : GRU
참고 & 이미지 출처 : 2019 KAIST 딥러닝 홀로서기 세미나

반갑습니다