
pandas :: series
pandas의 구성
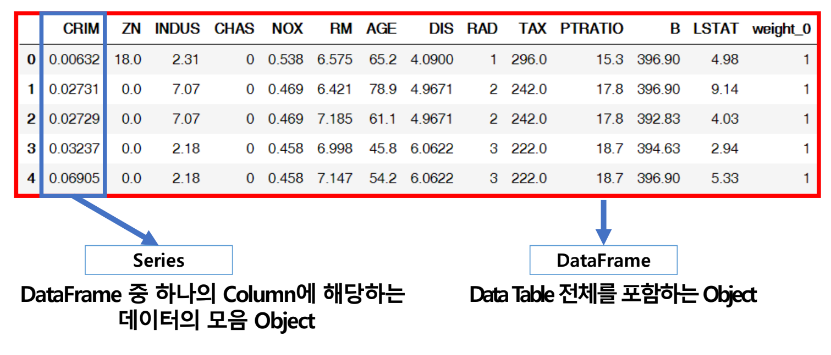
Series
- Column Vector를 표현하는 object
from pandas import Series, DataFrame
import pandas as pd
import numpy as nplist_data = [1,2,3,4,5]
example_obj = Series(data = list_data)
example_obj 0 1
1 2
2 3
3 4
4 5
dtype: int64
list_data = [1,2,3,4,5]
list_name = ["a","b","c","d","e"]
# index 이름을 지정
example_obj = Series(data = list_data, index=list_name)
example_obj a 1
b 2
c 3
d 4
e 5
dtype: int64
example_obj.index # index 리스트만Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
example_obj.values # 값 리스트만array([1, 2, 3, 4, 5], dtype=int64)
type(example_obj.values)numpy.ndarray
dict_data = {"a":1, "b":2, "c":3, "d":4, "e":5}
# data type, series 이름 설정
example_obj = Series(dict_data, dtype=np.float32, name="example_data")
example_obj a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
Name: example_data, dtype: float32
# data index에 접근하기
example_obj["a"]1.0
# data index에 값 할당하기
example_obj["a"] = 3.2
example_obj a 3.2
b 2.0
c 3.0
d 4.0
e 5.0
Name: example_data, dtype: float32
example_obj[example_obj > 2] a 3.2
c 3.0
d 4.0
e 5.0
Name: example_data, dtype: float32
example_obj * 2 a 6.4
b 4.0
c 6.0
d 8.0
e 10.0
Name: example_data, dtype: float32
np.exp(example_obj) a 24.532532
b 7.389056
c 20.085537
d 54.598148
e 148.413162
Name: example_data, dtype: float32
np.abs(example_obj) a 3.2
b 2.0
c 3.0
d 4.0
e 5.0
Name: example_data, dtype: float32
np.log(example_obj) a 1.163151
b 0.693147
c 1.098612
d 1.386294
e 1.609438
Name: example_data, dtype: float32
"b" in example_objTrue
example_obj.to_dict(){'a': 3.200000047683716, 'b': 2.0, 'c': 3.0, 'd': 4.0, 'e': 5.0}
example_obj.valuesarray([3.2, 2. , 3. , 4. , 5. ], dtype=float32)
example_obj.indexIndex(['a', 'b', 'c', 'd', 'e'], dtype='object')
example_obj.name = "number"
example_obj.index.name = "alphabet"
example_obj alphabet
a 3.2
b 2.0
c 3.0
d 4.0
e 5.0
Name: number, dtype: float32
dict_data_1 = {"a":1, "b":2, "c":3, "d":4, "e":5}
indexes = ["a","b","c","d","e","f","g","h"]
series_obj_1 = Series(dict_data_1, index=indexes)
series_obj_1 a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
f NaN
g NaN
h NaN
dtype: float64
