0. 기초의 기초
머신러닝의 가장 간단한 모델은 선형회귀 식일 것이다. 선형회귀식은 최소제곱법을 이용하여 식을 데이터에 적합시킨다. 선형회귀식은 다르게 보면 행렬로 볼 수도 있는데, 이때는 와 같은 형태가 되고, 이때 consistent한 방정식이라면 오차가 0이 되는 x를 찾을 수 있지만, 이는 특수한 경우일 뿐이다. 일반적인 경우라면 적합시킨다 하더라도 각 점에 대해 오차가 존재하게 되고, 손실값은 해당 오차들의 합과 같게 된다.
ml 지도학습 분야에서 크게 분야를 또 나눠보면 회귀 문제와 분류 문제가 될 것이다. 사실 분류문제는 회귀 문제를 발전시켜서 y값이 discete한 변수가 되도록 만들고, 이에 맞추어 손실함수를 수정한 것에 불과하다. 선형회귀로 분류 모델을 만들수는 있다! 로짓회귀에 비해 오차가 많이(좀 많이) 커질 따름이다.
최적화 이론에서는 대부분 미분을 사용하게 된다. 최적화에서 미분이란 각 변수에 대해 목적함수가 변하는 순간적인 값을 측정한 것이라고 간주하는 것 같다. 이는 비록 최적해를 제공하지 못할 수도 있지만 반복적으로 특정 범위 내의 변수들에 대해 목적함수를 미분한다면 결국 최적해 근처에 접근할 수 있게 해준다고 한다.
최적화 문제에는 목적함수(objective function)과 손실함수(loss function)이라는 용어가 항상 등장한다. 두 함수에 대해 잠깐 정리하고 넘어가자.
- Objective function : 일련의 변수에 의해 정의되는 함수로서 최적화 문제의 목표는 목적함수의 값을 최대 혹은 최소화하는 변수값을 찾는 것이다.
- Loss function : 음이 아닌 비용을 가지는 목적함수를 이야기하나 본래의 목적함수가 모종의 이유로 직접 최적화할 수 없을 경우 이를 근사한 손실함수를 사용하기도 한다.
1. Univariate Optimization
1-1. Global/Local Minimum/Maximum
가장 단순한 함수는 변수가 하나인 함수일 것이다. 다음과 같은 목적함수 f(x)가 있다고 하자.
이 함수는 아래로 볼록한 함수이다. 또한 다음과 같이 표현할 수도 있다.
이렇게 보면 자연스럽게 최소값이 x = 1에 위치한다는 것을 알 수 있다. 항이 0 되는 지점이기 때문이다. 또한 해당 지점의 미분값이 0이기도 하다.
반대로 다음과 같은 함수가 있다고 하자.
이는 자연스럽게 위로 볼록한 함수가 되고 x = 1에서 최대값을 가진다. 하지만 역시나 해당 지점의 미분값은 0이 된다.
마지막으로 함수 하나를 더 살펴보자.
위 함수는 최대값 혹은 최소값이 없다. 하지만 x = 1에서 역시나 미분값은 0이 된다. 고등학교 때 배운 미분의 개념과 연결시키되 이를 확장지어서 생각해보자. 일차 미분을 이용하면 함수의 최대 혹은 최소값을 구할 수 있지만, 일차 미분만으론 해당 함수가 최대 혹은 최소값을 가지는지 알 수 없다.
이때는 2차 미분을 활용하면 된다. 2차 미분은 해당 함수가 볼록한 함수인지 단조 함수인지 알려주기 때문이다. x 전체 구간에 대해 어떤 함수의 2차 미분값이 0이 아니라면 해당 함수는 볼록함수이다. 하지만 이 역은 성립하지 않는다. 어떤 함수가 특정 구간에서 2차 미분값이 0 이더라도 그 함수가 극대값이나 극소값을 가지는지 알 수 없다.
- critical point : 1차 미분값이 0인 지점. 극대값, 극소값, 안장점 중 하나일 것이다.
- 극소값 인 값 a
- 극대값 인 값 a
- degenerate미분값이 0인 지점이 존재하지만 2차 미분 시 어떤 값 b에서 0이라면 해당 함수는 극대, 극소 혹은 saddle point인지 모호하다.
즉, 우리는 최적화 문제를 풀고자 하기 때문에 변수가 하나인 함수 f(x)를 최소화하려고 하는 경우에 다음과 같은 조건을 만족시키는 점 b를 찾으면 된다.
하지만 이 점 b는 어디까지나 극소점이지 최소점은 아니다. 즉 함수의 전체 구간(정의역)에 대해 해당 f(b)가 최소점임을 보장하지는 않는다. 이로인해 위의 조건은 매우 국소적 관점에서의 최소값이 된다.
1.1 Lemma 4-2-1
제약이 없는 최적화 문제에서 최적화 조건
변수가 하나인 함수 f(x)는 다음과 같은 경우에 에서 국소적 최소값을 가진다.
위 두 조건을 각각 FOC(first-order condition), SOC(second-order condition)라고 한다.
그리고 위 조건은 국소적인 관점에서 최소값을 찾고자할 때 충분조건이며 "거의" 필요조건이다. "거의"라고 표현한 이유는 당연히 이더라도 의 경우와 같이 최소값을 가지는 함수들이 있기 때문이다. 즉, 해당 조건을 만족하지 않아도 최소값을 가질 수는 있다.
이를 테일러 급수를 이용해서 표현하면 다음과 같을 것이다.
여기서 는 매우 작은 수를 가지고 의 국소적 관점을 의미한다. 위의 식에서 이므로 1차 항은 0이 되고, 2차 이후의 항은 이므로 0보다 큰 아주 작은 값을 가지게 된다.
즉, ()이 된다. 다시말해 어떠한 작은 값 에 대해 foc와 soc를 만족한 는 가 성립하게 된다. 결론적으로 는 지역적 최소값이 된다는 의미이다.
또한 위 테일러 급수는 왜 이 문제가 되는지 알 수 있다. 과 이 모두 0이기 때문에 0이 아닌 항이 나타날 때까지 테일러 급수를 확장해야하는데 만약 0이 아닌 항이 양수라면, 이 되어 가 최소값을 가지는 지점이 될 수 있다. 하지만 0이 아닌 항이 음수가 되면 이 되면 의 부호에 따라 는 saddle point가 될 수도, 최대값을 가지는 지점이 될 수도 있게 된다.
이번에는 좀 더 일반화하여 2차 함수가 극대값 혹은 극소값을 가지는지 판별해보도록하자. 결론부터 말하면 꼴일 때, a > 0 이면 극소값(2차 함수이기 때문에 최소값이기도 하다.)을 a < 0이면 극대값(2차함수이기 때문에 최대값이기도 하다.)을 가진다.
2차 함수는 2차 항의 부호에 따라 하나의 극대 혹은 극소값이 존재하는 간단한 경우이다. 하지만 sin함수와 같은 주기함수 등의 경우에선 무한개의 극대 혹은 극소값을 가질 수 있다. 하지만 lemma 4-2-1은 매우 국소적인 지역에서의 최대 혹은 최소값을 살피게 된다. 즉, 위의 정리를 이용한 최대 혹은 최소값 추정은 global minimum/maximum이 아닌, local minimum/maximum이다. 여기서 global minimum/maximum 이란 변수 전체의 범위에 대한 최대최소값을 의미한다.
좀 더 확장하여 극대와 극소값을 모두 가지는 함수를 살펴보도록 하자.
위와 같은 함수가 있다고 할 때, 해당 함수는 두 개의 극소값을 가지고 있다. 또한 global minimum은 x = 2 이며, local minimum은 x = -1이다.
이는 lemma 4-2-1을 사용하면 쉽게 알 수 있다.
이때 자연스레 x = 0이 local maximum이라는 점은 알 수 있다. 두 minimum 사이의 극값이기 때문이다. 하지만 두 minimum point 중 어느 점이 local이고 어느 점이 global maximum인지 판별할 길은 아직 배우지 않았다.
특이할 것은, Covex 함수는 하나의 global minimum을 보장하는 함수라고 한다. 즉, 위의 lemm 4-2-1을 이용할 때, 어느 점이 global minimum인지 확신할 수 없어도, 두 점 중 한 점이 global minimum인 것을 알 수 있듯이, 무조건 global minimum을 확신할 수 있는것이다.
1-2.Gradient Descent
그렇다면 모든 함수에서 local/global minimum/maximum을 1차, 2차 미분을 통해 구할 수 있을까? 그렇지 않다. 만약 방정식 이 closed form의 해를 계산할 수 없다면, 당연히 위의 방식을 이용해 극대 혹은 극소값을 찾을 수 없다. 혹은 함수 가 closed form의 해를 가질 수 있는 함수라 하더라도, 너무 복잡한 형태를 가지고 있다면, 정확하게 방정식을 푸는 것이 불가능할 수도 있다. 일반적인 딥러닝 모델들이 그 식이 미분하여 계산하기에는 너무 복잡하여 그래디언트 디센트 기반 방법론들을 이용하는 이유이다.
이때 사용하는 방법이 gradient descent이다. gradient descent란 초기값 에서 시작하여 연속적으로 x를 가장 가파른 아래 방향의 경사(steepest descent direction)으로 업데이트하는 방식이다.
x를 업데이트 하는 방식은 익숙한 위의 식을 이용해서 이루어진다. 이때 는 한번 움직이는 크기를 제약하는 상수항 learning rate이다. 현재 다루는 단변량 식은 단순해서 두 방향밖에 없기 때문에 왜 가장 가파른 아래 방향의 경사라는 복잡한 표현을 썻나 싶겠지만, 딥러닝과 같이 파라미터의 수가 많아지면 방향이 무척 많아진다. 차원 수가 늘어나기 때문에, 그만큼 방향의 경우도 늘어가네 되는 것이다.
매 이터레이션마다 변화하는 x의 양은 다음과 같다.
여기서 는 국소적인 크기로 x를 이동시키기 위해 아주 작은 양수임을 명심하자(딥러닝에선 보통 0.005를 기준값으로 사용한다.). 이때, 의 크기가 아주 작기 때문에 위 식을 테일러 급수를 이용해 표현하면 1차 식으로 표현이 가능하다.
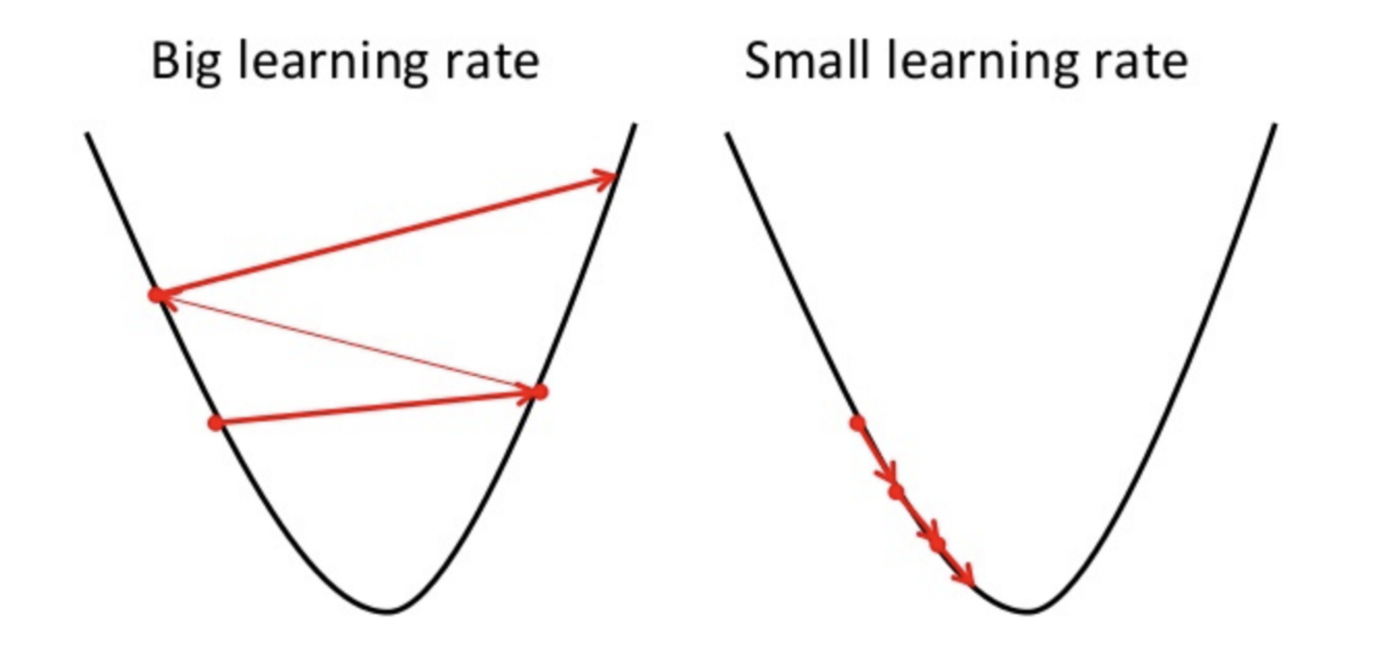
이를 통해 새로 업데이트 되는 x가 항상 지금보다 작은 값의 f(x)로 이동하리라는 것을 쉽게 알 수 있다(최소값을 구하고자 하는 상황이다.). 하지만 이때, 가 너무 작다면 매우 느리게 이동하여 수렴하기까지 오래 걸릴 것이다. 그렇다고 를 너무 크게 잡으면 테일러 급수에서 2차 이후의 항을 무시한 것이 큰 오차를 내어 적절한 근사가 되지 않아 위의 식이 성립하지 않는 상황이 될 수 있다. 즉, gradient란 극히 국소적인 지점에서의 변화율을 의미하지 넓은 범위에서의 변화율을 의미하지 않기 때문에, 적절한 값을 이용해야 한다. 만약 너무 큰 값을 이용하게 된다면, 테일러 급수의 2차항이 유의미한 값을 가지게 되고 현재의 f(x) 값보다 큰 지점으로 이동하거나, optimal point를 지나치는 오버슈이 일어날 수 잇다. 이 중 현재 f(x)보다 큰 지점으로 이동하는 것을 발산한다고 이야기한다.
다음을 통해 실제로 그래디언트 디센트가 이루어지는 두 이터레이션을 살펴보도록 하자.
optimal point : x = 1
위 상황은 극소점인 x = 1에 비해 큰 x = 2에서 시작한 경우의 모습이다. 이때 적절한 크기의 learning rate이 곱해져서 optimal point를 향해 잘 움직이고 있는 모습니다.
optimal point : x = 1
위 상황은 learning rate이 0.8로 매우 큰 상황이다 그 결과 이 optimal point인 x = 1을 지나 0.08이 되는 overshoot이 발생했으며, 역시 초기값인 x = 2를 지나 2.568이 되어 발산하고 있는 모습이다.
즉, 적절한 learning rate을 설정하지 못한다면 overshoot 상황이 발생하게 되고, 심할 경우에는 오히려 f(x)의 값이 상승하는 divergence(발산)이 발생하게 된다.
1-2-1. 안정적으로 수렴시키기
gradient descent의 실행은 일반적으로 최적화하고자 하는 변수 x의 연속적인 값 를 점차적으로 최적해에 가까워지도록 생성한다. 이때 t번째 값 는 점차적으로 최적해에 가까워지면서 first order condition을 만족시키는데 가까워지기 때문에 는 0에 가까워진다. 즉, 최적해에 가까워질 수록 이동하는 폭이 줄어든다는 뜻이다. 이를 이용해서 그래디언트 디센트 알고리즘의 종료시점을 결정하기도 한다.
아래 그림은 각각 수렴하는 경우와 발산하는 경우를 보여주고 있다. 이때 x축은 실행 횟수 혹은 step 수라고 할 수 있고, y축이 목적함수의 값이다. 우리는 목적함수를 최소화하려는 목표에 맞추어 그래디언트 디센트를 실행하게 된다. 좌측과 같이 일정 횟수를 지나면 변화가 거의 없게 되고, 이때 우리는 알고리즘을 종료하는 이상적인 상황을 맞게 된다. 하지만 learning rate이 적절하게 선택되지 못한다면 우측과 같이 optimal point를 지나 overshoot이 반복적으로 발생하면서 발산하게 되는 것이다.
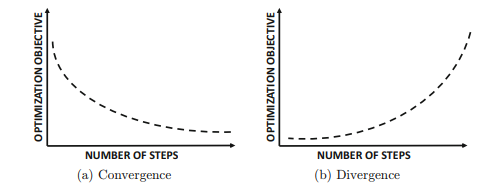
이때 overshoot의 상황을 잠시 구별해보면 다음과 같다.
- 느리게 수렴 : optimal point를 지나기는 하나 결국은 수렴하게 되는 경우
미분값의 부호는 변화할 수 있으나, 매 step마다 이동폭이 점차 줄어듬 - 발산 : optimal point를 지나면서 발산하는 경우
미분값의 부호가 매 step마다 변화하고, 그 폭 역시 지속적으로 증가하게 됨.
주로 learning rate이 지나치게 클 경우 발생
즉, learning rate은 지나치게 큰데, optimal point 근방이라 해당 지점의 미분값이 매우 작을 경우에는 learning rate로 인해 optimal point를 지나 overshoot하게 되고, 그 결과 발산하거나 optimal point에서 먼 지역에서 saturate하게 될 가능성이 있게 되는 것이다. 이를 방지하고자 step이 증가함에 따라 learning rate을 감소시키는 방법을 사용하기도 하나, 이 역시 초기 learning rate이 지나치게 클 경우 큰 효력을 발휘하지 못한다. 그러므로 발산하는 상황이 보인다면(파라미터의 크기가 지속적으로 커지거나, 목적함수값이 감소하지 않는다면) learning rate을 줄일 필요가 있다고 할 수 있다.
