
📊 실습: AWS RedShift는 Cluster를 구글 Colab에서 접근해 데이터를 조회해 보자
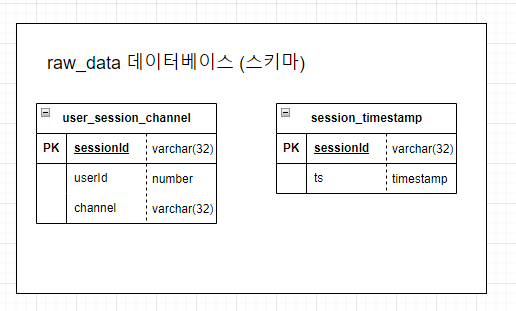
- 실습에서 사용하게 될
RedShift의 스키마이다. user_session_channel이라는 사용자의 세션 정보를 담고 있는 테이블과session_timestamp라는 각 세션의 시간을 담고 있는 테이블로 이루어져 있다.SQL문을 통해 이 테이블에 저장되어 있는 데이터들을 다양한 조건으로 조회해 보자.
1. 구글 Colab에서 RedShift Cluster 호출
%load_ext sql- 먼저
SQL을 사용하기 위해 다음과 같이SQL을 로드해 준다.
!pip install SQLAlchemy==1.4.47- AWS RedShift 데이터베이스 환경에 접근하기 위해서는
SQLAlchemy를 설치해 주어야 한다. - 이후 데이터베이스 환경에 접근하는 방법은 다양하지만 실습 환경에서는
직접적으로 DB 환경을 입력해 접근해 주기로 하였다. 이 방법은 편리하기는 하나 DB 정보가 외부에 노출되기 때문에 실제 프로젝트에서는 권장하지 않는 방법이다.
%sql postgresql://username:password@hostname/dbname- 다른 DB 환경 접근 방법으로는 별도의 폴더에 별도의 파일로
DB credentials을 관리하고 이를 불러오는 방법과ipython-sql을 이용하는 방법이 있다.
2. 다양한 조건에 따라 SELECT 함수를 이용해 데이터 조회
1) 테이블의 저장된 데이터 파악
- 테이블에 저장된 데이터들이 어떤 형식으로 저장이 되어 있는지 파악하기 위해 10 개 정도의 데이터만
LIMIT을 통해 조회해 본다.
%%sql
SELECT *
FROM raw_data.user_session_channel
LIMIT 10;- 조회 결과
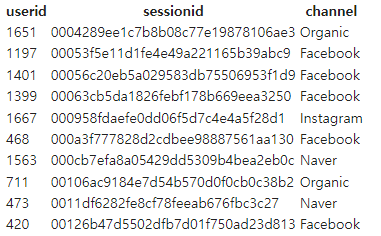
- 이를 통해
user_session_channel의 데이터는 INT 타입의userid, VARCHAR 타입의sessionid, 그리고 이 세션에 유입된 사이트명(Facebook, Instagram, Naver, Organic 등)을 담고 있는 VARCHAR 타입의channel로 이루어져 있음을 알 수 있다. - 같은 방식으로
session_timestamp테이블을 조회해 보자.
%%sql
SELECT *
FROM raw_data.session_timestamp
LIMIT 10;- 조회 결과

user_session_channel와 동일하게sessionid가 있음을 알 수 있고,날짜 시간(%Y-%m-%d %H:%i:%s)형식으로 데이터가 저장되어 있음을 알 수 있다.- 이렇게 데이터를 조회해 보면 어떤 데이터를 조회하고자 할 때 어떤 컬럼을 어떻게 조회해야 하는지를 알 수 있다.
2) 유입된 채널 종류 조회
- 사용자들이 유입된 채널을 파악하기 위해 채널만 조회해 보자.
- 이때 중복된 채널은 조회할 필요 없으므로
DISTINCT함수를 사용하여 중복을 제거한다.
%%sql
SELECT DISTINCT channel
FROM raw_data.user_session_channel;- 조회 결과

- 총 6 개의 사이트에서 사용자들이 유입되었음을 알 수 있다.
3) 채널별로 몇 번이나 유입되었는지 조회
- 사용자들이 많이 유입된 채널을 파악하기 위해 채널별로 몇 번이나 유입되었는지 조회해 보자.
%%sql
SELECT channel
, COUNT(1) cnt -- 채널별 카운트를 하고 싶은 경우. COUNT 함수!!
FROM raw_data.user_session_channel
GROUP BY channel
ORDER BY cnt DESC;- 조회 결과
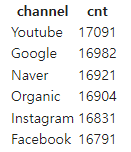
- 사용자가 가장 많이 유입된 채널은 Youtube인 것을 알 수 있다.
4) CASE-WHEN문을 사용해 channel type별 조회
- Facebook과 Instagram이라면 Social-Media, Google, Naver라면 'Search-Engine', 그외의 것이라면 Something-Else로 데이터를 조회하자.
%%sql
SELECT channel
, CASE WHEN channel in ('Facebook', 'Instagram')
THEN 'Social-Media'
WHEN channel in ('Google', 'Naver')
THEN 'Search-Engine'
ELSE 'Something-Else'
END channel_type
FROM raw_data.user_session_channel
LIMIT 100;- 조회 결과

- 이때 제대로 데이터의 채널 타입이 나오는지 확인하였다면 각 채널 타입별 유입 수도 확인해 보자.
%%sql
SELECT CASE WHEN channel in ('Facebook', 'Instagram')
THEN 'Social-Media'
WHEN channel in ('Google', 'Naver')
THEN 'Search-Engine'
ELSE 'Something-Else'
END channel_type
, COUNT(*) channel_type_cnt
FROM raw_data.user_session_channel
GROUP BY channel_type;- 조회 결과
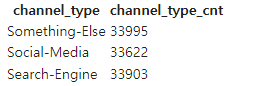
5) Pandas와 연동해 조회
- 먼저 변수에 pandas의 DataFrame으로 보여 줄 결과 값을 넣고 DataFrame으로 적용해 준다.
result = %sql SELECT * FROM raw_data.user_session_channel
df = result.DataFrame()- 제대로 결과 값이 나오는지 확인하기 위해
df.head()코드를 사용해 준다..head()의 경우 default로 상위 다섯 개의 값을 표출해 준다. 반대로.tail()의 경우 하위 다섯 개의 값을 표출해 준다.
df.head()- 조회 결과

- pandas를 사용할 경우 다음과 같이 목록 형식으로 보기 좋게 조회되는 것을 알 수 있다.
- pandas로도 각 채널별 유입 수를 알 수 있는데 다음과 같이 groupby 후 count() 함수를 써 주면 된다.
df.groupby(["channel"])["sessionid"].count()- 조회 결과


송의 개발 LOG