1. Transformer
- RNN 기반 모델이 가진 구조적 단점은 단어가 순서대로 들어온다는 점 때문에 처리해야 하는 시퀀스가 길수록 연산시간이 길어진다
- 이런 문제를 해결하기 위해 등장한 모델이 트랜스포머
- 모든 토큰을 동시에 입력받아 병렬 연산하기 때문에 GPU연산에 최적화
※ 트랜스포머 구조(simple)
트랜스포머는 인코더 블록과 디코더 블록이 6개씩 모여있는 구조
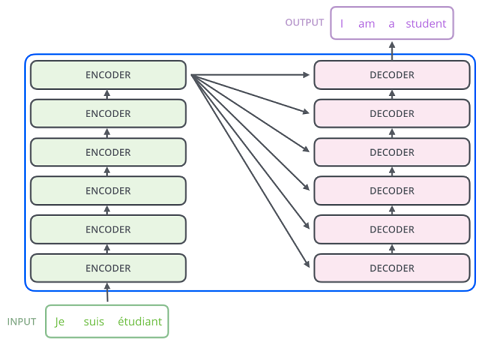
- 인코더 블록 (2개의 sub-layer)
- Multi-Head (Self) Attention
- Feed Forward
- 디코더 블록 (3개의 sub-layer)
- Masked Multi-Head (Self) Attention
- Multi-Head (Encoder-Decoder) Attention
- Feed Forward
2. 트랜스포머 구조
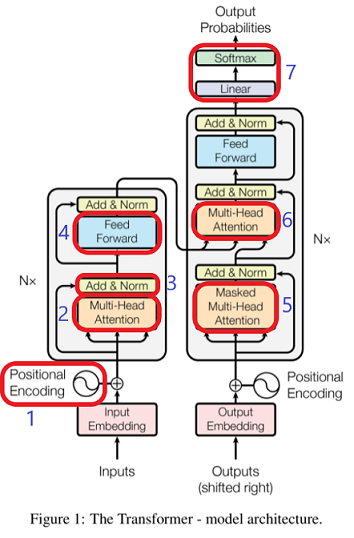
1. Positional Encoding(위치 인코딩)
- 트랜스포머에서는 병렬화를 위해 모든 단어 벡터를 동시에 입력 받기 때문에 컴퓨터는 어떤 단어가 어디에 위치하는지 모른다
- 컴퓨터가 이해할 수 있도록 단어의 위치 정보를 제공하기 위한 벡터를 따로 제공해 주어야한다
- 단어의 상대적인 위치 정보를 제공하기 위한 벡터를 만드는 과정을 위치 인코딩이라고 한다
※ Self-Attension
- it과 같은 지시대명사가 어떤 대상을 가리키는지 알아야 한다
- 트랜스포머에서는 문장 자신에 대해 어텐션 메커니즘을 적용한다 이것이 셀프어텐션
- 기존 Attension과의 차이는 각 벡터가 모두 가중치 벡터라는 점
- 셀프어텐션에서도 쿼리-키-밸류의 아이디어가 사용
- 쿼리 : 분석하고자 하는 단어에 대한 가중치 벡터
- 키 : 각 단어가 쿼리에 해당하는 단어와 얼마나 연관있는 지를 비교하기 위한 가중치 벡터
- 벨류 : 각단어의 의미를 살려주기 위한 가중치 벡터
※ Self-Attention의 과정
- Self-Attention은 세가지 가중치 벡터를 대상으로 어텐션을 적용
① 특정 단어의 쿼리 벡터()와 모든 단어의 키 벡터()를 내적( • )
내적 값 = Attention 스코어
② 트랜스포머에서는 이 가중치를 로 나누어준다
= 벡터 차원
③ softmax를 취해준다. 이를 통해 쿼리에 해당하는 단어와 문장 내 다른 단어가 가지는 관계의 비율을 구할 수 있다
④ softmax의 출력값과 밸류 벡터를 곱해주고 다 더한다
2. Multi-Head Attention
- self-attention을 동시에 병렬적으로 실행하는 것
- 각 head 마다 다른 attention 결과를 내어주기 때문에 앙상블과 유사한 효과
# example
8개의 head를 사용하여 8번의 self-attention을 실행하여 각각의 출력 행렬 Z0, Z1 … Z7 생성
→ 출력된 행렬Zn은 이어붙여진다
→ 행렬 Wo의 요소 역시 학습을 통해 갱신
→ 최종적으로 생성된 행렬 Z는 토큰 벡터로 이루어진 행렬 X와 동일한 shape가 된다3. Layer Normalization & Skip Connection
- 트랜스포머의 모든 sub layer에서 출력된 벡터는 layer normalization 과 skip connection을 거친다
- later normalization의 효과는 batch normalization과 유사하게 학습이 훨씬 빠르게 잘되도록 한다
- skip connection은 역전파 과정에서 정보가 소실되지 않도록 한다
4. Feed Forward Neural Network
- 은닉층의 차원이 늘어났다가 다시 원래 차원으로 줄어드는 단순한 2층 신경망
- 활성화 함수로 ReLU를 사용
5. Mastek Self-Attention
- 디코더 블록에서 사용되는 특수한 self-attention
- 디코더는 auto-regressive(왼쪽 단어를 보고 오른쪽 단어를 예측)하게 단어를 생성하기 때문에 타깃 단어 이후 단어를 보지 않고 단어를 예측한다
- 따라서 타깃 단어 뒤에 위치한 단어는 self-attention에 영향을 주지 않도록 마스킹을 해주어야 한다
- self-attention 매커니즘에서 softmax를 취해주기 전에 가려주고자 하는 요소에 -무한에 해당하는 -10억을 더해준다 이 과정이 마스킹 → 마스킹된 값은 softmax를 취해줬을 때 0이 나오므로 value 계산에 반영이 안된다
6. Encoder-Decoder Attention
- 번역할 문장과 변역된 문장 간의 정보 관계 엮어주는 부분
- 디코더 블록의 masked self-attention으로부터 출력된 벡터를 쿼리벡터(q)로 사용
- 키와(k) 밸류벡터는(v) 최상위 인코더 블록에서 사용했던 값을 그대로 가져와 사용한다
7. linear & Softmax layer
- 디코더의 최상층을 통과한 벡터들은 linear층을 지난 후 softmax를 통해 예측할 단어의 확률을 구한다
3. GPT, BERT
트랜스포머 구조를 변형항 만들어진 언어 모델
사전 학습된 언어모델이라는 공통점
※ 사전학습 : 레이블링 되지 않은 대량의 데이터를 사용하여 미리 학습하는 과정
※ fine-tuning : 사전학습이 끝난 모델에 우리가 하고자하는 태스크에 특화된(task specific) 데이터를 학습(학습시 레이블링 된 데이터 사용)
1. GPT
트랜스포머의 디코더 블록을 12개 쌓아올린 모델
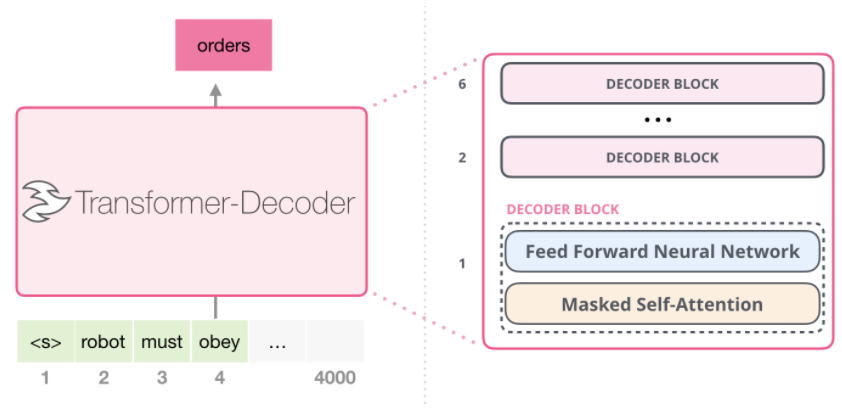
GPT의 구조
- GPT에서는 인코더를 사용하지 않기 때문에 디코더 블록내에 2개의 sub-layer만 있다
- GPT는 인코더를 사용하지 않아서 Encoder-decoder attention 층이 빠진다
※ Fine-tuning
기존 모델에서는 태스크에 맞춰 모델 구조를 변경해주고 학습을 진행
GPT와 같은 사전 학습 언어 모델은 fine-tuning 과정에서 데이터의 입력 방식만을 변형시키고 모델 구조는 일정하도록 설계
2. BERT
트랜스포머의 인코더만을 사용하여 문맥을 양방향으로 읽어낸다
트랜스포머의 인코더 블록을 12개 쌓아올린 모델

BERT의 구조
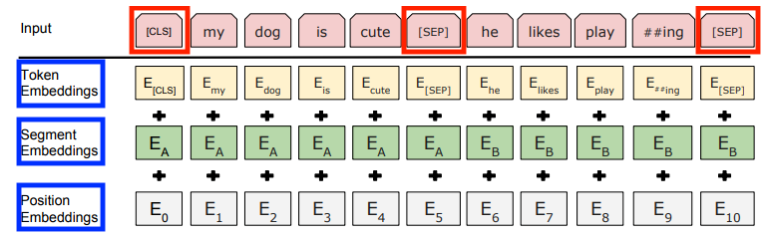
- special token : CLS, SEP
- CLS토큰 : classification 입력의 맨 앞에 위치하는 토큰(NSP이라는 학습을 위해 존재)
- SEP토큰 : seperation 첫번째부분의 끝자리와 두번째 부분의 끝자리에 위치
- input vector
- token embeddings : 단어를 나타내는 임베딩, 사전학습된 임베딩 벡터를 사용
- segment embeddings : 첫번째 부분과 두번째 부분을 구분하기 위한 임베딩
- position embeddings : 단어의 위치를 나타내기 위한 임베딩
- BERT의 사전학습 방법들
MLM(masked language model) : 빈칸 채우기를 하면서 단어를 학습
사전학습 과정에서 레이블링 되지 않은 말뭉치 중에서 랜덤으로 15%가량의 단어를 마스킹 후 마스킹된 위치에 원래 있던 단어를 예측하는 방식으로 학습을 진행
양쪽의 문맥을 동시에 볼 수 있다는 장점
- NSP(Next Sentence Prediction)
모델이 문맥에 맞는 이야기를 하는지 동문서답을 하는지를 판단하며 학습하는 방식

AI/Data Science