
유니온 파인드(Union-Find)
서로소인 부분집합의 표현
그래프/트리의 대표적 알고리즘이다.
서로소 집합이란? 공통 원소가 없는 두 집합을 의미한다.
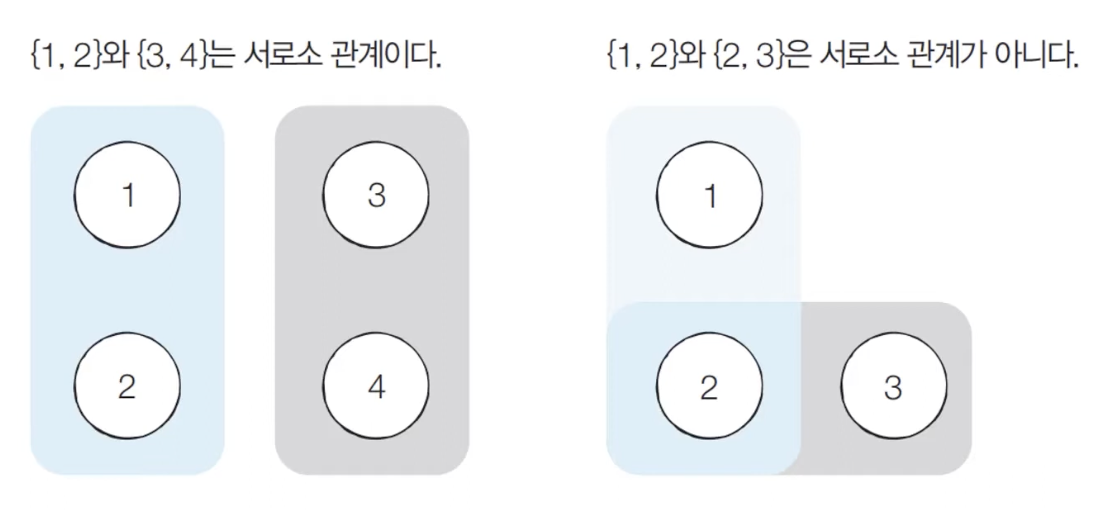
📌 서로소 집합 자료구조
서로소 부분 집합들로 나누어진 원소들의 데이터를 처리하기 위한 자료구조이다.
서로소 집합 자료구조는 두 종류의 연산을 지원한다.
- 합집합(Union)
두 개의 원소가 포함된 집합을 하나의 집합으로 합치는 연산 - 찾기(Find)
특정한 원소가 속한 집합이 어떤 집합인지 알려주는 연산
따라서 서로소 집합 자료구조는 합치기 찾기(Union Find) 자료구조라고 불리기도 한다.
알고리즘 동작 과정
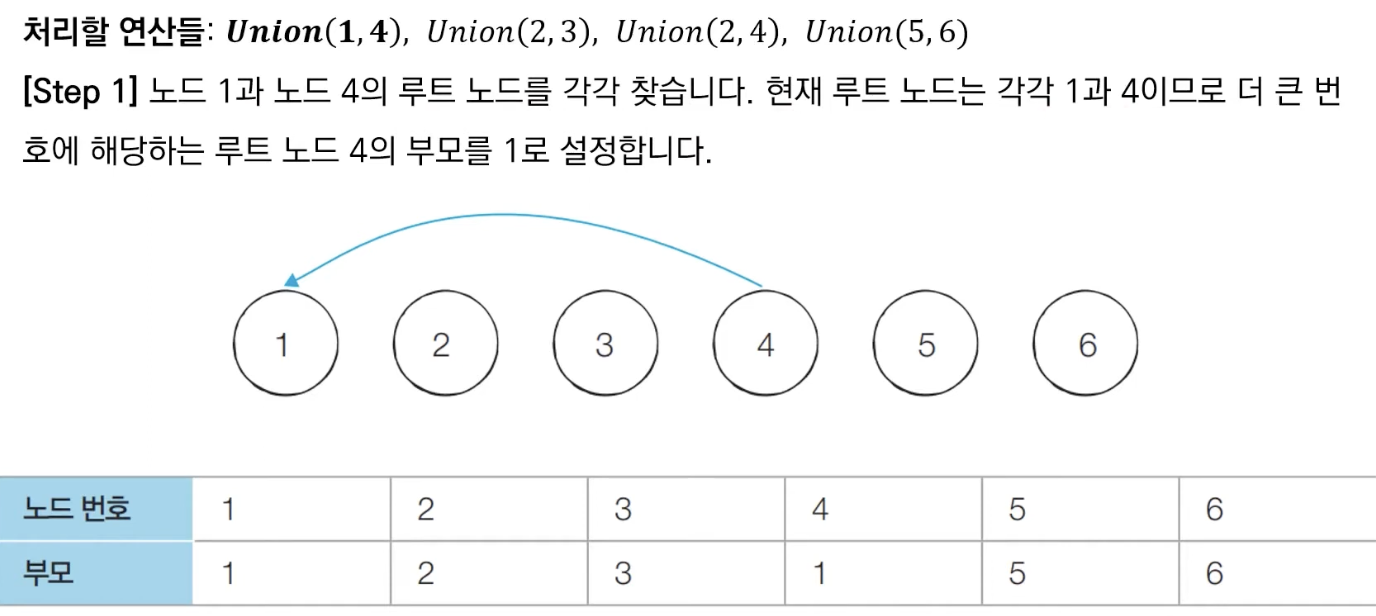
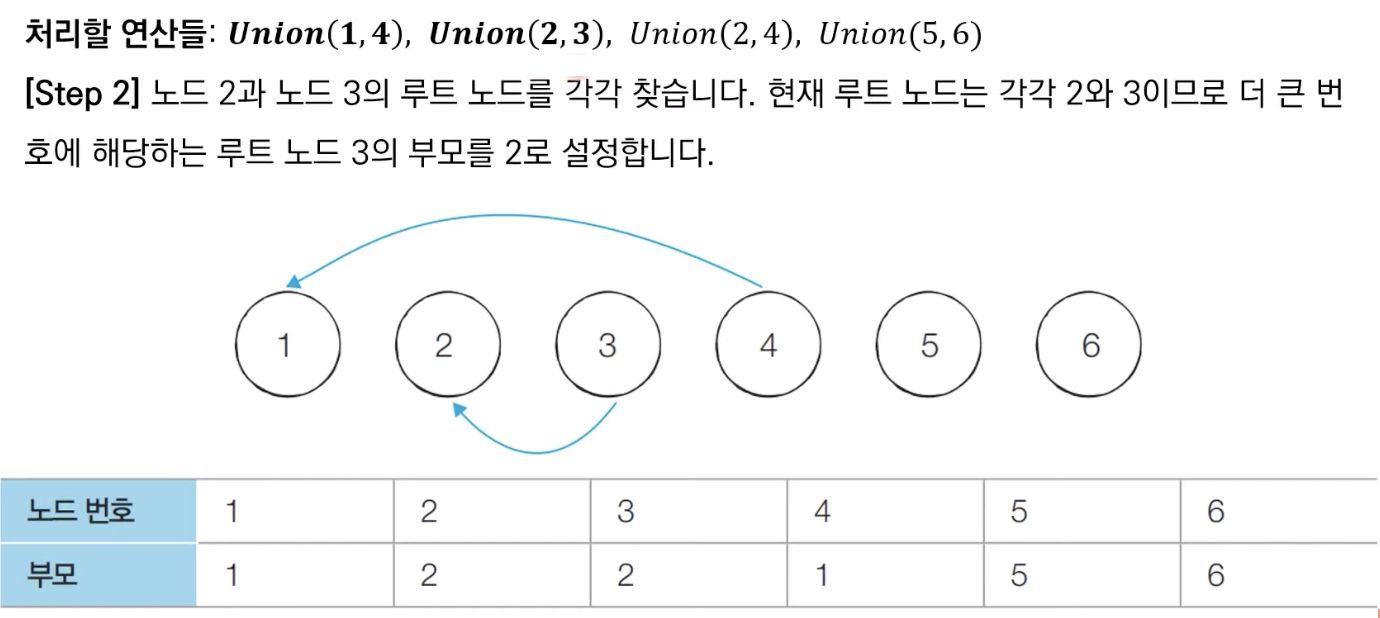
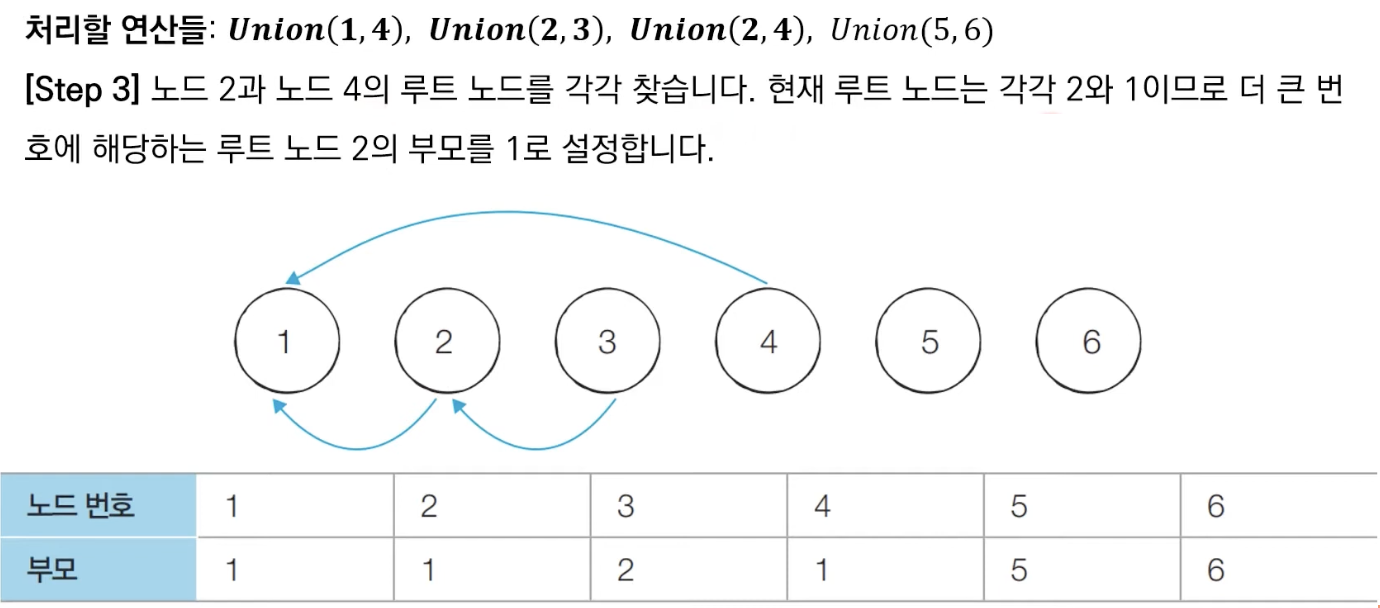
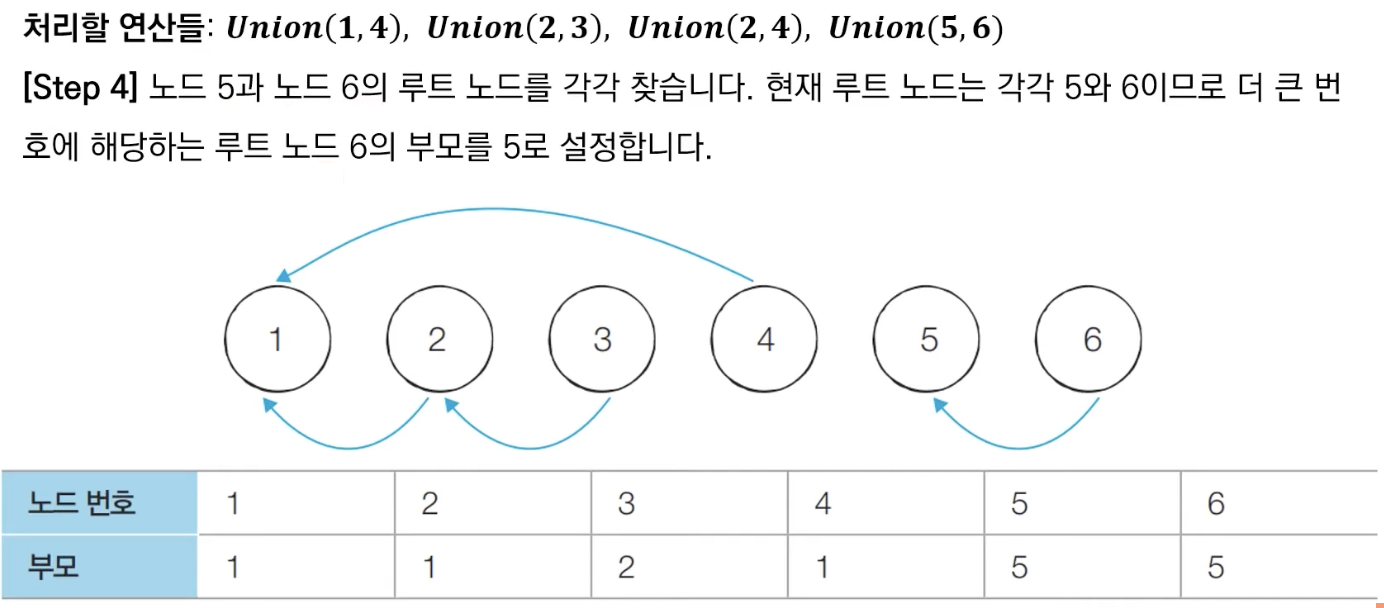
합집합(Union)연산을 확인하여, 서로 연결된 두 노드 A, B를 확인합니다.
1) A와 B의 루트 노드 A', B'를 각각 찾습니다.
2) A'를 B'의 부모 노드로 설정합니다. → 이때 노드 번호가 작은 쪽이 부모가 되도록 한다.- 모든 합집합(Union) 연산을 처리할 때까지 1번의 과정을 반복합니다.
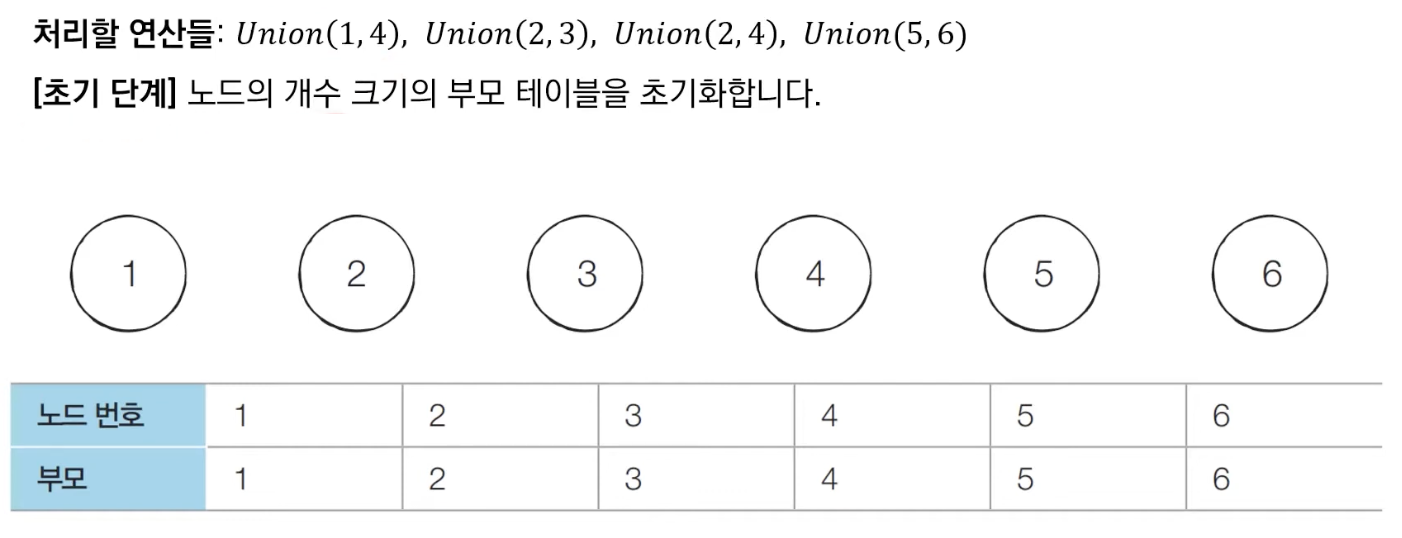
⏰ 초기 단계
부모 노드를 자기 자신으로 설정한다. 6개의 노드가 서로 각각의 집합이라고 볼 수 있다.
즉, 6개의 집합은 모두 서로 다른 집합으로 분류되고 있다.
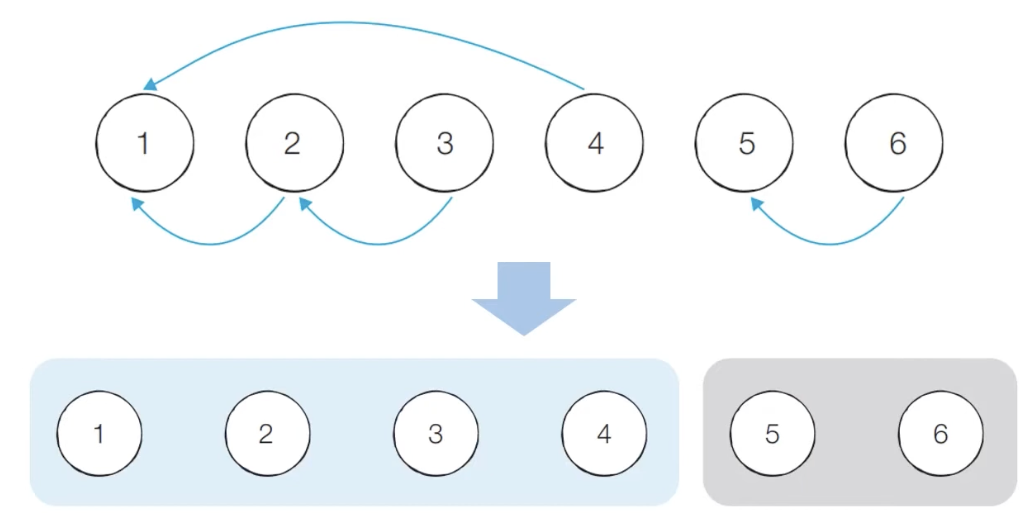
알고리즘의 연결성
서로소 집합 자료구조에서는 연결성을 통해 손쉽게 집합의 형태를 확인할 수 있다.
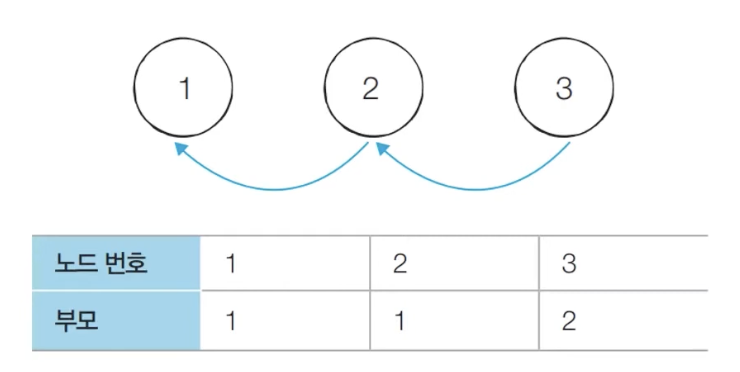
기본적인 형태의 서로소 집합 자료구조에서는 루트 노드에 즉시 접근할 수 없다.
루트 노드를 찾기 위해 부모 테이블을 계속해서 확인하며 거슬러 올라가야 한다.
다음 예시에서 노드 3의 루트를 찾기 위해서는 노드 2를 거쳐 노드 1에 접근해야 한다.
👩🏻💻 기본적인 Union-Find 코드
import java.util.*;
public class Main {
// 노드의 개수(V)와 간선(Union 연산)의 개수(E)
// 노드의 개수는 최대 100,000개라고 가정
public static int v, e;
public static int[] parent = new int[100001]; // 부모 테이블 초기화하기
// 특정 원소가 속한 집합을 찾기
public static int findParent(int x) {
// 루트 노드가 아니라면, 루트 노드를 찾을 때까지 재귀적으로 호출
if (x == parent[x]) return x;
return findParent(parent[x]);
}
// 두 원소가 속한 집합을 합치기
public static void unionParent(int a, int b) {
a = findParent(a);
b = findParent(b);
if (a < b) parent[b] = a;
else parent[a] = b;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
v = sc.nextInt();
e = sc.nextInt();
// 부모 테이블상에서, 부모를 자기 자신으로 초기화
for (int i = 1; i <= v; i++) {
parent[i] = i;
}
// Union 연산을 각각 수행
for (int i = 0; i < e; i++) {
int a = sc.nextInt();
int b = sc.nextInt();
unionParent(a, b);
}
// 각 원소가 속한 집합 출력하기
System.out.print("각 원소가 속한 집합: ");
for (int i = 1; i <= v; i++) {
System.out.print(findParent(i) + " ");
}
System.out.println();
// 부모 테이블 내용 출력하기
System.out.print("부모 테이블: ");
for (int i = 1; i <= v; i++) {
System.out.print(parent[i] + " ");
}
System.out.println();
}
}합집합(Union) 연산이 편향되게 이루어지는 경우 찾기(Find) 함수가 비효율적으로 동작한다.
최악의 경우에는 찾기(Find) 함수가 모든 노드를 다 확인하게 되어 시간 복잡도가 O(V)이다.
다음과 같이 {1, 2, 3, 4, 5}의 총 5개의 원소가 존재하는 상황을 확인해 보자.
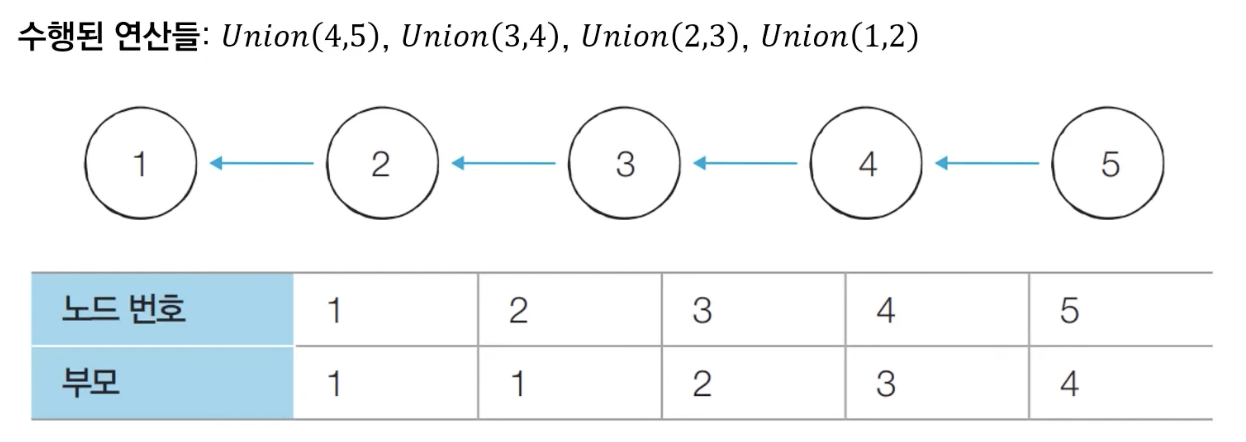
📌 Union-Find 알고리즘: 경로 압축
찾기(Find) 함수를 최적화하기 위한 방법으로 경로 압축(Path Compression)을 이용할 수 있다.
찾기(Find) 함수를 재귀적으로 호출한 뒤에 부모 테이블 값을 바로 갱신한다.
변경 사항
// 특정 원소가 속한 집합을 찾기
public static int findParent(int x) {
// 루트 노드가 아니라면, 루트 노드를 찾을 때까지 재귀적으로 호출
if (x == parent[x]) return x;
return parent[x] = findParent(parent[x]);
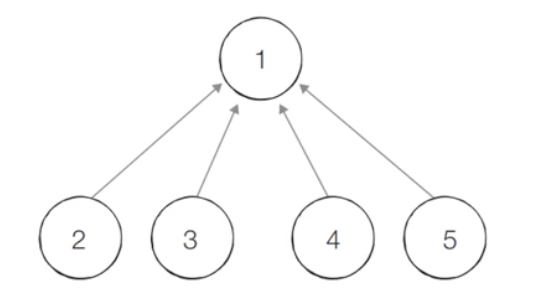
}경로 압축 기법을 적용하면 각 노드에 대하여 찾기(Find) 함수를 호출한 이후에
해당 노드의 루트 노드가 바로 부모 노드가 된다.
동일한 예시에 대해서 모든 합집합(Union) 함수를 처리한 후
각 원소에 대하여 찾기(Find) 함수를 수행하면 다음과 같이 부모 테이블이 갱신된다.
→ 기본적인 방법에 비하여 시간 복잡도가 개선된다.

👩🏻💻 개선된 Union-Find 코드 (경로 압축)
import java.util.*;
public class Main {
// 노드의 개수(V)와 간선(Union 연산)의 개수(E)
// 노드의 개수는 최대 100,000개라고 가정
public static int v, e;
public static int[] parent = new int[100001]; // 부모 테이블 초기화하기
// 특정 원소가 속한 집합을 찾기
public static int findParent(int x) {
// 루트 노드가 아니라면, 루트 노드를 찾을 때까지 재귀적으로 호출
if (x == parent[x]) return x;
return parent[x] = findParent(parent[x]);
}
// 두 원소가 속한 집합을 합치기
public static void unionParent(int a, int b) {
a = findParent(a);
b = findParent(b);
if (a < b) parent[b] = a;
else parent[a] = b;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
v = sc.nextInt();
e = sc.nextInt();
// 부모 테이블상에서, 부모를 자기 자신으로 초기화
for (int i = 1; i <= v; i++) {
parent[i] = i;
}
// Union 연산을 각각 수행
for (int i = 0; i < e; i++) {
int a = sc.nextInt();
int b = sc.nextInt();
unionParent(a, b);
}
// 각 원소가 속한 집합 출력하기
System.out.print("각 원소가 속한 집합: ");
for (int i = 1; i <= v; i++) {
System.out.print(findParent(i) + " ");
}
System.out.println();
// 부모 테이블 내용 출력하기
System.out.print("부모 테이블: ");
for (int i = 1; i <= v; i++) {
System.out.print(parent[i] + " ");
}
System.out.println();
}
}Reference
