
pandas :: dataframe

https://www.slideshare.net/wesm/pandas-powerful-data-analysis-tools-for-python
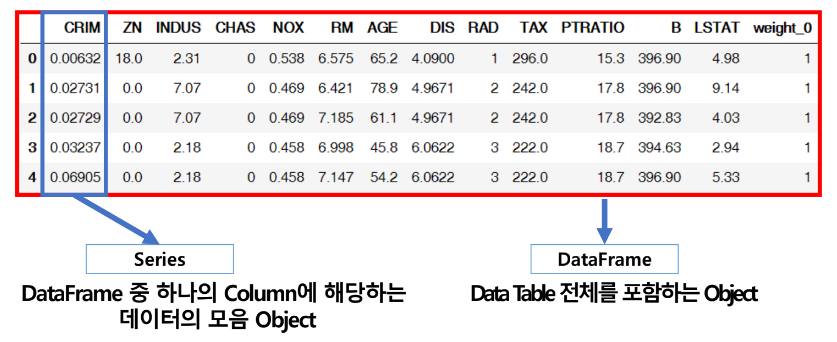
DataFrame
- Series를 모아서 만든 Data Table = 기본 2차원
from pandas import Series, DataFrame
import pandas as pd
import numpy as np# Example from - https://chrisalbon.com/python/pandas_map_values_to_values.html
raw_data = {'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'],
'age': [42, 52, 36, 24, 73],
'city': ['San Francisco', 'Baltimore', 'Miami', 'Douglas', 'Boston']}
df = pd.DataFrame(raw_data, columns = ['first_name', 'last_name', 'age', 'city'])
df| first_name | last_name | age | city | |
|---|---|---|---|---|
| 0 | Jason | Miller | 42 | San Francisco |
| 1 | Molly | Jacobson | 52 | Baltimore |
| 2 | Tina | Ali | 36 | Miami |
| 3 | Jake | Milner | 24 | Douglas |
| 4 | Amy | Cooze | 73 | Boston |
# column 선택
DataFrame(raw_data, columns = ["age", "city"])| age | city | |
|---|---|---|
| 0 | 42 | San Francisco |
| 1 | 52 | Baltimore |
| 2 | 36 | Miami |
| 3 | 24 | Douglas |
| 4 | 73 | Boston |
# 새로운 column (debt) 추가
DataFrame(raw_data,
columns = ["first_name","last_name","age", "city", "debt"]
)| first_name | last_name | age | city | debt | |
|---|---|---|---|---|---|
| 0 | Jason | Miller | 42 | San Francisco | NaN |
| 1 | Molly | Jacobson | 52 | Baltimore | NaN |
| 2 | Tina | Ali | 36 | Miami | NaN |
| 3 | Jake | Milner | 24 | Douglas | NaN |
| 4 | Amy | Cooze | 73 | Boston | NaN |
# column 선택 - series 추출 : 방법 1
df = DataFrame(raw_data, columns = ["first_name","last_name","age", "city", "debt"])
df.first_name 0 Jason
1 Molly
2 Tina
3 Jake
4 Amy
Name: first_name, dtype: object
# column 선택 - series 추출 : 방법 2
df["first_name"] 0 Jason
1 Molly
2 Tina
3 Jake
4 Amy
Name: first_name, dtype: object
df| first_name | last_name | age | city | debt | |
|---|---|---|---|---|---|
| 0 | Jason | Miller | 42 | San Francisco | NaN |
| 1 | Molly | Jacobson | 52 | Baltimore | NaN |
| 2 | Tina | Ali | 36 | Miami | NaN |
| 3 | Jake | Milner | 24 | Douglas | NaN |
| 4 | Amy | Cooze | 73 | Boston | NaN |
# loc : index location
df.loc[1] first_name Molly
last_name Jacobson
age 52
city Baltimore
debt NaN
Name: 1, dtype: object
# iloc : index position
df["age"].iloc[1:] 1 52
2 36
3 24
4 73
Name: age, dtype: int64
# loc은 index 이름, iloc은 index number# Example from - https://stackoverflow.com/questions/31593201/pandas-iloc-vs-ix-vs-loc-explanation
s = pd.Series(np.nan, index=[49,48,47,46,45, 1, 2, 3, 4, 5])
s.loc[:3] # 3이라는 index까지 49 NaN
48 NaN
47 NaN
46 NaN
45 NaN
1 NaN
2 NaN
3 NaN
dtype: float64
s.iloc[:3] # 처음부터 3개 49 NaN
48 NaN
47 NaN
dtype: float64
df.age > 40 0 True
1 True
2 False
3 False
4 True
Name: age, dtype: bool
# column에 새로운 데이터 할당
df.debt = df.age > 40
df| first_name | last_name | age | city | debt | |
|---|---|---|---|---|---|
| 0 | Jason | Miller | 42 | San Francisco | True |
| 1 | Molly | Jacobson | 52 | Baltimore | True |
| 2 | Tina | Ali | 36 | Miami | False |
| 3 | Jake | Milner | 24 | Douglas | False |
| 4 | Amy | Cooze | 73 | Boston | True |
# transpose
df.T| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| first_name | Jason | Molly | Tina | Jake | Amy |
| last_name | Miller | Jacobson | Ali | Milner | Cooze |
| age | 42 | 52 | 36 | 24 | 73 |
| city | San Francisco | Baltimore | Miami | Douglas | Boston |
| debt | True | True | False | False | True |
# 값 출력
df.values array([['Jason', 'Miller', 42, 'San Francisco', True],
['Molly', 'Jacobson', 52, 'Baltimore', True],
['Tina', 'Ali', 36, 'Miami', False],
['Jake', 'Milner', 24, 'Douglas', False],
['Amy', 'Cooze', 73, 'Boston', True]], dtype=object)
# csv 변환
df.to_csv()',first_name,last_name,age,city,debt\r\n0,Jason,Miller,42,San Francisco,True\r\n1,Molly,Jacobson,52,Baltimore,True\r\n2,Tina,Ali,36,Miami,False\r\n3,Jake,Milner,24,Douglas,False\r\n4,Amy,Cooze,73,Boston,True\r\n'
# column을 삭제함
del df["debt"]df| first_name | last_name | age | city | |
|---|---|---|---|---|
| 0 | Jason | Miller | 42 | San Francisco |
| 1 | Molly | Jacobson | 52 | Baltimore |
| 2 | Tina | Ali | 36 | Miami |
| 3 | Jake | Milner | 24 | Douglas |
| 4 | Amy | Cooze | 73 | Boston |
# column 추가
values = Series(data=["M","F","F"],index=[0,1,3])
values 0 M
1 F
3 F
dtype: object
df["sex"] = values
df| first_name | last_name | age | city | sex | |
|---|---|---|---|---|---|
| 0 | Jason | Miller | 42 | San Francisco | M |
| 1 | Molly | Jacobson | 52 | Baltimore | F |
| 2 | Tina | Ali | 36 | Miami | NaN |
| 3 | Jake | Milner | 24 | Douglas | F |
| 4 | Amy | Cooze | 73 | Boston | NaN |
# Example from Python for data analyis
pop = {'Nevada': {2001: 2.4, 2002: 2.9},
'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
DataFrame(pop)| Nevada | Ohio | |
|---|---|---|
| 2001 | 2.4 | 1.7 |
| 2002 | 2.9 | 3.6 |
| 2000 | NaN | 1.5 |
