[논문 리뷰] Spectral images based sound classification using CNN with meaningful data augmentation (2020)
Paper Review
Abstract
- 많은 오디오 녹음에는 배경 소음, 매우 짧은 간격 및 클립의 급격한 변화가 있기 때문에, 짧은 audio clips을 통해 특징을 추출하고 다양한 소리를 분류하는 것은 쉽지 않다.
- possibility of overfitting의 위험을 피하기 위해 training samples 수는 많을 수록 좋다.
- 따라서, data aumentation이 필요 → 더 많은 training samples 제공 + 모델의 정확도와 성능 높일 수 있다.
- 본 연구에서 제안하는 방법론은 학습의 성과를 향상시키기 위한 의미 있는 data aumentation의 아이디어를 포함한다.
- 의미 있는 data augmentation과 함께 CNN을 사용하여 환경 소리 분류를 기반으로 하는 spectral images의 효과적인 접근 방식을 제안한다.
- 접근 방식
- 스펙트로그램 이미지의 형태로 오디오 클립의 기능을 정의한다.
- 이미지에 사용 가능한 data augmentation을 사용하는 대신, 오디오 클립에 직접 적용되는 variations을 고려하여 의미 있는 data augmentation을 제안한다.
- Result
- The ResNet-152 model
- ESC-10 data set : 99.04%
- Us8k data set : 99.49%
- DenseNet-161 model
-
ESC-50 data set : 97.57%
→ ESC-50 data set에서 이전에 발표된 모든 방법 중 최고의 정확도를 보여주었다.
-
- The ResNet-152 model
- 개선 : 의미 있는 data augmentation로 정확도를 향상시켰다.
Intro
- Mel spectrogram 기능을 사용하여, 스펙트로그램 이미지 형태로 오디오 클립의 기능을 정의.
- spectral images는 오디오 신호에 대한 주파수 스펙트럼의 visible representation으로 볼 수 있음.
- spectral images의 장점
- the audio signals are less periodic
- weak ambiance
- short interval
- the addition of noise on audio signals is much easy as compared with images
- Data set.
- Environment Sound Classification Data
- ESC-10
- ESC-50
- Urbansound8k (Us8k)
- Environment Sound Classification Data
Methodology
- the classification of sounds from the environment after converting the audio clips into spectrogram images.
- Model : DCNN, transfer learning models
2 approaches
1. M1 ) TAA (Traditional Augmentation Approach)
- traditional method available for various image-based training tasks
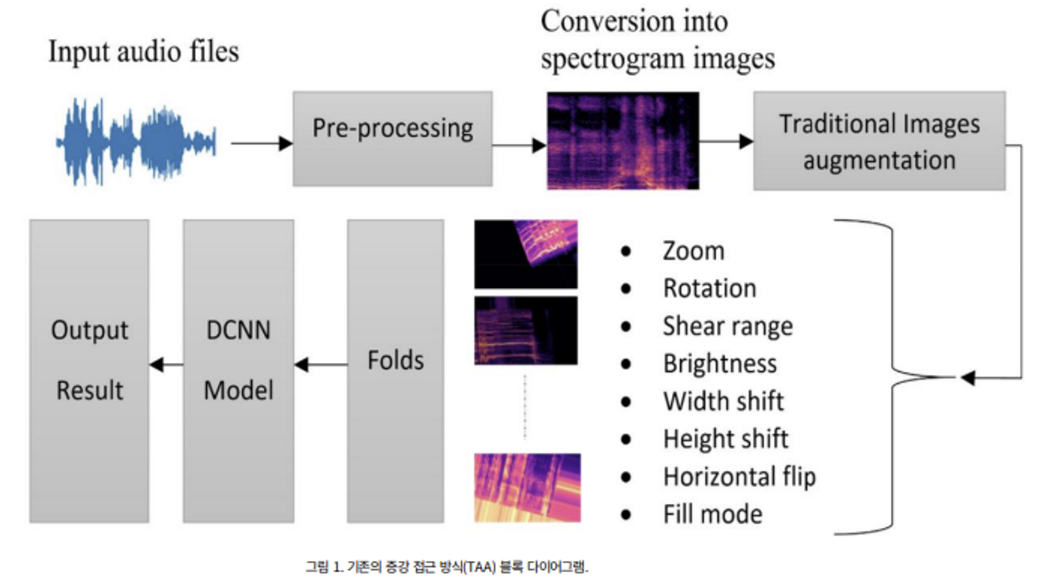
- used Kera’s package
- respective values
- Zoom range: 0.25
- Width shift: 0.20
- Fill mode: nearest
- Brightness range: [0.5,1.5]
- Rotation angle: 30
- Height shift: 0.20
- Shear range: 0.30
- Horizontal flip: True
1. M2 ) NAA (Novel Augmentation Approarch)
- classification of different sounds by using spectrogram images
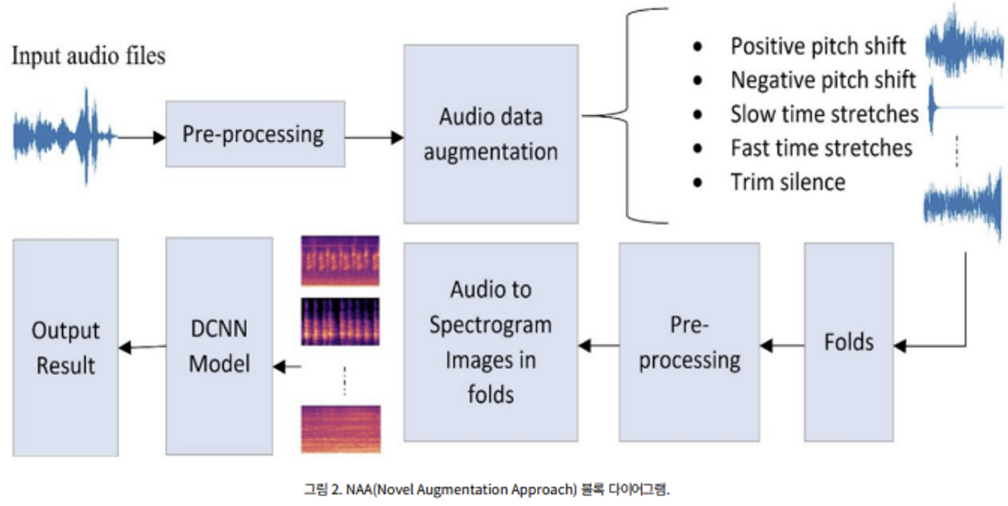
- 학습을 위해 generated audio clips는 Mel-spectrogram images로 변환.
- used Librosa library
[ 5 Transformation ]
1) Pitch shift transformation.
💡 shift audio to left/right with a random second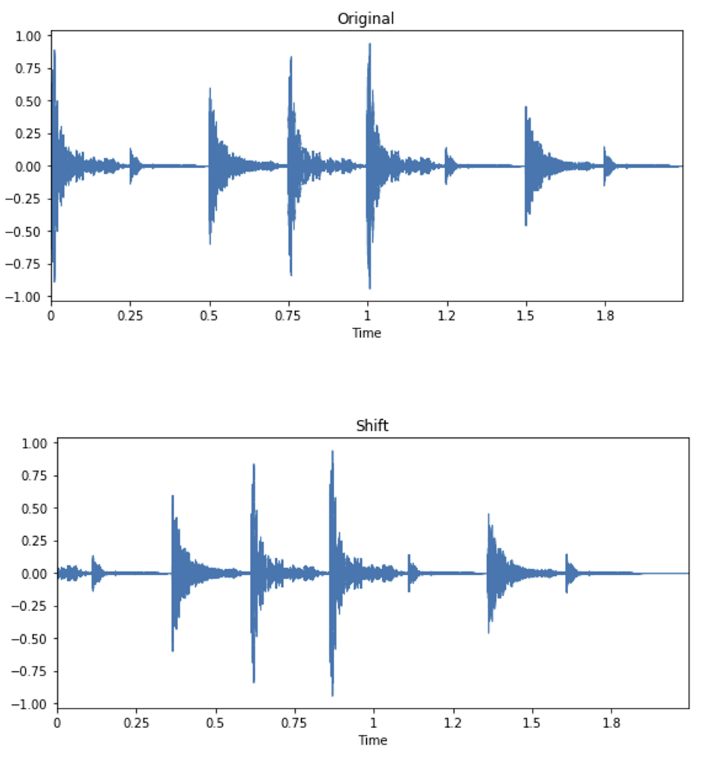
- Positive pitch shift (PPS)
- 양의 피치 이동 (+2)
- Negative pitch shift (NPS)
- 음의 피치 이동 (-2)
- code
import numpy as np def manipulate(data, sampling_rate, shift_max, shift_direction): shift = np.random.randint(sampling_rate * shift_max) if shift_direction == 'right': shift = -shift elif self.shift_direction == 'both': direction = np.random.randint(0, 2) if direction == 1: shift = -shift augmented_data = np.roll(data, shift) # Set to silence for heading/ tailing if shift > 0: augmented_data[:shift] = 0 else: augmented_data[shift:] = 0 return augmented_data
2) Time stretches transformation.
💡 It stretches times series by a fixed rate. performed by librosa function.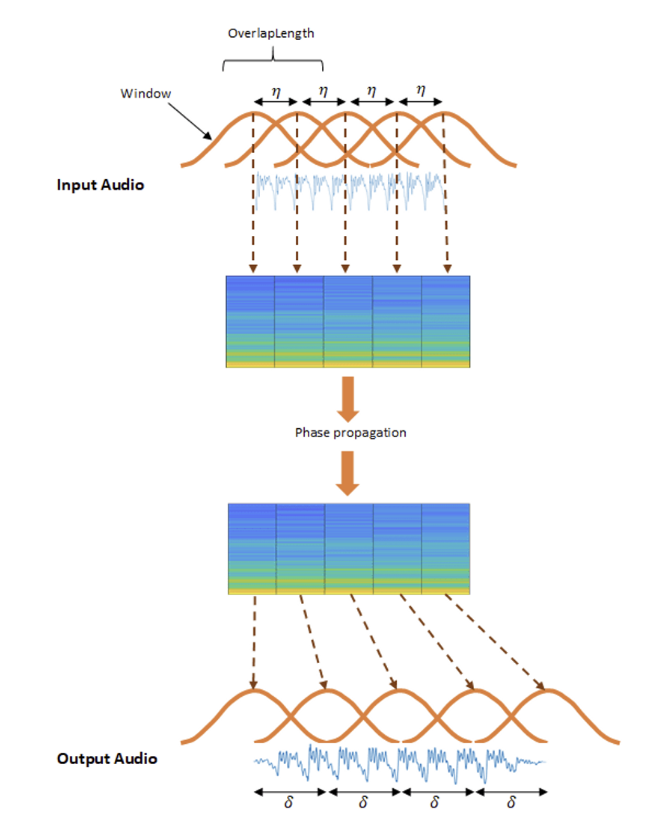
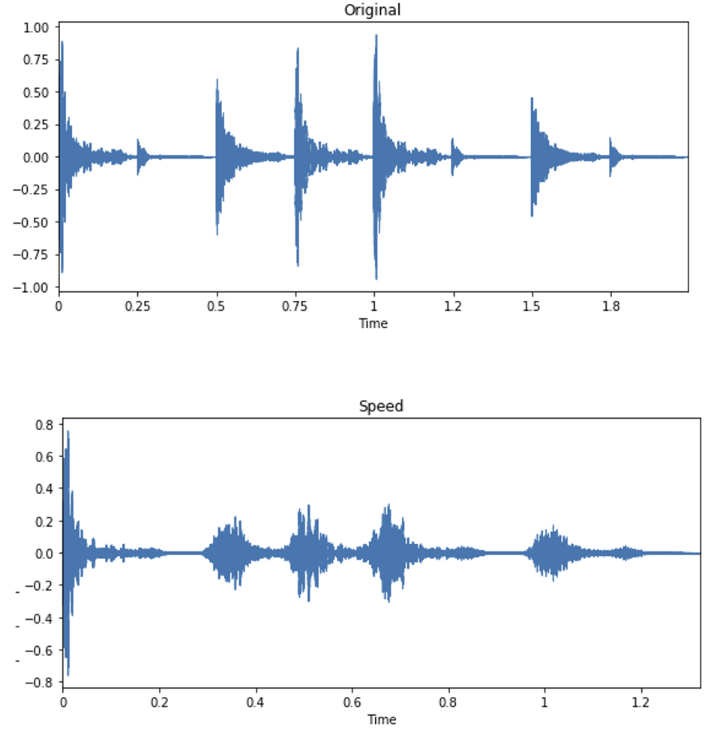
-
Slow time stretches (STS)
- slow down by the factor of (0.7)
-
Fast time stretches (FTS)
- fast by the value of (1.20)
-
code
import librosa def manipulate(data, speed_factor): return librosa.effects.time_stretch(data, speed_factor)
3) Trim silence.
💡 This technique helps to trail or trim the silence part of the audio signals.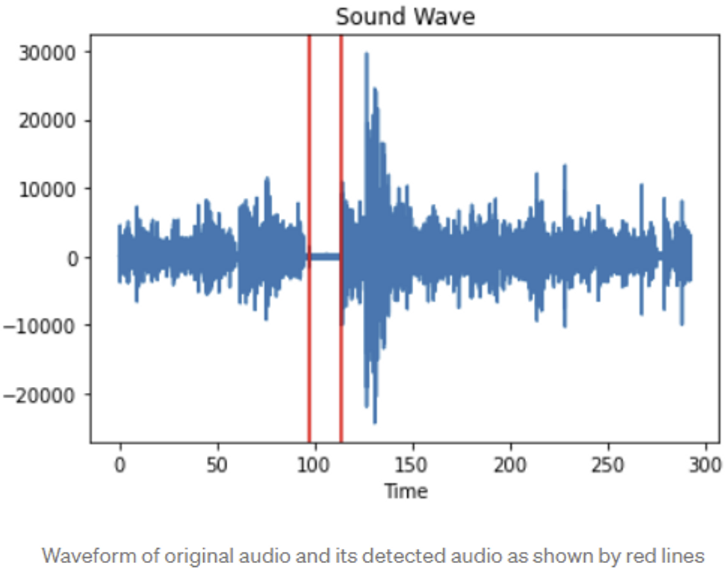

- Trim silence (TS)
- trail or trim the silence signal
- code
from scipy.io.wavfile import read, writedef remove_silence(file,sil,keep_sil,out_path): ''' This function removes silence from the audio. Input: file = Input audio file path sil = List of silence time slots that needs to be removed keep_sil = Time to keep as allowed silence after removing silence out_path = Output path of audio file returns: Non - silent patches and save the new audio in out path ''' rate,aud=read(path) a=float(keep_sil)/2 sil_updated=[(i[0]+a,i[1]-a) for i in sil] # convert the silence patch to non-sil patches non_sil=[] tmp=0 ed=len(aud)/rate for i in range(len(sil_updated)): non_sil.append((tmp,sil_updated[i][0])) tmp=sil_updated[i][1] if sil_updated[-1][1]+a/2<ed: non_sil.append((sil_updated[-1][1],ed)) if non_sil[0][0]==non_sil[0][1]: del non_sil[0] # cut the audio print('slicing starte') ans=[] ad=list(aud) for i in tqdm.tqdm(non_sil): ans=ans+ad[int(i[0]*rate):int(i[1]*rate)] #nm=path.split('/')[-1] write(out_path,rate,np.array(ans)) return non_sil
Results
< CNN >
Result 1) 7계층 제안 CNN 아키텍처에 대한 학습 정확도 대 검증 정확도 결과
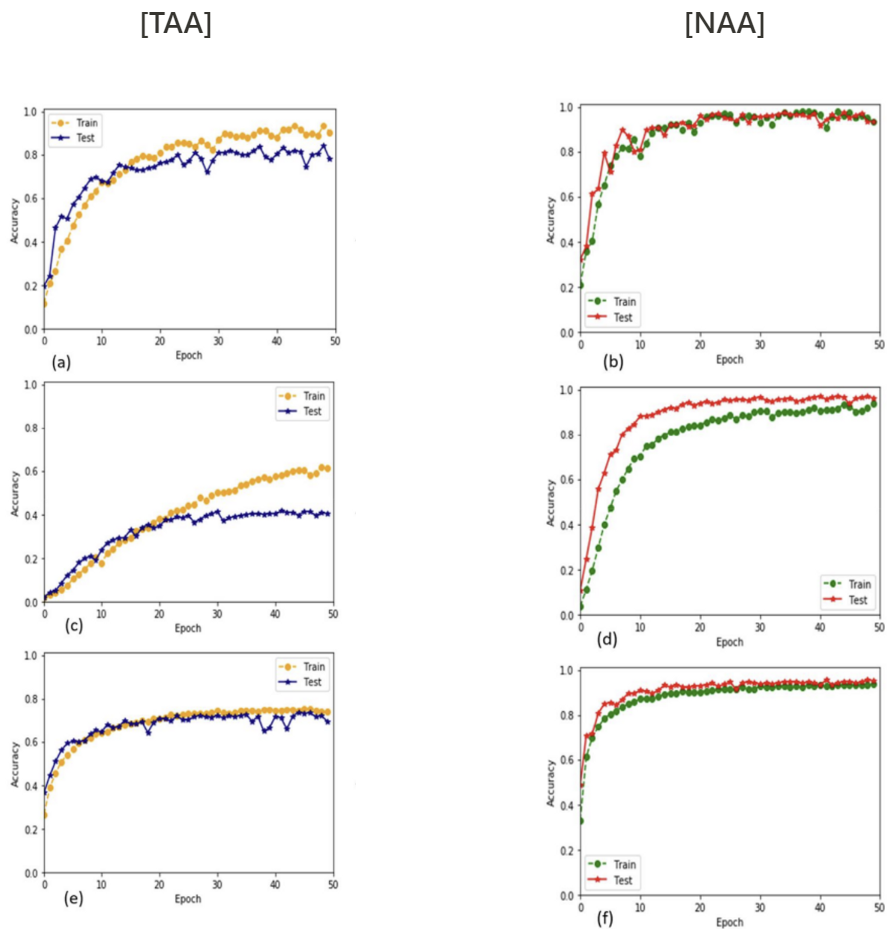
- Data set.
- (a), (b) : ESC-10
- (c), (d) : ESC-50
- (e), (f) : Us8k
Result 2) 9계층 제안 CNN 아키텍처에 대한 학습 정확도 대 검증 정확도 결과
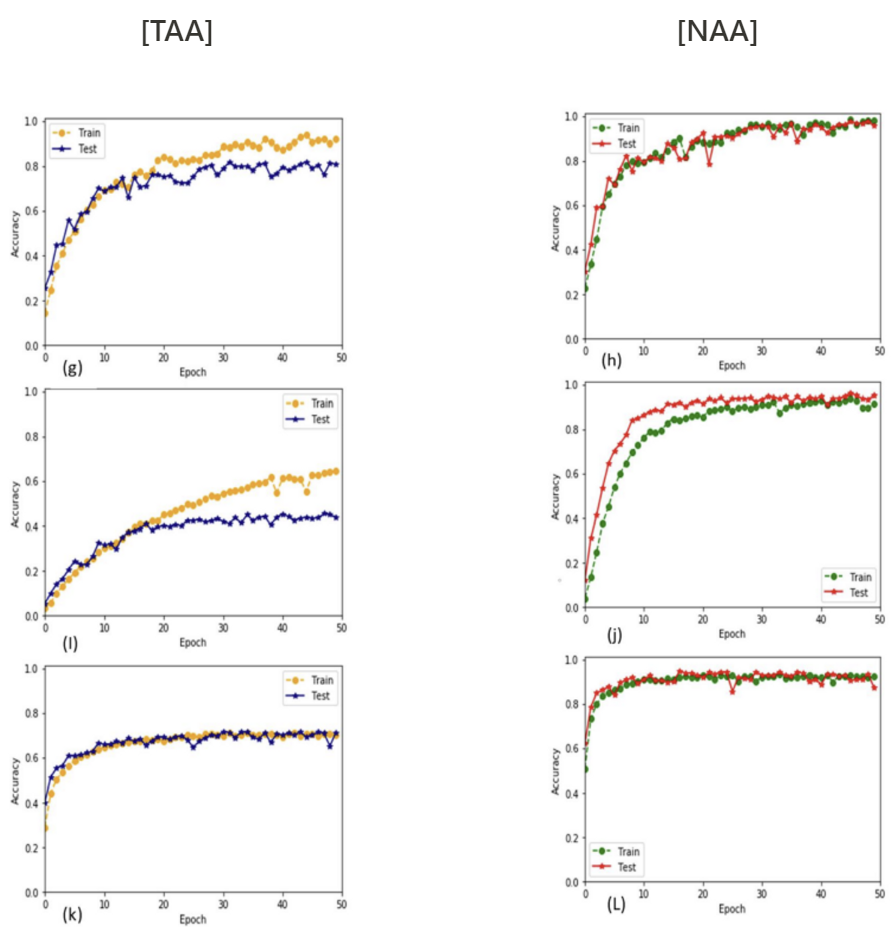
- Data set.
- (g),(h) : ESC-10 관련
- (I),(j) : ESC-50
- (k),(l) : Us8k
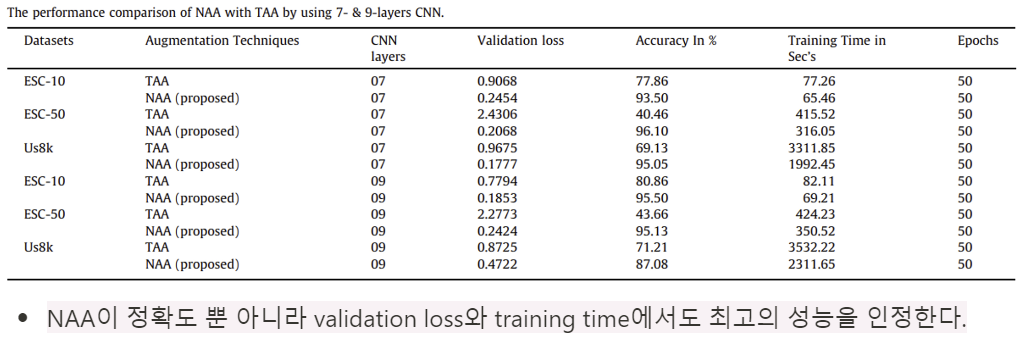
[The performance comparison of NAA with TAA by using 7- & 9-layers CNN]
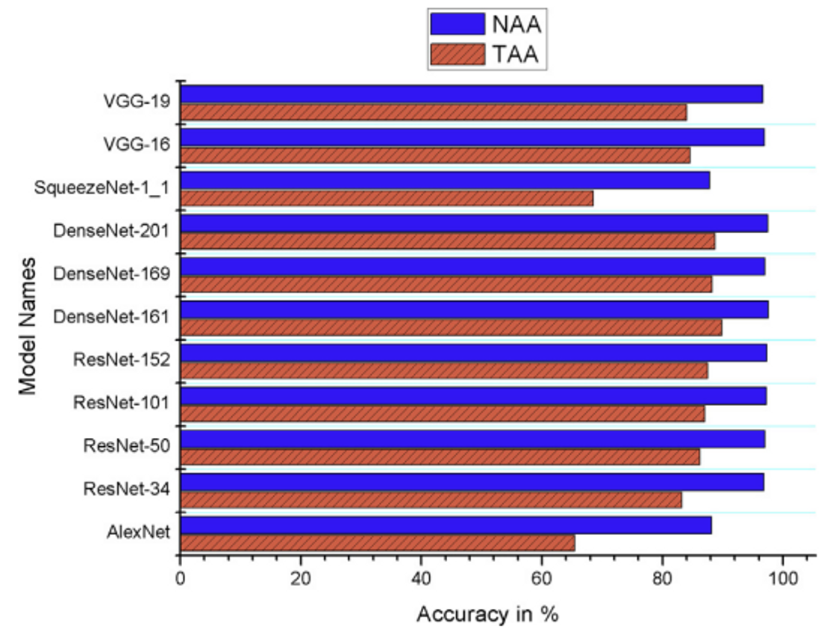
< Transfer learning models >
[Comparison of the accuracies of Transfer learning models]
- ESC-50 data set에서 이전에 발표된 모든 방법 중 97.57%로 최고의 정확도를 보여주었다.
- (나머지 data도 동일하게 정확도가 훨씬 높다.)
[The performance comparison of NAA with TAA by using Transfer learning models for the ESC-50 dataset.]
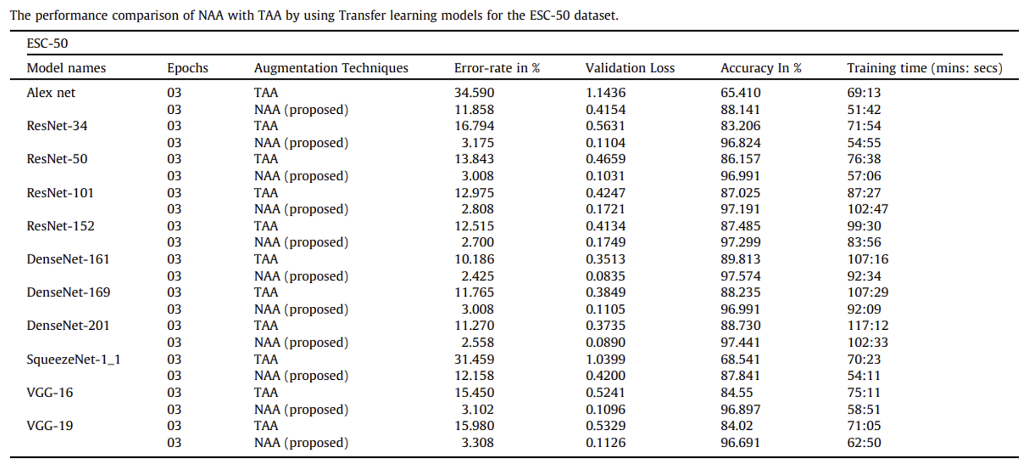
- The distinct pre-trained weights : (ResNet, DenseNet, AlexNet, SqueezeNet, VGG)
- DenseNet-161 model의 NAA는 가장 lowest loss value (0.0835)를 달성하였다. → 이 또한 ESC-5 data의 모든 방법론 중 가장 높은 정확도를 달성
[기존 연구와 NAA 비교]
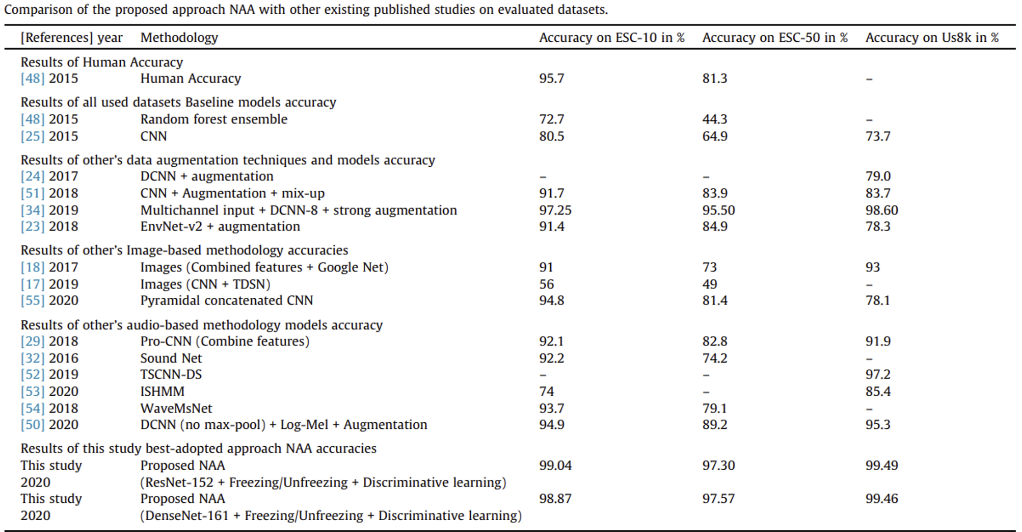
- NAA가 압도적으로 높은 정확도를 보이고 있다.
- augmentation techniques를 사용한 다양한 예측 알고리즘, CNN, transfer learning models들은 overfitting 문제를 극복하지 못하고 광범위한 불균형을 초래한다.
- 이 문제를 해결할 수 있는 방법 중 하나는 정규화와 의미 있는 augmentation이다.
Refernce
Spectral images based environmental sound classification using CNN.pdf
Posters
data augmentation
https://kr.mathworks.com/help/audio/ref/stretchaudio.html
http://kth.diva-portal.org/smash/get/diva2:1381398/FULLTEXT01.pdf
https://medium.com/@makcedward/data-augmentation-for-audio-76912b01fdf6
https://onkar-patil.medium.com/how-to-remove-silence-from-an-audio-using-python-50fd2c00557d
kaggle : https://www.kaggle.com/code/CVxTz/audio-data-augmentation/notebook
spectrogram
https://towardsdatascience.com/data-augmentation-for-speech-recognition-e7c607482e78
