Section 01. 개요
01. 주소 공간(address space)
인터넷에 연결된 각 장치의 식별자: IP 주소
- 각각의 장치는 고유한 MAC 주소로 식별
IPv4 주소: 32비트 길이 → or 4,294,967,296의 주소 공간을 갖는다. (현재는 고갈)
인터넷 상에서 유일한(unique) 식별자 → 두 개의 장치가 같은 주소를 가질 수 없다
02. 표기법
표기법은 2진 표기법, 16진 표기법, 점-10진 표기법이 존재
⇒ 2진, 점-10진(Dotted-decimal) 표기법
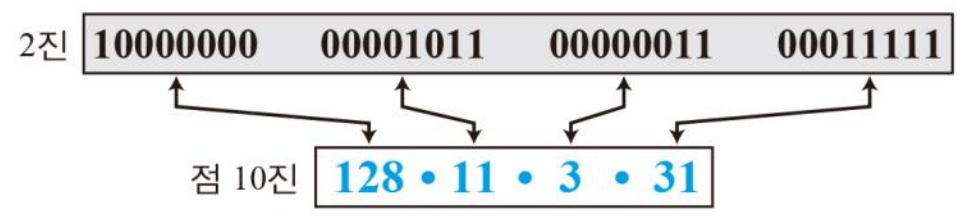
2진에서는 공백, 점 10진에서는 점으로 구분
⇒ 16진, 점-10진, 2진 표기

Section 02. 클래스 기반 주소 지정
IP 주소는 시작할 때 클래스(class) 개념을 이용한다.
90년대 중반에 클래스 기반이 아닌 새로운 주소지정 방법이 등장한다.
⇒ CIDR
01. 클래스 별 주소공간 점유
클래스(class)는 IP주소를 점유율에 따라 구분하는 개념이다.
총 5개(A, B, C, D, E)의 클래스로 구분된다.
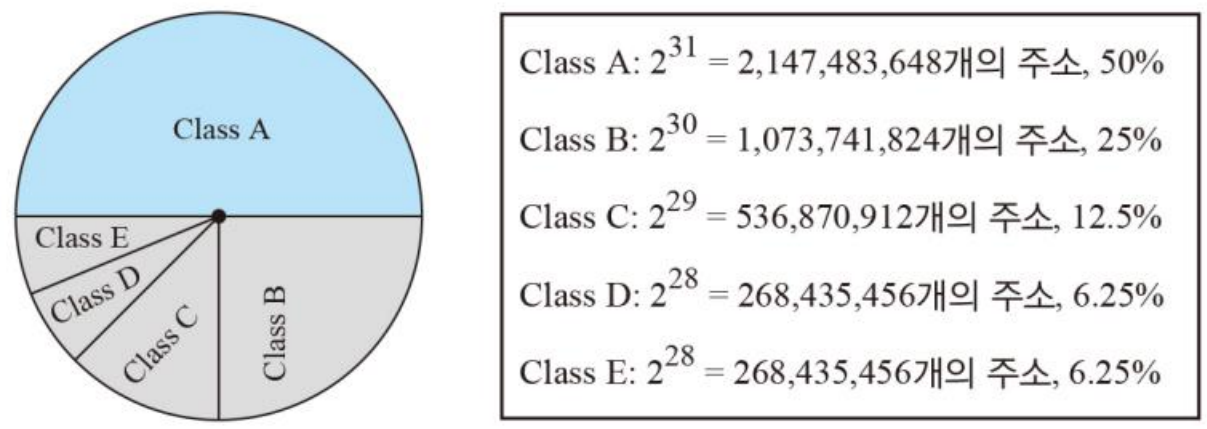
주소 공간의 점유율
IPv4 주소는 총 개이다.
클래스 A부터 남는 주소의 50% 씩 점유율을 가지게 된다.
이때 4Byte로 구성되는 IPv4 주소 중, 첫 번째 Byte를 통해 클래스를 찾을 수 있다.
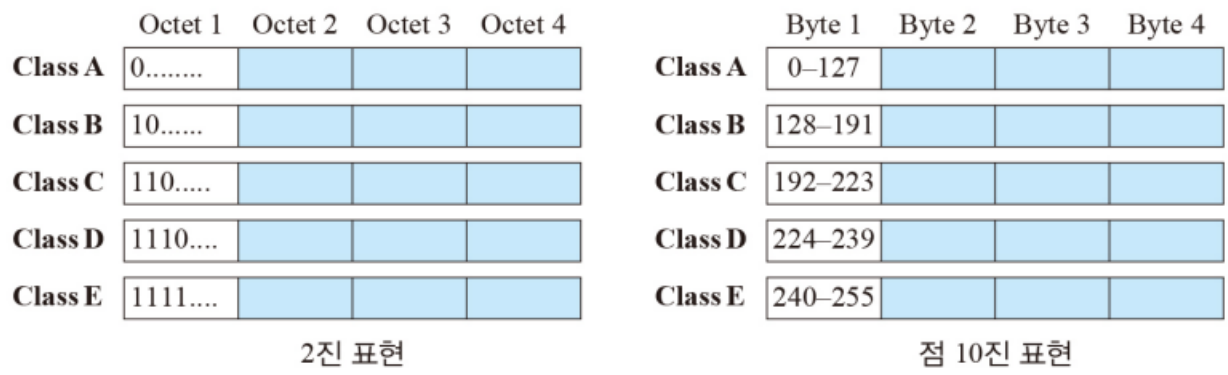
클래스 별 비트 범위
| class | 비트 범위 |
|---|---|
| A | 00000000 ~ 01111111 |
| B | 10000000 ~ 10111111 |
| C | 11000000 ~ 11011111 |
| D | 11100000 ~ 11101111 |
| E | 11110000 ~ 11111111 |
각 클래스 별로 주소의 첫 1바이트는 00000000, 10000000, … 11110000 와 같다.
이는 곧 1이 얼마나 연속되느냐에 따라 클래스를 알아낼 수 있다는 것이다.

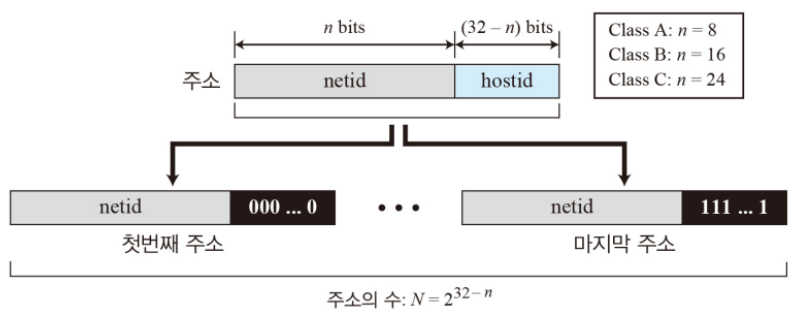
02. 2계층 주소지정 방식

네트워크 내의 모든 주소는 한 블록에 속한다.
netid는 네트워크를 정의, hostid는 네트워크에 연결된 특정 호스트를 정의
IPv4 주소 지정의 목적: 인터넷에서 패킷을 전송하기 위해, 네트워크 계층의 목적지 주소를 지정하는 것이다.
03. A, B, C 클래스 주소의 Netid와 Hostid
IP주소는 네트워크 아이디(Netid)와 호스트 아이디(Hostid)를 활용하여 통신한다.
실제로 우리(호스트)는 하나의 네트워크 망 안에 각각 존재하며, 각 기기에 할당된 IP 주소는 네트워크 아이디와 호스트 아이디로 구성되어 있을 것이다. 우리의 기기로 데이터를 불러올 때는 네트워크 아이디를 통해 내가 속한 네트워크에 접근한 뒤, 그 안에서 호스트 아이디를 통해 나의 기기(호스트)를 찾게 된다.
IP주소의 클래스 별로 용도가 다르다. 클래스 A, B, C는 실제 호스트에게 할당되는 주소로 네트워크 아이디와 호스트 아이디가 구별되어 존재한다. A는 1Byte 만큼, B는 2Byte, C는 3Byte만큼 네트워크 아이디가 구성된다.
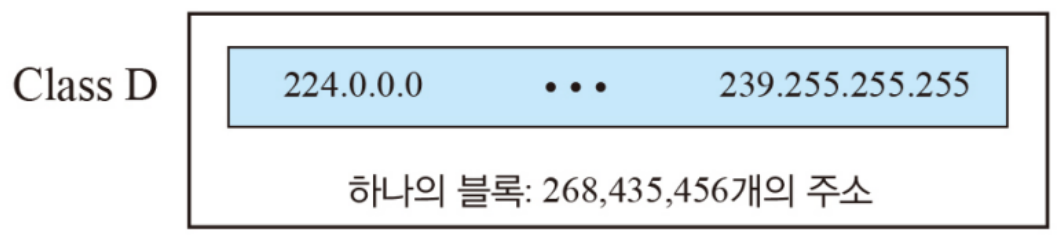
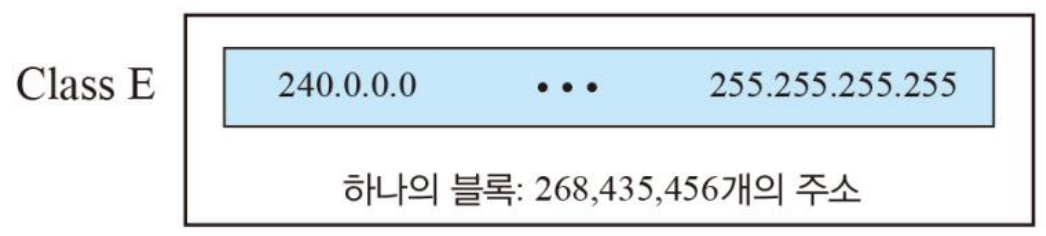
클래스 D, E는 각각 멀티캐스트, 예비용으로 실제 호스트에 할당되지는 않는다.
→ 2계층 주소지정 방식 (네트워크 아이디와 호스트 아이디를 나누는 주소지정 방식)
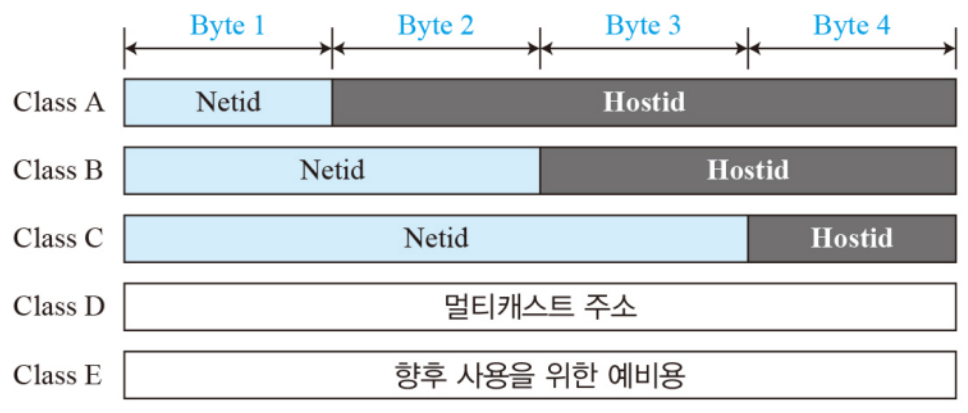
04. 클래스 별 특성
블록: 호스트를 할당할 수 있는, 네트워크 아이디가 고정된 IP주소의 묶음
- 클래스 A의 블록
- 처음 1 Byte만 네트워크 아이디로 지정
- 가장 왼쪽(처음) 비트는 0으로 고정
- 00000000 ~ 01111111 ⇒ 7 비트로 나타낼 수 있는 블록의 수는 = 128
- 각 블록에 속한 주소의 수는 16,777,216개 = 256 256 256 =

⇒ 클래스 A는 할당할 호스트가 아주 많을 때 사용
- 클래스 B의 블록
- 처음 2 Byte만 네트워크 아이디로 지정
- 가장 왼쪽 2bit를 10으로 고정
- 10 000000 00000000 ~ 10 111111 11111111
⇒ 14 비트로 나타낼 수 있는 블록의 수는 = 16,384 - 각 블록에 속한 주소의 수는 65,536개 = 256 * 256 =

- 클래스 C의 블록
- 처음 3 Byte를 네트워크 아이디로 지정
- 가장 왼쪽(처음) 3 비트는 “110”으로 고정
- 110 00000 00000000 00000000 ~ 110 11111 11111111 11111111
⇒ 21 비트로 나타낼 수 있는 블록의 수는 = 2,097,152 - 각 블록에 속한 주소의 수는 256개 =

- 클래스 D와 클래스 E의 블록
- 클래스 기반 주소지정에서 정보 추출하기
클래스 별로 netid를 지정하는 비트 수를 통해 netid와 hostid에 관한 정보를 추출할 수 있다.
05. 네트워크 주소
이때, 블록의 첫 번째 주소와 가장 마지막 주소는 일반적으로 사용하지 않는다.
첫 번째 주소는 네트워크의 주소로 쓰이며, 마지막 주소는 브로드캐스트 주소이다.
브로드캐스트 주소는 네트워크에 연결된, 해당 주소 범위에 있는 모든 호스트에게 트래픽)데이터)을 전달할 수 있다.
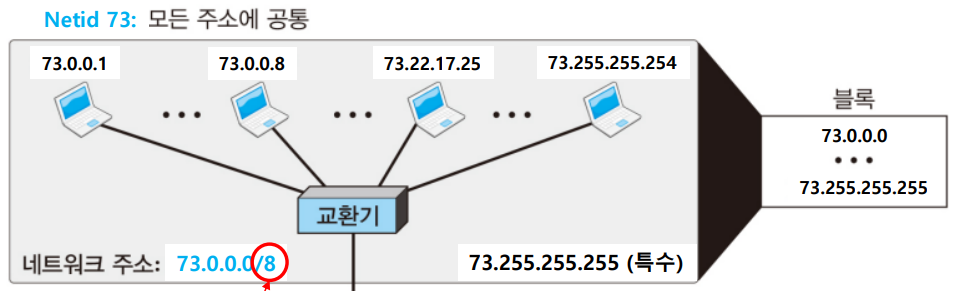
네트워크 id가 73이고, netid는 8bit인 네트워크가 있다. 이때, 73.0.0.0은 네트워크 주소로, 73.255.255.255는 브로드캐스트를 위한 주소이다.
네트워크 주소는 네트워크의 식별자이다.
네트워크 주소는 목적지로 패킷을 전송하는데 사용되는 것처럼, 주소가 주어지면 블록에 대한 정보를 찾을 수 있어 아주 중요하다. 라우터는 패킷이 도착하면 어떤 인터페이스로 보내야 하는지 알아야 하며, 이를 위해서는 네트워크 주소가 필요하다.
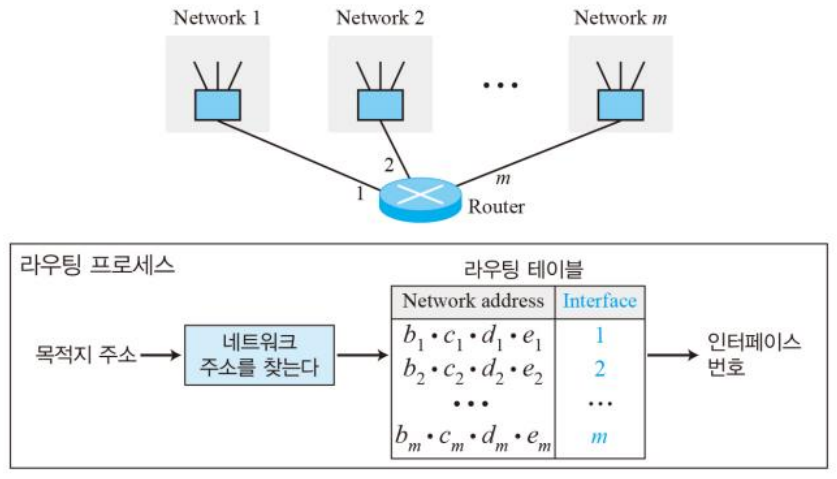
06. 네트워크 마스크(디폴트 마스크)
네트워크 마스크는 목적지 주소를 이용하여 네트워크 주소를 찾아내는 것에 사용된다.
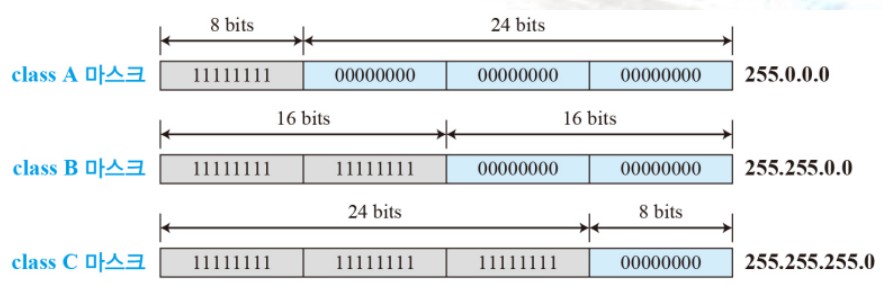
기존의 IP주소 중에서 netid(네트워크 주소) 부분은 1, hostid 부분은 0으로 대체된다고 보면 된다.
디폴트 마스크에서 목적지 주소와 기본 마스크를 AND 연산할 경우 네트워크 주소를 찾아낼 수 있다.
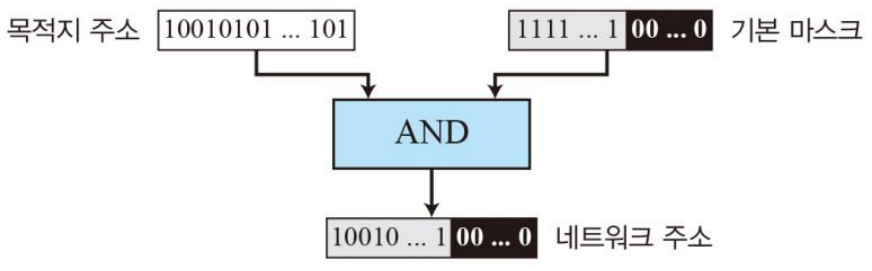
AND 연산은 모두 1인 것만 1로 반환하기 때문에, 목적지 주소에서 hostid를 제외하고 네트워크 주소만을 온전히 가져올 수 있다. (hostid 부분은 모두 0으로)
07. 3계층 주소 지정: 서브넷팅
흔히 사용되는 IPv4 주소 체계는 클래스를 나누어 IP주소를 할당했다. 하지만, 이 방식은 매우 비효율적인데 실제로 할당 받은 조직이 할당 받은 것보다 훨씬 적은 수의 직원이 있다면 그만큼 낭비되는 호스트가 존재하는 것이다. 이를 해결하기 위해 효율적으로 사용할 수 있는 서브넷이 등장했다.
서브넷팅(subnetting)은 IP 주소 낭비를 방지하기 위해 원본 네트워크를 여러 개의 서브넷으로 분리하는 과정이다. 이때 서브넷은 자신만의 주소를 갖는다.
클래스 A나 B를 받은 조직이 보안과 관리를 더 잘하기 위해 서브넷으로 나누기도 한다.
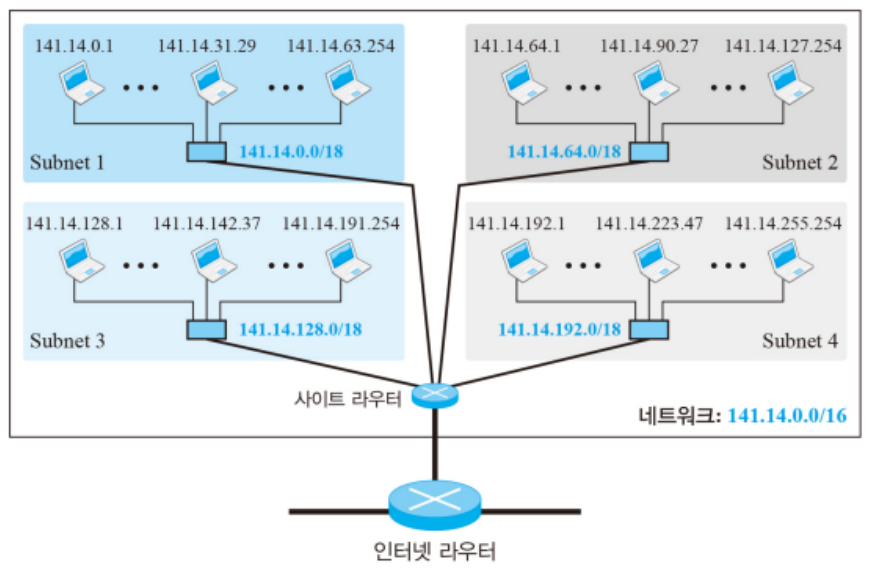
이때 네트워크는 141.14.0.0/16으로 16bit, 141.14를 netid로 한다. 여기에 2개의 비트를 추가로 서브넷팅에 사용하여, 총 4개의 서브넷은 18bit를 netid로 사용한다. (00, 01, 10, 11)


네트워크 마스크와 서브넷 마스크. 서브넷으로 나누면서 netid의 길이가 늘어나며, subnetid라고 한다.
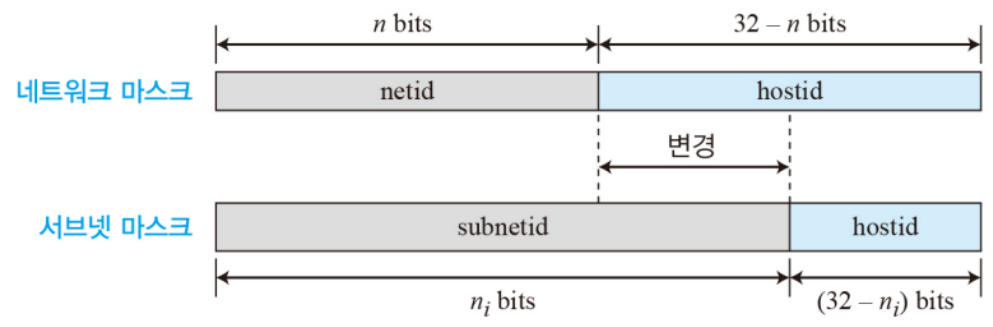
따라서 서브넷팅은 서브넷 마스크의 bit 수를 증가시키는 것이다. 서브넷 마스크의 bit 수를 1씩 증가시키면, 할당할 수 있는 네트워크가 2배로 증가하고, 할당할 수 있는 호스트는 2배로 감소한다.

서브넷팅에서 subnetid 길이 구하기
서브넷팅은 netid의 길이는 증가시키고 hostid의 길이는 감소시킨다.
네트워크를 같은 수의 호스트를 가지는 s개의 서브넷으로 나누면 각 서브넷의 subnetid를 구할 수 있다.
- : 기존 netid의 길이
- : subnetid의 길이
- : 2의 거듭제곱인 서브넷의 개수
Section 03. 클래스 없는 주소 지정
클래스 기반 주소 지정에서 서브넷팅은 실제로 주소 고갈 문제를 해결하지 못한다. 인터넷이 성장함에 따라 장기적으로 큰 주소 공간을 확보하는 것이 필요하다.
IPv6는 장기적 해결책으로서 개발되었지만, 각 기관에 대해 주소를 분배하는 것에 대한 해결책은 아니다.
클래스기반이 아닌 주소 지정(classless addressing)은 여전히 IPv4를 사용하면서 각 기관에 주소를 효율적으로 분배하는 해결책이다.
01. 가변길이 블록

각 기관은 가변길이 블록으로 , , … 개의 주소를 갖는 블록을 지정할 수 있다.
02. 프리픽스(prefix)와 서픽스(suffix)
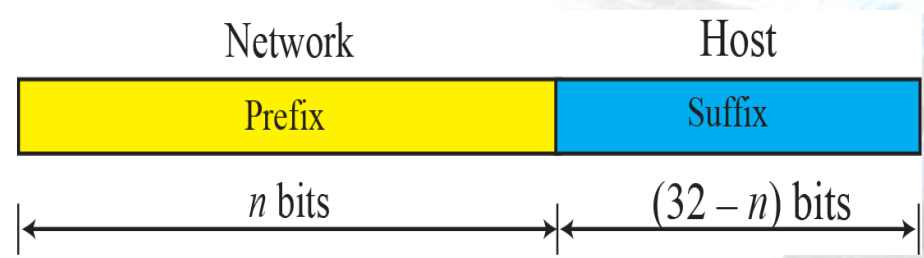
- 프리픽스(prefix): netid와 동일
- 서픽스(suffix): hostid와 동일
03. CIDR(classless inter-domain routing)
CIDR는 IP 주소의 영역을 여러 네트워크 영역으로 나누기 위해, IP를 묶는 방식이다.
- 이는 여러 개의 사설망을 구축하기 위해 망을 나누는 방법이다.
CIDR Block / CIDR Notation
- CIDR Block: IP 주소의 집합
- CIDR Notation: CIDR Block을 표시하는 방법
- 네트워크 주소와 호스트 주소로 구성하며, 각 호스트 주소 숫자 만큼의 IP를 가진 네트워크 망을 형성할 수 있다.
Section 04. IPv6 주소
IPv6 등장 배경
IPv4의 주소 공간의 한계, 최소 지연과 자원의 예약이 불가, 암호화와 인증을 제공하지 않는 한계점으로 IPv6이 등장한다.
IPv6은 4Byte를 사용하는 IPv4와 다르게 16Byte의 주소 길이를 갖는다.

16Byte는 곧 128bit로 IPv4의 주소 공간은 , IPv4 주소의 배로 절대 주소가 고갈되지 않는다.
IPv6 주소 표기법
-
점 10진 표기법

-
콜론 16진 표기법: 32개의 16진수

-
제로 압축

-
혼합 표기법
콜론 16진 표기법 + 점 10진 표기법

가장 왼쪽이 모두 0인 주소는 압축하여 표현한다.

3가지 주소 유형
- 유니캐스트(Unicast)
- one to one, 패킷을 특정 수신자에게 전달한다
- 단일 인터페이스(컴퓨터 또는 라우터)를 정의한다
- 애니캐스트(Anycase)
- one to nearest, 단일 주소를 모두 공유하는 컴퓨터 그룹을 정의하고 그 중에서도 가장 접근이 쉬운 그룹의 멤버 중 한 명에게만 전달한다
- 멀티캐스트(Multicast)
- one to many, 컴퓨터 그룹을 정의하여 그 안에서 전달한다. ⇒ zoom 같은
- one to many, 컴퓨터 그룹을 정의하여 그 안에서 전달한다. ⇒ zoom 같은
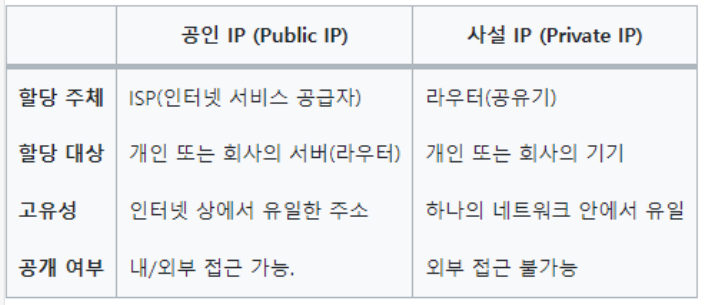
(참고) 공인 IP와 사설 IP
01. 공인 IP (공용 IP)
인터넷 사용자의 로컬 네트워크를 식별하기 위해 ISP(인터넷 서비스 공급자, KT, LG U+, SKT)가 제공하는 IP 주소
전세계에서 유일한 IP 주소를 가진다. → uniuqe
주소가 외부에 공개되어 있어 인터넷에 연결된 다른 PC로부터의 접근이 가능하다.
- 유동 IP: 장비에 고정적으로 IP를 부여하지 않고 컴퓨터를 사용할 때 남아 있는 IP(IP pool) 중에서 돌아가며 부여한다.
- 고정 IP: 컴퓨터에 고정적으로 부여된 IP로 한 번 부여되면 반납하기 전까지 다른 장비에 부여할 수 없다. (주로 산업 현장, 금융, 사무실 네트워크 망에서 사용)
- 인터넷 상에서 서버를 운영하고자 할 때는 공인 IP를 고정 IP로 부여받아야 한다.
02. 사설 IP
일반 가정이나 회사 내에 할당된 네트워크의 IP 주소 → 로컬 IP, 가상 IP라고 한다.
IPv4의 주소 부족으로 인해 (공인 IP에서) 서브넷팅된 IP이기 때문에 라우터에 의해 로컬 네트워크 상의 PC나 장치에 할당한다.
사설 IP 주소만으로는 인터넷에 직접 연결할 수 없다. 라우터를 통해 1개의 공인(pulic) IP만 할당하고, 라우터에 연결된 개인 PC는 사설(private) IP를 각각 할당 받아 인터넷에 접속할 수 있다. (보안을 위해)
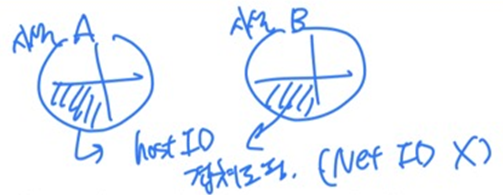
사설 IP는 공인 IP에서 서브넷팅된 것이기 때문에, 서로 다른 사설 네트워크에 있는 호스트의 주소(hostid)는 같을 수 있다.
03. 공인 IP와 사설 IP
- 공인 IP와 사설 IP의 차이
- 공인 IP와 사설 IP의 관계
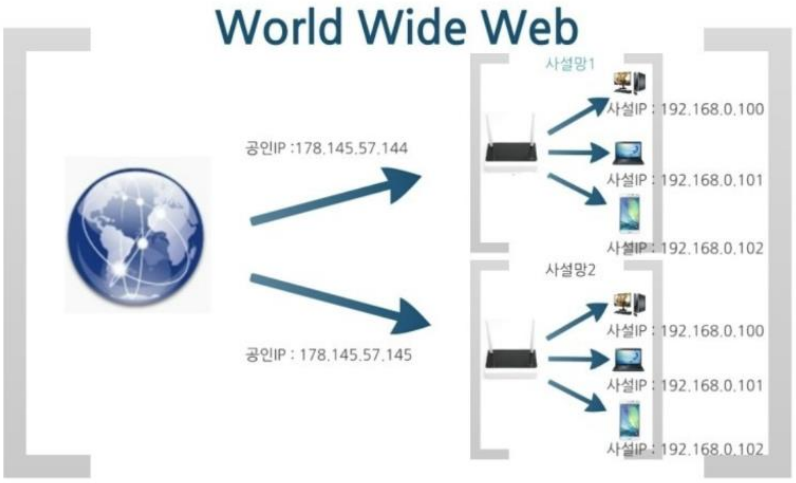
공인 IP가 사설 IP를 포함한다.
