자연어 논문 리뷰
1.Word2Vec
오늘 다뤄볼 논문은 이제는 거의 고전 수준이 되어버린(사실 그렇게 엄청 오래된 논문은 아니지만 이 바닥에선 고전이라고 할 수 있을 것 같다.) word2vec이다. 방법론 자체가 지금의 기준으로 엄청 참신하다거나 너무 새로워서 모든 related work를 살펴봐야 할
2.Pointer - Generator
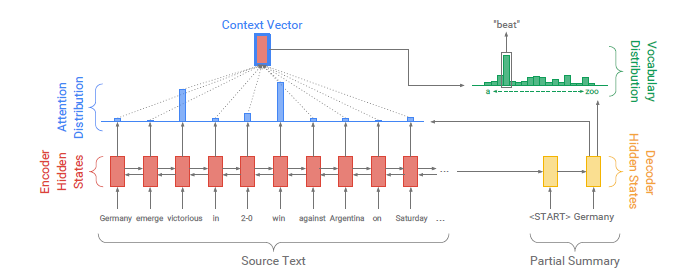
이번에 다뤄볼 논문은 pointer generator라고 불리는 논문이다. arxiv 게재 기준으로 2017년에 나온 꽤 오래된 논문이지만(2017년 논문을 오래됐다고 할 때마다 이게 맞나 싶다...) summarization 분야나 연구실에서 하고 싶은 DST(Dia
3.Style Transformer
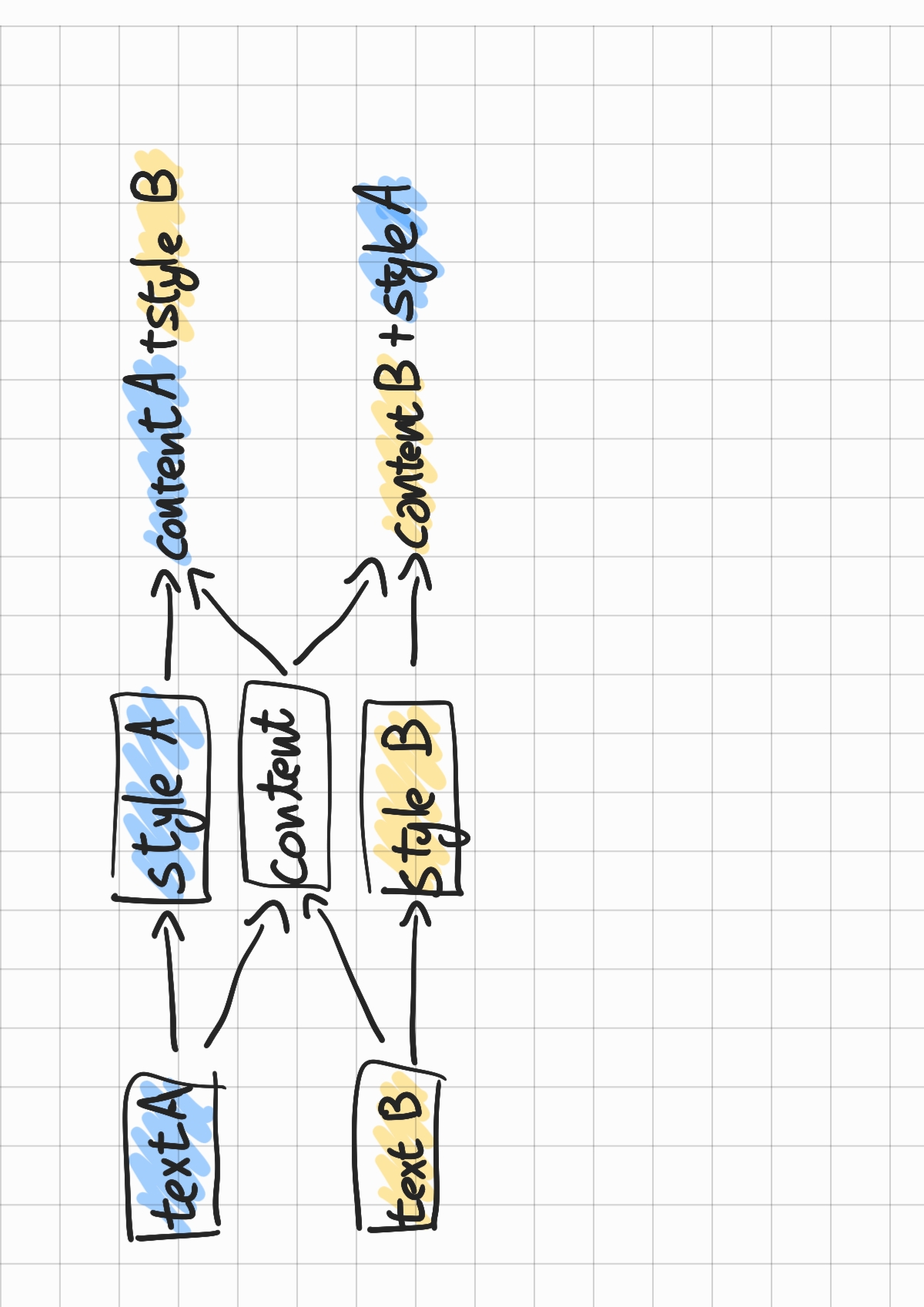
최근 투빅스 컨퍼런스에서 "비영어권 사용자를 위한 글을 정갈하게 다듬어주기"(내맘대로붙여본이름, 정식이름은아직정해지지않았다.) 프로젝트가 시작되었다. 전체적인 플로우는 아래 그림과 같이 이루어질텐데, 나는 그 중에서도 unpaired data를 이용해서 non-nati
4.Seq2Seq with Attention
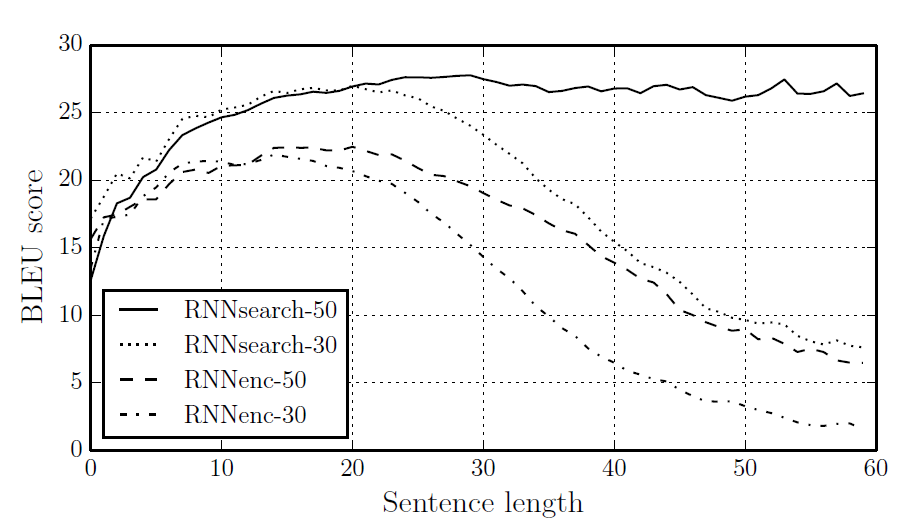
이번에 리뷰해볼 논문은 Neural Machine Translation by Jointly Learning to Align and Translate이다. 지금은 유명해지신 조경현 교수님이 참여하신 논문인데, 본래는 교수님이 제시하신 seq2seq 구조를 개선하고자 at
5.Transformer - Implementation
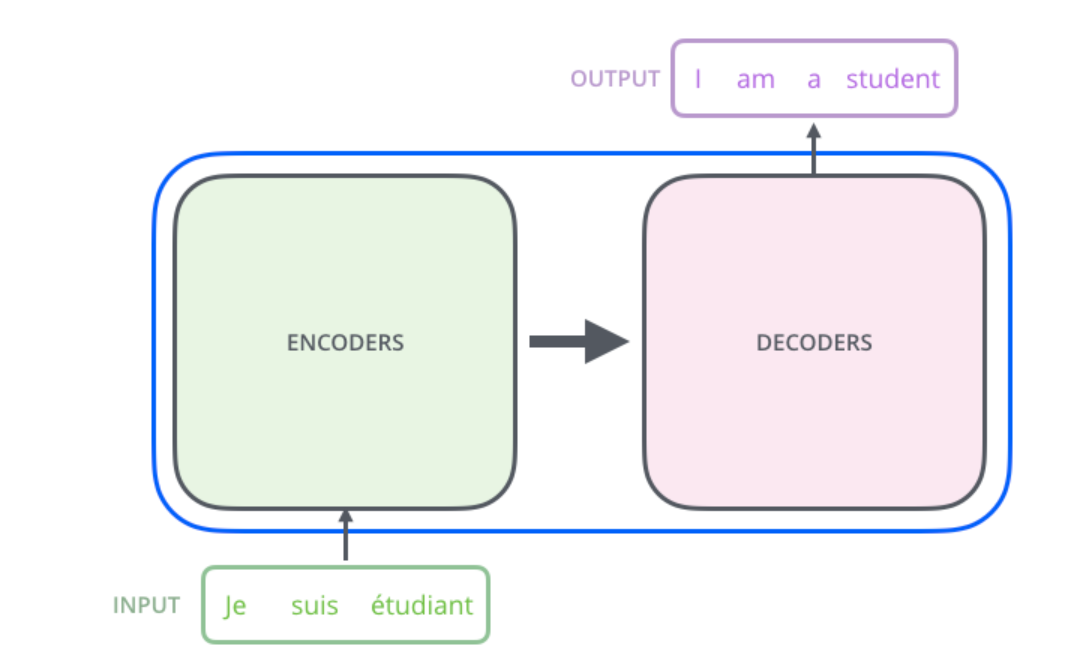
본격적인 트랜스포머 구현에 앞서 다시한번 모델 구조를 정리하고, 하이퍼 파라미터로 무엇들이 있는지 살펴보고자 한다. 전반적인 모델 구조는 이전의 게시물들을 통해 알아보자. seq2seq Encoder-Decoder 구조Encoder와 Decoder를 연결하는 구조 Se
6.BERT - Pre-training of Deep Bidirectional Transformers for Language Understanding
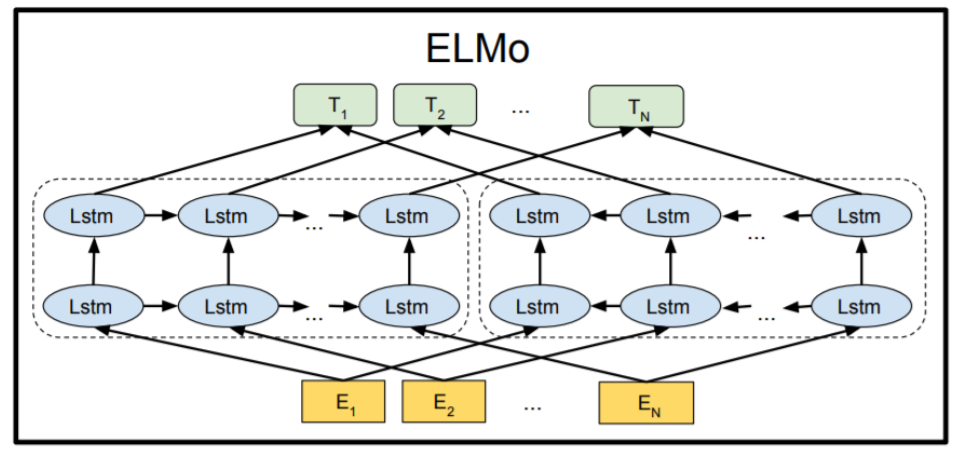
BERT는 대표적인 NLU 태스크에 적합한 pre-trained 모델이다. bert는 양방향 인코더를 활용해 레이블이 없는 자연어를 학습시켜 단순하게 마지막에 가까운 레이어만 fine tuning하면 당시 QA 등의 다양한 SOTA를 달성할 수 있었다. BERT는 현재
7.[GPT-1] Improving Language Understanding by Generative Pre-Training
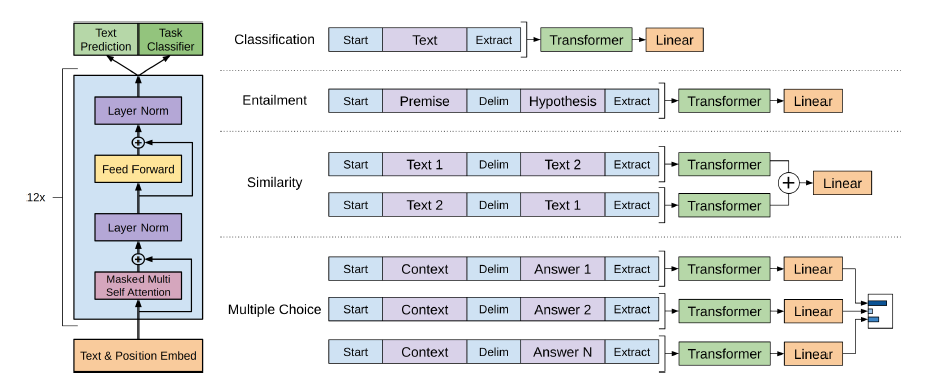
최근 몇년간 NLP를 휩쓴 모델 두 가지만 이야기해보라고 하면 단연 GPT 시리즈와 BERT를 꼽을 것이다. BERT는 특유의 NLU 친화적인 모델구조로 인해 다양한 태스크에 쉽게 적용될 수 있어 무척 많은 연구들이 쏟아져 나왔다. 이에 비해 GPT의 경우 OpenAI
8.[GPT-2] Language Models are Unsupervised Multitask Learners
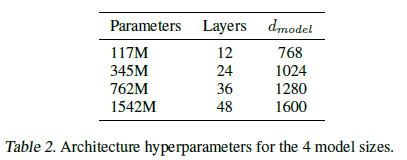
GPT-1의 마지막 파트를 살펴보면 pretrain된 모델이 downstream task에 대해 학습되지 않은 상태에서 각 태스크에 대해 어느 정도의 성능을 보이는지 측정한 파트가 있다. 매우 단순하게 pretrain이 실제로 다양한 downstream task를 수행
9.Linear Transformer
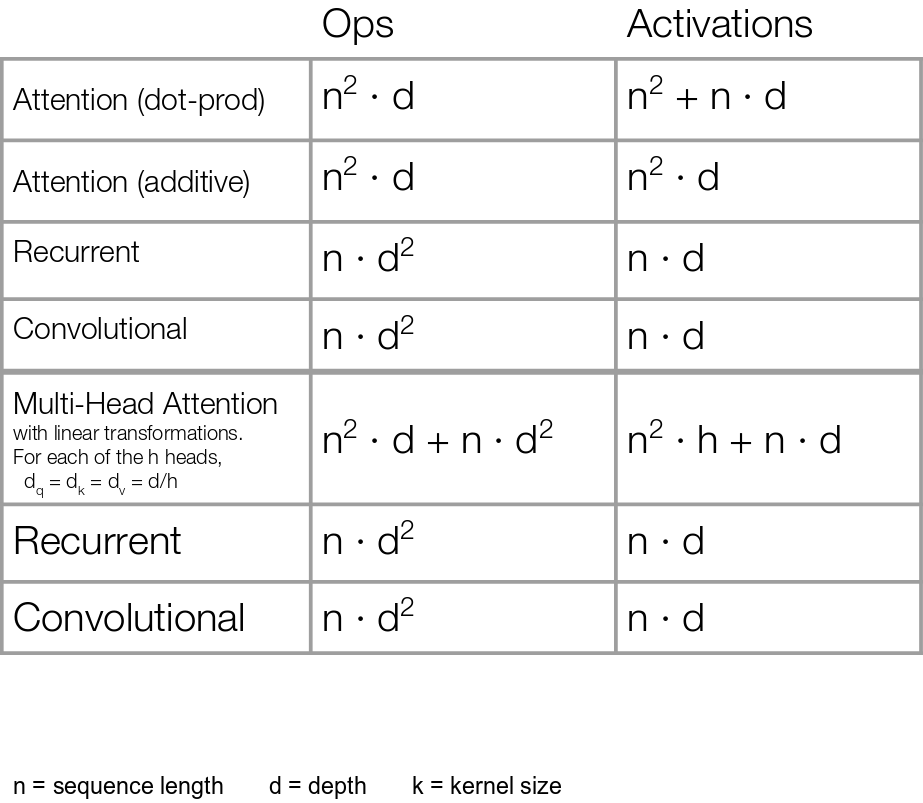
투빅스 컨퍼런스 주제로 무려 pretrain 모델 만들기를 선정했다... 아직도 이게 맞나 싶긴 하지만 gpu 충분하고 다들 충분히 모델이나 관련 지식이 충분하니까 학부생으로서 할 수 있는 가장 좋은 프로젝트가 될 수 있지 않을까 싶다. 모델의 컨셉은 긴 시퀀스를 입력
10.Contextual Embedding - How Contextual are Contextualized Word Representations?

오늘 살펴볼 논문은 How Contextual are Contextualized Word Representations? Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings 라는 논문이다. 이름이 무척 긴데, 사실 이
11.[GPT-2] Language Models are Unsupervised Multitask Learners
GPT-1의 마지막 파트를 살펴보면 pretrain된 모델이 downstream task에 대해 학습되지 않은 상태에서 각 태스크에 대해 어느 정도의 성능을 보이는지 측정한 파트가 있다. 매우 단순하게 pretrain이 실제로 다양한 downstream task를 수행
12.[TAPT, DAPT] - Don't Stop Pretraining. Adapt Language Models to Domains and Tasks.

BERT와 GPT 이후에 수많은 사전학습 모델이 쏟아져 나왔다. 제각기 다른 데이터셋과 다른 목적함수, 모델 구조를 가지고 학습이 되었지만 한가지 동일한 것이 있었다. Pretrain -> Finetune으로 이어지는 프레임워크였다. 이는 사전학습 시에 가능한 대량의