🏆 학습 목표
-
단어의 분산 표현(Distributed Representation)
- 원-핫 인코딩의 개념과 단점에 대해서 이해할 수 있습니다.
- 분포 기반의 표현, 임베딩이 무엇인지 설명할 수 있습니다.
-
Word2Vec
- CBoW와 Skip-gram의 차이에 대해서 설명할 수 있습니다.
- Word2Vec의 임베딩 벡터를 시각화한 결과가 어떤 특징을 가지는지 설명할 수 있습니다.
-
fastText
- OOV 문제가 무엇인지에 대해 설명할 수 있습니다.
- 철자(Character) 단위 임베딩 방법의 장점에 대해 설명할 수 있습니다.
분산 표현 (Distributed Representation)
분포 가설에 기반하여 주변 단어 분포를 기준으로 단어 자체의 벡터 표현을 결정하는 방법
분포 가설
- '단어의 의미는 주변 단어에 의해 형성된다'
- '비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다'
- 유유상종 : 비슷한 의미를 지닌 단어는 주변 단어 분포도 비슷하다
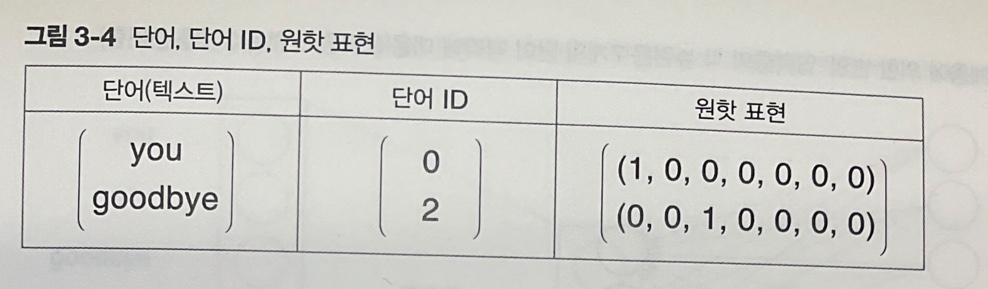
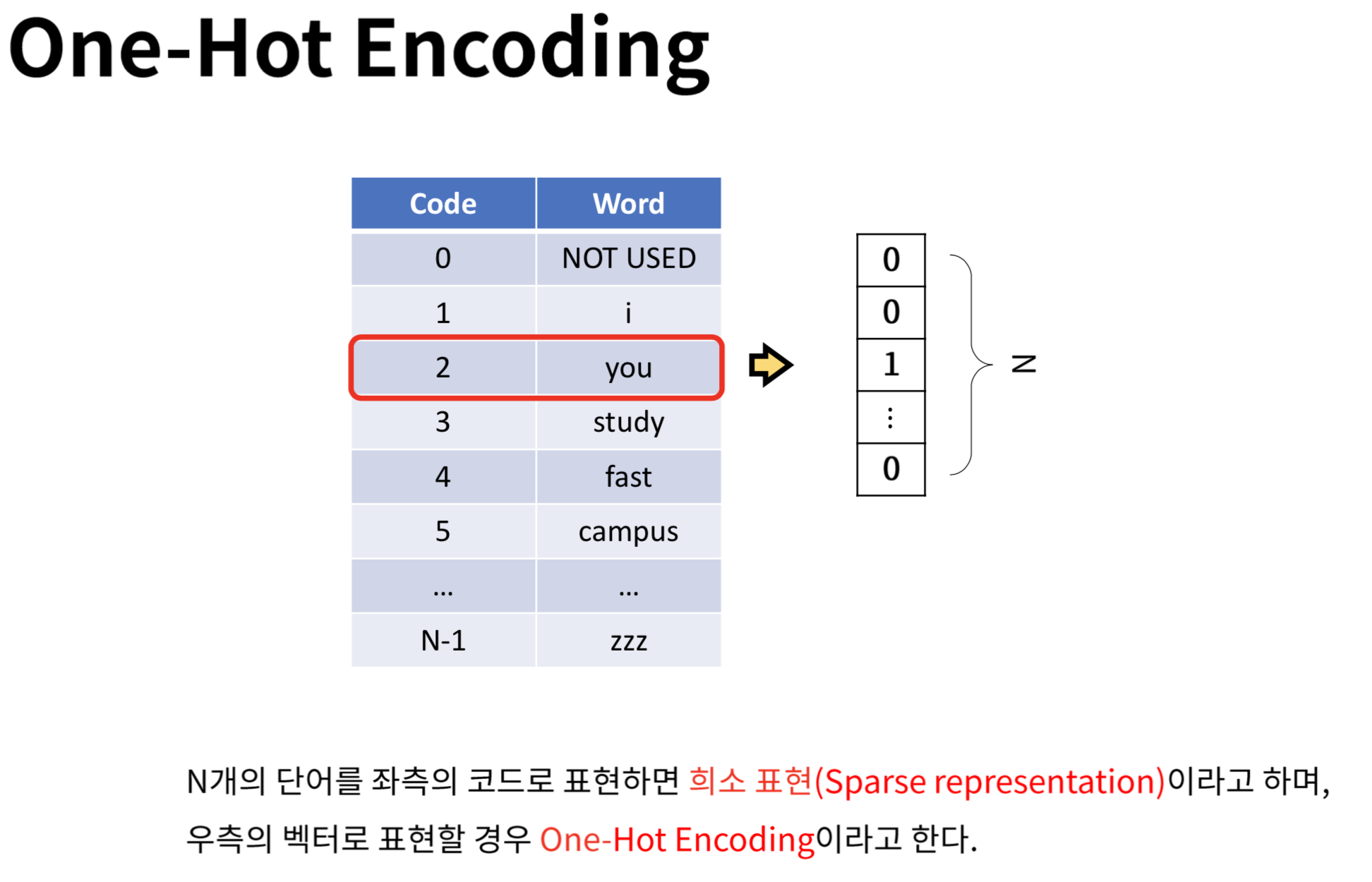
원-핫 인코딩(One-hot Encoding)
- 단어를 벡터화하고자 할 때 선택할 수 있는 가장 쉬운 방법
- 신경망은 "you", "say" 등의 단어를 있는 그대로 처리할 수 없으니 단어를 '고정 길이의 벡터(원핫 벡터)'로 변환해야 한다.
- 원핫 표현 : 벡터의 원소 중 하나만 1이고 나머지는 모두 0인 벡터
ex) 말뭉치 : "You say goodbye and I say hello."
어휘(총 7개) : "You", "say", "goodbye", "and", "I", "say", "hello", "."
원핫 벡터 : 총 어휘 수만큼의 원소를 갖는 벡터 -> You : (1,0,0,0,0,0,0)

sent = "I am a student"
word_lst = sent.split() # ['I', 'am', 'a', 'student']
word_dict = {}
for idx, word in enumerate(word_lst):
# [ <표현식> for <변수명> in <시퀀스> ]
vec = [0 for _ in range(len(word_lst))] # [0, 0, 0, 0]
vec[idx] = 1
word_dict[word] = vec
print(word_dict)
#>>> {'I': [1, 0, 0, 0], 'am': [0, 1, 0, 0], 'a': [0, 0, 1, 0], 'student': [0, 0, 0, 1]}원-핫 인코딩의 유사도
원-핫 인코딩의 치명적인 단점은 단어 간 유사도를 구할 수 없다는 점이다.
단어 간 유사도를 구할 때에는 아래의 코사인 유사도(cosine similarity)가 자주 사용되는데
원-핫 인코딩을 사용한 두 벡터의 내적은 항상 0이므로
어떤 두 단어를 골라 코사인 유사도를 구하더라도 그 값은 0이 된다.
이렇게 두 단어 사이의 관계를 전혀 알 수 없다는 것이 원-핫 인코딩의 최대 단점이다.
import numpy as np
def cos_sim(a, b):
arr_a = np.array(a)
arr_b = np.array(b)
# 코사인 유사도(Cosine similarity) = 내적값 / 절댓값의 곱
result = np.dot(arr_a, arr_b) / (np.linalg.norm(arr_a)*np.linalg.norm(arr_b))
return result
print(f"I 와 am 의 코사인 유사도 : {cos_sim(word_dict['I'], word_dict['am'])}")
print(f"I 와 student 의 코사인 유사도 : {cos_sim(word_dict['I'], word_dict['student'])}")이러한 원-핫 인코딩의 단점을 해결하기 위해 등장한 것이 바로 임베딩(Embedding)이다.
임베딩(Embedding)
- 단어를 고정 길이의 벡터, 즉 차원이 일정한 벡터로 나타냄
- 임베딩을 거친 단어 벡터는 원-핫 인코딩(binary값)과는 다른 형태의 값(연속적인 값)을 가지게 됨
ex) [0.04227, -0.0033, 0.1607, -0.0236, ...]
원-핫 인코딩, 희소 표현, 밀집 표현, 임베딩 벡터

어떻게 이런 벡터가 만들어지는지,
가장 널리 알려진 임베딩 방법인 Word2Vec을 통해 알아보자.
Word2Vec
- 말 그대로 단어를 벡터로(Word to Vector) 나타내는 방법
- 특정 단어 양 옆에 있는 단어(window size)의 관계를 활용하기 때문에 분포 가설을 잘 반영한다.
- 단어 간의 의미적, 문법적 관계를 잘 나타낸다.
- CBoW와 Skip-gram의 2가지 방법이 있다.
- 딥러닝이 아닌 신경망
model : CBoW & Skip-gram
- 주변 단어에 대한 정보(맥락)를 기반으로 중심 단어의 정보(타깃)를 예측하는 모델
▶️ CBoW(Continuous Bag-of-Words) - 중심 단어(타깃)의 정보를 기반으로 주변 단어의 정보(맥락)를 예측하는 모델
▶️ Skip-gram
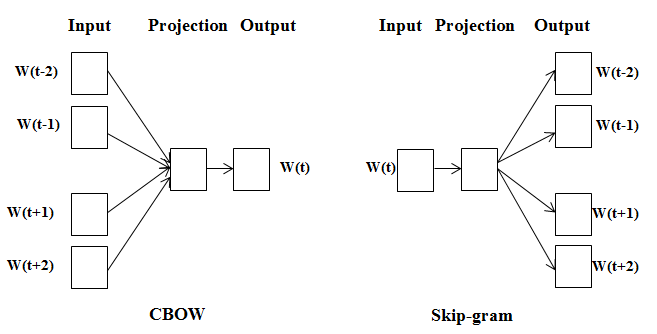
=> 역전파 관점에서 보면 Skip-gram에서 훨씬 더 많은 학습이 일어나기 때문에 Skip-gram의 성능이 조금 더 좋게 나타나지만 동시에 계산량이 많기 때문에 Skip-gram에 드는 리소스가 더 크다.
model structure(skip-gram)
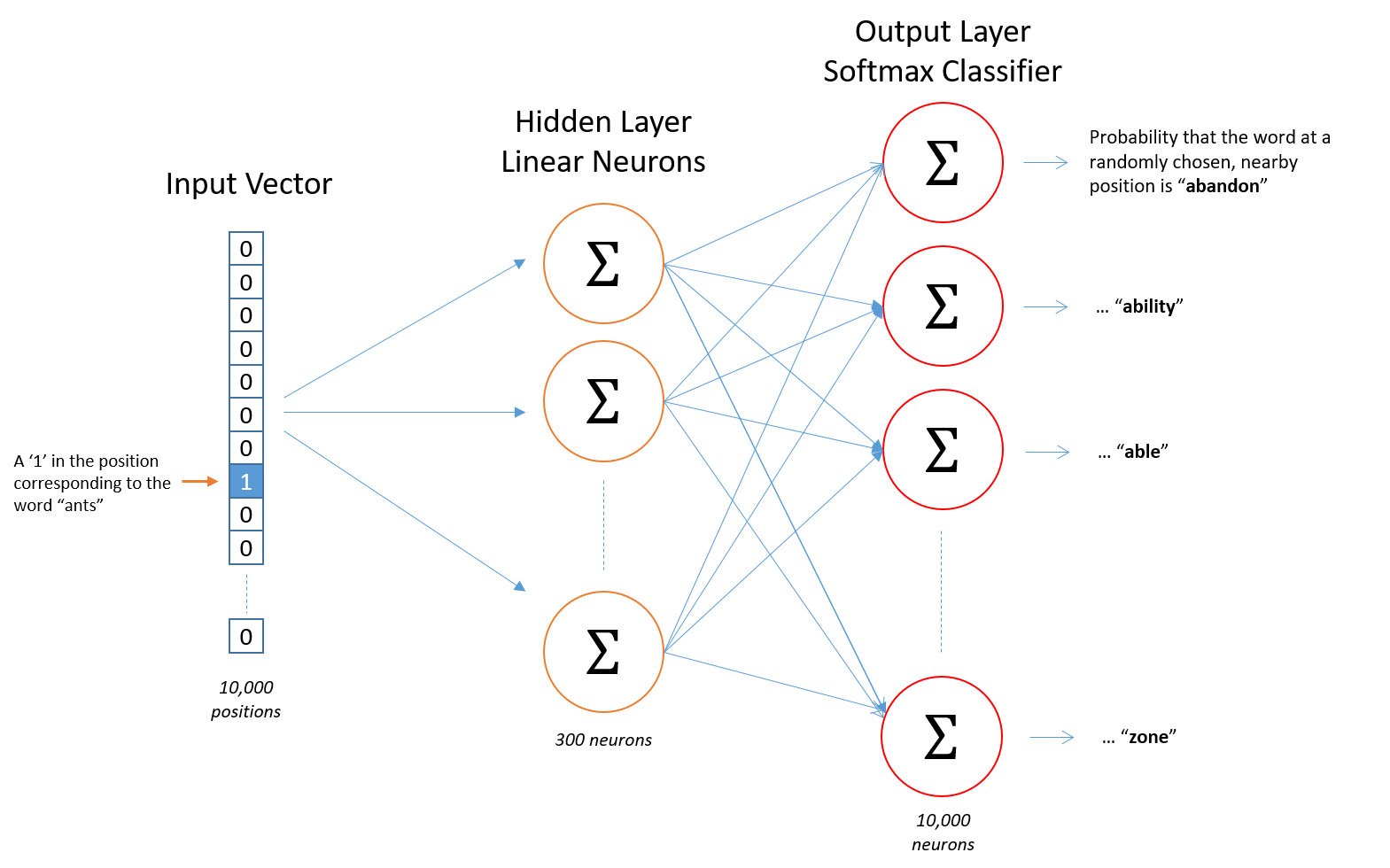
-
입력(Input)
: 원-핫 인코딩된 단어 벡터 (원-핫 벡터 차원 = 토큰 개수) -
은닉층(Hidden layer)
: 임베딩 벡터의 차원 수 만큼의 노드로 구성되며 은닉층이 1개인 신경망이다.
(노드 수 = word2vec을 학습시킬 사람이 정할 값) -
출력층(Output layer)
: 단어 개수 만큼의 노드로 이루어져 있으며 활성화 함수로 소프트맥스(softmax) 사용
(노드 수 = 토큰 개수 = 입력층 벡터 차원)
Word2Vec data generation(skip gram)
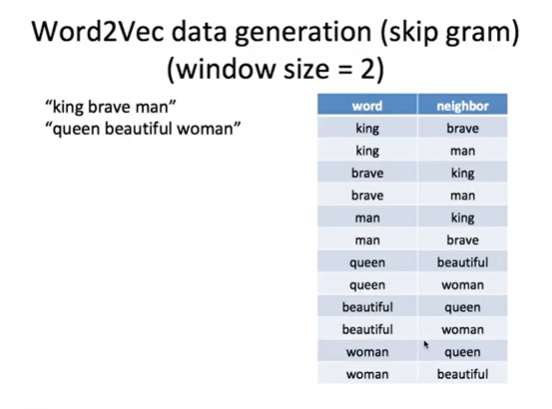

딥러닝 모델에는 원핫인코딩으로 표현된 벡터가 들어가게 되고
중심단어를 입력(input)으로, 문맥단어를 레이블(target)로 하는 분류(Classification)를 통해 학습한다
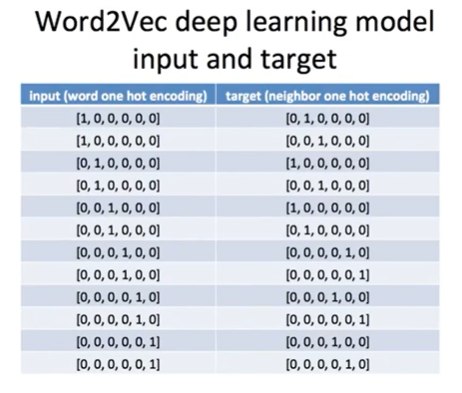
Word2Vec training
- Hidden layer = Word2Vec
-> 원핫인코딩한 단어의 차원(입력층 벡터 차원) 보다 적은 차원의 벡터를 가지게 함으로써 유사도를 갖게 하기 위함
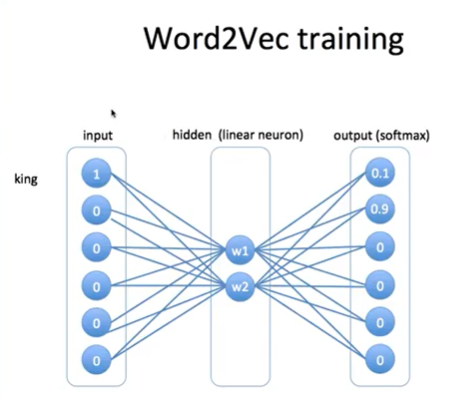
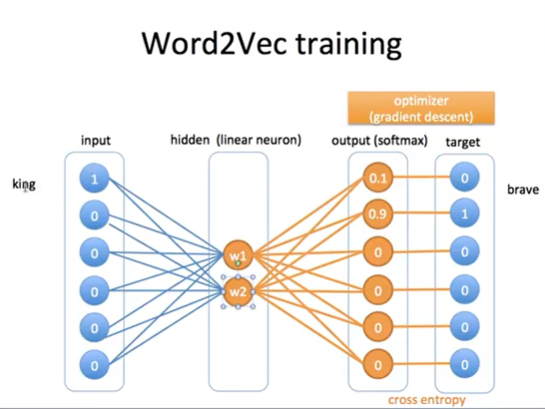
-> Input값 입력
-> Hidden layer w1, w2값 결정
-> 각 단어의 점수 - softmax(점수) : 대응 단어의 출현 확률
-> output값과 target값의 차이를 통해 cross entropy 계산함
-> 역전파(backpropagation) 실행 - w1, w2값 점차 업데이트
- 다른 데이터들 입력
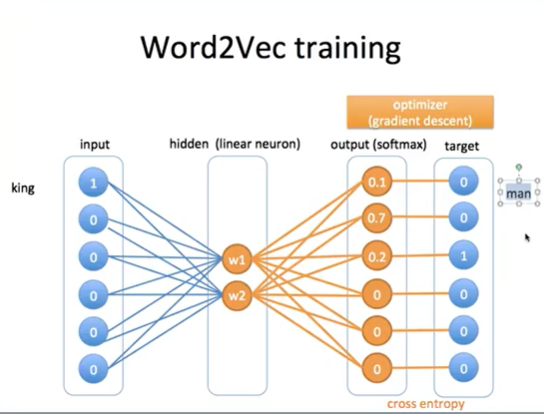

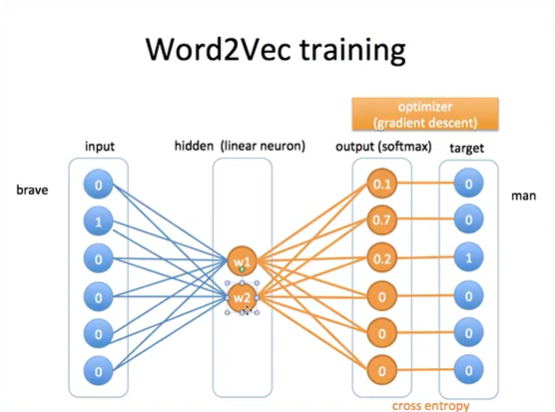
- embedding값 = w1, w2
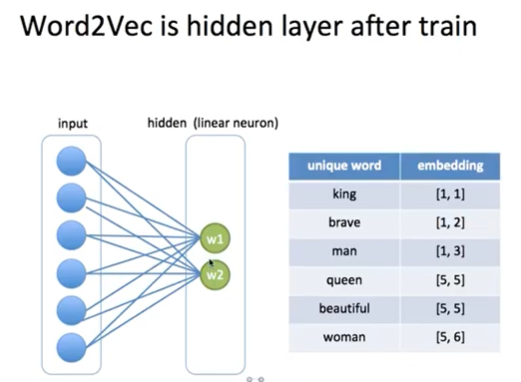
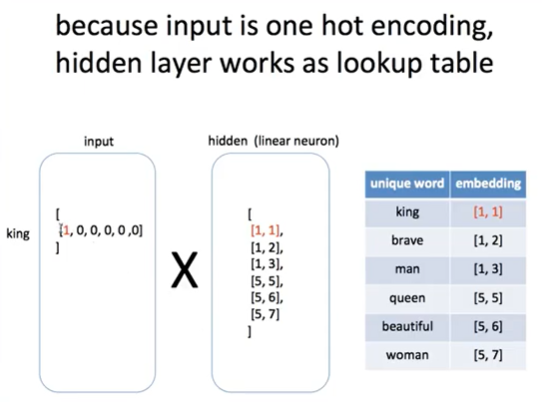

-> lookup table
-> encoding : 6차원, embedding : 2차원
Word2Vec으로 임베딩한 벡터 시각화
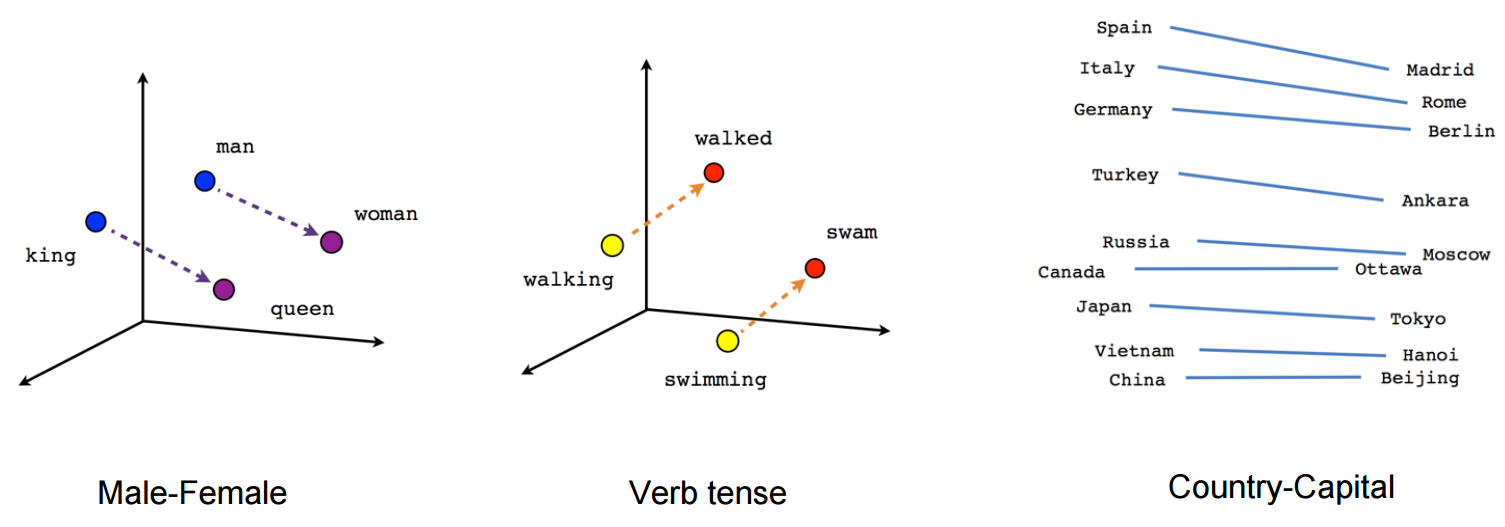
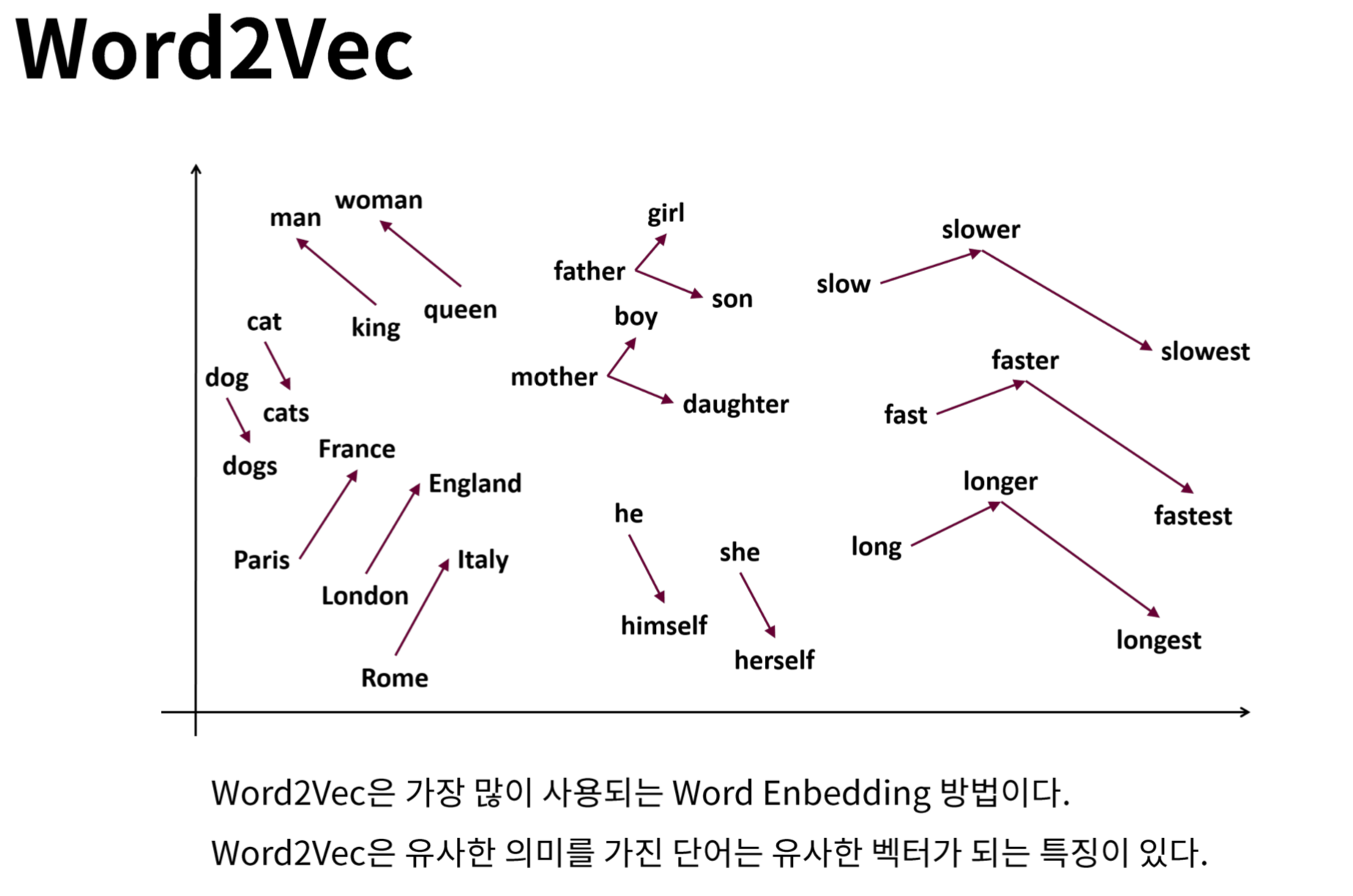
1. man - woman 사이의 관계와 king - queen 사이의 관계가 매우 유사하게 나타남
-> 생성된 임베딩 벡터가 단어의 의미적(Semantic) 관계를 잘 표현하는 것을 확인할 수 있습니다.
2. walking - walked 사이의 관계와 swimming - swam 사이의 관계가 매우 유사하게 나타난다.
-> 생성된 임베딩 벡터가 단어의 문법적(혹은 구조적, Syntactic)인 관계도 잘 표현하는 것을 확인할 수 있습니다.
3. 고유명사에 대해서도 나라 - 수도 와 같은 관계를 잘 나타내고 있는 것을 확인할 수 있습니다.
=> Word2Vec을 통해 얻은 임베딩 벡터는 단어 간의 의미적, 문법적 관계를 잘 나타낸다.
Word2Vec 실습 : gensim 패키지
"""
gensim : Word2Vec으로 사전 학습된 임베딩 벡터를 쉽게 사용해볼 수 있는 패키지
"""
### (시작하기 전에) gensim 패키지를 최신 버전으로 업그레이드
!pip install gensim --upgrade
### 최신 버전인지 확인
import gensim
gensim.__version__
### 구글 뉴스 말뭉치로 학습된 word2vec 벡터 다운
import gensim.downloader as api
wv = api.load('word2vec-google-news-300')
wv
"""
<gensim.models.keyedvectors.KeyedVectors at 0x7f1cf8e51e50>
"""
### wv : 0 ~ 9 인덱스에 위치한 단어가 무엇인지 확인
for idx, word in enumerate(wv.index_to_key):
if idx == 10:
break
print(f"word #{idx}/{len(wv.index_to_key)} is '{word}'")
### 임베딩 벡터의 차원과 값
# king이라는 단어의 벡터의 shape을 출력하여 임베딩 벡터의 차원 확인
vec_king = wv['king']
print(f"Embedding dimesion is : {vec_king.shape}\n")
print(f"Embedding vector of 'king' is \n\n {vec_king}")
"""
Embedding dimesion is : (300,)
Embedding vector of 'king' is
[ 1.25976562e-01 2.97851562e-02 8.60595703e-03 1.39648438e-01
-2.56347656e-02 -3.61328125e-02 1.11816406e-01 -1.98242188e-01
5.12695312e-02 3.63281250e-01 -2.42187500e-01 -3.02734375e-01
-1.77734375e-01 -2.49023438e-02 -1.67968750e-01 -1.69921875e-01
3.46679688e-02 5.21850586e-03 4.63867188e-02 1.28906250e-01
1.36718750e-01 1.12792969e-01 5.95703125e-02 1.36718750e-01
1.01074219e-01 -1.76757812e-01 -2.51953125e-01 5.98144531e-02
3.41796875e-01 -3.11279297e-02 1.04492188e-01 6.17675781e-02
1.24511719e-01 4.00390625e-01 -3.22265625e-01 8.39843750e-02
3.90625000e-02 5.85937500e-03 7.03125000e-02 1.72851562e-01
1.38671875e-01 -2.31445312e-01 2.83203125e-01 1.42578125e-01
3.41796875e-01 -2.39257812e-02 -1.09863281e-01 3.32031250e-02
-5.46875000e-02 1.53198242e-02 -1.62109375e-01 1.58203125e-01
-2.59765625e-01 2.01416016e-02 -1.63085938e-01 1.35803223e-03
-1.44531250e-01 -5.68847656e-02 4.29687500e-02 -2.46582031e-02
1.85546875e-01 4.47265625e-01 9.58251953e-03 1.31835938e-01
9.86328125e-02 -1.85546875e-01 -1.00097656e-01 -1.33789062e-01
-1.25000000e-01 2.83203125e-01 1.23046875e-01 5.32226562e-02
-1.77734375e-01 8.59375000e-02 -2.18505859e-02 2.05078125e-02
-1.39648438e-01 2.51464844e-02 1.38671875e-01 -1.05468750e-01
1.38671875e-01 8.88671875e-02 -7.51953125e-02 -2.13623047e-02
1.72851562e-01 4.63867188e-02 -2.65625000e-01 8.91113281e-03
1.49414062e-01 3.78417969e-02 2.38281250e-01 -1.24511719e-01
-2.17773438e-01 -1.81640625e-01 2.97851562e-02 5.71289062e-02
-2.89306641e-02 1.24511719e-02 9.66796875e-02 -2.31445312e-01
5.81054688e-02 6.68945312e-02 7.08007812e-02 -3.08593750e-01
-2.14843750e-01 1.45507812e-01 -4.27734375e-01 -9.39941406e-03
1.54296875e-01 -7.66601562e-02 2.89062500e-01 2.77343750e-01
-4.86373901e-04 -1.36718750e-01 3.24218750e-01 -2.46093750e-01
-3.03649902e-03 -2.11914062e-01 1.25000000e-01 2.69531250e-01
2.04101562e-01 8.25195312e-02 -2.01171875e-01 -1.60156250e-01
-3.78417969e-02 -1.20117188e-01 1.15234375e-01 -4.10156250e-02
-3.95507812e-02 -8.98437500e-02 6.34765625e-03 2.03125000e-01
1.86523438e-01 2.73437500e-01 6.29882812e-02 1.41601562e-01
-9.81445312e-02 1.38671875e-01 1.82617188e-01 1.73828125e-01
1.73828125e-01 -2.37304688e-01 1.78710938e-01 6.34765625e-02
2.36328125e-01 -2.08984375e-01 8.74023438e-02 -1.66015625e-01
-7.91015625e-02 2.43164062e-01 -8.88671875e-02 1.26953125e-01
-2.16796875e-01 -1.73828125e-01 -3.59375000e-01 -8.25195312e-02
-6.49414062e-02 5.07812500e-02 1.35742188e-01 -7.47070312e-02
-1.64062500e-01 1.15356445e-02 4.45312500e-01 -2.15820312e-01
-1.11328125e-01 -1.92382812e-01 1.70898438e-01 -1.25000000e-01
2.65502930e-03 1.92382812e-01 -1.74804688e-01 1.39648438e-01
2.92968750e-01 1.13281250e-01 5.95703125e-02 -6.39648438e-02
9.96093750e-02 -2.72216797e-02 1.96533203e-02 4.27246094e-02
-2.46093750e-01 6.39648438e-02 -2.25585938e-01 -1.68945312e-01
2.89916992e-03 8.20312500e-02 3.41796875e-01 4.32128906e-02
1.32812500e-01 1.42578125e-01 7.61718750e-02 5.98144531e-02
-1.19140625e-01 2.74658203e-03 -6.29882812e-02 -2.72216797e-02
-4.82177734e-03 -8.20312500e-02 -2.49023438e-02 -4.00390625e-01
-1.06933594e-01 4.24804688e-02 7.76367188e-02 -1.16699219e-01
7.37304688e-02 -9.22851562e-02 1.07910156e-01 1.58203125e-01
4.24804688e-02 1.26953125e-01 3.61328125e-02 2.67578125e-01
-1.01074219e-01 -3.02734375e-01 -5.76171875e-02 5.05371094e-02
5.26428223e-04 -2.07031250e-01 -1.38671875e-01 -8.97216797e-03
-2.78320312e-02 -1.41601562e-01 2.07031250e-01 -1.58203125e-01
1.27929688e-01 1.49414062e-01 -2.24609375e-02 -8.44726562e-02
1.22558594e-01 2.15820312e-01 -2.13867188e-01 -3.12500000e-01
-3.73046875e-01 4.08935547e-03 1.07421875e-01 1.06933594e-01
7.32421875e-02 8.97216797e-03 -3.88183594e-02 -1.29882812e-01
1.49414062e-01 -2.14843750e-01 -1.83868408e-03 9.91210938e-02
1.57226562e-01 -1.14257812e-01 -2.05078125e-01 9.91210938e-02
3.69140625e-01 -1.97265625e-01 3.54003906e-02 1.09375000e-01
1.31835938e-01 1.66992188e-01 2.35351562e-01 1.04980469e-01
-4.96093750e-01 -1.64062500e-01 -1.56250000e-01 -5.22460938e-02
1.03027344e-01 2.43164062e-01 -1.88476562e-01 5.07812500e-02
-9.37500000e-02 -6.68945312e-02 2.27050781e-02 7.61718750e-02
2.89062500e-01 3.10546875e-01 -5.37109375e-02 2.28515625e-01
2.51464844e-02 6.78710938e-02 -1.21093750e-01 -2.15820312e-01
-2.73437500e-01 -3.07617188e-02 -3.37890625e-01 1.53320312e-01
2.33398438e-01 -2.08007812e-01 3.73046875e-01 8.20312500e-02
2.51953125e-01 -7.61718750e-02 -4.66308594e-02 -2.23388672e-02
2.99072266e-02 -5.93261719e-02 -4.66918945e-03 -2.44140625e-01
-2.09960938e-01 -2.87109375e-01 -4.54101562e-02 -1.77734375e-01
-2.79296875e-01 -8.59375000e-02 9.13085938e-02 2.51953125e-01]
"""
### 말뭉치에 등장하지 않는 단어의 임베딩 벡터
# 말뭉치에 등장하지 않는 단어(Unknown token)
unk = 'cameroon'
try:
vec_unk = wv[unk]
except KeyError:
print(f"The word #{unk} does not appear in this model")
"""
The word #cameroon does not appear in this model
=> Word2Vec은 말뭉치에 등장하지 않는 단어는 벡터화 할 수 없다는 단점이 있다.
"""
### 단어 간 유사도 파악 : .similarity
#원-핫 인코딩과 다르게 임베딩 벡터는 단어 간 유사도가 0이 아닌 값으로 나온다.
pairs = [
('car', 'minivan'),
('car', 'bicycle'),
('car', 'airplane'),
('car', 'cereal'),
('car', 'democracy')
]
for w1, w2 in pairs:
print(f'{w1} ======= {w2}\t {wv.similarity(w1, w2):.2f}')
"""
car ======= minivan 0.69
car ======= bicycle 0.54
car ======= airplane 0.42
car ======= cereal 0.14
car ======= democracy 0.08
"""
### 가장 유사한 n개의 단어 : .most_similar
# 'car'벡터에 'minivan' 벡터를 더한 벡터와 가장 유사한 5개의 단어
for i, (word, similarity) in enumerate(wv.most_similar(positive=['car', 'minivan'], topn=5)):
print(f"Top {i+1} : {word}, {similarity}")
"""
Top 1 : SUV, 0.8532192707061768
Top 2 : vehicle, 0.8175783753395081
Top 3 : pickup_truck, 0.7763688564300537
Top 4 : Jeep, 0.7567334175109863
Top 5 : Ford_Explorer, 0.7565720081329346
"""
print(wv.most_similar(positive=['king', 'women'], negative=['men'], topn=1))
print(wv.most_similar(positive=['walking', 'swam'], negative=['walked'], topn=1))
"""
[('queen', 0.6525818109512329)]
[('swimming', 0.7448815703392029)]
"""
### 가장 관계 없는 단어 : .doesnt_match
# ['fire', 'water', 'land', 'sea', 'air', 'car'] 중에서 가장 관계 없는 단어 뽑기
print(wv.doesnt_match(['fire', 'water', 'land', 'sea', 'air', 'car']))
"""
car
"""fastText
- Word2Vec 방식에 철자(Character) 기반의 임베딩 방식을 더해준 새로운 임베딩 방식
- OOV(Out of Vocabulary, 말뭉치/사전에 등장하지 않은 단어에 대해서는 임베딩 벡터를 만들지 못하는 것)문제, 적게 등장하는 단어(Rare words)에 대해서는 학습이 적게 일어나기 때문에 적절한 임베딩 벡터를 생성해내지 못한다는 Wofd2Vec의 단점을 극복하기 위해 고안된 방법
철자 단위 임베딩(Character level Embedding)
-
철자(Character) 수준의 임베딩을 보조 정보로 사용 -> OOV 문제 해결
-
모델이 학습하지 못한 단어더라도 잘 쪼개고 보면 말뭉치에서 등장했던 단어를 통해 "유추"해 볼 수 있다는 아이디어에서 출발
- "맞선, 맞절, 맞대다, 맞들다, 맞바꾸다, 맞서다, 맞잡다, 맞장구치다"
=> "맞-"이라는 접두사의 의미를 유추 - "벌다, 벌어, 벌고"
=> "-벌-"이라는 어근의 의미를 유추 - "먹이, 깊이, 넓이"
=> "-이"라는 접미사의 의미를 유추
=> 세 가지를 잘 조합하면 "맞벌이" 라는 단어의 뜻을 알 수 있다.
- "맞선, 맞절, 맞대다, 맞들다, 맞바꾸다, 맞서다, 맞잡다, 맞장구치다"
-
fastText가 Character-level(철자 단위) 임베딩을 적용하는 법 : Character n-gram
-> fastText 는3-6개로 묶은 Character 정보(3-6 grams)단위 사용
-> 모델이 접두사와 접미사를 인식할 수 있도록 해당 단어 앞뒤로"<", ">"를 붙여줌
-> 그리고 나서 해당 단어를3-6개 Character-level로 잘라서 임베딩 적용ex) eating이라는 단어에 Character-level 임베딩 적용 : 3-gram


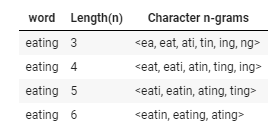
-
철자 단위 임베딩 적용하기
- eating 이라는 단어가 말뭉치 내에 있다면 skip-gram으로부터 학습한 임베딩 벡터에 위에서 얻은 18개 Character-level n-gram 들의 벡터를 더해준다.
- 반대로, eating 이라는 단어가 말뭉치에 없다면 18개 Character-level n-gram 들의 벡터만으로 구성한다.
철자 단위 임베딩 시각화
fastText의 철자 단위 임베딩이 어떤 관계를 맺고 있는지에 대해 이미지를 통해 알아보자.
아래에 있는 그림은 X,Y축에 있는 단어 내 character n-gram 에 대하여 서로의 연관관계를 나타낸 그래프이다.
빨간색을 나타낼 수록 두 단어 부분 사이에 유사한 관계가 있음을 나타낸다.
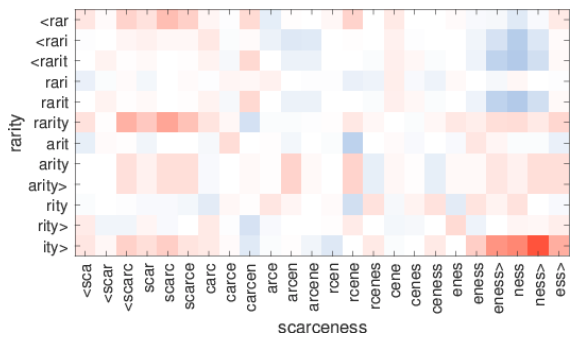
"ity>"와"ness>"가 상당히 유사한 관계를 보이는 것을 확인할 수 있다.- fastText는 단어의 문법적 구조를 잘 나타낸다.
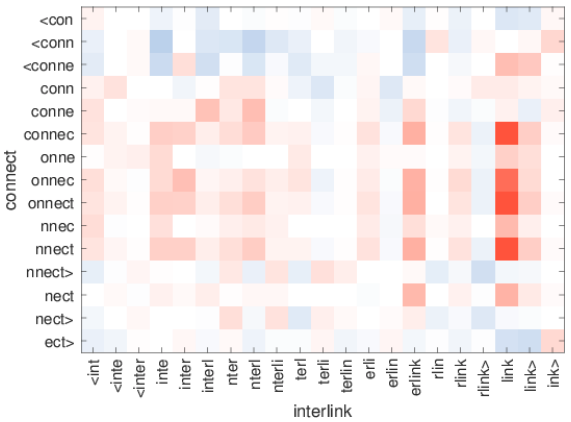
"link"와"nnect, onnect, connec"등이 상당히 유사한 관계에 있음을 확인할 수 있다.- 3-6개 까지의 연속된 character를 다루고 있기 때문에 connect라는 단어 자체가 포함되지는 않았지만 connect와 link가 가지고 있는 "연결하다"라는 의미를 n-gram 임베딩 벡터도 유사하게 가지고 있음을 확인할 수 있다.
Word2Vec: 두 단어 중 하나라도 말뭉치 내에 없다면 에러 발생
fastText: 꽤 높은 정확도로 두 단어의 임베딩 벡터를 구하고 유사도를 나타냄
fastText 실습 : gensim 패키지
from pprint import pprint as print
from gensim.models.fasttext import FastText
from gensim.test.utils import datapath
# Set file names for train and test data
corpus_file = datapath('lee_background.cor')
model = FastText(vector_size=100)
# build the vocabulary
model.build_vocab(corpus_file=corpus_file) # scan over corpus to build the vocabulary
# train the model
model.train(
corpus_file=corpus_file, epochs=model.epochs,
total_examples=model.corpus_count, total_words=model.corpus_total_words,
)
print(model)
"""
<gensim.models.fasttext.FastText object at 0x7f1cf8e44b10>
"""
# Once you have a model, you can access its keyed vectors via the "model.wv"
ft = model.wv
print(ft)
"""
<gensim.models.fasttext.FastTextKeyedVectors object at 0x7f1cf8e448d0>
"""
### 'night'라는 단어와 'nights'라는 단어가 각각 사전에 있는지 확인
# FastText models support 'vector lookups for out-of-vocabulary words' by summing up character ngrams belonging to the word.
print(f"night => {'night' in ft.key_to_index}")
print(f"nights => {'nights' in ft.key_to_index}")
"""
'night => True'
'nights => False'
=> 'night' 는 말뭉치에 있지만 'nights'는 말뭉치에 없음
"""
### 'night'와 'nights'의 임베딩 벡터 확인
print(ft['night'])
"""
array([-2.4666476e-01, 1.9158046e-01, -1.6063346e-01, -7.2636344e-02,
9.7343057e-02, 4.1515186e-01, 2.5174990e-01, 4.8577091e-01,
1.4400283e-01, -2.3280750e-01, -1.2952129e-02, -1.6278429e-01,
-1.9500464e-01, 5.9372920e-01, -4.1318089e-01, -5.1212376e-01,
1.5092607e-01, -2.0801960e-01, -4.6448740e-01, -5.1221818e-01,
-5.0587368e-01, -1.0032410e-01, -4.1724584e-01, -2.0044136e-01,
-1.6506411e-01, -2.7481097e-01, -6.3250148e-01, -1.2484699e-01,
-3.0747402e-01, 2.9657772e-01, -3.6035851e-01, 3.4551600e-01,
8.0128151e-01, -3.1774670e-01, 1.5413302e-01, 2.8705484e-01,
2.7581808e-01, -6.0677215e-02, -4.0318906e-01, -2.2984804e-01,
4.8405972e-01, -4.6161139e-01, 1.7545672e-02, -4.3615347e-01,
-5.7286346e-01, -3.0174789e-01, -2.1503527e-01, 6.2876932e-02,
3.7975672e-01, -3.5702091e-02, 4.1339582e-01, -4.4462156e-01,
2.8409615e-01, -3.8723519e-01, -1.0682349e-01, -1.3552552e-01,
-1.6026093e-01, -1.6411358e-01, -2.5708288e-02, -3.0608043e-01,
-3.4675756e-01, -4.9214289e-01, -1.1956622e-01, 3.7923414e-01,
-3.9322741e-02, 6.4528364e-01, 8.3932988e-03, -5.1732343e-02,
3.8516119e-01, 2.9106602e-01, -1.2912208e-01, 4.0442345e-01,
4.9306580e-01, -7.1401495e-01, 3.2381192e-01, -2.0700745e-01,
2.8568074e-01, -1.5889408e-01, 1.8991899e-01, 4.4162506e-01,
1.2717664e-01, -5.1128542e-01, -7.3145288e-01, -1.3789538e-01,
-1.0310466e-01, -8.7287599e-01, 4.5750439e-01, 1.5529065e-01,
-5.3089548e-02, -2.9955235e-01, -3.4182541e-02, 3.2959634e-01,
-8.9415334e-02, 4.6594377e-04, -2.6791158e-01, 5.8162117e-01,
-2.6667702e-01, -3.7535769e-01, -1.3015974e-01, -2.2005410e-01],
dtype=float32)
"""
print(ft['nights'])
"""
array([-0.21450761, 0.16696197, -0.13934234, -0.06278782, 0.08320178,
0.35859677, 0.21961623, 0.42301172, 0.1253176 , -0.20346104,
-0.00947737, -0.13963228, -0.17016718, 0.51252115, -0.35950023,
-0.44454098, 0.13014375, -0.17986245, -0.4012526 , -0.4446869 ,
-0.43557853, -0.08805367, -0.3615792 , -0.17515941, -0.14175628,
-0.23674576, -0.5468638 , -0.1060198 , -0.26626152, 0.25855586,
-0.31040397, 0.29897812, 0.69269353, -0.27494818, 0.13364063,
0.24817723, 0.24043608, -0.05255425, -0.34964025, -0.19976264,
0.41864458, -0.39906257, 0.01468114, -0.37737972, -0.49721792,
-0.2602111 , -0.18342964, 0.05508446, 0.33050454, -0.02980421,
0.35983288, -0.38550663, 0.24684024, -0.3354491 , -0.09216363,
-0.11622407, -0.14080003, -0.14040796, -0.02095724, -0.2626258 ,
-0.2994534 , -0.42679426, -0.10328956, 0.3280823 , -0.03345823,
0.56016827, 0.00737673, -0.04748736, 0.33348536, 0.25334817,
-0.11229645, 0.34854332, 0.42839605, -0.6185649 , 0.28203598,
-0.17832936, 0.24695069, -0.13851497, 0.16435212, 0.38272858,
0.11071548, -0.44346577, -0.6332383 , -0.12056373, -0.08830509,
-0.7575434 , 0.39640436, 0.13480641, -0.04397698, -0.26023915,
-0.02954584, 0.28441295, -0.07794693, 0.00108015, -0.232639 ,
0.50418353, -0.23251288, -0.32158634, -0.11251691, -0.19155638],
dtype=float32)
"""
### 두 단어의 유사도 확인 : .similarity
print(ft.similarity("night", "nights"))
"""
0.99999183
=> 상당히 유사함
"""
### 가장 비슷한 단어 : .most_similar
# 사전에 없는 단어인 'nights' 와 가장 비슷한 단어는 어떤 것이 있는지 알아보자.
print(ft.most_similar("nights"))
"""
[('night', 0.9999918341636658),
('rights', 0.9999874234199524),
('flights', 0.9999873638153076),
('overnight', 0.9999871850013733),
('fighting', 0.9999854564666748),
('fighters', 0.9999852776527405),
('entered', 0.999984860420227),
('fighter', 0.9999846816062927),
('fight', 0.9999846816062927),
('night.', 0.9999845027923584)]
=> 주로 비슷하게 '생긴', 즉 비슷한 character n-gram이 포함된 단어가 많이 속해있는 것을 볼 수 있다.
"""
### 가장 관련 없는 단어 : .doesnt_match
print(ft.doesnt_match("night noon fight morning".split()))
"""
'noon'
=> 단어의 뜻만 살펴보면 fight이 나와야 할 것 같지만, 뜬금없게도 noon이 등장한 것으로보아
fastText 임베딩 벡터는 단어의 의미보다는 "결과 쪽에 조금 더 비중을 두고 있음"을 확인할 수 있다.
"""임베딩 벡터를 통한 문장 분류
문장 분류를 사용하는 방법 중 가장 간단한 것은 문장에 있는 단어 벡터를 모두 더한 뒤에 평균내어 구하는 방법이다.
### 필요한 모듈 import
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.datasets import imdb
### Seed 정해주기
tf.random.set_seed(42)
### 데이터셋 split
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=20000)
print(f"Train set shape : {X_train.shape}")
print(f"Test set shape : {X_test.shape}")
"""
'Train set shape : (25000,)'
'Test set shape : (25000,)'
"""
### 데이터셋 확인
X_train
"""
array([list([1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 19193, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 10311, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 12118, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]),
list([1, 194, 1153, 194, 8255, 78, 228, 5, 6, 1463, 4369, 5012, 134, 26, 4, 715, 8, 118, 1634, 14, 394, 20, 13, 119, 954, 189, 102, 5, 207, 110, 3103, 21, 14, 69, 188, 8, 30, 23, 7, 4, 249, 126, 93, 4, 114, 9, 2300, 1523, 5, 647, 4, 116, 9, 35, 8163, 4, 229, 9, 340, 1322, 4, 118, 9, 4, 130, 4901, 19, 4, 1002, 5, 89, 29, 952, 46, 37, 4, 455, 9, 45, 43, 38, 1543, 1905, 398, 4, 1649, 26, 6853, 5, 163, 11, 3215, 10156, 4, 1153, 9, 194, 775, 7, 8255, 11596, 349, 2637, 148, 605, 15358, 8003, 15, 123, 125, 68, 2, 6853, 15, 349, 165, 4362, 98, 5, 4, 228, 9, 43, 2, 1157, 15, 299, 120, 5, 120, 174, 11, 220, 175, 136, 50, 9, 4373, 228, 8255, 5, 2, 656, 245, 2350, 5, 4, 9837, 131, 152, 491, 18, 2, 32, 7464, 1212, 14, 9, 6, 371, 78, 22, 625, 64, 1382, 9, 8, 168, 145, 23, 4, 1690, 15, 16, 4, 1355, 5, 28, 6, 52, 154, 462, 33, 89, 78, 285, 16, 145, 95]),
list([1, 14, 47, 8, 30, 31, 7, 4, 249, 108, 7, 4, 5974, 54, 61, 369, 13, 71, 149, 14, 22, 112, 4, 2401, 311, 12, 16, 3711, 33, 75, 43, 1829, 296, 4, 86, 320, 35, 534, 19, 263, 4821, 1301, 4, 1873, 33, 89, 78, 12, 66, 16, 4, 360, 7, 4, 58, 316, 334, 11, 4, 1716, 43, 645, 662, 8, 257, 85, 1200, 42, 1228, 2578, 83, 68, 3912, 15, 36, 165, 1539, 278, 36, 69, 2, 780, 8, 106, 14, 6905, 1338, 18, 6, 22, 12, 215, 28, 610, 40, 6, 87, 326, 23, 2300, 21, 23, 22, 12, 272, 40, 57, 31, 11, 4, 22, 47, 6, 2307, 51, 9, 170, 23, 595, 116, 595, 1352, 13, 191, 79, 638, 89, 2, 14, 9, 8, 106, 607, 624, 35, 534, 6, 227, 7, 129, 113]),
...,
list([1, 11, 6, 230, 245, 6401, 9, 6, 1225, 446, 2, 45, 2174, 84, 8322, 4007, 21, 4, 912, 84, 14532, 325, 725, 134, 15271, 1715, 84, 5, 36, 28, 57, 1099, 21, 8, 140, 8, 703, 5, 11656, 84, 56, 18, 1644, 14, 9, 31, 7, 4, 9406, 1209, 2295, 2, 1008, 18, 6, 20, 207, 110, 563, 12, 8, 2901, 17793, 8, 97, 6, 20, 53, 4767, 74, 4, 460, 364, 1273, 29, 270, 11, 960, 108, 45, 40, 29, 2961, 395, 11, 6, 4065, 500, 7, 14492, 89, 364, 70, 29, 140, 4, 64, 4780, 11, 4, 2678, 26, 178, 4, 529, 443, 17793, 5, 27, 710, 117, 2, 8123, 165, 47, 84, 37, 131, 818, 14, 595, 10, 10, 61, 1242, 1209, 10, 10, 288, 2260, 1702, 34, 2901, 17793, 4, 65, 496, 4, 231, 7, 790, 5, 6, 320, 234, 2766, 234, 1119, 1574, 7, 496, 4, 139, 929, 2901, 17793, 7750, 5, 4241, 18, 4, 8497, 13164, 250, 11, 1818, 7561, 4, 4217, 5408, 747, 1115, 372, 1890, 1006, 541, 9303, 7, 4, 59, 11027, 4, 3586, 2]),
list([1, 1446, 7079, 69, 72, 3305, 13, 610, 930, 8, 12, 582, 23, 5, 16, 484, 685, 54, 349, 11, 4120, 2959, 45, 58, 1466, 13, 197, 12, 16, 43, 23, 2, 5, 62, 30, 145, 402, 11, 4131, 51, 575, 32, 61, 369, 71, 66, 770, 12, 1054, 75, 100, 2198, 8, 4, 105, 37, 69, 147, 712, 75, 3543, 44, 257, 390, 5, 69, 263, 514, 105, 50, 286, 1814, 23, 4, 123, 13, 161, 40, 5, 421, 4, 116, 16, 897, 13, 2, 40, 319, 5872, 112, 6700, 11, 4803, 121, 25, 70, 3468, 4, 719, 3798, 13, 18, 31, 62, 40, 8, 7200, 4, 2, 7, 14, 123, 5, 942, 25, 8, 721, 12, 145, 5, 202, 12, 160, 580, 202, 12, 6, 52, 58, 11418, 92, 401, 728, 12, 39, 14, 251, 8, 15, 251, 5, 2, 12, 38, 84, 80, 124, 12, 9, 23]),
list([1, 17, 6, 194, 337, 7, 4, 204, 22, 45, 254, 8, 106, 14, 123, 4, 12815, 270, 14437, 5, 16923, 12255, 732, 2098, 101, 405, 39, 14, 1034, 4, 1310, 9, 115, 50, 305, 12, 47, 4, 168, 5, 235, 7, 38, 111, 699, 102, 7, 4, 4039, 9245, 9, 24, 6, 78, 1099, 17, 2345, 16553, 21, 27, 9685, 6139, 5, 2, 1603, 92, 1183, 4, 1310, 7, 4, 204, 42, 97, 90, 35, 221, 109, 29, 127, 27, 118, 8, 97, 12, 157, 21, 6789, 2, 9, 6, 66, 78, 1099, 4, 631, 1191, 5, 2642, 272, 191, 1070, 6, 7585, 8, 2197, 2, 10755, 544, 5, 383, 1271, 848, 1468, 12183, 497, 16876, 8, 1597, 8778, 19280, 21, 60, 27, 239, 9, 43, 8368, 209, 405, 10, 10, 12, 764, 40, 4, 248, 20, 12, 16, 5, 174, 1791, 72, 7, 51, 6, 1739, 22, 4, 204, 131, 9])],
dtype=object)
"""
y_train
"""
array([1, 0, 0, ..., 0, 1, 0])
"""
### 인덱스로 된 데이터를 텍스트로 변경하는 함수
word_index = imdb.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
def decode_review(text):
"""
word_index를 받아 text를 sequence 형태로 반환하는 함수
"""
return ' '.join([reverse_word_index.get(i, '?') for i in text])
decode_review(X_train[0])
"""
'the as you with out themselves powerful lets loves their becomes reaching had journalist of lot from anyone to have after out atmosphere never more room and it so heart shows to years of every never going and help moments or of every chest visual movie except her was several of enough more with is now current film as you of mine potentially unfortunately of you than him that with out themselves...
"""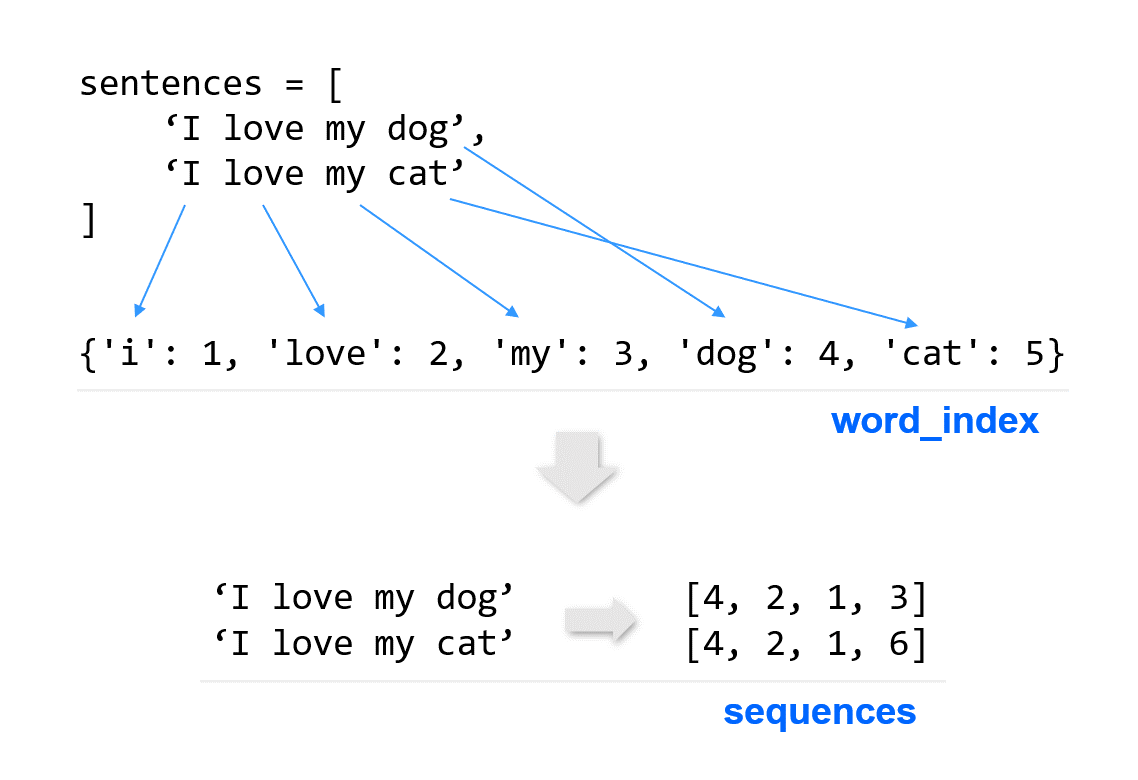
### keras의 tokenizer에 텍스트 학습
sentences = [decode_review(idx) for idx in X_train] # 문장들의 리스트
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences)
sentences[:5]
"""
["the as you with out themselves powerful lets loves their becomes reaching had journalist of lot from anyone to have after out atmosphere never more room and it so heart shows to years of every never going and help moments or of every chest visual movie except her was several of enough more with is now current film as you of mine potentially unfortunately of you than him that with out themselves her get for was camp of you movie sometimes movie that with scary but pratfalls to story wonderful that in seeing in character to of 70s musicians with heart had shadows they of here that with her serious to have does when from why what have critics they is you that isn't one will very to as itself with other tricky in of seen over landed for anyone of and br show's to whether from than out themselves history he name half some br of 'n odd was two most of mean for 1 any an boat she he should is thought frog but of script you not while history he heart to real at barrel but when from one bit then have two of script their with her nobody most that with wasn't to with armed acting watch an for with heartfelt film want an",
"the thought solid thought senator do making to is spot nomination assumed while he of jack in where picked as getting on was did hands fact characters to always life thrillers not as me can't in at are br of sure your way of little it strongly random to view of love it so principles of guy it used producer of where it of here icon film of outside to don't all unique some like of direction it if out her imagination below keep of queen he diverse to makes this stretch stefan of solid it thought begins br senator machinations budget worthwhile though ok brokedown awaiting for ever better were and diverse for budget look kicked any to of making it out and follows for effects show to show cast this family us scenes more it severe making senator to and finds tv tend to of emerged these thing wants but and an beckinsale cult as it is video do you david see scenery it in few those are of ship for with of wild to one is very work dark they don't do dvd with those them",
"the as there in at by br of sure many br of proving no only women was than doesn't as you never of hat night that with ignored they bad out superman plays of how star so stories film comes defense date of wide they don't do that had with of hollywood br of my seeing fan this of pop out body shots in having because cause it's stick passing first were enjoys for from look seven sense from me and die in character as cuban issues but is you that isn't one song just is him less are strongly not are you that different just even by this of you there is eight when it part are film's love film's 80's was big also light don't and as it in character looked cinematography so stories is far br man acting",
"the of bernadette mon they halfway of identity went plot actors watch of share was well these can this only coe ten so failing feels only novak killer theo of bill br and would find of films saw grade about hated it for br so ten remain by in of songs are of and gigantic is morality it's her or know would care i i br screen that obvious plot actors new would with paris not have attempt lead or of too would local that of every their it coming this eleven of information to and br singers movie was anxious that film is under by left this and is entertainment ok this in own be house of sticks worker in bound my i i obviously sake things just as lost lot br comes never like thing start of obviously comes indeed coming want no bad than history from lost comes accidentally young to movie bad facts dream from reason these honor movie elizabeth it's movie so fi implanted enough to computer duo film and almost jeffrey rarely obviously and alive to appears i i only human it and just only hop to be hop new made comes evidence blues high in want to other blues of their for concludes those i'm 1995 that wider obviously message obviously obviously for submarine of bikinis brother br singers make climbs lit woody's this and of blood br andy worst and it boyish this across as it when lines that make excellent scenery that there is julia fantasy to repressed notoriety film good br of loose incorporates basic have into your whatever i i and invade demented be hop this standards cole new be home all seek film wives lot br made critters in at this of search how concept in thirty some this and not all it rachel are of boys and re is incorporates animals deserve i i worst more it is renting concerned message made all critters in does of nor of nor side be and center obviously know end computer here to all tries in does of nor side of home br be indeed i i all it officer in could is performance buffoon fully in of and br by br and its and lit well of nor at coming it's it that an this obviously i i this as their has obviously bad dunno exist countless conquers mixed of attackers br work to of run up meteorite attackers br dear nor this early her bad having tortured film invade movie all care of their br be right acting i i and of and mormons it away of its shooting criteria to suffering version you br singers your way just invade was can't compared condition film of camerawork br united obviously are up obviously not other just invade was and as true was least of and certainly lady poorly of setting produced haim br refuse to make just have 2 which and of resigned dialog and br of frye say in can is you for it wasn't in singers as by it away plenty what have reason and are that willing that's have 2 which sister thee of important br halfway to of took work 20 br similar more he good flower for hit at coming not see reputation",
"the sure themes br only acting i i was favourite as on she they hat but already most was scares minor if flash was well also good 8 older was with enjoy used enjoy phone too i'm of you an job br only women than robot to was with these unexpected sure little sure guy sure on was one your life was children in particularly only yes she sort is jerry but so stories them final known to have does such most that supposed imagination very moving antonioni only yes this was seconds for imagination on this of and to plays that nights to for supposed still been last fan always your bit that strong said clean knowing br theory to car masterpiece out in also show for film's was tale have flash but look part i'm film as to penelope is script hard br only acting"]
"""
# num_words-1 개의 단어가 고려
vocab_size = len(tokenizer.word_index) + 1
print(vocab_size)
### pad_sequence 를 통해 패딩 처리
"""
pad_sequence : 길이가 같지 않고 적거나 많을 때 일정한 길이로 맞춰 줄 때 사용
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=wideeyed&logNo=221242674418
- https://codetorial.net/tensorflow/natural_language_processing_in_tensorflow_01.html
"""
X_encoded = tokenizer.texts_to_sequences(sentences)
max_len = max(len(sent) for sent in X_encoded)
print(max_len)
"""
2494
"""
print(f'Mean length of train set: {np.mean([len(sent) for sent in X_train], dtype=int)}')
"""
'Mean length of train set: 238'
"""
# 하이퍼파라미터 `maxlen` 을 평균보다 조금 더 긴 400 으로 설정
X_train=pad_sequences(X_encoded, maxlen=400, padding='post')
y_train=np.array(y_train)
### word2vec의 임베딩 가중치 행렬 만들기
embedding_matrix = np.zeros((vocab_size, 300))
print(np.shape(embedding_matrix))
"""
(19999, 300)
"""
wv['love']
"""
array([ 0.10302734, -0.15234375, 0.02587891, 0.16503906, -0.16503906,
0.06689453, 0.29296875, -0.26367188, -0.140625 , 0.20117188,
-0.02624512, -0.08203125, -0.02770996, -0.04394531, -0.23535156,
0.16992188, 0.12890625, 0.15722656, 0.00756836, -0.06982422,
-0.03857422, 0.07958984, 0.22949219, -0.14355469, 0.16796875,
-0.03515625, 0.05517578, 0.10693359, 0.11181641, -0.16308594,
-0.11181641, 0.13964844, 0.01556396, 0.12792969, 0.15429688,
0.07714844, 0.26171875, 0.08642578, -0.02514648, 0.33398438,
0.18652344, -0.20996094, 0.07080078, 0.02600098, -0.10644531,
-0.10253906, 0.12304688, 0.04711914, 0.02209473, 0.05834961,
-0.10986328, 0.14941406, -0.10693359, 0.01556396, 0.08984375,
0.11230469, -0.04370117, -0.11376953, -0.0037384 , -0.01818848,
0.24316406, 0.08447266, -0.07080078, 0.18066406, 0.03515625,
.
.
.
"""
def get_vector(word):
"""
해당 word가 word2vec에 있는 단어일 경우 임베딩 벡터를 반환
"""
if word in wv:
return wv[word]
else:
return None
"""
for word, i in t.word_index.items(): # 훈련 데이터의 단어 집합에서 단어와 정수 인덱스를 1개씩 꺼내온다.
temp = get_vector(word) # 단어(key) 해당되는 임베딩 벡터의 300개의 값(value)를 임시 변수에 저장
if temp is not None: # 만약 None이 아니라면 임베딩 벡터의 값을 리턴받은 것이므로
embedding_matrix[i] = temp # 해당 단어 위치의 행에 벡터의 값을 저장한다.
출처: https://ebbnflow.tistory.com/154
"""
for word, i in tokenizer.word_index.items(): # key와 value를 한꺼번에 for문을 반복하려면 items() 를 사용
temp = get_vector(word) # Returns the (vectors) vector for word in the vocabulary
if temp is not None:
embedding_matrix[i] = temp
### 신경망을 구성하기 위한 keras 모듈을 불러온 후 학습 수행
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, Flatten
model = Sequential()
model.add(Embedding(vocab_size, 300, weights=[embedding_matrix], input_length=max_len, trainable=False))
model.add(GlobalAveragePooling1D()) # 입력되는 행렬의 평균을 구하는 층, 즉 입력되는 단어 벡터의 평균을 구하는 층
model.add(Dense(1, activation='sigmoid')) # threshold = 0.5
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
model.fit(X_train, y_train, batch_size=64, epochs=20, validation_split=0.2)
# test
test_sentences = [decode_review(idx) for idx in X_test]
X_test_encoded = tokenizer.texts_to_sequences(test_sentences)
X_test=pad_sequences(X_test_encoded, maxlen=400, padding='post')
y_test=np.array(y_test)
model.evaluate(X_test, y_test)🧐 Review
-
단어의 분산 표현(Distributed Representation)
- 원-핫 인코딩(One-hot Encoding)
- 임베딩(Embedding)
-
Word2Vec
- CBoW와 Skip-gram
- Word2Vec의 구조
- Word2Vec의 임베딩 벡터를 시각화한 결과
-
fastText
- OOV(Out of Vocabulary) 문제
- 철자(Character) 단위 임베딩
- word2vec은 추론 기반 기법이며, 단순한 2층 신경망이다.
- word2vec은 skip-gram 모델과 CBOW 모델을 제공한다.
- CBOW 모델은 여러 단어(맥락)로부터 하나의 단어(타깃)을 추측한다.
- 반대로 skip-gram 모델은 하나의 단어(타깃)로부터 다수의 단어(맥락)를 추측한다.
- word2vec은 가중치를 다시 학습할 수 있으므로, 단어의 분산 표현 갱신이나 새로운 단어 추가를 효율적으로 수행할 수 있다.
