오전문제는 41일차 메모 실습 코드 손코딩
My SQL 5
select 명령문의 절(clause) - group by
-
각 select 명령문은 select와 from이라는 절을 가지기 때문에 적어도 2개의 절을 가지고 있다. 그리고 where, group by, order by 같은 절은 선택적으로 사용된다.
-
group by절은 where 또는 from절 앞에 올 수 없다. 그리고 order by절이 사용된다면 이 절은 항상 가장 나중에 사용된다.
-
order by절은 마지막에 수행되는 절로 정렬 대상의 결과 값에 null이 존재한다면 null이 가장 적은 값이 되어 asc 정렬에는 맨 처음에 출력되고, desc인 경우는 맨 마지막에 출력된다.
-
having절은 group by 절이 사용되어야 만이 사용할 수 있다. > where의 역할 (함수를 사용하기 위한)
- having 절은 group by 절에서 생성된 중간 테이블에서 동작한다.
select ...
from ...
order by ...
select ...
from ...
group by ...
having ...
select ...
from ...
where ...각 절이 수행되는 순서는 2번(FROM 절) -> 3번(WHERE 절) -> 4번(GROUP BY절) -> 5번(HAVING 절) -> 1번(SELECT 절) -> 6번(ORDER BY절) 순으로 처리가 진행된다.
문제
-
등록 테이블("FEE")에서 장학금(jang_total)을 지급 받은 학생의 학번(stu_no)과 장학금 내역을 출력하라.
select stu_no, jang_total from fee where jang_total > 0;
-
등록 테이블("FEE")에서 장학금(jang_total)을 1,000,000 이상 지급 받은 학생 중에서 2회 이상 지급받은 학생의 학번(stu_no)과, 지급받은 횟수를 학번 내림차순으로 출력하라.
-
select stu_no, count(*) from fee where jang_total >= 1000000 group by stu_no having count(*) > 1 order by stu_no desc;- group by는 데이터를 특정 기준에 따라 그룹화할 떄 사용된다. 해당 열의 고유한 값들로 데이터를 그룹화
- group by로 stu_no를 묶어서 having절을 이용해 조건을 설정해 원하는 데이터 출력
-
-
수강신청 테이블(attend)에서 2006 년도 1학기에 수강 신청한 학생의 학번(stu_no)과 수강년도(att_year), 학기(att_term), 교과목코드(sub_code), 교수코드(prof_code)를 교수코드 오름차순으로 나타내어라.
select stu_no, att_year, att_term, sub_code, prof_code from attend where att_year = '2006' and att_term = 1 order by prof_code;
용어 정리
DDL(Data Definition Language)
만들고/고치고/지우고/이름바꾸는 명령어 - 정의
-
데이터를 두는 공간을 '테이블', 테이블의 형식을 '스키마', 이러한 테이블의 스키마를 정의하는데 쓰이는 명령어
-
CREATE, ALTER, DROP, RENAME, TRUNCATE
DML(Data Manipulation Language)
DML로 데이터를 추가/변경/조회/삭제 - 조작
- INSERT, UPDATE, SELECT, DELETE, COMMIT, ROLLBACK
DCL(Data Control Language)
db에 접근하고 객체들을 사용하도록 권한을 주고 회수하는 명령어 - 제어
- GRANT, REVOKE
TCL(Transaction control Language)
논리적인 일의 단위, 물리적으로 보이는 처리단위가 아니라 시스템상의 처리단위를 말한다. >> 하나의 작업 단위 : 트랜잭션
-
COMMIT & ROLLBACK
-
DML(Data Manipulation Language)가 실행되는 것과 동시에 트랜잭션이 진행이 된다.
-
ROLLBACK : 트랜잭션의 처리과정에서 발생한 변경사항을 취소한다.
- 단, DML(INSERT, DELETE, UPDATE)는 가능하지만 DDL(CREATE, DROP등)은 불가능하다.
스키마 SCHEMA
데이터베이스에서 자료의 구조, 자료의 표현 방법, 자료 간의 관계를 형식 언어로 정의한 구조
-
데이터베이스 관리 시스템(DBMS)이 주어진 설정에 따라 데이터베이스 스키마를 생성한다.
- 데이터베이스 사용자가 자료를 저장, 조회, 삭제, 변경할 때 DBMS는 자신이 생성한 데이터베이스 스키마를 참조하여 명령을 수행한다.
-
외부 스키마(External Schema) : 프로그래머나 사용자의 입장에서 데이터베이스의 모습으로 조직의 일부분을 정의한 것
-
개념 스키마(Conceptual Schema) : 모든 응용 시스템과 사용자들이 필요로하는 데이터를 통합한 조직 전체의 데이터베이스 구조를 논리적으로 정의한 것
-
내부 스키마(Internal Schema) : 전체 데이터베이스의 물리적 저장 형태를 기술하는 것
관계형 데이터베이스 용어
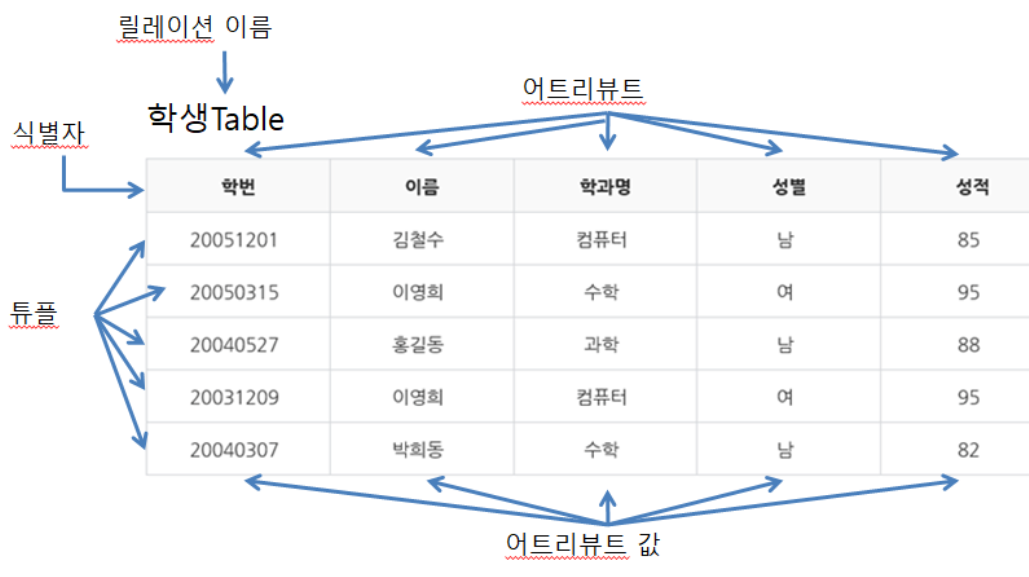
-
릴레이션(relation) : 개체(Entity) - 데이터들의 집합을 의미 >> 튜플과 에트리뷰트로 데이터를 정렬하여 관리한다. >> 테이블
-
한 릴레이션에 정의된 튜플들은 모두 다르다.
-
한 릴레이션에 정의된 튜플들은 순서에 무관하다.
-
튜플들은 시간에 따라 변한다.
-
릴레이션 스키마를 구성하는 에트리뷰트의 값은 동일해도 된다.
-
에트리뷰트는 더 이상 쪼갤 수 없는 원자값으로 구성된다.
-
릴레이션을 구성하는 튜플을 유일하게 식별하기 위한 속성들의 부분집합을 키(Key)로 설정한다.
-
-
식별자: 기본키primary key
-
튜플(tuple), 레코드(record), 로우(Row): 릴레이션의 각 행을 의미
- 카디널리티(cardinality) : 튜플들의 수
-
속성(Attibute), 컬럼(column) : 릴레이션의 각 열을 의미
- 차수(Degree) : 속성들의 수
-
릴레이션 스키마(relation schema) : 속성 이름들(학번, 이름, 학과명, 성별 성적,)
-
릴레이션 인스턴스(relation instance) : 튜플들의 집합(속성들의 실제값)
-
도메인(Domain) : 릴레이션에 포함된 각각의 속성들이 가질 수 있는 값들의 집합으로, 하나의 도메인을 여러 속성에서 공유할 수 있다.
- 릴레이션에 저장되는 데이터 값들이 본래 의도했던 값들만 저장되고 관리하기 위해서
SQL 함수
검색 연산자
값 비교 연산자
-
SELECT * FROM sample21 WHERE no <> 2;- = 연산자가 서로 같은 값인지를 비교하는 연산자인 데 반해,
- <> 연산자는 서로 다른 값인지를 비교하는 연산자이다.
- != 연산자는 서로 다른 값인지를 비교하는 연산자이다.
and / or
and는 or에 비해 우선순위가 높다.
-
SELECT * FROM sample24 WHERE a <> 0 AND b <> 0;: a열과 b열 모두 이 아닌 행 검색 -
SELECT * FROM sample24 WHERE a <> 0 OR b <> 0;: a열이 0이 아니거나, b열이 0이 아닌 행을 검색
NOT
SELECT * FROM sample24 WHERE NOT(a<>0 OR b<>0);: a열이 0이 아니거나 b열이 0이 아닌 행을 제외한 나머지 행을 검색
null값 찾기
-
SELECT * FROM sample21 WHERE birthday IS NULL;>> birthday열이 null값인 데이터 추출 -
SELECT * FROM sample21 WHERE birthday IS NOT NULL;>> birthday열이 null이 아닌 데이터 추출
패턴매칭에 의한 검색
Like패턴
-
패턴을 정의할 때 사용할 수 있는 메타문자로는 % 와 __가 있다. >>_ 언더바는 문자 하나 의미
-
SELECT * FROM sample25 WHERE text LIKE 'SQL%';: text열이 'sql'로 시작하는 문자열의 행을 검색 -
SELECT * FROM sample25 WHERE text LIKE '%SQL%';: text열이 'sql'을 포함하는 행을 검색(sql이 문장에 들어만 가있으면 된다.) -
SELECT * FROM sample251 WHERE text LIKE '__';: 문자 두개인 행 검색 (몇개든 가능) -
SELECT * FROM sample251 WHERE text LIKE 'a__';: a로 시작하는 3글자 -
SELECT * FROM sample251 WHERE text LIKE '가_다';: text열에 처음 문자가 가이고, 마지막 문자가 다인 3글자 행을 검색 -
SELECT * FROM sample25 WHERE text LIKE '%\%%';: Text열이 %를 포함하는 행을 검색
%를 LIKE로 검색할 경우에는 \%로 한다! > 역슬래쉬 이용
를 LIKE로 검색할 경우에는 \로 한다. > 마찬가지
문자열 상수 ' 의 이스케이프
-
'it's' >> 작은 따옴표가 3개로 에러가 난다. 그럼 어떻게 해야하냐?
- 'It''s' 이렇게 작은 따옴표를 하나 더 써서 사용한다. '과 끝의 '이 정확하게 표기되지 않으면 에러가 발생한다.
SQL에서는 '를 2개 연속해서 기술하는 것으로 이스케이프 처리를 할 수 있다.
정렬 연산자 order by, limit
order by 사용 >> 실질적으로 저장된 데이터가 변경되는 것이 아닌 출력 순서가 바뀌는 것
-
ORDER BY로 검색 결과 정렬하기
-
SYNTAX WHERE 구 뒤에 ORDER BY 구를 지정하는 경우
SELECT 열명 FROM 테이블명 WHERE 조건식 ORDER BY 열명
-
SYNTAX FROM 구 뒤에 ORDER BY 구를 지정하는 경우
SELECT 열명 FROM 테이블명 ORDER BY 열명
-
- SYNTAX 내림차순으로 정렬
SELECT 열명 FROM 테이블명 ORDER BY 열명 DESC;
- SYNTAX 오름차순으로 정렬
SELECT 열명 FROM 테이블명 ORDER BY 열명 ASC;
- age열의 값을 DESC로 내림차순 정렬하기
SELECT * FROM sample31 ORDER BY age DESC;
- age열의 값을 ASC로 오름차순 정렬하기
SELECT * FROM sample31 ORDER BY age asc;
asc는 생략 가능 >> 기본적으로 asc로 정렬되기 때문에
-
복수의 열을 지정해 정렬하기
-
SELECT * FROM sample32 ORDER BY a, b;: sample32를 a열과 b열로 정렬하기 -
SELECT * FROM sample32 ORDER BY a ASC, b DESC;>> a가 같으면, b로 정렬
-
-
NULL 값의 정렬순서
- NULL 값을 가장 작은 값으로 취급해 ASC(오름차순)에서는 가장 먼저, DESC(내림차순)에서는 가장 나중에 표시한다.
-
결과 행 제한하기 - LIMIT = 출력값을 제한
페이지를 설정할때 자주 사용 1페이지에 limit 20, 2페이지에 limit 20 offset 20이런식으로
SELECT 열명 FROM 테이블명 WHERE 조건식 ORDER BY 열명 LIMIT 행수
-
sample33에 LIMIT 3 으로 상위 3건만 취득하기
SELECT * FROM sample33 LIMIT 3;
-
sample33을 정렬 후 LIMIT 3 으로 상위 3건만 취득하기
SELECT * FROM sample33 ORDER BY no DESC LIMIT 3;
- LIMIT를 사용할 수 없는 데이터베이스에서의 행 제한
LIMIT는 표준 SQL이 아니기 때문에 MySQL과 PostgreSQL 이외의 데이터베이스에서는 사용할 수 없다. SQL SERVER에서는 LIMIT와 비슷한 기능을 하는 'TOP'을 사용할 수 있다.
-
SELECT TOP 3 * FROM sample33;>> orable에는 limit, top이 존재하지 않고, rownum이라는 열을 이용해 where문에서 조건을 지정해 행을 제한한다.-
SELECT * FROM sample33 WHERE ROWNUM <= 3;- ROWNUM은 클라이언트에게 결과가 반환될 때 각 행에 할당되는 행 번호이다. 단, ROWNUM으로 행을 제한할 때는 WHERE 구로 지정하므로 정렬하기 전에 처리되어 LIMIT로 행을 제한한 경우와 결괏값이 다르다.
-
sample33에서 LIMIT 3 OFFSET 0 으로 첫 번째 페이지 표시
SELECT * FROM sample33 LIMIT 3 OFFSET 0;>> 0번째 부터 3개로 리밋
-
SYNTAX OFFSET 지정
SELECT 열명 FROM 테이블명 LIMIT 행수 OFFSET 위치
-
sample33에서 LIMIT 3 OFFSET 3으로 두 번째 페이지 표시
SELECT * FROM sample33 LIMIT 3 OFFSET 3;>> 3번쨰 부터 3개
-
sample33에서 LIMIT 3 OFFSET 6으로 세 번째 페이지 표시
SELECT * FROM sample33 LIMIT 3 OFFSET 6;>> 6번째 부터 3개 (남은 데이터가 3개가 안되어도, 남은 데이터 출력 8이 남았다면 그냥 8출력 )
-
별칭 붙이기 as
별칭 붙이기
-
에일리어스(alias)라고도 불리는 별명은 영어, 숫자, 한글 등으로 지정할 수 있다.
- 별명을 한글로 지정하는 경우에는 여러 가지로 오작동하는 경우가 많으므로 더블쿼트("")로 둘러싸서 지정한다. 이 룰은 데이터베이스 객체의 이름에 ASCII 문자 이외의 것을 사용할 경우에 해당한다.
-
SELECT *, price * quantity AS amount FROM sample34;>> price * quantity 식에 amount라는 별명 붙이기
키워드 as는 생략 가능하다
SELECT price * quantity "금액" FROM sample34;
SELECT price * quantity AS SELECT FROM sample34; # 예약어로는 이름을 줄수 없다. 에러
SELECT price * quantity AS "SELECT" FROM sample34;-
WHERE 절에서 금액을 계산하고 2000원 이상인 행 검색하기
에러 예시
정답
-
SELECT *, price * quantity AS amount FROM sample34 WHERE price * quantity >= 2000;-
WHERE 구와 SELECT 구의 내부처리 순서
-
WHERE 구에서의 행 선택, SELECT 구에서의 열 선택은 데이터베이스 서버 내부에서 WHERE 절 -> SELECT 절의 순서로 처리된다.
-
WHERE 구로 행이 조건에 일치하는지 아닌지를 먼저 조사한 후에 SELECT 구에 지정된 열을 선택해 결과로 반환하는 식으로 처리한다.
-
-
에러
-
SELECT *, price * quantity AS amount FROM sample34 WHERE amount >= 2000;>> amount라는 열이 실제로 존재하는 것이 아닌 별칭을 주고,별칭으로 where절에서 조건지정x- SELECT 명령을 실행해 보면 amount라는 열은 존재하지 않는다는 에러가 발생한다.
-
별명은 SELECT 구문을 내부 처리할 때 붙여진다.
- 즉, WHERE 구의 처리는 SELECT 구보다 선행되므로 WHERE 구에서 사용한 별칭은 아직 내부적으로 지정되지 않은 상태가 되어 에러가 발생하는 것이다.
-
SELECT 구에서 지정한 별명은 WHERE 구 안에서 사용할 수 없다!
-
ORDER BY 구에서 금액을 내림차순으로 정렬하기
SELECT *, price * quantity AS amount FROM sample34 ORDER BY price * quantity DESC;
-
금액의 별명을 사용해 내림차순으로 정렬하기
SELECT *, price * quantity AS amount FROM sample34;
-
ORDER BY구에서 별명을 사용해 정렬하기
SELECT *, price * quantity AS amount FROM sample34 ORDER BY amount DESC;
-
SELECT 구에서 지정한 별명을 마치 그런 열이 존재하는 것처럼 ORDER BY 구에서 사용할 수 있다.
-
WHERE 구에서는 별명을 사용할 수 없다.
- WHERE 구 -> SELECT 구 -> ORDER BY 구 >> 이렇게 내부처리가 되기 때문에 ORDER BY 구에서는 SELECT 구에서 지정한 별명을 사용할 수 있고, where절에서는 사용 x
숫자 연산자
null값의 연산
- NULL + 1
- 1 + NULL
- 1 + 2 * NULL
- 1 / NULL
위 연산결과는 모두 null이 된다.
소수점 연산
DECIMAL(M,D)
M은 소수 부분을 포함한 실수의 총 자릿수를 나타내며, 최댓값은 65다.
D는 소수 부분의 자릿수를 나타내며, D가 0이면 소수 부분을 가지지 않는다.
-
SELECT 10%3; >> 오라클에서는 불가능
-
SELECT MOD(10, 3); >> mod() :나머지 연산
-
CREATE TABLE sample341(amount decimal(7, 2)); >> 7은 실수의 총 자릿수, 2는 소수점 자리수
-
INSERT INTO sample341 VALUES(5961.60);
-
INSERT INTO sample341 VALUES(2138.40);
-
INSERT INTO sample341 VALUES(1080.00);
-
ROUND()
-
SELECT amount, ROUND(amount) FROM sample341;-
ROUND 함수의 두 번째 인수를 지정해, 소수점 둘째 자리를 반올림
SELECT amount, ROUND(amount, 1) FROM sample341;>> 소수점 첫쨰자리까지 출력한다는 의미로 반올림은 둘째 자리에서 이뤄진다.
-
ROUND 함수의 두 번째 인수를 지정해 10단위를 반올림
SELECT amount, ROUND(amount, -2) FROM sample341;>> 두번째 인수가 음수일 경우, 소수점 아래의 자릿수가 아닌 십진수의 자릿수를 지정하게 된다.- ,
amount값이159이면,ROUND(amount, -2)는200이 됩니다. 만약amount값이143이면,ROUND(amount, -2)는100이 된다.
-
-
문자열 연산자
문자열 결합 연산자
| 연산자/함수 | 연산 | 데이터베이스 |
|---|---|---|
| + | 문자열 결합 | SQL Server |
| | | 문자열 결합 | |
| CONCAT | 문자열 결합 | MySQL |
-
문자열 결합으로 단위를 연결해 결과 얻기 - concat() : 연결
SELECT CONCAT(quantity, unit) FROM sample35;
-
공백추가
SELECT CONCAT(quantity,' ', unit) FROM sample35;
-
앞 4자리(년) 추출 - substring() : 자르기
SELECT SUBSTRING('20140125001', 1, 4);>> 2014 출력
-
5째 자리부터 2자리(월) 추출
SELECT SUBSTRING('20140125001', 5, 2);>> 01출력
-
공백 제거 - TRIM() : 공백 제거 / length() : 글자 수
-
SELECT LENGTH(' ABC ');>> 10출력 -
SELECT LENGTH(TRIM(' ABC '));>> 공백 제거되서 3출력
-
갱신 및 삭제
update문
UPDATE sample41 SET no = no + 1;>> 모든 행의 번호에 1을 더한다.
복수열 update
-
두 구문으로 나누어 UPDATE 명령 실행 - 원래 하던 구문
-
UPDATE sample41 SET a = 'xxx' WHERE no = 2;>> a를 xxx로 변환, no 가 2인애를 -
UPDATE sample41 SET b = '2014-01-01' WHERE no = 2;
-
-
하나로 묶어서 UPDATE 명령 실행- , (컴마)를 이용
-
UPDATE sample41 SET a = 'xxx', b = '2014-01-01' WHERE no = 2; -
UPDATE sample41 SET no = no + 1, a = no;>> no를 1 증가 후 a에 no 넣음 -
UPDATE sample41 SET a = no, no = no + 1;>> a에 no를 넣고, no를 증감
위 두 구문은 순서가 영향이 미치는걸 알 수 있다. 단, mysql에서만 해당되고, oracle은 순서와 상관없이, 증가 되기 전의 원래 가지고 있던 값이 대입된다.
데이터베이스 제품에 따라 결과가 달라진다.
-
두 UPDATE 명령은 콤마(,)로 구분된 갱신 식의 순서가 서로 다르다. 그리고 이들 UPDATE 명령을 각각 실행한 결과가 서로 다르게 나온다.
null로 갱신하기
UPDATE sample41 SET a = NULL;>> not null 제약이 설정되어 있는 열은 null이 허용되지 않음
-
물리 삭제 : sql의 delete명령을 사용해 직접 데이터를 삭제하는 방식
-
논리 삭제 : 테이블에서 실제로 행을 삭제하는 대신, UPDATE 명령을 이용해 '삭제플래그'의 값을 유효하게 갱신해두자는 발상에 의한 삭제 방법 >> 삭제는 실제로 안하지만, 삭제한 척 하는 >> 해당 데이터를 0으로 둔다던가 정하기 나름
- 실제 테이블 안에 데이터는 남아있지만, 참조할 때에는 '삭제플래그'가 삭제로 설정된 행을 제외하는 SELECT 명령을 실행한다. 결과적으로 해당 행이 삭제된 것처럼 보인다.
장단점
-
장점 : 데이터를 삭제하지 않기 때문에 삭제되기 전의 상태로 간단히 되돌릴 수 있다는 것을 꼽을 수 있다.
-
단점 : 삭제해도 데이터베이스의 저장공간이 늘어나지 않는 점 >> 실제로 삭제 안하니까 똑같음
데이터베이스의 크기가 증가함에따라 검색속도가 떨어지는 점을 들 수 있다.
애플리케이션 측 프로그램에서는 삭제임에도 불구하고 UPDATE 명령을 실행하므로 혼란을 야기하기도 한다.
함수
집계함수
집합으로부터 하나의 값을 계산하는 것을 '집계'라 부른다. 이러한 이유로 집계함수를 SELECT 구에 쓰면 WHERE 구의 유무와 관계없이 결과값으로 하나의 행을 반환한다.
+ CURRENT_TIMESTAMP : 글을 쓴 오늘 날짜가 들어감 테이블 만들 때 사용 가능
CREATE TABLE SAMPLE421(
no INT AUTO_INCREMENT PRIMARY KEY,
a DATETIME DEFAULT CURRENT_TIMESTAMP,
b varchar(10)
);- COUNT(집합) : 행의 개수
- SUM(집합) : 총 합
- AVG(집합) : 평균
- MIN(집합) : 최소값
- MAX(집합) : 최대값
count()로 행 개수 계산
-
SELECT COUNT(*) FROM sample51; # 5>> 모든 행의 개수 -
SELECT COUNT(*) FROM sample51 WHERE name = 'A'; #2>> name이 A인 행 개수WHERE 구로 조건을 지정하면 테이블 전체가 아닌, 검색된 행이 COUNT로 넘겨져 where문의 조건에 맞는 행의 개수를 구할 수 있다.
집계함수와 null값
-
집계함수는 집합 안에 NULL 값이 있을 경우 이를 제외하고 처리한다.
-
집계함수는 집합 안에 NULL 값이 있을 경우 무시한다!
중복 제거
-
DISTINCT
-
SELECT DISTINCT name FROM sample51;: DISTINCT를 지정 ,(콤마)는 붙이지 않는다. -
SELECT 구에 지정하는 ALL 또는 DISTINCT는 중복된 값을 제거할 것인지 설정하는 스위치와 같은 역할을 한다. 생략할 경우 >> ALL로 간주
SELECT COUNT(ALL name), COUNT(DISTINCT name) FROM sample51;# 4 3
합계 구하기
-
SUM() >> 문자열형이나 날짜 시간형의 집합에서는 합계를 구할 수 없음
- NULL값 무시 == count() 와 마찬가지로 null값을 제거한 뒤에 합계를 낸다.
-
SELECT SUM(quantity) FROM sample51;
평균값 구하기
-
AVG() >> null값을 제거한 뒤에 평균값 계산
-
만약 null을 0으로 간주해 평균을 내고 싶다면 CASE를 이용해 변환해서 계산하면 된다.
SELECT AVG(CASE WHEN quantity IS NULL THEN 0 ELSE quantity END) AS avgnull0 FROM sample51;>> quantity가 null이면 0으로, 아니면 그 자체로 처리해라 / 이것의 별명을 avgnull0으로 준것 (as생략 가능)
-
IFNULL() 을 사용해서도 가능 > 이게 더 간편
SELECT AVG(IFNULL(quantity, 0)) AS avgnull0 FROM sample51;
-
최소값/최대값 구하기
-
MIN() / MAX() : 문자열 형과 날짜 시간형에도 사용가능하다. NULL값을 무시한다.
-
SELECT MIN(quantity), MAX(quantity), MIN(name), MAX(name) FROM sample51;
그룹화
-
GROUP BY >> 집계함수와 함꼐 사용하지 않으면 의미x / 그룹화된 각각의 그룹이 하나의 집합으로서 집계함수로 넘겨준다. (실제 열 이름을 사용해야 함 해당 열을 기준으로 집계함수를 실행하는 것이므로 )
-
SELECT * FROM 테이블명 GROUP BY 열1, 열2, ... -
SELECT name, COUNT(name), sum(quantity) FROM sample51 GROUP BY name;
Having문으로 조건 지정 (order by와 함께 사용)
WHERE 구에서는 집계함수를 사용할 수 없다!
SELECT name, COUNT(name) FROM sample51 GROUP BY name HAVING COUNT(name) = 1;
에러 예제
SELECT name, COUNT(name) FROM sample51 WHERE COUNT(name) = 1 GROUP BY name; >>에러. 해석 순서 때문에- where이 group by보다 먼저 처리되기때문에 뭐를 묶은지 인식하지 못한다. 그러므로 having으로 줘야하는 것이다.
from > WHERE 구 -> GROUP BY 구 -> HAVING 구 -> SELECT 구 -> ORDER BY 구 : 내부처리 순서
SELECT name AS n, COUNT(name) AS cn FROM sample51 GROUP BY n HAVING cn = 1;>> mysql정상 실행 / 오라클은 X >> 해석 순서때문에 별칭을 사용할 수 없다. having이 select보다 먼저 처리
정답
SELECT name AS n, COUNT(name) AS cn FROM sample51 GROUP BY n HAVING cn = 1;>> mysql에서는 정상 실행 BUT 오라클에서는 불가능- group by 에 조건을 줄 때 having을 준다.
복수열의 그룹화
GROUP BY에 지정한 열 이외의 열은 집계함수를 사용하지 않은 채 SELECT 구에 기술해서는 안 된다.
에러예시
-
SELECT no, name, quantity FROM sample51 GROUP BY name;-
데이터 베이스에 따라서는 에러가 날 수 있다. -> MySQL8.0 마이너 업데이트 되면서 다시 에러
- name은 GROUP BY 에서 지정하므로 OK. >> no, quantity는 지정할 수 없다.
A의 값이 1, 2 같이 두 개이므로 어느 값을 출력해야 될 지 모르기 때문에. - 직계함수를 사용하지 않으면 뭘 출력해야 할지 뚜렷하지 않기 떄문에 에러가 남
- name은 GROUP BY 에서 지정하므로 OK. >> no, quantity는 지정할 수 없다.
-
정답
-
SELECT MIN(no), name, SUM(quantity) FROM sample51 GROUP BY name; -
no와 quantity로 그룹화한다면 GROUP BY no, quantity로 지정한다. 이처럼 GROUP BY에서 지정한 열이라면 SELECT 구에 그대로 지정해도 된다.
SELECT name, quantity FROM sample51 GROUP BY name, quantity;
결과값 정렬
-
name 열로 그룹화해 합계를 구하고 내림차순으로 정렬
SELECT name, COUNT(name), SUM(quantity) FROM sample51 GROUP BY name ORDER BY SUM(quantity) DESC;
문제
검색 문제
-
다음을 sample21이라는 이름의 테이블을 만들자.
no 정수
name 문자열
birthday 날짜
address 문자열 -
다음 세 개의 데이터를 삽입하자.(sample21)
1, '박준용', '1976-10-18', '대구광역시 수성구'
2, '김재진', NULL, '대구광역시 동구'
3, '홍길동', NULL, '서울특별시 마포구' -
sample21 테이블에서 no가 2가 아닌 데이터들의 모든 정보를 검색.
select * from sample21 where no != 2;
-
sample21 테이블에서 birthday가 NULL인 모든 행의 모든 정보를 검색.
select * from sample21 where birthday is null;
-
다음 sample24 테이블을 만들자.
no 정수
a 정수
b 정수
c 정수 -
sample24테이블에 다음 데이터를 순서대로 삽입하자.
1, 1 ,0, 0
2, 0 ,1, 0
3, 0 ,0, 1
4, 2, 2, 0
5, 0, 2, 2 -
sample24테이블에서 a 열과 b 열이 모두 0이 아닌 행 검색
select * from sample24 where a != 0 and b != 0;
-
a 열이 0이 아니거나 b열이 0이 아닌 행을 검색
select * from sample24 where a != 0 or b != 0;
-
a열이 0이 아니거나 b열이 0이 아닌 행을 제외한 나머지 행을 검색
select * from sample24 where not(a <> 0 or b <> 0);a와 b가 0인 행 추출
-
다음 sample25 테이블을 만들자.
no 정수
text 문자열 -
다음 데이터 3개를 삽입하자.(sample25)
1, 'SQL은 RDBMS를 조작하는 언어이다.'
2, 'LIKE에서는 메타문자 %와 _를 사용할 수 있다.'
3, 'LIKE는 SQL에서 사용할 수 있는 술어 중 하나이다.' -
sample25테이블에서 Text열이 'SQL로 시작하는 행을 검색
select * from sample25 where text like 'sql%';
-
sample25테이블에서 Text열이 'SQL을 포함하는 행을 검색
select * from sample25 where text like '%sql%';
-
sample25테이블에서 Text열이 %를 포함하는 행을 검색
select * from sample25 where text like '%\%%';
정렬 문제
-
다음 sample31 테이블을 만들자.
name 문자열
age 정수
address 문자열- 다음 3개의 데이터를 삽입하자.
'A씨', 36, '대구광역시 중구'
'B씨', 18, '부산광역시 연제구'
'C씨', 25, '서울특별시 중구'
- 다음 3개의 데이터를 삽입하자.
-
sample31의 모든 데이터를 출력하는 데 age로 오름차순 정렬
select * from sample31 order by age;
-
sample31의 모든 데이터를 출력하는 데 address로 오름차순 정렬
select * from sample31 order by address;
-
sample31의 모든 데이터를 출력하는 데 age로 내림차순 정렬
select * from sample31 order by age desc;
-
다음 5개의 데이터를 삽입하시오(sample32)
1, 1
2, 1
2, 2
1, 3
1, 2 -
sample32를 a열만으로 정렬하기
select * from sample32 order by a;
-
sample32를 a열로 먼저 정열하고 b열로 정렬하기
select * from sample32 order by a, b;
-
sample32를 b열로 먼저 정열하고 a열로 정렬하기
select * from sample32 order by b, a;
-
sample32를 a열로 먼저 오름차순 정열하고 b열로 내림차순 정렬하기
select * from sample32 order by a, b desc;
-
다음 sample33 테이블을 만드시오.
no 정수- 다음 7개의 데이터를 삽입하시오.
1
2
3
4
5
6
7
- 다음 7개의 데이터를 삽입하시오.
-
sample33에 상위 3건만 출력하기
select * from sample33 limit 3;
-
sample33을 내림 차순 정렬 후 상위 3건만 출력하시오
select * from sample33 order by no desc limit 3;
-
sample33에서 0번째에서 3건을 출력하기.
select * from sample33 limit 3 offset 0;
-
sample33에서 3번째에서 3건을 출력하기.
select * from sample33 limit 3 offset 3;
-
sample33에서 6번째에서 3건을 출력하기.
select * from sample33 limit 3 offset 6;
별칭 함수 문제
-
다음 sample34테이블을 만들자.
no 정수
price 정수
quantity 정수- 다음 3개의 데이터를 삽입하자.
1, 100, 10
2, 230, 24
3, 1980, 1
- 다음 3개의 데이터를 삽입하자.
-
sample34의 모든 열을 출력하고, 거기에 price * quantity 식에 'amount'라는 별명 붙여서 출력하자.
select *, price * quantity as amount from sample34;
-
sample34의 모든 열을 출력하고, 거기에 price * quantity 식에 '금액'라는 별명 붙여서 출력하자.
select *, price * quantity "금액" from sample34;
-
sample34의 모든 열을 출력하고, 거기에 price * quantity 식에 'SELECT'라는 별명 붙여서 출력하자.
select *, price * quantity "SELECT" from sample34;
-
amount(price quantity)가 2000이상인 sample34의 모든 열을 출력하고, 거기에 price quantity 식에 'amount'라는 별명 붙여서 출력하자.
select *, price * quantity as amount from sample34 where price * quantity >= 2000;
연산 문제
- 다음 연산결과는?
-
NULL + 1
-
1 + NULL
-
1 + 2 * NULL
-
1 / NULL >>>>>>>>>>>>싹다 null
-
amount(price quantity)가 2000이상인 sample34의 모든 열을 출력하고, 거기에 price quantity 식에 'amount'라는 별명 붙여서 출력하는데, amount를 내림차순으로 정렬하자.ORDER BY 구에서 금액을 내림차순으로 정렬하기
select * , price * quantity as amount from sample34 where price * quantity >= 2000 order by amount desc;
-
10을 3으로 나눈 나머지를 두가지 방법을 출력하자.
-
select 10 % 3; -
select mod(10, 3);
-
-
다음 sample341 테이블을 만들자.
amount 실수(전체 7자리, 소수점 2자리)create table sample341(amount decimal(7, 2));
다음 3개의 데이터를 삽입하자.
5961.60
2138.40
1080.00 -
amount와 amount를 소수점을 반올림하여 정수부분만 출력하자(sample341)
select amount, round(amount) from sample341;
-
amount와 amount를 소수점을 둘째자리에서 반올림하여 소수점 1번째 자리까지만 출력하자.(sample341)
select amount, round(amount, 1) from sample341;
-
amount와 amount를 정수를 십의 자리에서 반올림하여 출력하자.(sample341)
예) 5961.60 ==> 6000
ROUND 함수의 두 번째 인수를 지정해 10단위를 반올림select amount, round(amount, -2) from sample341;
-
다음 sample35 테이블을 만들자.
no 정수
price 정수
quantity 정수
unit 문자열다음 3개의 데이터를 삽입하자.
1, 100, 10, '개'
2, 230, 24, '캔'
3, 1980, 1, '장' -
quantity와 unit를 결합하여 출력하자.(sample35)
select concat(quantity, unit) from sample35;
-
quantity와 unit사이에 공백을 결합하여 출력하자.(sample35)
select concat(quantity,' ', unit) from sample35;
-
'20140125001' 년 추출하여 출력
select substring('201401250001', 1, 4);
-
'20140125001' 월 추출하여 출력
select substring('201401250001', 5, 2);
-
' ABC '의 길이 출력
select length( ' ABC ');
-
' ABC '의 공백빼고 길이 출력
select length(trim( ' ABC '));
함수 문제
-
sample41을 다음과 같이 만들자
no 정수
a 문자열
b 날짜-
create table sample41(no int auto_increment primary key, a varchar(20), b datetime default current_timestamp);다음 두개의 데이터를 넣자.(sample41)
1, "ABC", "2014-01-25"
no 에 2를, a에 "XYZ"
-
-
b의 값이 NULL인 것을 검색하자(sample41)
select * from sample41 where b is null;
-
컬럼 b의 값이 NULL인 것을 모두 '2014-09-07'로 변경하자(sample41)
update sample41 set b = '2014-08-07' where b is null;
-
모든 행의 번호(no)에 1을 더한다.(sample41)
update sample41 set no = no + 1;
-
sample41 테이블에서 no가 2인 것의 a의 값을 'xxx'로 하자.
update sample41 set a = 'xxx' where no = 2;
-
sample41 테이블에서 no가 2인 것의 b의 값을 '2014-01-01' 하자.
update sample41 set b = '2014-01-01' where no = 2;
-
sample41 테이블에서 no가 2인 것의 a의 값을 'xxx', b의 값을 '2014-01-01'로 하자.
update sample41 set a = 'xxx', b = '2014-01-01' where no = 2;
-
sample41 테이블의 no의 값을 1추가하고, a에 no의 값을 넣자.
update sample41 set no = no + 1, a = no where no = 2;
-
sample41 테이블의 a의 값에 no의 값을 넣고, no의 값에 1을 추가하자.
update sample41 set a = no, no = no + 1 where no = 2;
-
sample41 테이블의 a의 값에 NULL을 넣자.
update sample41 set a = null;
-
다음과 같이 sample42 테이블을 만드시오.
no 정수 자동증가
a 문자열
flag 정수 기본값 0create table sample42(no int auto_increment primary key, a char(3), flag int default 0);
- 다음 4개의 데이터를 삽입하시오.(sample42)
a에 'ABC'
a에 'XYZ'
a에 'GHI'
a에 'JKL'
-
sample 42의 모든 데이터 조회
select * from sample42;
-
다음 SAMPLE421 테이블을 만든다.
no 정수 자동증가 기본키
a 날짜시간 기본값 현재시간
b 문자열create table sample421(no int auto_increment primary key, a datetime default current_timestamp, b varchar(5));
- sample421에 다음 3개의 데이터를 넣는다.
b에 'HI'
b에 'GOOD'
b에 'NICE'
-
sample421의 모든 데이터 조회
select * from sample421;
-
다음 sample51테이블을 만든다.
no 정수
name 문자열
quantity 정수- 다음 5개의 데이터를 삽입한다.(sample51)
1, 'A', 1
2, 'A', 2
3, 'B', 10
4, 'C', 3
5, NULL, NULL
- 다음 5개의 데이터를 삽입한다.(sample51)
-
sample51테이블의 모든 행의 갯수를 출력
select count(*) from sample51;
-
name이 'A'인 것의 모든 데이터를 출력.
select * from sample51 where name = 'a';
-
name이 'A'인 것의 행의 갯수를 출력
select count(*) from sample51 where name = 'a';
-
sample51의 모든 데이터를 출력.
select * from sample51;
-
sample51 테이블의 no의 행의 갯수와 name의 행의 갯수를 출력.
select count(no), count(name) from sample51;
-
sample51 테이블의 모든 이름을 출력
select name from sample51;
-
sample51 테이블에서 이름을 출력하는데 중복된 이름은 제외하고 출력
select distinct name from sample51;
-
sample51 테이블의 모든 이름의 행의 갯수와 중복된 이름을 제외한 이름의 행의 갯수를 출력하시오.
select count(name), count(distinct name) from sample51;
-
sample51 테이블의 quantity의 평균과 quantity의 합을 quantity의 행의 갯수로 나눈 값을 출력하시오.
select avg(quantity) , sum(quantity) / count(quantity) from sample51;
-
sample51 테이블의 quantity의 평균을 구하는 데 quantity가 null 이면 0으로 치환하여 평균을 구하시오.(두가지 방법)
-
select avg(ifnull(quantity, 0)) from sample51; -
SELECT AVG(CASE WHEN quantity IS NULL THEN 0 ELSE quantity END) AS avgnull0 FROM sample51;
-
-
sample51 테이블의 quantity 최솟값, quantity 최댓값, name 최솟값, name 최대값을 출력하시오.
select min(quantity), max(quantity), min(name), max(name) from sample51;
-
sample51 테이블의 이름을 그룹화하여 이름을 출력하시오.
select name from sample51 group by name;
-
sample51테이블에서 이름의 이름의 행의 갯수, quantity의 합을 이름으로 그룹화하여 출력하시오.
select count(name), sum(quantity) from sample51 group by name;
-
sample51 테이블에서 이름, 이름의 행의 갯수를 이름으로 그룹화하여 출력하시오.
SELECT name, COUNT(name) FROM sample51 GROUP BY name HAVING COUNT(name) = 1;
-
sample51 테이블에서 이름, 이름의 행의 갯수를 이름으로 그룹화하고 이름의 행의 갯수가 1인 것을 출력하시오.
select name, count(name) from sample51 group by name having count(name) = 1;
-
sample51 테이블에서 이름으로 그룹화하고 no의 최솟값, 이름, quantity의 합을 출력하시오.
select min(no), name, sum(quantity) from sample51 group by name;
-
sample51 테이블을 name, quantity로 그룹화하고 name, quantity를 출력하시오.
select name, quantity from sample51 group by name, quantity;
-
sample51 테이블을 name 열로 그룹화해 name, name의 행수, quantity의 합계를 구하고 quantity의 합계의 내림차순으로 정렬하여 출력하시오.
select name, count(name), sum(quantity) from sample51 group by name order by sum(quantity) desc;
