Intro
GPT-1의 마지막 파트를 살펴보면 pretrain된 모델이 downstream task에 대해 학습되지 않은 상태에서 각 태스크에 대해 어느 정도의 성능을 보이는지 측정한 파트가 있다. 매우 단순하게 pretrain이 실제로 다양한 downstream task를 수행할만큼 언어구조를 이해하도록 학습하는지 확인하는 절차였던 것 같다. 이는 모델이 수행해야 하는 태스크를 전혀 학습하지 못한채, input으로 각 태스크의 input과 이를 LM이 수행할 수 있도록 해주는 프롬프트만 입력하는 일종의 zero-shot 환경에서의 성능이라 볼 수 있다.
GPT-2는 이를 더 확장하여 더 큰 모델이 더 많은 데이터에 학습했을 때, 유의미한 수준의 zero-shot 성능을 보이는지 확인하는 논문이라 할 수 있다. GPT 논문을 읽기 전까지 마냥 데이터 우겨넣고 모델만 키울 줄 아는 OpenAI놈들이라 비하하던 나 자신을 후회하며 두번째 논문 리뷰를 시작해보자.
Background
GPT-1과 BERT 발표 이후 수많은 Pretrain 모델들이 발표되었다. 그리고 그 모델들은 하나의 프레임워크를 따른다. 이는 다음과 같다.
- 대량의 Unlabeld Dataset을 이용한 Pretrain
- Label이 있는 비교적 소량의 Downstream Task를 위한 Dataset을 이용해 Finetuning
이를 이용해 pretrain 개념이 없던 시절에는 달성하지 못한 높은 성능을 달성하게 되었다. 이는 대량의 데이터셋을 이용한 pretrain 덕분에 모델의 크기를 키울 수 있었고, 이를 통해 비교적 소량의 finetuning datset으로도 쉽게 성능을 끌어올릴 수 있기 때문이다. 하지만 이렇게 finetune된 모델은 결국 해당 태스크만 수행할 수 있는 아주 지엽적인 모델이 되어버린다.
이에 GPT-2의 저자들은 이러한 finetuning을 통해 지엽적인 모델을 만들어버리는 순간 일반화 성능이 떨어지는 것이 아닌가 하는 의심에서 연구가 출발되었다고 한다.
물론 이에 대응해서 다양한 태스크를 사전학습에 반영하는 Multitask Learning 방법론들도 여럿 연구되어 왔다고 한다. 하지만 안정적으로 Multitask 성능을 확보하기 위해서는 결국 pretrain에 사용될만큼 많은 양의 각 downstream task용 dataset이 필요하게 되고, 저자들은 이러한 접근방식이 과연 지속적으로 유지될 수 있는 방향인지 의구심을 품는다. 아무래도 레이블링이 인적, 금전적, 시간적 자원을 많이 잡아먹기 때문일 것이다.
이와 더불어서 더이상 task-specific한 모델 구조는 더이상 필요하지도 않다고 본다. BERT와 GPT-1에서 보여줬듯이 트랜스포머 기반의 self attention block이 이미 충분히 사전학습된 지식을 이용하여 downstream task를 수행하는데 탁월한 모습을 보였기 때문이다. 즉, 이전처럼 이 구조 붙이고 저 구조 붙이는 복잡한 방식의 모델 설계가 범용적인 대형 모델보다 우위에 설 수 없다는 의미이다.
Appoach
그래서 저자들이 들고 온 방법론은 결국 다시 LM이다. 이 논문의 1저자 중 한명인 Radford는 이전의 GPT-1의 1저자이기도 한데, GPT-1에서 보였던 LM 모델링이 사전학습에 매우 효과적이라고 여긴 것 같다. 전반적인 LM의 흐름 자체는 일반적인 LM과 다를 바 없다. 즉, 연속된 문자열의 나열로 구성된 문장의 생성 확률을 이전 토큰들을 조건으로 하는 조건부 확률의 결합확률로 분해하여 아래와 같이 나타낼 수 있다.
LM pretrain을 통해 학습된 모델이 만약 충분히 general한 상황이라고 해보자. 즉, 별도의 finetuning 없이도 인간처럼 다양한 태스크를 풀 수 있다고 생각하는 것이다. 이를 논문에서는 general system이라 표현하고 있는데, 아래와 같이 간단히 정의할 수 있을 것 같다.
General System : 다양한 태스크에 대해 별도의 fine-tuning 없이도 우수한 성능을 보이는 일반화된 모델
기본적인 downstream task를 수식으로 간단히 표현해보면 아래와 같다.
하지만 모델이 다양한 태스크를 한번에 수행할 수 있는 general system이라면, 동일한 input에 대해서도 다른 task를 수행할 능력이 있기 때문에, task 역시 조건으로 걸어야 한다.
GPT-2가 general system 이라 가정하면, 어떻게 input으로 task를 넣을 수 있을까? text style transfer처럼 가장 첫 토큰으로 각 태스크에 해당하는 special token을 넣어볼 수도 있을 것이다. 하지만 논문에서는 더 급진적인 방법을 택한다. 언어라는 것은 무척 자유롭게 표현이 가능한 데이터 형태이기 때문에, task, input, output이 모두 연속된 문자열로 표현이 가능하다고 주장한다. 예를 들어 번역 태스크를 GPT-2가 수행했으면 좋겠다면 다음과 같이 전체 input을 구성한다.
translate to french, english text, french text
그러니까, 저런 문자열을 집어넣어서 번역 태스크를 수행하도록 유도하는 것이다. 위 예시를 task, input, output으로 분해하면 다음과 같다.
- task : translate to french
- input : english text
- output : french text
위와 같은 형태의 데이터에 대해 LM을 수행하면서 모델은 task와 input이 주어지면 자연스레 output을 생성할 수 있게 된다. 즉, 모든 태스크를 LM으로 변환해서 next token prediction 문제로 바꾼 것이다.
이러한 접근은 GPT-2가 처음은 아니라고 한다. GPT-1 논문 말미에도 간단하게 서술이 되고 있고, MQAN이라는 모델에서 보다 본격적으로 다루고, 실제 이러한 학습이 가능함을 증명하고 있다고 한다. 이것이 가능한 이유가 최적화 관점에서 supervised objective가 결국 unsupervised objective의 부분집합이기 때문에, unsupervised objective에서 찾은 global minimum은 당연하게도 supervised objective의 global minimum이기 때문이라고 한다. 사실 이 부분은 그렇게 와닿지 않는다. 너무 피상적으로 정의하고 있는 것 같고, 실제로 논문에서도 toy-ish setup이라 표현한다.
어쨋든, 이렇게 문제를 unsupervised setting으로 바꾸면, 발생하는 것이 수렴하기 어렵고, 학습속도가 너무 느리다는 것이다. 이는 자연스러운 것이 unsupervised setting에서 유의미하게 학습이 가능하려면 파라미터의 수가 이전과 비교할 수 없을 만큼 많아져야 하고(T5, GPT-2,3 등의 모델이 커진 이유), 이렇게 막대한 파라미터를 최적화하는 과정이 빠르거나 쉽게 수렴하기 힘들다.
말이 많았는데, 정리하자면 연구진들의 연구 동기는 다음과 같다.
모델의 크기를 막대하게 키운다면 unsupervised setting인 Language Modeling을 통해서 multi task learning이 가능해질 것이다. 그리고 이를 저자들은 zero-shot setting에서 다양한 태스크에 모델 성능을 측정함으로써 증명해보이고자 한다.
Dataset
Common Crawl
아무래도 모델 크기가 크다보니 당연하게 데이터셋에 대한 이야기를 하지 않을 수 없다. GPT-2 이전에도 Common Crawl과 같은 대형 코퍼스가 존재했으나, 해당 데이터셋은 unintelligible한 문장들이 다수 발견되는 등의 quality issue가 발생하여 사용할 수 없었다고 한다. 연구진들이 Common Crawl 데이터를 정제하는 등의 작업을 수행할 수도 있었으나, 이는 결국 데이터셋의 크기를 줄이고, 특정 태스크로 모델을 사전에 한정짓는 행위가 되어 버린다(정제하는 과정에서 특정 태스크에 맞는 데이터만 남게 되기 때문에). 그래서 연구진들은 그냥 새로 수집했다. 그렇게 수집한 데이터셋이 WebText이다.
WebText
대량의 데이터셋을 수집하면서도 quality control을 실현하기 위해서, 연구진은 간단한 휴리스틱을 도입했다. 큰 아이디어는 인간들이 미리 큐레이팅하거나 거른 페이지에서만 수집했다.
구체적으론 Reddit에서 3 karma(공감과 같은 장치이다)이상을 받은 페이지에 대해서, 해당 페이지의 링크들에 대해서만 수집을 진행한 것이다. 이렇게 수집한 WebText는 총 45,000,000 페이지이며 이를 HTML에 대한 파싱과 중복 문서 제거 등의 작업을 거쳐 총 40GB의 텍스트 데이터를 수집했다.
특이할 점은 Wikipedia 데이터를 제외했다는 점인데, 이는 워낙 위키피디아 자체가 여러 사이트에서 인용하고 있기 때문에 train과 test 데이터 간의 overlap을 조절하기 까다롭기 때문이라고 이야기하고 있다.
이외도 BPE의 경우 글자 단위가 아니라 실제 바이트 단위로 내려가서 인코딩을 실시했고, 이때 실제 언어적 특성을 반영하기 위해 문자 카테고리마다 병합이 일어나지 않도록 처리했다고 한다.
Model
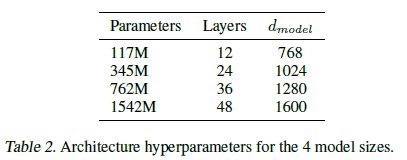
모델은 기존의 GPT-1의 구조를 그대로 따르고 있다. 다만, 몇가지 세세한 조정(layer normalization의 위치, residual block의 크기 등)을 조절하였다고 하는데, 전체 모델을 파악하는데 있어 크게 중요한 사항은 아니다. 주목할 점은 GPT-1보다 모델 크기가 더 커졌다. 가장 작은 모델이 GPT-1과 동일한 하이퍼파라미터를 공유하는데, 가장 큰 모델은 레이어도 48개에 model dim은 1600이나 된다. 진정으로 Big Model이라고 할 수 있다.
Experiment
실험에서 특이할 사항은 가장 큰 모델 조차도 WebText에 아직 과적합되지 않앗다고 한다. 아직 PPL이 나아질 여지가 남아있는 상태에서 실험들이 진행되었다고 하는데, 대형 pretrained LM들을 대량의 데이터에 의도적으로 과적합시키면 어떤 일이 일어날 지 궁금하다. 최근에 읽어본 논문들에선 모두 과소적합이 일어났다고 서술하기 때문이다.
실험은 크게 4가지 분야의 벤치마크 데이터셋을 이용했으며, 주의할 점은 GPT-2는 해당 벤치마크 데이터에 대한 fine tuning이 진행되지 않은 채, fine-tune된 모델들과 성능 비교를 하고 있다는 점이다. 즉, GPT-2는 해당 태스크를 접한 적이 없음에도 zero-shot setting에서 tine tuned 모델과 비교하는 매우 불합리한 상황이라고 할 수 있다.
Language Modeling
위에서도 언급했지만 GPT-2는 다양한 데이터셋에 대한 fine tune을 전혀 진행하지 않은 상태에서 각 데이터셋에 fine tune된 모델들과 비교할 예정이다.

LM 성능부터 비교를 해보자면, 전혀 fine tune이 되지 않은 상태임에도 단 한가지 데이터셋을 제외하고 모든 데이터셋에서 SOTA의 성능을 보인다. 특이할 만한점은 long-term dependency를 염두에 둔 데이터셋(LAMBADA, Children's Book Test)나 아주 작은 데이터셋(Penn Treebank, WikiText-2)에서 특히 성능이 좋은데 개인적인 의견으론 이는 WebText 데이터셋이 워낙 크고, GPT-2 역시 워낙 커서 pretrain의 효과를 톡톡히 보고 있는 것 같다.
STOA를 달성하지 못한 1BW 데이터셋의 경우 워낙 데이터셋이 크고, 문장들을 suffling하여 long term depedency가 필요하지 않기 때문이라고 언급하고 있다.
그럼 데이터셋을 하나씩 살펴보면서 자세히 분석해보자.
Children's Book Test
CBT는 서로 다른 성질의 단어들을 LM이 제대로 이해할 수 있는지 측정하고 구축된 데이터셋이라 한다. 여기서 서로 다른 성질의 단어란, named entity, 명사, 동사, 전치사 등 품사나 역할 측면에서 다른 단어들을 의미한다. 이때 각 단어들을 vocab에서 예측하지 않고 주어진 보기 10개 중에 고르는 cloze test를 하기 때문에 accuracy를 지표로 삼고 있다. GPT-2는 오직 LM으로서만 동작하기 때문에 해당 보기의 확률과 해당 보기를 선택했을 경우의 이후 문장의 조건부 확률을 이용해 가장 높은 확률을 가지는 보기를 예측값으로 선택했다고 한다.
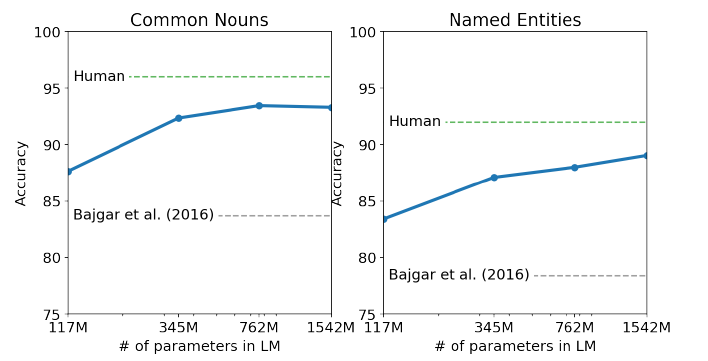
표를 살펴보게 되면, 모델 크기가 커지면서 점점 인간 성능에 근접해가는 것을 볼 수 있는데, 역시나 pretrain에서 모델의 크기가 중요하다는 점을 시사한다.
LAMBADA
LAMBADA는 위에서도 언급했듯이 모델이 long term dependency를 제대로 잡아내고 있는지 측정하고자 고안된 데이터셋이다. 여기서는 마지막 토큰을 예측하는 태스크를 수행하게 되는데, 이때 인간은 마지막 토큰을 예측하기 위해 최소한 50 토큰이 필요하다고 한다. 최소 50 토큰의 context를 이용해야 마지막 토큰을 예측할 수 있는 태스크라고 한다. 추가적으로 특이할만한 이야기는 없었는데 아무래도 그냥 GPT-2가 long term dependency를 잘 잡아낸다는 이야기를 하고 싶었던 것 같다.
Winograd Schema Challenge
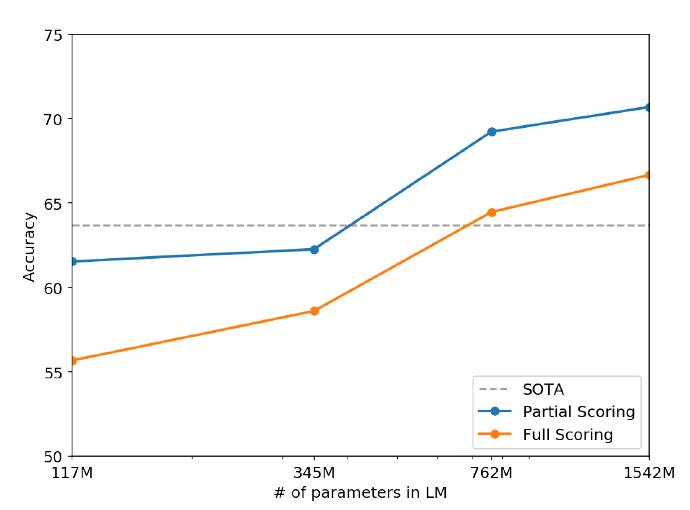
Winograd Schema Challenge는 문장 내 모호성을 해소하는 과정을 통해 모델이 commonsence reasoning이 가능한지를 측정하는 데이터셋이라고 한다.
자세한 내용은 해당 논문을 조금 살펴봐야할 것 같다. 하지만 논문을 읽으면서 들었던 생각은 commonsence라는 것이 input 데이터 내부에 존재하는 것이 아니라 외부에 존재하는 지식이기 때문에, 모델이 얼마나 정보들을 잘 parameterization하고 있는지 측정하고 있는 태스크인 것 같다. 특히 모델의 크기가 정보의 parameterization에 중요한 요소라고 알고 있기 때문에 위와 같이 모델 크기가 중요하게 작용한 것이 아닌가 싶다.
Converstaion Question Answering
CoQA는 대표적인 Reading Comprehension 태스크인데, 과거 대화 내용을 이용하여 모델이 얼마나 현재 질문을 이해하고 이를 context에서 추출할 수 있는지 측정하는 태스크로 알고 있다. GPT-2는 여기서 context에 해당하는 문서와 이전의 대화를 입력으로 넣었을 때 베이스 라인 모델 4개 중 3개의 성능을 넘어서는 모습을 보여줬다고 한다. 물론 SOTA 모델에 비해 한참 모자란 성능이지만, supervised 환경을 전혀 적용하지 않고도 베이스라인 모델의 성능을 넘어선 것은 고무적이라 할 수 있을 것이다.
Summarization
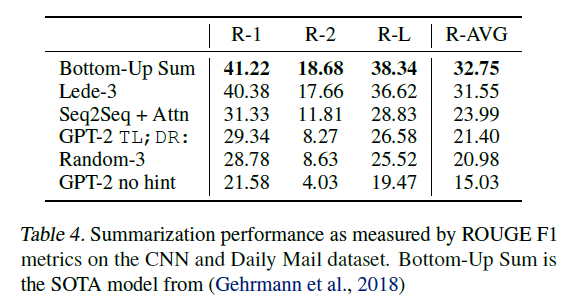
요약 태스크의 경우 자주 쓰이는 CNN and Daily Mail dataset이 이용되었다. 이때 재밌는 것은 어떻게 요약을 프롬프트로 수행할까 봤더니 본문을 주고 TL;DR: 이라는 토큰을 넣어줬다고 한다. 이는 문장이 길어서 읽지 않았다는 의미를 지니는 인터넷 속어이다. 흔히 한국어에서 3줄 요약 이라고 쓰는 것과 비슷한 활용을 가진다. 이때 위 표에서 처럼 TL;DR: 마저 주지 않을 경우 본문에서 랜덤한 세 문장을 뽑는 것보다 못한 성능을 보여주고 있다. 위에서도 보이지만 가장 앞 3문장을 뽑는 것이 seq2seq with attention 모델보다 성능이 좋을만큼 개인적으론 요약 태스크가 상당히 추상적이고 정량평가가 힘든 태스크라고 생각하는데, GPT-2가 돌아간다는 것 자체가 신기하다.
Translation
GPT-2는 번역 태스크도 수행한다. 무턱대고 번역을 하지는 못하고 아래와 같이 example을 모델에 조건으로 넣어줘야 한다.
english sentence1 = french sentence1, english sentence =
신기한 점은 WebText 데이터 상에는 영어 데이터만 존재하는데도 불구하고 2017년쯤 나온 unsupervised NMT 모델들의 성능을 넘는 모습을 보여준다는 점이다. 이때 번역 언어가 프랑스어라서 상대적으로 영어와 유사하기 때문이지 않을까 추측한다.
즉, 모델에게 어느정도의 힌트를 주게 되면, 모델은 처음보는 태스크에 대해서도 일정 수준의 성능은 보여주는 점을 의미한다.
Question Answering
더 극단적인 환경에 모델을 밀어넣어보자. T5처럼 context를 주지않고 question만 입력해도 모델은 옳바른 답변을 생성할 수 있을까? 이때도 QA 태스크임을 알려주기 위해 question-answer pair를 앞에 조건으로 넣어준다고 한다. 결론부터 말하면 돌아는 간다.
정확히 말하면 작은 모델보다 큰 모델이 약 5.3배 더 높은 성능을 보였다. 그 성능은 4.1%의 exact match 였다고 한다. 물론 기존의 open domain QA system들에 비하면 훨씬 말도 안되는 성능이기는 하지만, 모델의 크기가 커질수록 성능이 높아진다는 측면을 보면 GPT-2 역시 어느정도 지식들을 parameterization 한 것이 아닌가 싶다.
Generation vs Memorization
그럼 GPT-2는 정말 생성을 하고 있는 걸까 아니면 그냥 학습 데이터의 문장들을 parameterization하여 기억하고 있는 것일까? 이 문제는 꽤 중요한데, 최근에 이루다처럼 모델이 학습 데이터를 기억하여 그대로 생성해버리면 개인정보 등의 문제가 발생할 수 있기 때문이다.
또한 모델의 성능 측정 측면에서도 중요하다. 학습 데이터들이 점점 커지면서 Train, Validation, Test Split이 점점 힘들어지기 때문이다. 우리는 보통 test에 대한 성능을 측정하지만, 만약 Train에 있는 데이터들이 test에도 중복으로 존재한다면? 전체 문장이 아니라 아주 중요한 문구나 일부 구절이 중복된다면? 이를 거르지 못하면 모델이 실제로 생성하는 것이 아니라 기억하는 것임에도 제대로 성능을 평가할 수 없다.
논문의 저자들은 이를 고려하여 8-gram overlap을 측정했다고 한다.
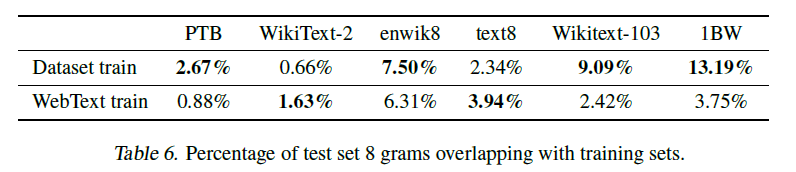
재밌는 점은 대부분의 LM Dataset의 test data가 WebText와는 평균 3% 정도로 낮은 overlap을 보이지만, enwik8이나 Wikitext-103, 1BW는 본인의 Train Dataset과 상당한 overlap을 보인다는 점이다. 이는 위에서 보여준 GPT-2의 one-shot 혹은 zero-shot 결과들이 단순히 WebText를 기억하고 생성해낸 것이 아님을 의미한다.
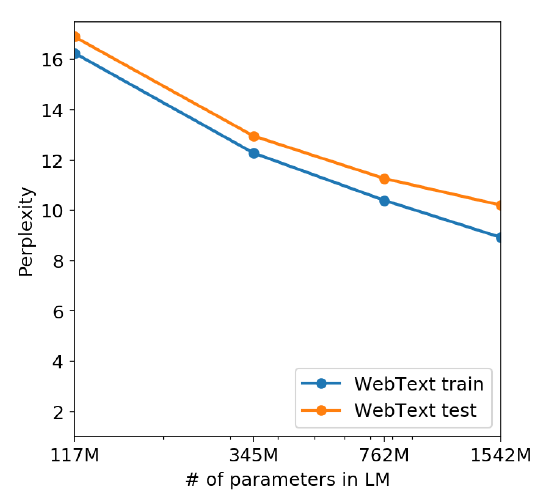
또한 위 그림에서 보이듯이 모델 크기가 커질수록 train과 test에서 ppl이 계속 떨어지는 모습을 보이고 있다. 즉, GPT-2는 아직도 WebText의 underfit된 모습이고, 그러므로 데이터를 기억하고 있지 못하다고 이야기한다.
위 문장들이 약간 나이브하다는 생각이 들긴 하지만, 이 논문에서 이를 더 다뤄버리면 이야기가 너무 길어질 수 있겠다는 생각이 든다. 아마 다른 논문들을 찾아보면 모델의 생성과 기억 관점에 대해 더 자세히 파고들었을 것 같다.
Conclusion
GPT-2 논문을 읽어보면 결국 파라미터의 크기를 키우고 dataset도 키웠을 때 language modeling 만으로 one shot 혹은 zero shot learning이 가능한지 보여주고 있다. 즉, 언뜻 생각했을 때 어떻게 lm만 수행한 pretrain model이 downstream task를 수행할 수 있지? 라는 의문이 들 수 있는데, 이를 해결하고자 노력한 논문인 것 같다. 실제로 논문에 실린 생성문들을 보면 꽤 그럴듯한 문장들이 만들어지고 있다.
이전에 DSBA CS224N 세미나에서 T5나 GPT-3를 잠시 다뤘던 것과 이어 생각해보면, 결국 GPT-2는 하나의 종착역으로서의 논문이라기 보다 모델을 키우고 finetuning을 줄이는 포문을 열어준 논문이라 생각한다.
점차 모델의 크기들이 커지면서 fine tuning에 드는 수고가 줄어들고 범용적인 pretrain model이 될 수 있지 않을까(내가 몰라서 그렇지 이미 됐을 수도 있다.) 하는 생각이 든다.
