Pandas 라이브러리의 pivot 메소드는 데이터를 재구조화하는 데 사용된다.
특히 데이터를 요약하거나 특정 형태의 분석이나 시각화를 위해 데이터를 새로운 형태로 변형할 때 아주 유용하다. pivot은 데이터프레임 내에서 특정 열을 새로운 행 인덱스, 열 인덱스, 데이터 값으로 재배치하는 방법을 제공한다.
Pivot Table
- 데이터 프레임에서 원하는 행과 열의 인덱스를 선택하여 데이터를 재구조화할 수 있다.
- 원본 데이터프레임에서 분석용 데이터프레임을 뽑아낼 때 주로 사용
- 데이터를 요약하는데 있어서 여러 집계 함수(sum, mean, count 등)를 적용할 수 있다
- Multi index를 생성할 수 있다.
사용 방법:
- index는 pivot table의
행으로 설정될 열을 지정한다. - columns는 pivot table의
열로 설정될 열을 지정한다. - values는 pivot table에서
데이터로 사용될 열을 지정한다. - aggfunc은 데이터를 어떻게 집계할지 결정하는 함수를 지정합한다. (예: sum, mean, count 등).
예시
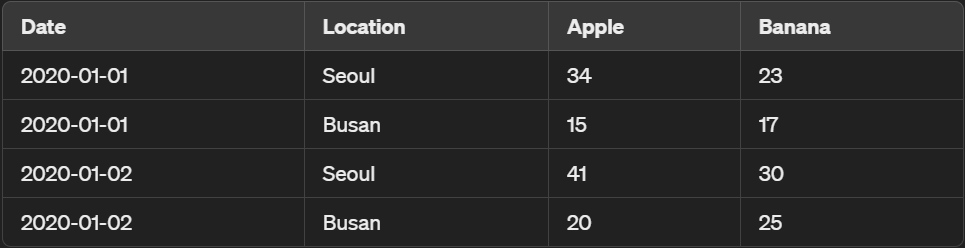
아래 여러 지점에서 여러 제품의 판매량을 기록한 데이터가 있다. (원본 데이터)
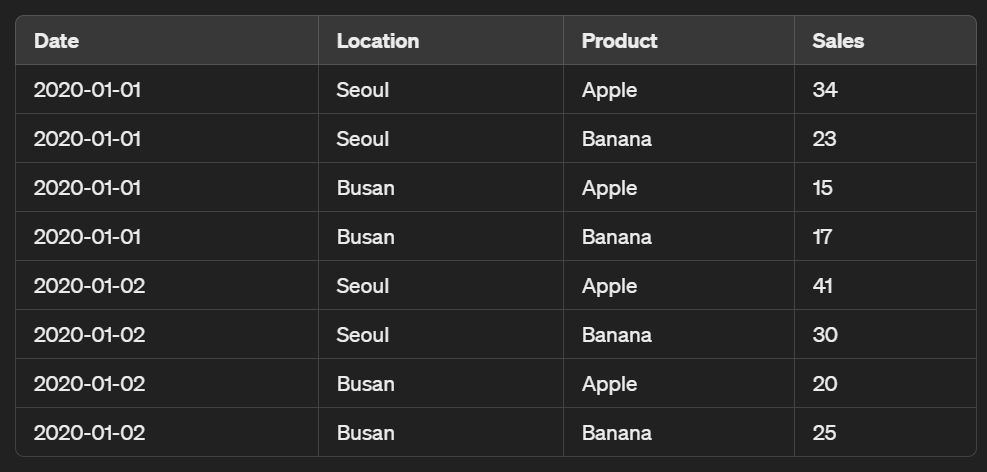
# 생성 코드
import pandas as pd
data = {
'Date': ['2020-01-01', '2020-01-01', '2020-01-01', '2020-01-01', '2020-01-02', '2020-01-02', '2020-01-02', '2020-01-02'],
'Location': ['Seoul', 'Seoul', 'Busan', 'Busan', 'Seoul', 'Seoul', 'Busan', 'Busan'],
'Product': ['Apple', 'Banana', 'Apple', 'Banana', 'Apple', 'Banana', 'Apple', 'Banana'],
'Sales': [34, 23, 15, 17, 41, 30, 20, 25]
}
df = pd.DataFrame(data)
이 원본 데이터프레임에서 pivot으로 각 지점에서의 일별 제품판매량을 확인하기 위한 분석용 테이블을 뽑아내보자.
→→→→→
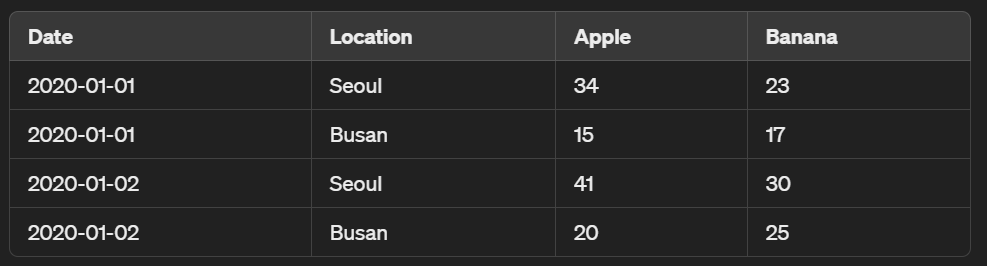
# Pivot Table 변환 코드
pivot_table = df.pivot_table(index=['Date', 'Location'], columns='Product', values='Sales', aggfunc='sum')
print(pivot_table)이렇게 pivot 테이블은 index로 지정한 열의 항목들을 레코드로 ⏬
columns로 지정한 열의 항목들 중 중복을 제거하고난 항목들을 새로운 컬럼으로 하여 ⏩
values로 지정한 열의 값 중 이들과 동시에 관계가 있는 값을 새로운 값으로 지정하는 것이다.
aggfunc=sum을 제외하면 pivot 함수는 기본적으로 데이터의 평균(mean)을 계산한다.
추가적인 예시를 보며 pivot table에 익숙해져보자.
col = ['Machine','Country','Price','Brand']
data = [['TV','Korea',1000,'A'],
['TV','Japan',1300,'B'],
['TV','China',300,'C'],
['PC','Korea',2000,'A'],
['PC','Japan',3000,'E'],
['PC','China',450,'F']]
df = pd.DataFrame(data=data, columns=col)
print(df)
>>
Machine Country Price Brand
0 TV Korea 1000 A
1 TV Japan 1300 B
2 TV China 300 C
3 PC Korea 2000 A
4 PC Japan 3000 E
5 PC China 450 F
# 기본 사용법
print(df.pivot(index='Machine',columns='Country',values='Price'))
>>
Country China Japan Korea
Machine
PC 450 3000 2000
TV 300 1300 1000
# `values` 값이 리스트일 경우 옆쪽으로 연속 생성
# `values` 를 따로 입력하지 않아도 모든 열이 `values`에 입력되기에 아래와 같이 출력
print(df.pivot(index='Machine',columns='Country',values=['Price','Brand']))
>>
Price Brand
Country China Japan Korea China Japan Korea
Machine
PC 450 3000 2000 F E A
TV 300 1300 1000 C B A
# 이 연속상태에서 [열이름] 형태를 붙여 원하는 values만 출력 가능
print(df.pivot(index='Machine',columns='Country')['Brand'])
>>
Country China Japan Korea
Machine
PC F E A
TV C B A
# `index`가 리스트인 경우
print(df.pivot(index=['Country','Machine'],columns='Brand',values='Price'))
>>
Brand A B C E F
Country Machine
China PC NaN NaN NaN NaN 450.0
TV NaN NaN 300.0 NaN NaN
Japan PC NaN NaN NaN 3000.0 NaN
TV NaN 1300.0 NaN NaN NaN
Korea PC 2000.0 NaN NaN NaN NaN
TV 1000.0 NaN NaN NaN NaN
# `columns`가 리스트인 경우
print(df.pivot(index='Country',columns=['Machine','Brand'],values='Price'))
>>
Machine TV PC
Brand A B C A E F
Country
China NaN NaN 300.0 NaN NaN 450.0
Japan NaN 1300.0 NaN NaN 3000.0 NaN
Korea 1000.0 NaN NaN 2000.0 NaN NaN피벗 변환이 불가능한 경우도 있다.
# 피벗화가 불가능한 중복값이 있는 객체 생성
df2 = pd.DataFrame(data=[['A','x',1],['A','x',2],['B','y',3],['B','z',4]],columns=['col1','col2','col3'])
print(df2)
>>
col1 col2 col3
0 A x 1
1 A x 2
2 B y 3
3 B z 4
# 피벗생성 시 오류 발생
print(df2.pivot(index='col1',columns='col2',values='col3'))
>>
오류발생
ValueError: Index contains duplicate entries, cannot reshape
