
Problems with RNNs
RNN은 input data를 순차적으로 넣어줘야 함. 한 단어씩.
- Slow to train
- Cannot use GPUs parallelly
- Long sequences lead to vanishing/expolding gradients
Transformer는 문장의 단어들을 동시에 넣어준다.
- Faster to train
- Parallelizable for sequential data
Sequence-to-Sequence Models
Encoder-Decoder Architecture
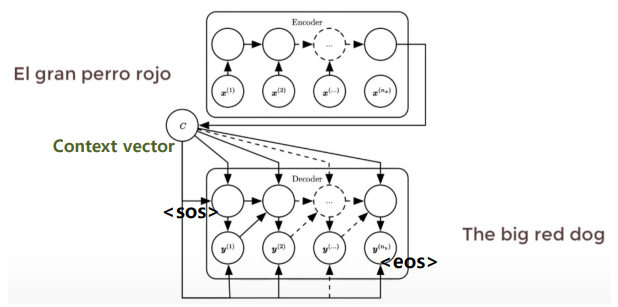
- 문장 전체를 Encoder에 입력
- 시작 토큰
sos를 입력으로 받아the출력 the는 다시 입력으로- 이 과정을 반복하여 마지막
dog가 출력되면, - 종료 토큰
eos를 출력하여 멈춘다. - RNN을 사용하지 않지만 여전히 encoder-decoder 구조를 유지
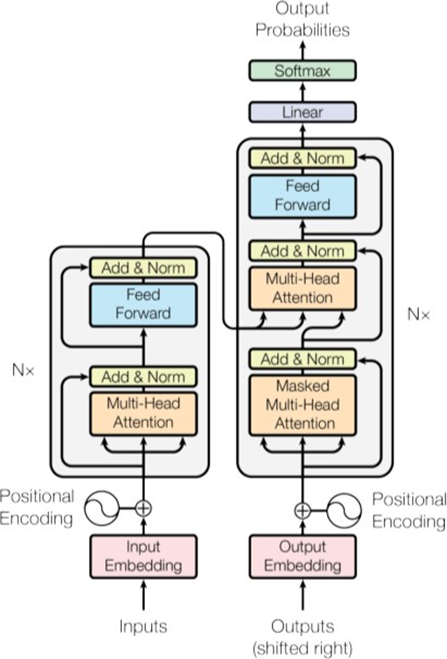
Transformer Architecture
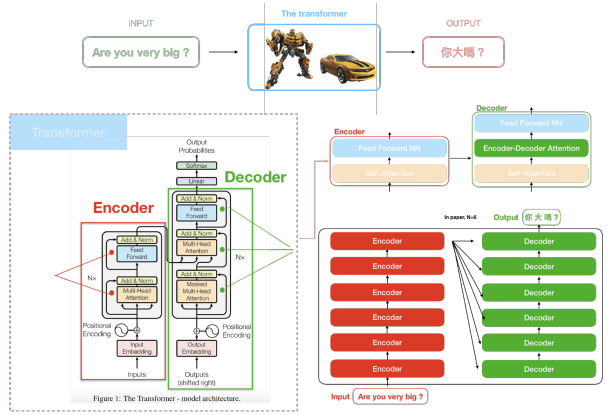
Nx: 인코더, 디코더 box 각각 N번 반복된다.
Input Embedding
- 비슷한 단어들은 가까이 위치하도록 pre-train
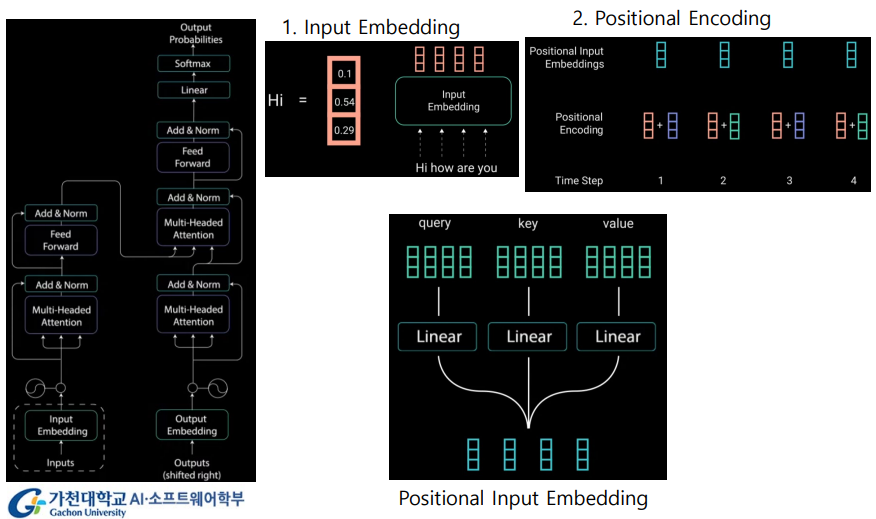
Positional Encoding
RNN은 각 단어의 위치 정보를 가지고 있으나Transformer는 순차적으로 입력 받는 방식이 아니기에- 단어의 위치 정보를 얻기 위해서 각 단어의 embedding vector에 위치 정보를 더하여 모델의 입력으로 사용한다 ->
positional encoding
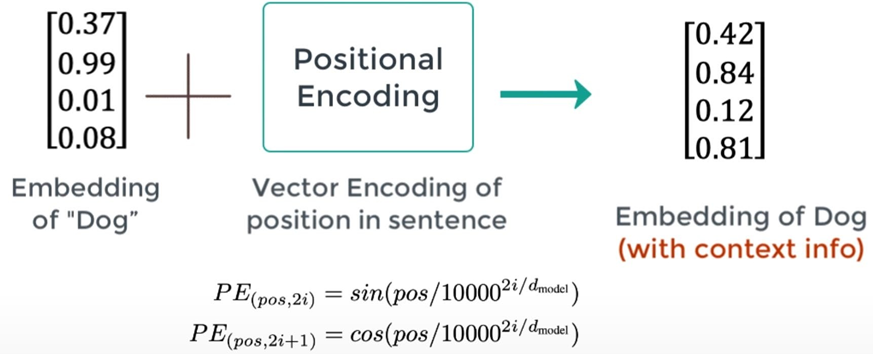
- Input으로 단어만 들어가는 게 아니라, 단어의 position도 함께.
Word+Position=Embedding
Attention Mechanism
Attention: input이 주어졌을 때, 어떤 부분이 중요한지- 한 문장 내 각 단어에 대해 다른 단어들과 얼마나 관련이 있는지
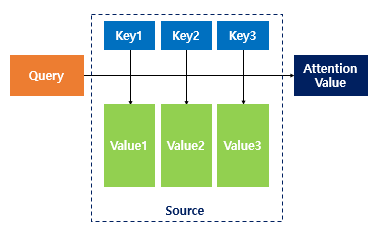
- Attention 함수는 주어진
Query에 대해서 모든Key와의 유사도를 각각 구한다. - 그리고 이 유사도를 가중치로 하여 key와 맵핑되어 있는 각각의
Value에 반영한다. - 유사도가 반영된
Value를 모두 가중합하여 리턴한다.
Encoder Block
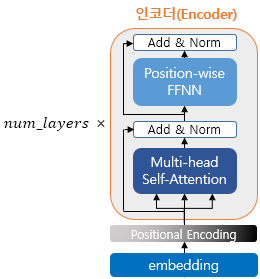
- num_layers 만큼 인코더 층을 쌓는다.
Feed Forward Network: Multi-layered Perceptron (FC)- Residual connection, Layer normalization (Layer 방향으로 normalization 한다)
Output: Context vector
Decoder Block
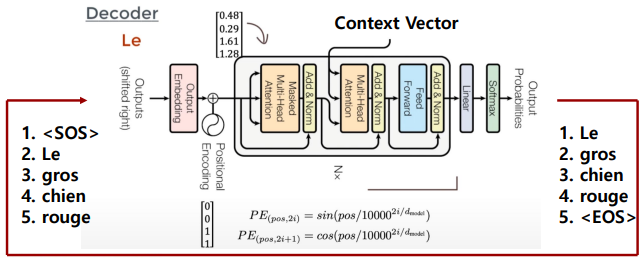
Output: 확률이 가장 높은 wordEOS가 나올 때까지 수행
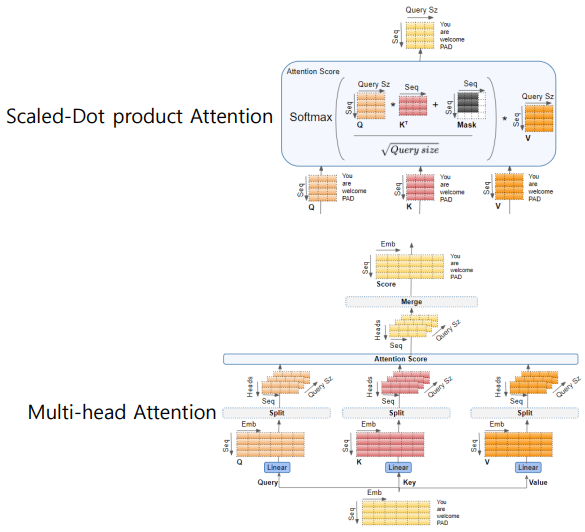
Self-Attention in Transformer
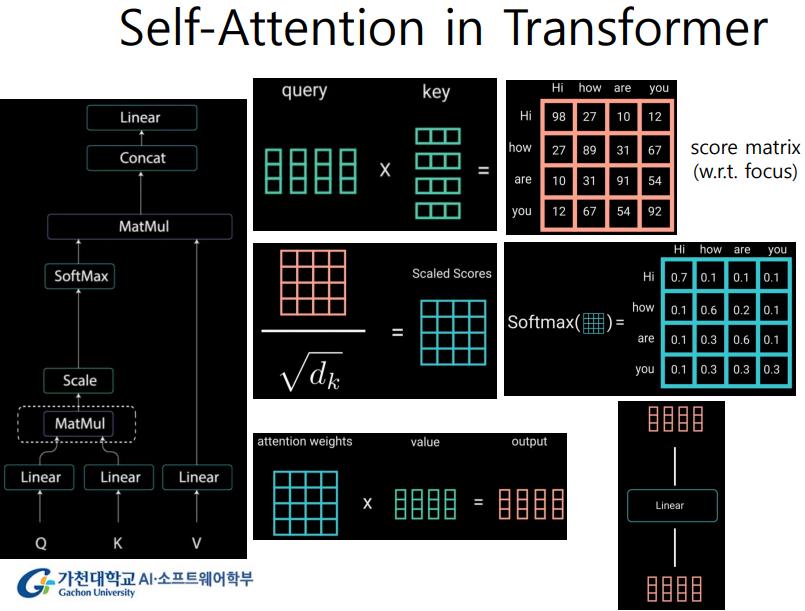
1. MatMul
- Query와 Key를 matmul 연산하여
score matrix생성 - 단어 사이의 focus. 얼마나 연관이 있는지 숫자로 표현
2. Scale
- 큰 숫자 방지. Scaling
3. Softmax
- Softmax 통과하면 확률 값으로 변환
-> 결과적으로 attention weight을 스스로 구함. Self attention.
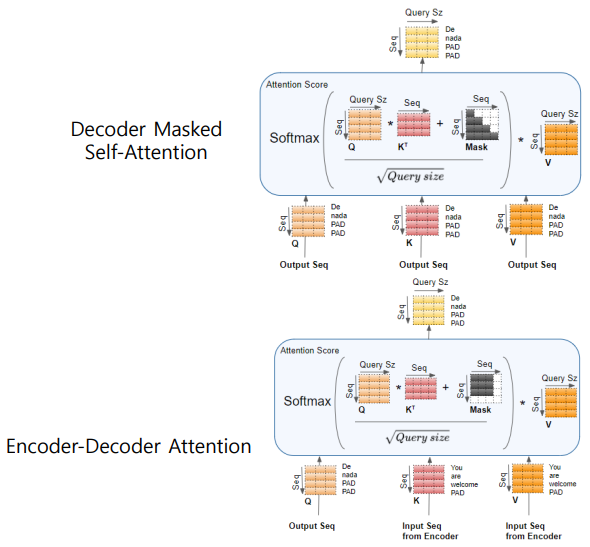
Decoder Masked Self-Attention
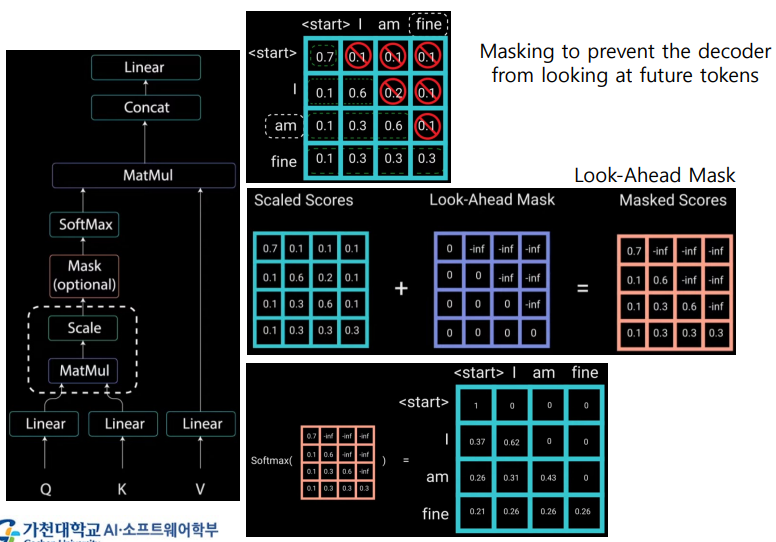
Masking: 현재 word에서 이전 words만 참조하도록, 나머지는 0으로 만든다.- Masking to prevent the decoder from looking at future tokens.
- 대각선의 윗부분은 -inf로 해서 더하고, softmax를 통과시키면 0이 된다.
Multi-headed Attention
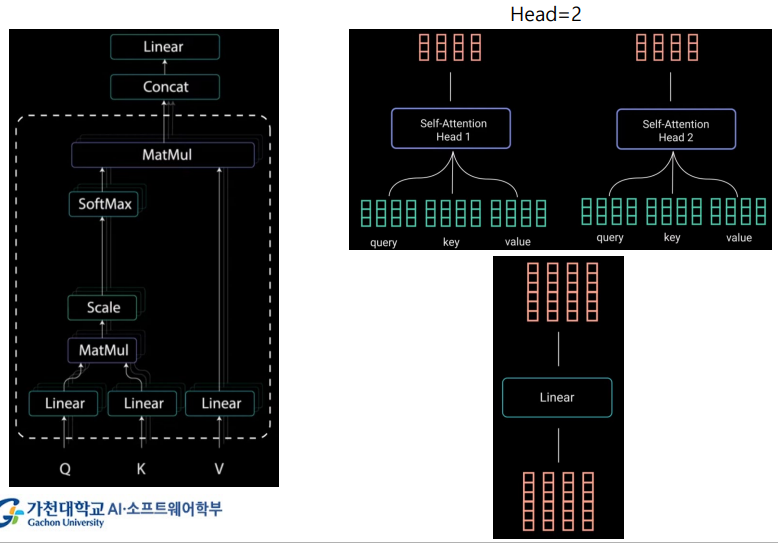
- Q, K, V 여러 개를 동작시킨다.
- 각 통과한 output을 head 1, head 2, ... 이런 식으로
- 사용된 head는 여러 개. 그 결과를 붙인다.
- 그리고 linear를 통과시킴
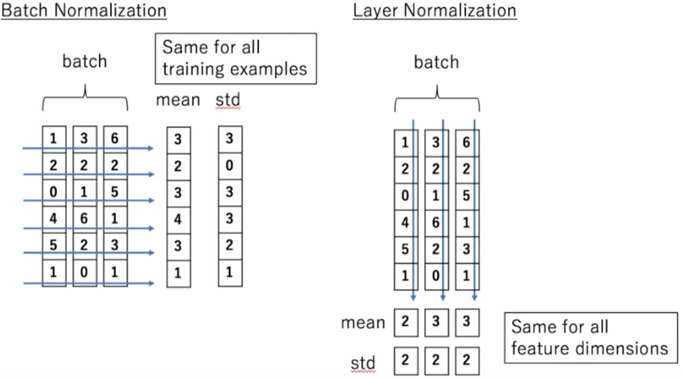
Residual Connection & Layer Normalization
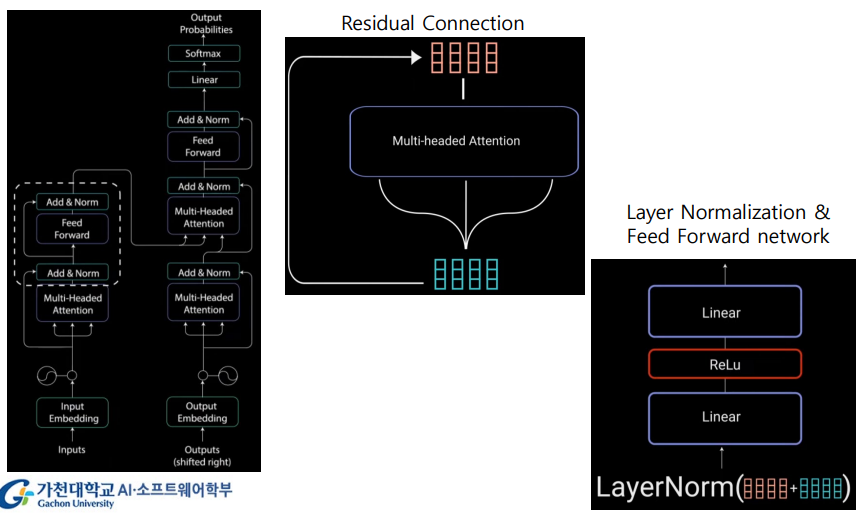
Summary of Attentions in Transformer
Language Model
- 다음 word or character를 추정하는 모델
- Provides context to distinguish between words and phrases that osund similar.
- context를 기반으로 의미상 비슷하거나 소리가 비슷한 단어도 잘 구분
- GRT, BERT

Übermensch