학습 목표
- 머신러닝모델을 만들 때 학습과 테스트 데이터를 분리 해야 하는 이유를 설명할 수 있습니다.
- 다중선형회귀를 이해하고 사용할 수 있습니다.
- 과적합/과소적합을 일반화 관점에서 설명할 수 있습니다.
- 편향/분산의 트레이드오프 개념을 이해하고 일반화 관점에서 설명할 수 있습니다.
성과 측정 : 학습과 테스트 데이터의 분리
데이터를 통해 머신러닝 모델을 만들고 새로운 예측을 하기 전 가장 먼저 확인해야 할 것은 바로 "이 모델이 정말 잘 작동하는가? "입니다. 즉, 우리가 만든 모델의 예측을 신뢰할 수 있는지에 대한 검증이 필요합니다. 다음은 모델 테스트 전 그 검증이 필요한 이유입니다.
- 레이블을 알고 있는 모델(by 학습데이터)에게 새 데이터를 적용하여 모델의 예측 성능을 제대로 평가하기 위해
- 훈련된 데이터(train)를 잘 맞추는 모델이 아닌, 한 번도 접해보지 못한 데이터(test)를 얼마나 잘 맞추는지 보기 위해(새로운 데이터에서 잘 작동하는지 아닌지)
- 모델의 일반화를 위해
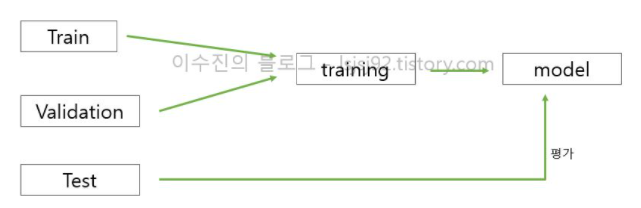
train & validation
- 훈련용 데이터
- train : 모델이 잘 학습 되는지, 안되는지 'training' 과정에서 확인
- validation : 중간 검증/평가 (ex. 모의고사)
- X_train, y_train
test
- 성능평가용 데이터
- 모델이 '한 번도 보지 못한 데이터'에 대해 평가
- '최종적으로 단 1번만' 사용하는 data
- X_test, y_test
1. sample()
train = df.sample(frac=0.75,random_state=1)
test = df.drop(train.index)
2. train_test_split()
# 훈련데이터 세트 세팅
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X = cancer.data # X - 함수의 입력(x) & 2차원 배열(행렬)
y = cancer.target # y - 함수의 출력(y) & 1차원 배열(벡터)
# 훈련데이터 세트 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.2, train_size=0.8, random_state=42)*train_test_split
: 데이터셋을 섞어서 나눠주는 scikit-learn 함수. 전체 행 중 75%를 훈련 세트로, 나머지 25%를 테스트 세트로 뽑습니다.(레이블 데이터 포함)
*stratify
:random sampling과는 다른 샘플링 방식으로 훈련데이터를 나눌 때 무작위로 샘플링을 하되, original dataset의 클래스 비율이 train, test set에서도 동일하게 유지되는 것을 보장합니다. original dataset에서 특정 클래스 비율이 불균형한 경우 stratify 매개변수에 타깃 데이터(y)를 지정하여 호출하면 (어떠한 통계적 기법을 통해서) 이 비율이 유지될 수 있도록 샘플링합니다.
*test/train_size
: 테스트/훈련 세트의 비율 전달
*np.random.seed()
: 만약 데이터 포인트가 레이블 순서대로 정렬되어있다면 train_test_split 함수로 데이터를 나누기 전 유사 난수 생성기를 통해 데이터셋을 무작위로 섞어야 데이터셋 뒤쪽의 동일한 25% 레이블을 뽑는 상황이 생기지 않습니다.
np.random.seed()는 정확히 무엇을 의미하는가?
*random_state
: train_test_split()는 데이터를 무작위로 섞은 뒤, 데이터 셋을 나누어 함수를 호출할 때마다 다른 결과로 분할이 되는데, random_state를 특정 숫자로 지정하면 항상 동일하게 분할할 수 있습니다. np.random.seed에 넣을 난수 초깃값을 이 매개변수로 전달하게 되면 코드는 항상 같은 결과를 출력하게 됩니다. 실제 상황에서는 거의 필요 없지만, 다른 사람들과 결과를 공유해야하거나 실험결과를 똑같이 재현해야 할 때는 유용하게 쓰입니다.
시계열 데이터 분리
# to_datetime을 통해 시간과 날짜를 다루기 쉬운 datetime64 형태로 변환
df['date'] = pd.to_datetime(df['date'])
# 2015-03-01을 기준으로 훈련/테스트 세트를 분리합니다.
cutOff = pd.to_datetime('2015-03-01')
#cutOff = datetime(2015, 3, 1, 0, 0, 0)
train = df[df['date'] < cutOff]
test = df[df['date'] >= cutOff]다중선형회귀모델(Multiple linear regression)
기준 모델 생성
# 타겟인 SalePrice 평균
train['SalePrice'].mean()
# label 정의
target = 'SalePrice'
y_train = train[target]
y_test = test[target]
# SalePrice 평균값으로 예측(기준모델)
predict = y_train.mean()
# 기준모델로 훈련 에러(MAE) 계산
from sklearn.metrics import mean_absolute_error
y_pred = [predict] * len(y_train)
# y_train개수만큼의 predict값으로 이루어진 리스트 생성
mae = mean_absolute_error(y_train, y_pred)
print(f'훈련 에러: {mae:.2f}')
# 테스트 에러(MAE)
y_pred = [predict] * len(y_test)
mae = mean_absolute_error(y_test, y_pred)
print(f'테스트 에러: {mae:.2f}')특성(2개 이상) 시각화
matplotlib
import matplotlib.pyplot as plt
import numpy as np
from matplotlib import style
# 테마 설정
style.use('seaborn-talk')
# figure 생성
fig = plt.figure()
# for 3d plot
ax = fig.gca(projection='3d')
# 그래프 세부 설정 (데이터, 라벨 이름, 제목)
ax.scatter(train['GrLivArea'], train['OverallQual'], train['SalePrice'])
ax.set_xlabel('GrLivArea', labelpad=12) #labelpad : 라벨 이름과 그래프 간 여백 지정
ax.set_ylabel('OverallQual', labelpad=10)
ax.set_zlabel('SalePrice', labelpad=20)
plt.suptitle('Housing Prices', fontsize=15)
plt.show()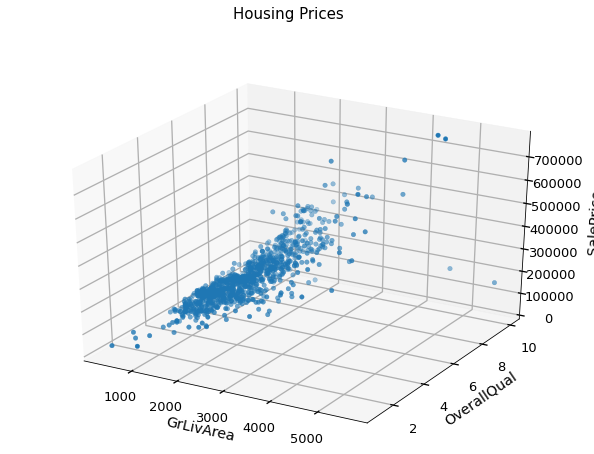
pyplot
pip install plotly --upgrade
import plotly.express as px
px.scatter_3d(
train,
x='bathrooms',
y='sqft_living',
z='price',
title='House Prices'
)
다중선형회귀 모델링
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
model = LinearRegression()
target = 'price'
features = ['bathrooms', 'sqft_living']
X_train = train[features]
y_train = train[target]
X_test = test[features]
y_test = test[target]
# 모델 학습 & 예측 성능 검증
model.fit(X_train, y_train)
y_pred = model.predict(X_train)
mae = mean_absolute_error(y_train, y_pred)
print(f'훈련 에러(MAE) : {mae:.2f}')
# 테스트 & 모델 성능 평가
y_pred2 = model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred2)
print(f'테스트 에러(MAE): {mae:.2f}')다중선형회귀 그래프_평면의 방정식
import numpy as np
import plotly.express as px
import plotly.graph_objs as go
import itertools
def surface_3d(df, f1, f2, target, length=20, **kwargs):
"""
2특성 1타겟 선형모델평면을 시각화 합니다.
df : 데이터프레임
f1 : 특성 1 열 이름
f2 : 특성 2 열 이름
target : 타겟 열 이름
length : 각 특성의 관측치 갯수
"""
# scatter plot(https://plotly.com/python-api-reference/generated/plotly.express.scatter_3d)
plot = px.scatter_3d(df, x=f1, y=f2, z=target, opacity=0.5, **kwargs)
# 다중선형회귀방정식 학습
model = LinearRegression()
model.fit(df[[f1, f2]], df[target])
# 좌표축 설정
x_axis = np.linspace(df[f1].min(), df[f1].max(), length)
y_axis = np.linspace(df[f2].min(), df[f2].max(), length)
coords = list(itertools.product(x_axis, y_axis))
# 예측
pred = model.predict(coords)
z_axis = pred.reshape(length, length).T
# plot 예측평면
plot.add_trace(go.Surface(x=x_axis, y=y_axis, z=z_axis, colorscale='Viridis'))
return plot
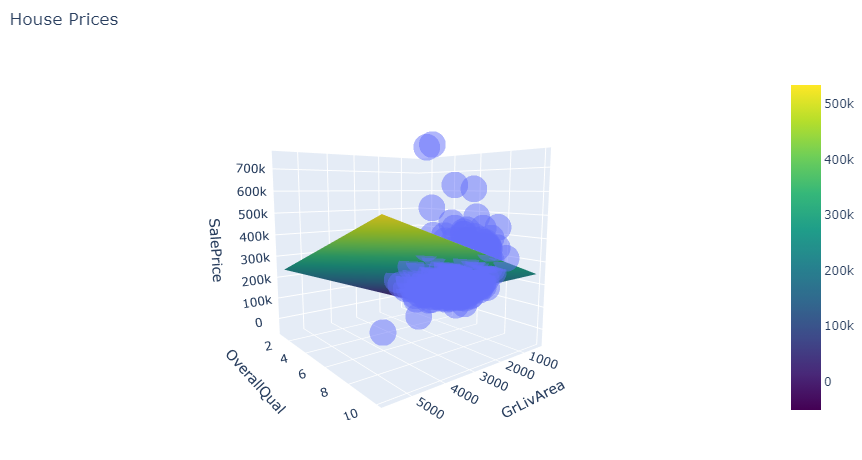
surface_3d(
train,
f1='GrLivArea',
f2='OverallQual',
target='SalePrice',
title='House Prices'
)
회귀계수 해석 및 모델 평가
절편과 계수
## 절편(intercept)과 계수들(coefficients)
model.intercept_, model.coef_
>>> (-102743.02342270731, array([ 54.40145532, 33059.44199506]))회귀식
b0 = model.intercept_
b1, b2 = model.coef_
print(f'y = {b0:.0f} + {b1:.0f}x\u2081 + {b2:.0f}x\u2082')
>>> y = -102743 + 54x₁ + 33059x₂=> 과 모두 양수이므로 , 이 증가할 때마다 도 증가한다는 뜻입니다.
회귀모델 평가지표들(evaluation metrics)
평가 지표 한눈에 보기
- MSE (Mean Squared Error) =
- MAE (Mean absolute error) =
- RMSE (Root Mean Squared Error) =
- R-squared (Coefficient of determination) =
- 참고
- SSE(Sum of SquaresError, 관측치와 예측치 차이):
- SSR(Sum of Squares due toRegression, 예측치와 평균 차이):
- SST(Sum of SquaresTotal, 관측치와 평균 차이): , SSE + SSR⇒ 실제 관측값
⇒ 평균
⇒ 예측값, 추정치
⇒ 관측값과 mean과의 거리(평균으로부터 얼마나 떨어져있는가)
⇒ 실 관측값 - 회귀식에 의한 예측값
⇒ 회귀선과 추정치의 거리
⇒ 회귀식에 의한 예측 값 - 실 관측값의 평균
MSE (Mean Squared Error, 평균 제곱 오차)
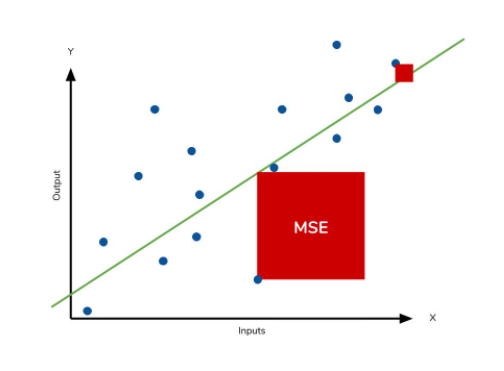
- 제곱 -> 잔차(예측값&실제값 차이)의 면적 합 나타내고, 단위 스케일 변화로 특이값(outliers)에 민감함
- (실제 관측값)이 퍼져있는지 아닌지
- 정답에 대한 오류를 숫자로 나타낸 것 -> 값이 작을수록 정답에 가까움
- 어느 정도 오류인지 파악이 힘듬
1.
def MSE(y_true, y_pred):
return np.mean(np.square((y_true - y_pred)))
MSE(y_true, y_pred)
2.
from sklearn.metrics import mean_squared_error
mean_squared_error(y_true, y_pred)MAE (Mean absolute error, 평균 절대 오차)
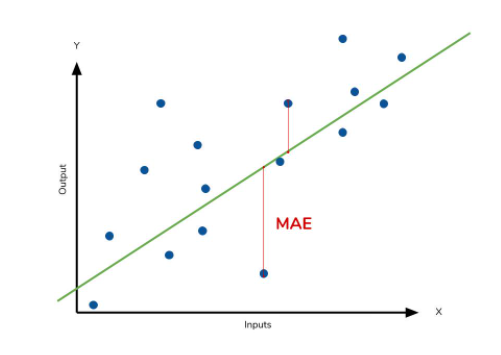
- 절대값을 취해 단위 유닛이 동일하여(스케일 변화X)가장 직관적으로 오류의 양을 확인할 수 있고 해석이 용이함
- MSE 보다 특이값(outlers)에 robust하다
- 절대값을 취하므로 모델이 underperformance 인지 overperformance 인지 알 수 없음
- underperformance: 모델이 실제보다 낮은 값으로 예측
- overperformance: 모델이 실제보다 높은 값으로 예측
1.
import numpy as np
def MAE(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred)))
MAE(y_true, y_pred)
2.
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_true, y_pred)해석 : target의 범위 중 MAE가 어느 부분에 속하는지 볼것
RMSE (Root Mean Squared Error)
실제값과 유사한 단위로 변화→ 스케일 변화의 문제점 커버(MSE 단점 개선)→ 해석 용이
import numpy as np
from sklearn.metrics import mean_absolute_error
np.sqrt(mean_absolute_error(y_true, y_pred))
R-squared (Coefficient of determination)
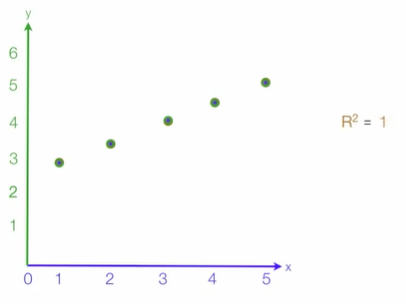
- 설명력, 결정 계수 => 회귀 모형의 적합성 판단
- 회귀모델의 설명력(0~1) : 1에 가까워질수록 추정한 회귀 모형이 아주 적합(추정한 회귀 모형이 실제 데이터와 일치)하며 모델의 데이터에 대한 설명력이 높음(Error값→0)
- 전체 제곱합 중 회귀(예측값) 제곱합이 차지하는 비율
from sklearn.metrics import r2_score
r2_score(y_test, y_test_pred)참고

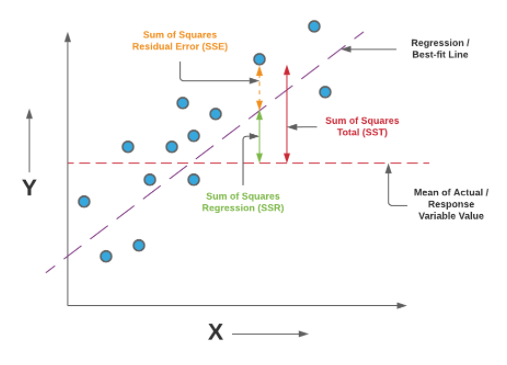
SSE(Sum of Squares 'Error')
- 관측치와 예측치 차이
SSR(Sum of Squares due to 'Regression')
- 예측치와 평균 차이
SST(Sum of Squares 'Total')
- 관측치와 평균 차이
- SSE + SSR
📌과적합(Overfitting)과 과소적합(Underfitting)
일반화(generalization)
모델이 처음 보는 데이터에 대해 정확하게 예측할 수 있으면 이를 훈련 세트에서 테스트 세트로 일반화(generalization)되었다고 한다.
- 일반화 오차 = 테스트데이터에서 만들어내는 오차
- 일반화가 잘 된 모델 = 훈련데이터에서와같이 테스트데이터에서도 좋은 성능을 내는 모델
- 일반화 방법 = 모델이 너무 훈련데이터에 과하게 학습(과적합)을 하지 않도록 하는 방법
우리는 당연히 예측모델이 훈련데이터에서보다 테스트데이터에서 오차가 적게 나오기를 기대하지만 현실적으로 모든 데이터를 얻을 수 없기 때문에 훈련데이터로부터 일반화가 잘 되는 모델을 학습시켜야 합니다.
과적합(Overfitting)
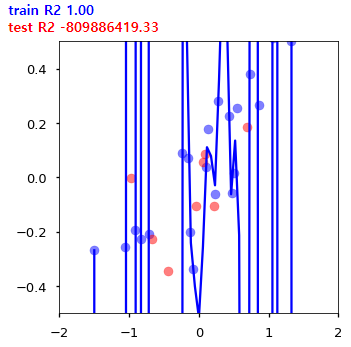
학습 데이터에서 필요 이상으로 특징을 발견해서(분산⬆) 학습 데이터에 대한 정확도는 상당히 높지만 테스트 데이터 또는 실제 데이터에 대해서는 낮은 정확도를 보일 경우
*사실 머신러닝과정 중에서 과적합은 피할 수 없는 문제이고 완전히 극복할 수도 없다. 그래서 대부분 학습알고리즘은 이런 과적합을 완화시킬 수 있는 방법을 제공하기 때문에 잘 알아 두어야 한다.
과소적합(Underfitting)
충분하지 못한 특징만으로 학습되어 특정 특징에만 편향되게 학습된 것으로 보통 테스트 데이터뿐만 아니라 학습 데이터에 대해서도 정확도가 낮게 나올 경우 과소적합된 모델일 가능성이 높습니다.
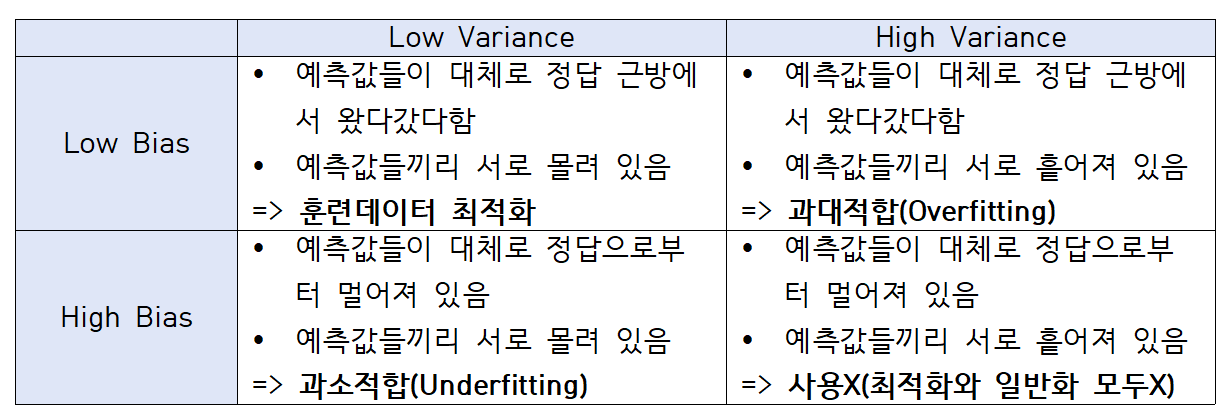
📌편향/분산 트레이드오프
지도학습(Supervised Learning)에서는 사람이 정해준 정답이 있고, 컴퓨터가 그 정답을 잘 맞추는 방향으로 훈련(training)을 시킨다. 정답 하나를 맞추기 위해 컴퓨터는 여러 번의 예측값(predict) 내놓기를 시도하는데, 여기서 컴퓨터가 내놓은 예측값의 동태를 묘사하는 표현이 '편향' 과 '분산' 이다.
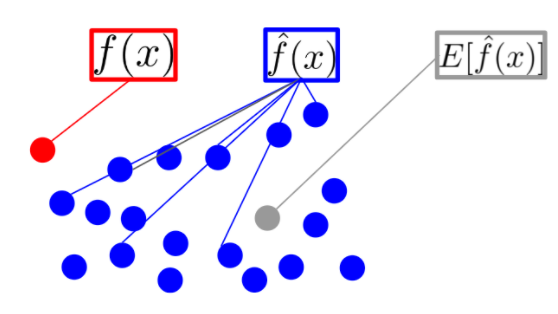
- = 데이터(점 하나하나)
- = 실제값(x에 상관없이 단일한 정답)
- = 컴퓨터가 내놓은 예측값(predicted value)
- = 예측값 평균
편향 (bias)
 예측값이 실제값(정답)과 얼마나 다른가(차이가 있는가, 떨어져 있는가, 멀게 있는가 등등)
예측값이 실제값(정답)과 얼마나 다른가(차이가 있는가, 떨어져 있는가, 멀게 있는가 등등)
분산(Variance)

- 예측값들이 자기들끼리 서로 얼마나 흩어져 있는가
- '예측값'(위 그림에서 파란 점들)과, '예측값들의 평균(위 그림에서 회색 점)'의 차이를 평균내어 제곱
⇒ 즉, 두 가지를 통해 "전체적인 경향" 표현
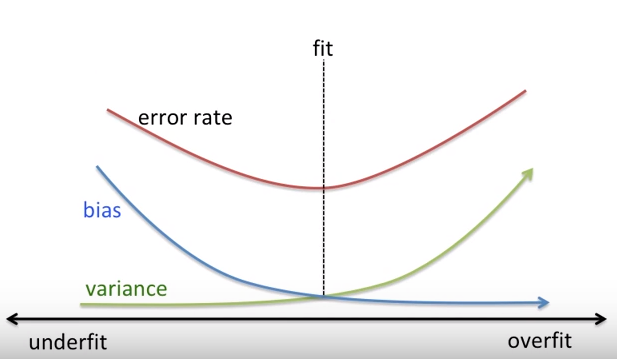
편향, 분산 tradeoff
MSE 식을 reducible, irreducible 에러로 나누어 표현하면
결국 Bias 에러 + Variance + irre 로 나뉘게 됩니다.
*Bias–variance tradeoff
(=어떤 짓을 해도 줄일 수 없는 근본적인 오차 )
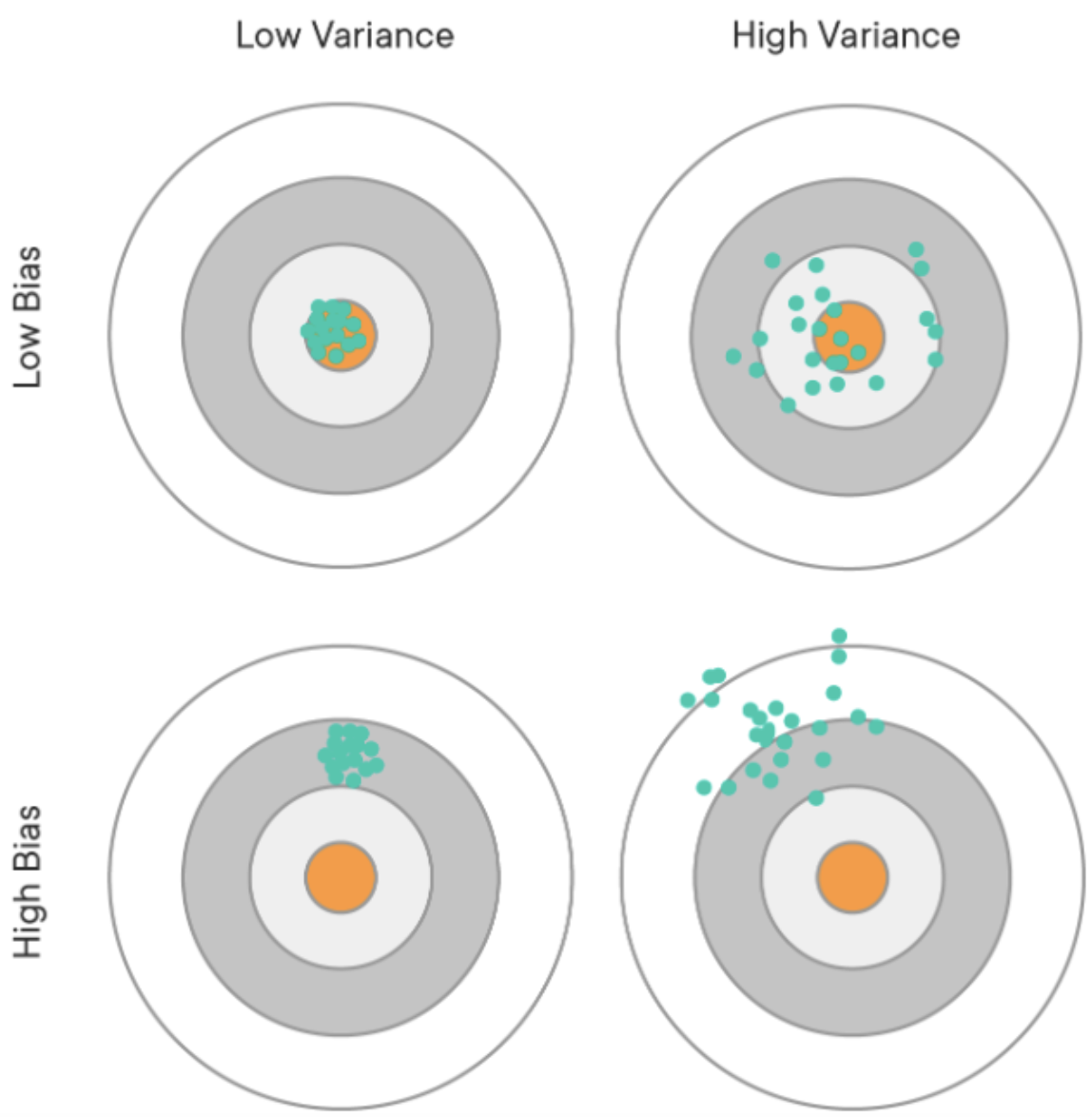
분산(variance)⬆ = 과적합
- 수학적으로 데이터에서 특징을 필요 이상으로 추출할 경우
- 예측값들이 멀리 흩어져있는 경우
- 모델이 학습 데이터의 노이즈에 민감하게 적합하여 테스트데이터에서 일반화를 잘 못하는 경우
- 분산↓ = 훈련/테스트 두 데이터에서 그 오차가 비슷하다(오차는 여전히 많지만)
편향(bias)⬆ = 과소적합
- 수학적으로 데이터에서 특징을 필요 이하로 추출할 경우
- 예측값들과 정답이 대체로 멀리 떨어져 있는 경우
- 모델이 학습 데이터에서, 특성과 타겟 변수의 관계를 잘 파악하지 못하는 경우
- 학습데이터에서 타겟값과 오차가 크다
=> 최적의 모델(에러율이 가장 적은 모델) = 분산과 편향이 균형된 모델
학습 데이터

훈련 데이터

회귀

분류
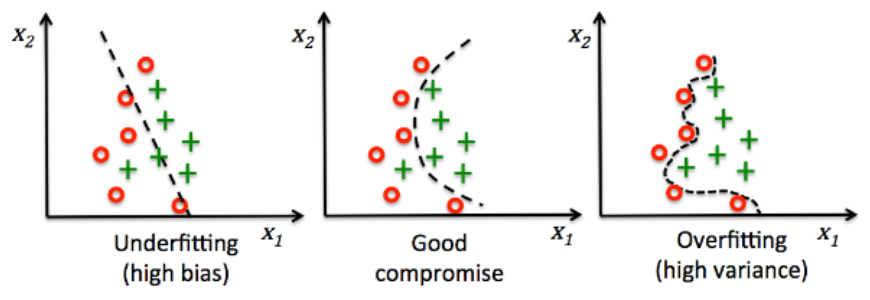
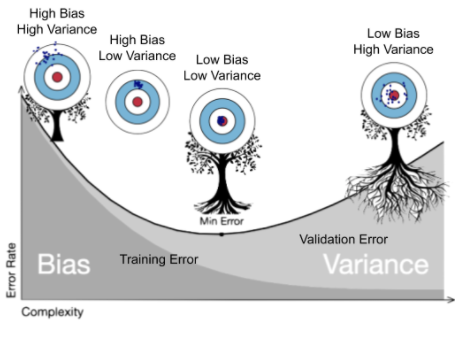
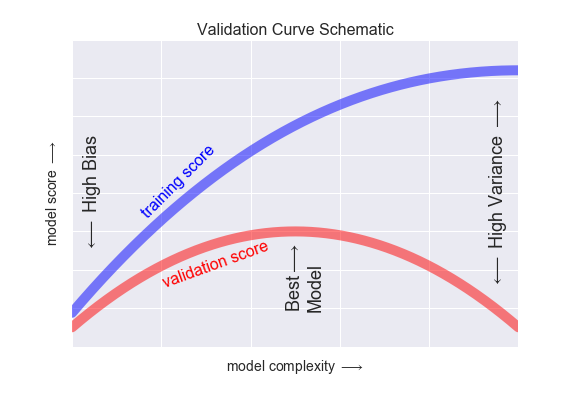
모델의 데이터 반복 학습 횟수↑ 모델의 복잡한 정도(Model Complexity)
⇒ 훈련용 데이터를 그대로 외우는 방향
⇒ Training Error는 갈수록 줄어들게 되지만 Validation Error는 어느 정도까지는 줄어들다가, 어느 지점 이후부터는 다시 상승
⇒ 모델을 훈련시키는 도중 Validation Error가 최소인 지점(Validation score가 최대)에서 훈련을 멈추는 것이 필요
[reference]
회귀의 오류 지표 알아보기
Bias and Variance (편향과 분산)
단순선형회귀, 다중선형회귀
10. Feature를 선택하는 방법과 다항식 모델(Polynomial regression) 인 경우
