
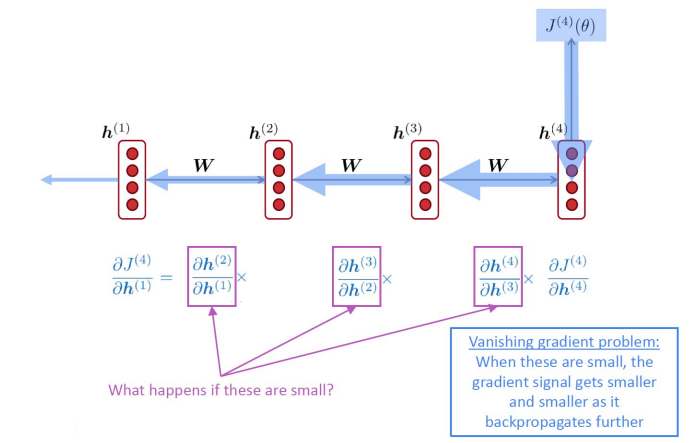
Vanilla RNN의 한계
- 바닐라 RNN은 출력 결과가 이전의 계산 결과에 의존
- 짧은 sequence에서만 효과가 있다는 단점
- 앞의 정보가 뒤로 충분히 전달되지 못할 수 있음
- Vanishing gradient problem
- The problem of Long-Term Dependencies
LSTM
Compared to Vanilla RNNs
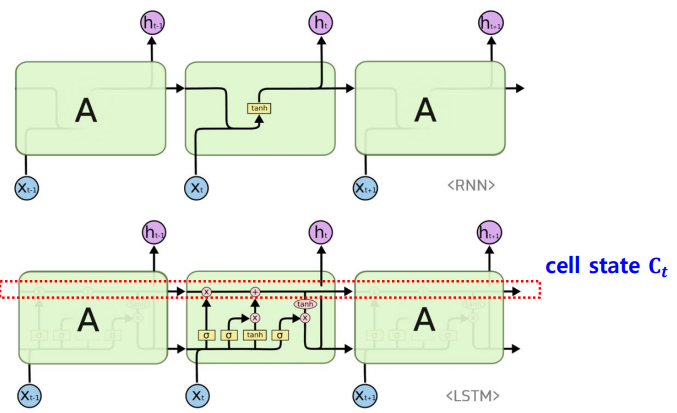
- 기존에는 short term memory 패쓰 -> hidden state
- 이제는 long term memory 패쓰 -> cell state
- Long-short term memory
- Separate memory into several types.
- The cell stores long-term information
- The LSTM can erase, write and read information from the cell.
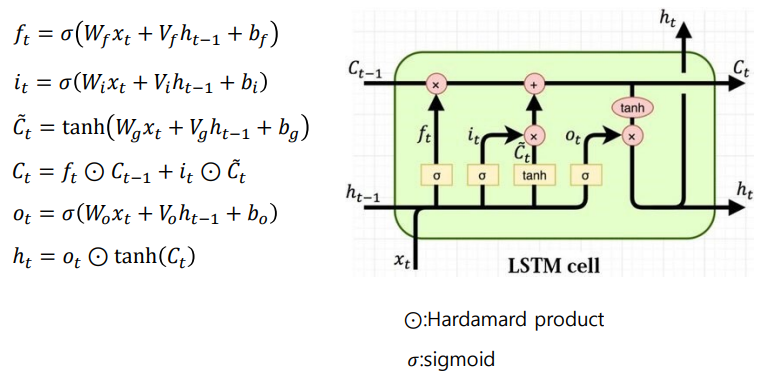
- Hidden state의 memory cell에 입력 게이트, 삭제 게이트, 출력 게이트를 추가하여 불필요한 기억을 지우고, 기억해야할 것들을 정한다.
- 즉, LSTM은 hidden state를 계산하는 식이 RNN보다 조금 복잡해졌으며
cell state라는 값을 추가함 - Cell state 또한 t-1시점의 cell state가 t시점의 cell state를 구하기 위한 입력으로 사용됨
- Hidden state와 cell state의 값을 구하기 위해서는 새로 추가된 3개의 게이트를 사용함. forget / input / update
Forget gate
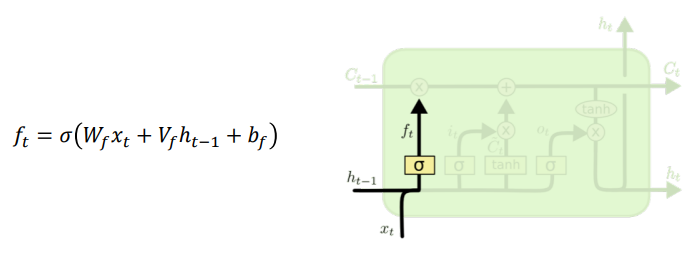
- Cell state로부터 정보를 버릴지 결정
Input: t시점 x값, t-1시점 hidden tate- Sigmoid 지나면 0~1 사이의 값
- 0에 가까울수록 정보가 많이 삭제, 1에 가까울수록 온전히 기억
Input gate
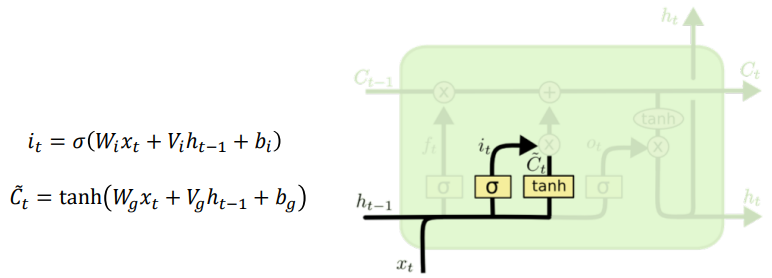
- Cell state로부터 정보를 저장할지 결정
- Tanh 지나면 -1~1 사이의 값
Update cell
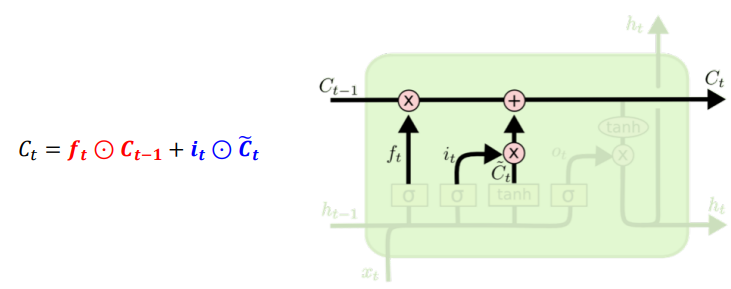
- Update, scaled by how much we decide to update.
- forget gate와 input gate를 통해.
forget gate에서 일부 기억을 잃은 상태input gate에서 선택된 기억 +forget gate의 결과값
-> 이 값을 t 시점의cell state라고 하며, 이 값은 t+1 시점의 LSTM 셀로 넘겨짐forget gate: 이전 시점의 입력을 얼마나 반영할지 의미input gate: 현재 시점의 입력을 얼마나 반영할지 결정
Output gate
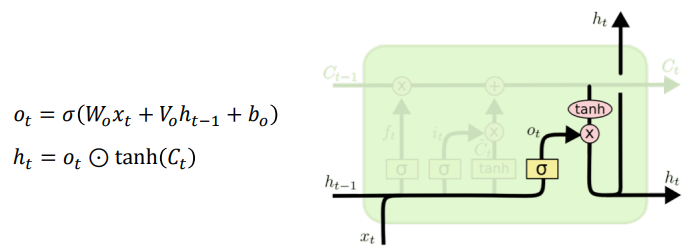
- The output will be based on our
cell state, but will be a filltered version.
정리
- LSTM은 gate를 통해 vanishing grate 문제를 개선. 그러나 완벽히 해결한 것은 아님
- Long term을 잘 학습
- Resnet처럼 정보를 잃어버리지 않게 전달
cell state는 addition and multiplication 연산으로만 이루어져 있음
-> vanishing gradient is small.
GRU

- Gated Recurrent Unit
- Simplified version of LSTM cell
- Using hidden state only
- 두 가지 게이트 -
update&reset forget gate와input gate가update gate로 대체됨reset gate는 이전 정보를 부분적으로 reset 할지 결정한다.

Übermensch