1. 언어모델
단어 쉬퀀스에서 각 단어의 확률을 계산하는 모델
CboW가 타겟단어를 예측할 확률 P(w)
앞 단어들이 등장 했을 때 특정 단어가 등장할 확률을 조건부 확률로 구한다
통계적 언어모델(Statistical Language Model, SLM)
- 통계적 언어 모델의 확률 계산
# example
I am a student
전체 말뭉치의 문장이 1000개고 그중 “I”로 시작하는게 100개라면
P(“I”) = 100/1000
"I" 로 시작하는 100개의 문장 중 바로 다음에 "am" 이 등장하는 문장이 50개라면
P(“am”|”I”) = 50 / 100- 단점 : 말뭉치에 없는 단어가 등장하면 확률이 0이 되어 버린다 = 희소문제
신경망 언어모델(Neural Langauge Model)
- 신경망 언어 모델에서는 횟수 기반 대신 Word2Vec이나 fastText 등의 출력값인 임베딩 벡터를 사용
- 그렇기 때문에 말뭉치에 등장하지 않더라도 의미적, 문법적으로 유사한 단어라면 선택될 수 있다
2. 순환 신경망 (RNN, Recurrent Neural Network)
RNN은 연속형 데이터를 처리하기 위해 고안된 신경망 구조
※ 연속형데이터(Sequential Data)란? : 어떤 순서로 오느냐에 따라서 단위의 의미가 달라지는 데이터
RNN의 구조
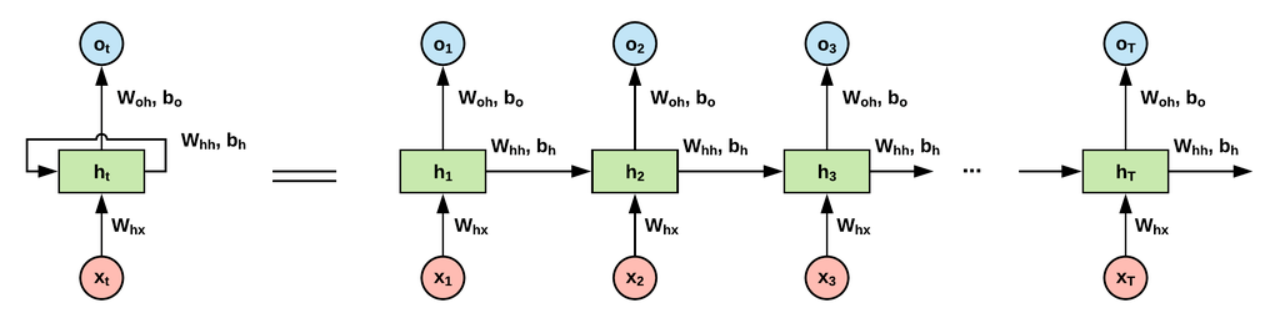
① 입력 벡터가 은닉층에 들어가는 것을 나타내는 화살표
② 은닉층로부터 출력 벡터가 생성되는 것을 나타내는 화살표
③ 은닉층에서 나와 다시 은닉층으로 입력되는 것을 나타내는 화살표
※ time-step
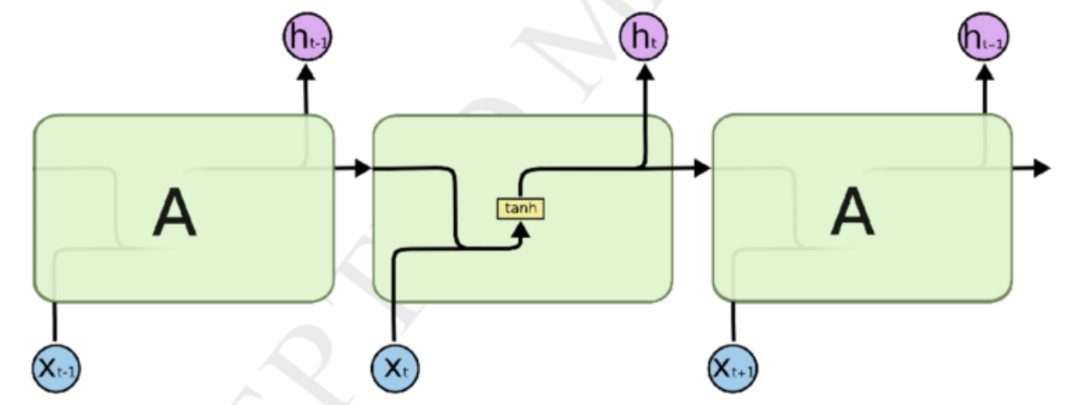
① t-1 시점에서는 와 가 입력되고 가 출력
② t 시점에서는 와 가 입력되고 가 출력
③ t+1시점에서는 과 가 입력되고 이 출력
t 시점의 RNN계층은 그 계층으로의 입력벡터 와 1개전의 RNN계층의 출력 벡터 를 받아들인다
입력된 두 벡터를 바탕으로 해당시점에서의 출력
=
다양한 형태의 RNN
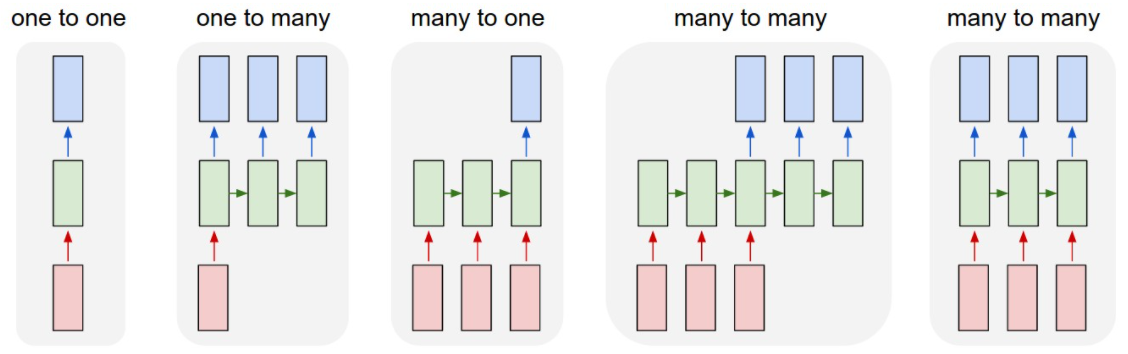
① one-to-many : 1개의 벡터를 받아 Sequential한 벡터를 반환
이미지를 입력받아 이를 설명하는 문장을 만들어내는 이미지 캡셔닝(Image captioning)에 사용
② many-to-one : Sequential 벡터를 받아 1개의 벡터를 반환
문장이 긍정인지 부정인지를 판단하는 감성 분석(Sentiment analysis)에 사용
③ many-to-many(1) : Sequential 벡터를 모두 입력받은 뒤 Sequential 벡터를 출력 시퀀스-투-시퀀스(Sequence-to-Sequence, Seq2Seq) 구조라고도 부른다
번역할 문장을 입력받아 번역된 문장을 내놓는 기계 번역(Machine translation)에 사용
④ many-to-many(2) : Sequential 벡터를 입력받는 즉시 Sequential 벡터를 출력 비디오를 프레임별로 분류(Video classification per frame)하는 곳에 사용
RNN의 장점과 단점
-
장점 : RNN은 모델이 간단하고 (이론적으로는) 어떤 길이의 sequential 데이터라도 처리할 수 있다
-
단점1 : 벡터가 순차적으로 입력 된다는 점. 이는 sequential 데이터 처리를 가능하게 해주는 요인이지만, 이러한 구조는 GPU 연산의 장점인 병렬화를 불가능하게 만들기 때문에 RNN 기반의 모델은 GPU 연산을 하였을 때 이점이 거의 없다
-
단점2 : 단순 RNN의 치명적인 문제점은 역전파 과정에서 RNN의 활성화 함수인 tanh 의 미분값을 전달하게 된다
역전파과정에서 이 값을 반복해서 곱해주기 때문에 10제곱, 100제곱이 될 수 있다-
ex) 0.9의 10제곱이면 0.349가 되어 시퀀스 앞쪽에 있는 hidden-state 벡터에는 역전파 정보가 거의 전달되지 않게 되고 이런 문제를 기울기 소실(Vanishing Gradient) 이라고 한다
-
ex) 1.1 이면 10제곱이면 2.59배로 커지게 됩니다. 이렇게 되면 시퀀스 앞쪽에 있는 hidden-state 벡터에는 역전파 정보가 과하게 전달됩니다. 이런 문제를 기울기 폭발(Exploding Gradient) 이라고 한다
이런 단점을 보완한 것이 장단기 기억망(Long-Short Term Memory, LSTM)
-
3. LSTM & GRU
LSTM(Long Term Short Memory, 장단기기억망)
RNN에 기울기 정보 크기를 조절하기 위한 Gate를 추가한 모델
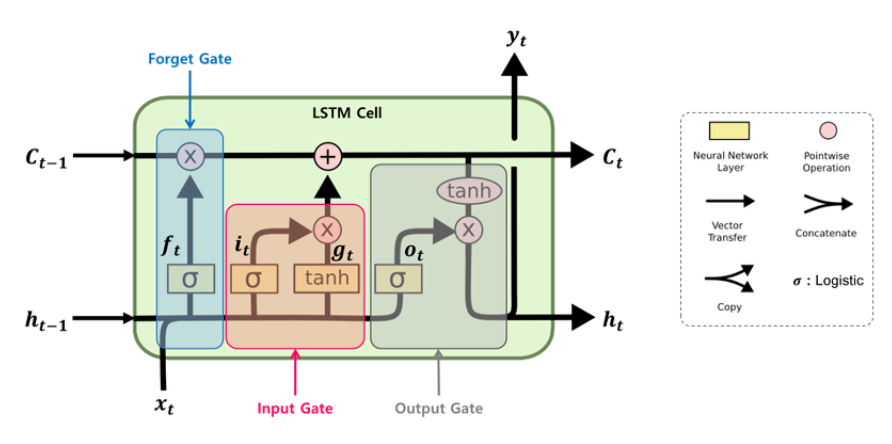
LSTM은 기울기 소실 문제를 해결하기 위해 3가지 gate를 추가
① forget gate (ft): 과거 정보를 얼마나 유지할 것인가?
② input gate (it) : 새로 입력된 정보는 얼마만큼 활용할 것인가?
③ output gate (ot) : 두 정보를 계산하여 나온 출력 정보를 얼마만큼 넘겨줄 것인가?
- hidden-state 말고도 활성화 함수를 직접 거치지 않는 상태인 cell-state 가 추가되었다
- cell-state는 역전파 과정에서 활성화 함수를 거치지 않아 정보 손실이 없기 때문에 뒷쪽 시퀀스의 정보에 비중을 결정할 수 있으면서 동시에 앞쪽 시퀀스의 정보를 완전히 잃지 않을 수 있다
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding
from tensorflow.keras.layers import LSTM
from tensorflow.keras.datasets import imdb
max_features = 20000
maxlen = 80
batch_size = 32
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Embedding(max_features, 128),
tf.keras.layers.LSTM(128, dropout=0.2, recurrent_dropout=0.2),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])GRU : LSTM의 간소한 버전인 GRU
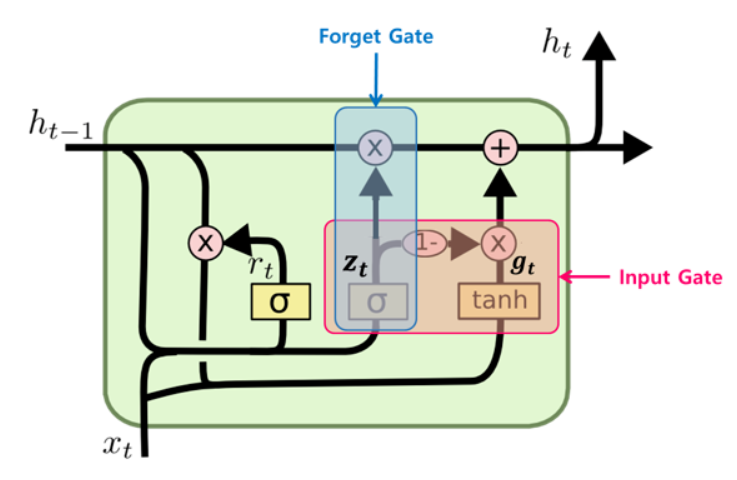
① LSTM에서 있었던 cell-state가 없음
cell-state 벡터 ct 와 hidden-state 벡터 ht가 하나의 벡터 ht로 통일
② 하나의 Gate zt가 forget, input gate를 모두 제어한다
zt가 1이면 forget 게이트가 열리고 input 게이트가 닫히게 되는 것과 같은 효과를 나타낸다
반대로 zt가 0이면 input 게이트만 열리는 것과 같은 효과를 나타낸다
③ GRU 셀에서는 output 게이트가 없음
대신에 전체 상태 벡터 ht 가 각 time-step에서 출력되며 이전 상태의 ht−1 의 어느 부분이 출력될 지 새롭게 제어하는 Gate인 rt 가 추가되었다
※ 기존 RNN기반(LSTM, GRU) 번역 모델의 단점
- 기울기 소실로부터 나타나는 장기 의존성(Long-term dependency) 문제
- 장기 의존성 문제 : 문장이 길어질 경우 앞 단어의 정보를 잃어버리게 되는 현상
- 장기 의존성 문제를 해결하기 위해 나온 것이 셀 구조를 개선한 LSTM과 GRU
4. Attention
-
LSTM, GRU가 장기 의존성 문제를 개선하더라도 문장이 매우 길어지면(30~50단어) 모든 단어 정보를 고정 길이의 hidden-state 벡터에 담기 어렵다 이런 문제를 해결하기 위해 attention을 쓴다
-
Attention은 각 인코더의 Time-step 마다 생성되는 hidden-state 벡터를 간직한다 (입력 단어가 N개라면 N개의 hidden-state 벡터를 모두 간직한다)
-
모든 단어가 입력되면 생성된 hidden-state 벡터를 모두 디코더에 넘겨줍니다.
※ 디코더에서 Attention이 동작하는 방법
- 디코더의 각 time-step 마다의 hidden-state 벡터는 쿼리(query)로 작용
- 인코더에서 넘어온 N개의 hidden-state 벡터를 키(key)로 여기고 이들과의 연관성을 계산
- 이 때 계산은 내적(dot-product)을 사용하고 내적의 결과를 Attention 가중치로 사용
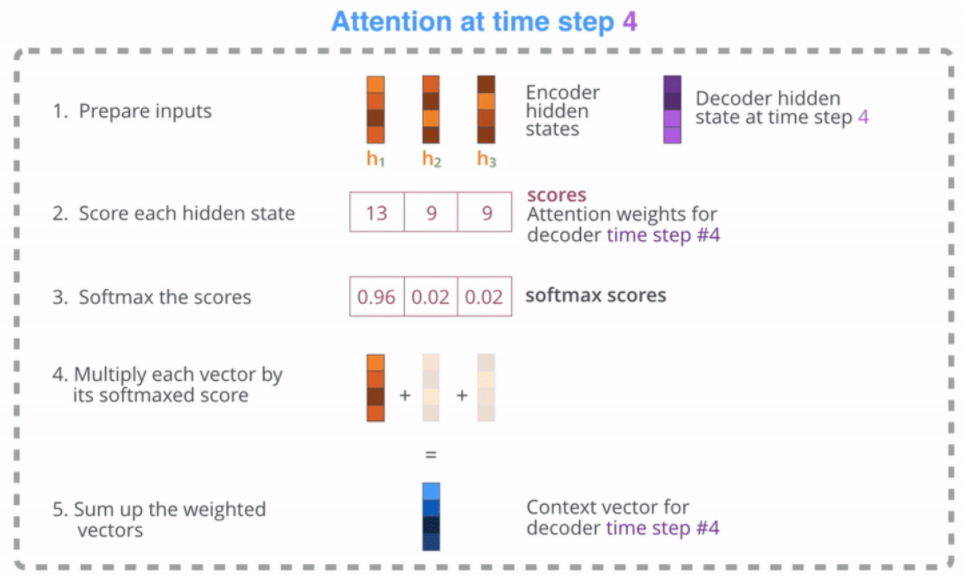
① 쿼리(Query, 보라색)로 디코더의 hidden-state 벡터, 키(Key, 주황색)로 인코더에서 넘어온 각각의 hidden-state 벡터를 준비한다
② 각각의 벡터를 내적한 값을 구한다
③ 이 값에 소프트맥스(softmax) 함수를 취해준다
④ 소프트맥스를 취하여 나온 값에 밸류(Value, 주황색)에 해당하는 인코더에서 넘어온 hidden-state 벡터를 곱해준다
⑤ 이 벡터를 모두 더하여 Context 벡터(파란색)를 만들어준다
이 벡터의 성분 중에는 쿼리-키 연관성이 높은 밸류 벡터의 성분이 더 많이 들어있게 된다
⑥ (그림X) 최종적으로 5에서 생성된 Context 벡터와 디코더의 hidden-state 벡터를 사용하여 출력 단어를 결정하게 된다
