QA
이번 수업에서 다룰 태스크는 Question & Answering입니다.
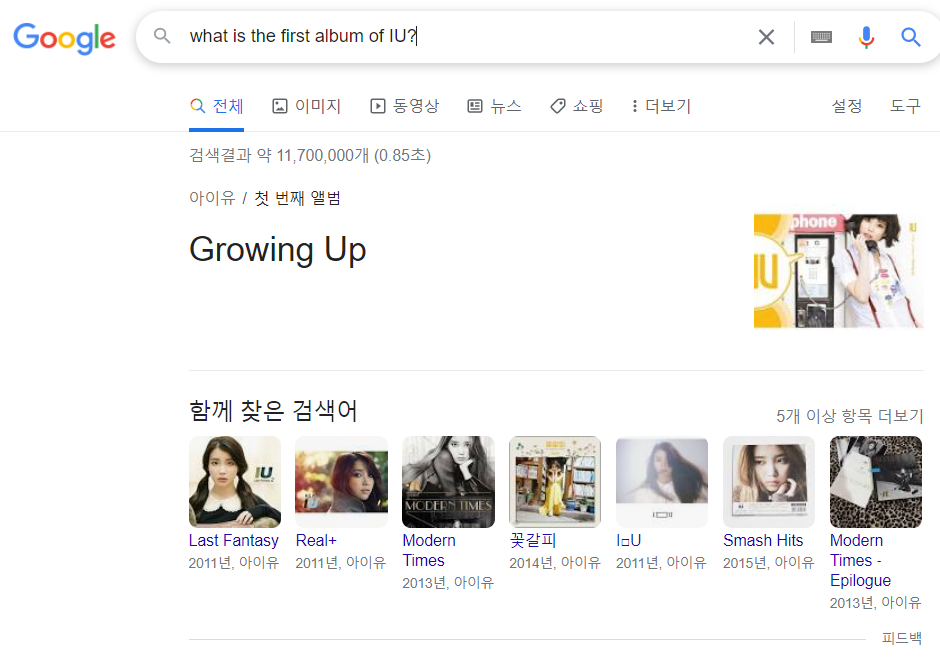
구글에 What is the first album of IU? 라고 검색하면, 아이유의 첫 앨범을 보여줍니다. 질문에 대한 해답을 보여주는 해당 칸은 단순히 입력된 쿼리와 비슷한 페이지를 찾아주는데 그치지 않습니다. 웹 페이지에서 관련 정보를 찾고 이를 요약해서 정확히 필요한 정보를 제시하고 있습니다. 이렇게 질문과 상응하는 해답을 내놓는 것을 QA라고 합니다.
0. Motivation
인터넷에는 수많은 정보가 있습니다. 보다 구체적으로 이야기해보자면, 네이버나 다음과 같은 포털 사이트, 오유나 여성시대와 같은 온라인 커뮤니티, 각종 대학교 사이트, 개인이 운영하는 사이트까지 수많은 웹 페이지가 산재해있습니다. 이러한 상황에서 QA는 다음과 같은 특징을 가지게 됩니다.
- QA는 그 중에서 가장 관련성이 높은 사이트를 반환하는 것을 의미합니다.
- 보통은 제시된 질문에 대한 해답을 목표로 합니다.
- 모바일이나 알렉사, 구글 어시스턴트와 같은 웹페이지를 제대로 제공하기 힘든 환경을 전제하고 개발합니다.
QA는 크게 두가지로 분류해볼 수 있습니다.
- 해답을 포함하고 있는 사이트나 문서를 찾는 것.
이는 기존의 검색 사이트에서 제공하고 있는 내용입니다. - 정답을 한 문단이나 문서로 찾아내는 것.
최근에는 medium이나 velog 처럼 하나의 웹페이지가 방대한 양의 정보를 담고 있어서, 이를 해답이라고 보기 어려운 경우들이 있습니다. 이때 해답을 한 문단이나 문서로 축약할 필요가 있습니다.
0-1. Dataset
2015 ~ 2016년 딥마인드 팀이 처음으로 질의응답 데이터셋을 배포합니다. 이후 가장 널리 사용되는 SQuAD 데이터를 비롯한 다양한 데이터셋이 개발되었다고 합니다. 이러한 데이터셋이 중요한 이유는 딥러닝을 비롯한 머신러닝 분야에선, 데이터가 충분히 확보되어야 유의미한 성능을 낼 수 있습니다. 그리고 충분한 데이터 셋을 만드는 것은 최근에 와서야 웹에 다양한 정보들이 축적되면서 가능해졌습니다. 실제로 SQuAD 데이터셋은 위키피디아 데이터를 기반으로 크라우드 소싱을 통해 개발되었습니다. 위키피디아나 크라우드 소싱 모두 활발한 웹 활동을 기반으로 만들어진 개념입니다.
0-2. Machine Comprehension
그래서 우리가 지금부터 살펴볼 질의응답이란 정확히 무엇을 해야 하는 걸까요? 우선, 컴퓨터가 문장을 이해하도록 만들고자 하는 것입니다. 국어과목 수능이나 모의고사에는 제시문과 일치하는 항목을 찾는 문제가 있습니다.

이런 식으로 제시문이 주어지고, 제시문의 정보와 보기의 정보가 일치하는지 고르는 문제이다. 이 문제를 풀기 위해선 우선 제시문을 이해해야합니다. 컴퓨터가 만약 위의 제시문을 이해하고 옳바른 정답을 고를 수 있다면, 사람과 동일하게 질문과 제시문을 이해하고 관련된 정보를 제공하는 문장을 생성할 수 있지 않을까요?
0-3. History of Open Domain QA
제한되지 않은 도메인에서의 QA는 다음과 같은 발전을 겪었습니다.
- Simmons et al. 1964
초창기의 QA는 의존 구문 분석을 통해 제한적으로 이루어졌습니다. 질문의 의존 구문을 분석하고 이에 매칭되는 답변을 찾는 방식이었습니다. - Murax 1993
최초로 웹페이지의 정보를 활용한 QA는 1993 Murax로 구현되었습니다. 당시 온라인 백과사전에서 정보를 수집했다고 합니다. 이 당시에 정보처리 방법론 자체는 단순해서 정규표현식 등을 활용했다고 합니다. - NIST TREC QA 1999
대량의 코퍼스를 활용한 시도는 미국에서 1999년에 있었습니다. - IBM's Jeopardy 2011.
2011년 IBM은 Jeopardy 퀴즈를 푸는 모델을 개발했습니다. - DrQA 2016
기존의 QA 시스템은 당연히 복잡할 수 밖에 없습니다. 이를 인공신경망을 이용해 단순화 시킨 것이 DrQA입니다.
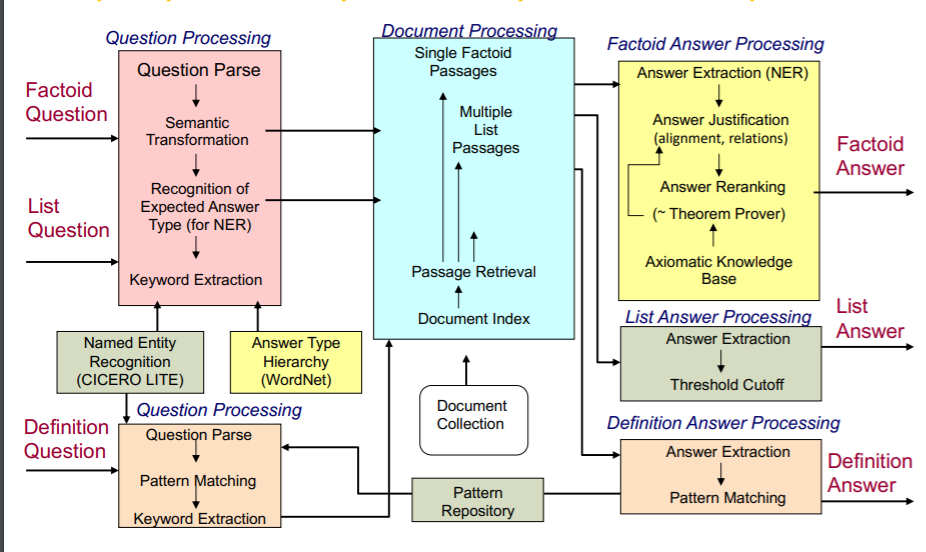
이전의 시스템은 위와 같이 다양한 하위 시스템들로 구성되어 있습니다. 각각의 하위 요소가 개별적으로 개발되고, 이를 통합하여 성능을 높이려 한 것입니다. 하지만 이와 대조적으로 NN을 이용한 QA는 좀 더 단순한 형태를 취하고 있습니다.
1. SQuAD
SQuAD에 대해 조금만 더 살펴보도록 합시다. SQuAD는 다음과 같은 데이터를 가지고 있습니다.

질문과 질문에 답하기 위해 필요한 정보가 담긴 passage가 있습니다. 해당 질문의 정답은 Denver Broncos로 passage 안에 직접적으로 담겨져 있습니다. 즉, passage에는 정답이 직접 주어져있습니다. 모델은 질문을 이해하고 정답에 해당하는 연속된 단어를 passage에서 추출해야합니다.
이때 인간의 답변은 어느정도 자율성을 가질 수도 있습니다.

위와 같이 동일한 질문에 대해 어떤 사람은 independent라고 하기도 하고, 다른 사람은 independent schools라고 하기도 합니다. 이에 대해 SQuAD는 3명의 답변을 실어놓음으로써 어느정도 사람의 답변에 대한 강건한 모델링이 가능하도록 합니다.
1-1. Evaluation
그렇다면 어떻게 QA에서 모델의 성능을 측정할까요? 두가지 방법이 있습니다.
-
정확도 : 만약 모델이 생성한 답이 세가지 인간의 답 중 하나와 동일하다면 1 point로, 세가지 인간의 답과 일치하지 않는다면 0 point로 하여, 전체 문제에 대한 평균을 구하는 것입니다. 즉, 전체 문제 중 몇 문제를 맞췄는지 측정하는 것이라 할 수 있습니다.
-
f1 score : 하지만 인간이 만든 답변은 유동적일 수 밖에 없습니다. 분류나 회귀처럼 절대적인 답이 정해져있지 않기 때문에, 인간이 생성한 답변과 조금 다르다 하여서 모델이 제대로 답변하지 못한 것이 아닐 수도 있습니다. 이를 반영하여 f1 score를 적용합니다. 통계에서 f1 score는 imbalance 상황에 사용하는데 초점이 맞추어져 있지만, 여기선 recall과 precision의 조화평균이라는 점에 초점이 맞추어져 있는 것 같습니다. 예측값에서의 정확도(precision)과 실제 인간의 답변에서의 정확도(recall) 간의 조화 평균이 좀 더 설득력이 있다고 보는 것입니다. 방법은 다음과 같습니다. 1) 각 답변과 예측값 사이의 f1 score를 측정한다. 2) 최대값을 해당 질문의 f1 score로 정한다. 3) 모든 질문의 f1 score를 평균내어 사용한다. 이를 통해 사람들이 만든 해답의 길이에 조금 자유로워지게 됩니다.
-
또한 성능 평가 시 a, an, the와 같은 관사나 구두문자는 제외합니다.
인간의 경우 SQuAD 1.1에 대해 82%의 정확도와 91.2 정도의 f1 score를 기록했습니다. SOTA인 bert ensemble의 경우엔 87%의 정확도와 93 f1 score를 기록했습니다... 인간보다 낫네요. 하지만 사실 인간에겐 불리한 지표였습니다. 인간은 다른 두 사람이 답변한 해답만 가지고 지표가 측정되었으니까요.
1-2. SQuAD 2
SQuAD 1.1에는 문제점이 있었습니다. 모든 질문엔 답이 있었습니다. 즉, 모델은 그저 그럴듯한 답변을 생성해내기만 하면 됐습니다. 실제로 질문과 passage를 이해하지 않고, 각 단어들의 랭킹을 세우기만 해도 풀리는 문제였습니다. 하지만, passage와 질문이 전혀 다른 이야기를 하고 있다면 어떨까요?
이를 고려하여 SQuAD 2.0이 개발되었습니다. 훈련 데이터의 1/3은 해답이 없는 passage였고, 검증과 테스트 데이터의 1/2가 해답이 없는 passage였습니다. 즉, passage를 보고는 질문에 답을 할 수 없는 경우였습니다. 이러한 경우에 해답은 NoAnswer과 같은 특정 토큰이었습니다. 모델이 해당 토큰을 예측하면 정확도와 f1 score 모두 1을 받고, 다른 어떠한 토큰이라도 반환한다면 0점으로 채점되었습니다.
이렇게 문제를 조금 비틀어놓으니, 모델들이 가지는 문제점이 명백해졌습니다. 인간과 유사한 성능을 보이던 모델들도 전혀 문장들을 이해하지 못하고 있던 것입니다.

위 문제에서 1234라는 숫자는 the Mongols destroyed the weakened Jin dynasty in 1234에 등장합니다. 아마 모델은 이 문장에서 destroy가 kill과 비슷하기 때문에 1234를 예측한 것 같습니다. 하지만 위 문제는 NoAnswer일 뿐입니다. 모델이 여전히 연속된 토큰들의 랭킹을 매기는 일에 지나지 않는다는 것을 보여줍니다.
이는 SQuAD 1.1에서 좋은 성능을 보이던 모델들이 단순히 예측 값에 threshold를 적용하는 등의 일부 수정을 하고 SQuAD 2.0을 풀었을 때 정확도가 20%p 넘게 떨어지는 결과를 보여줍니다. 전반적인 문제가 어렵지 않음에도 불구하고, 모델 성능은 매우 떨어진 것입니다.
이후에 bert 등의 모델이 SOTA를 보이면서 인간과 비슷한 성능을 보이고 있지만, 여전히 여러 단어가 복잡하게 등장하면 제대로 문제를 풀지 못하는 모습입니다.

위에서 여러 왕조가 반복적으로 등장하면서 모델을 헷갈리게 한 것 같습니다. 그 결과 인간은 following the Song dynasty만 보고 song dynasty라고 답하겠지만, 모델은 수많은 단어의 랭킹을 매기다 보니 여전히 잘못된 답변을 보였습니다.
1-3. Limitation
- 연속된 단어를 찾는 태스크일 뿐이다.
실제 질문과 답변을 하는 상황을 생각해보자. 이땐 문장과 일치하는 답변 뿐만 아니라 yes or no나 몇 개인지 세기, 이유 답변 하기 등 다양한 질문이 나오게 된다. 하지만 SQuAD는 문장과 일치하는 것만을 찾는 태스크였다. - 전적으로 passage에 의존했다.
SQuAD를 하는 모델들은 그저 단어들의 의미와 구조를 파악하고 이를 이용해 질문과 passage의 정보에서 답변을 추출할 뿐이다.
하지만 그럼에도 불구하고 SQuAD는 적절한 난이도를 가지고, 적절히 깨끗한 데이터로 QA를 할 수 있다는 점에서 그 의미가 있따고 한다. 특히 다른 도메인에서 QA를 구성할 때, SQuAD를 시작점으로 삼을 수 있다고 한다.
2. Stanford Attentive Reader
DrQA 혹은 Stanford Attentive Reader를 통해 어떻게 NN이 QA에 사용되는지 살펴보도록 하자.
2-1. Representation of a Question
우선 질문을 벡터화하여 보자.
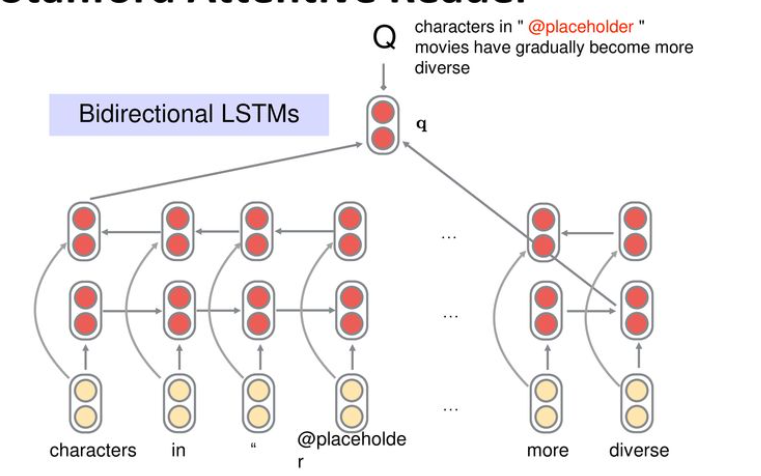
질문의 각 토큰을 Glove를 이용해 300차원 임베딩 벡터로 전환한 후 BiLSTM에 통과시킨다. 이후 양쪽 끝 시점의 hidden state를 concatenate하여 질문의 벡터로 사용한다. 수업을 들으면서 조금 갸우뚱했던 것이 이것만으로 충분히 문장이 벡터화된다는 것인데.. BiLSTM이 이렇게 강력한가 싶다. 이제는 트랜스포머의 인코더 등이 훨씬 강력할 것 같다.
2-2. Representation of a Passage
passage 역시 똑같은 과정으로 벡터화한다. 다만, 우리는 passage에서 어떠한 부분이 답변에 해당하는지 찾아야한다. 그래서 hidden state를 뽑지 않고 모든 시점의 hidden state를 이용하게 된다.
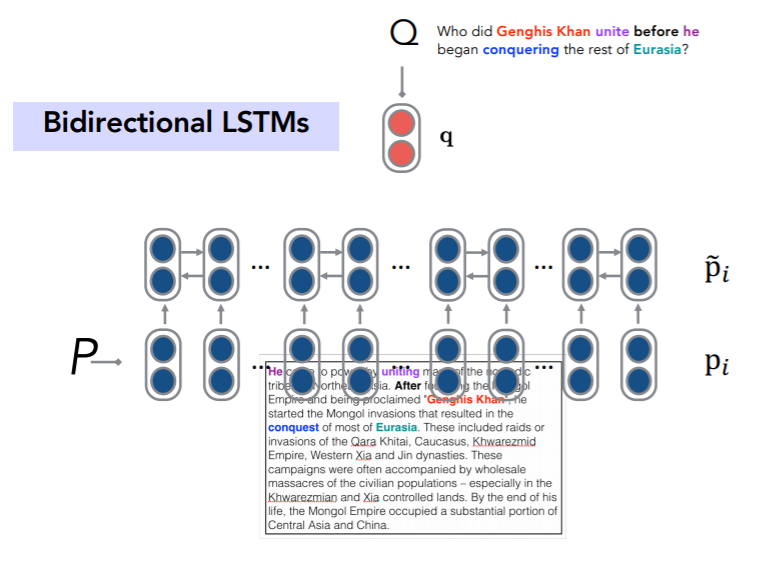
2-3. Attention
passge의 hidden state과 question 벡터를 attention 알고리즘을 사용하여 계산한다. 이때 vanilla attention?을 사용하지 않고, question 벡터를 passage 벡터로 맵핑하는 1층짜리 DNN을 쌓는다. 굳이 DNN이라 할 것 없이 question 벡터에 대한 선형 변환 후 passage의 각 hidden state와 내적한다고 표현해도 될 것 같다. softmax를 통해 attention score를 구하고 이를 이용해 start 토큰을 구하게 된다. 또한 다른 W 행렬을 통해 end 토큰을 구한다. start와 end 토큰을 구하는 과정에서 다른 점은 이용하는 W 행렬이 다른다는 점이다.
사실 답변에서 중요한 부분은 가운데 단어일 경우가 많을텐데 어떻게 start와 end 토큰만 잡아내서 답변을 생성할 수 있는 것일까? 이는 Passage가 BiLSTM으로 처리되기 때문에 가능한 것이다. 모델이 잘 학습되었다면, 양 방향에서 흘러오는 정보로 이 단어가 이전과 다른 의미 영역을 가지고, 답변에 해당하는 단어의 시작점임을 잘 나타낼 수 있는 hidden state가 만들어지게 된다는 것이다. 교수님 말대로 It's neural network, you have to do.
3. Stanford Attentive Reader++
더욱 발전된 모델이다.
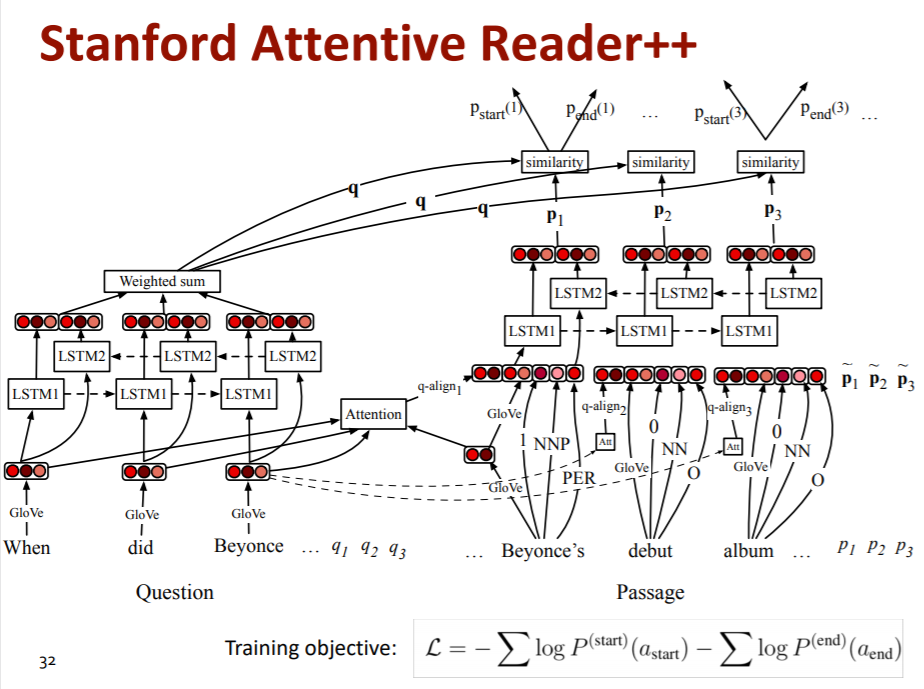
위와 같이 복잡하게 생긴 것 같은데, end-to-end 모델이라고 한다. 이를 구현하기 위해 손실함수는 오른쪽 아래에 보이는 것처럼 실제 start 토큰과 end 토큰이 생성되어야 할 지점의 attention dist 값이다.
여기서는 이전의 Stanford Attentive Reader 모델과 달라진 점만 다루도록 하자.
3-1. Attention in Question
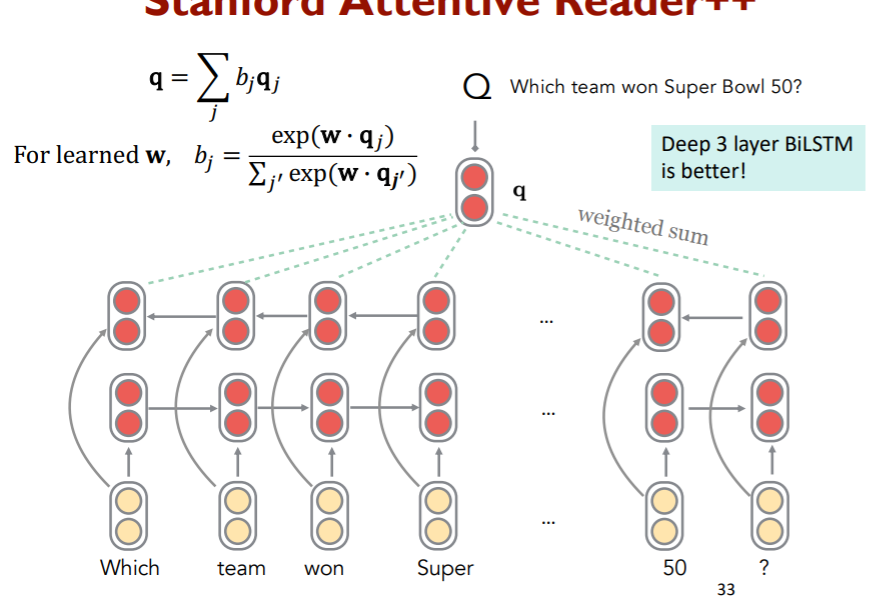
이전에는 Question의 각 양끝 시점의 hidden state만 사용했지만, 당연하게도 모든 시점의 hidden state을 사용하는 것이 좋을 것이다. 이를 위해 attention 매커니즘을 도입했다. 하지만 어떤 벡터와 유사도를 비교할 것인가?라는 문제점이 남아있다. 아직도 이게 된다는게 믿기지 않는데... 그냥 임의의 랜덤 벡터 q를 만들고, 이를 학습에 사용했다. nn이 모든 것을 학습을 통해 해결한다지만 이런 것까지 가능하다는게 이상하다. 그리고 q 벡터와 모든 hidden state 벡터를 attention을 통해 가중합하여 Question에 대한 최종 벡터를 만들었다.
3-2. Deep Bi-LSTM in Question
당연하지만 레이어가 깊어졌다. 논문을 봐야알겠지만, 이전엔 1층만 사용하다가 여기서 3층을 사용할 수 있었던 이유가 있을까? attention으로 vanishing gradient에서 조금 자유로워져서인가?
3-3. Passage
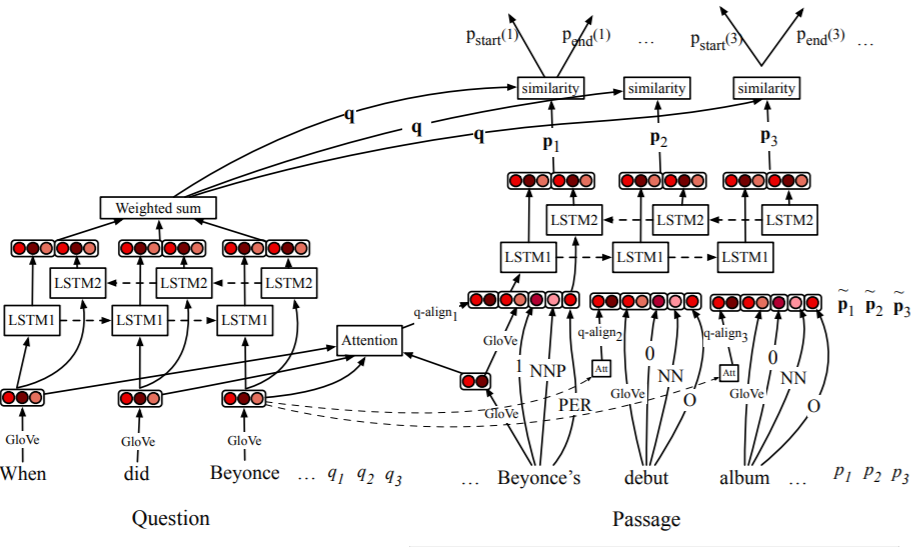
위 그림을 다시 한번 보자. passage는 정말 여러 단계를 거치게 된다.
우선 passage의 입력 벡터가 무엇이 쓰이는지 살펴보면 다음과 같은 것이 사용된다.
- glove의 300차원짜리 워드 임베딩
- POS와 NER 식별을 위해 작은 모델을 삽입하고 이 결과 나오는 ont hot vector
- term frequency
- 해당 토큰이 question에서 1)exact 2)none 3) lemma(형태 변화)를 통해 매칭되는지 여부에따른 bit
- passage의 토큰의 임베딩 벡터와 question의 토큰들의 임베딩 벡터를 1층짜리 hidden layer에 통과시킨 후 attention 매커니즘을 통해 구한 soft alignment(이 부분은 번역 태스크 수업에서 다룬 바 있다.)

위와 같이 5가지 종류의 벡터 혹은 스칼라가 concatenate되어 최종 입력값으로 사용된다.
3-4. Why Neural Networks works better?
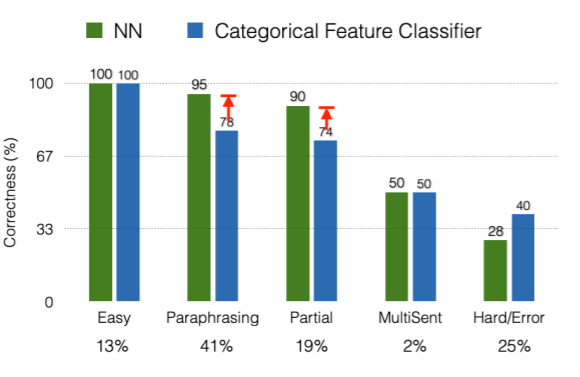
위에서 소개한 단순한 nn 기반 모델마저도 로지스틱 회귀 기반의 모델보다 무려 30%가량 성능이 개선된 모습을 보인다. 왜 그런것일까? 단순 로지스틱 회귀 모델이나 다른 수많은 전통적 기법의 모델들은 심지어 수많은 전문가들의 언어적 지식과 통계, 컴퓨터 과학의 지식에 기반을 둔 시스템인데도 불구하고 말이다. 위의 표가 약간의 해답을 제공해주지 않을까 싶다. 단순 nn 모델이 더 잘하는 부분은 언어를 이해하는 부분이다. 즉, 매닝 교수님은 어디에서 태어났나요? 라는 질문에 대해 passage에선 매닝 교수님의 출생지는 캘리포니아입니다. 라는 문장이 있을 때, nn 모델은 "태어나다"라는 단어와 "출생지"라는 단어가 의미적으로 유사하다는 것을 스스로 캐치한다. 전통적인 모델들은 이를 위해 인간이 어떠한 방법론을 통해 매치해야했다는 것과 비교하면 훨씬 유연한 방법이 되는 것이다.
4. BiDAF
위에서 나온 Stanford Attentive Reader는 좀 단순한 모델이다(내가 보기엔 그렇지 않지만 교수님은 그렇다고 하신다). 좀더 어텐션을 활용하고 성능이 좋으며 복잡한 모델도 한번 보도록 하자.
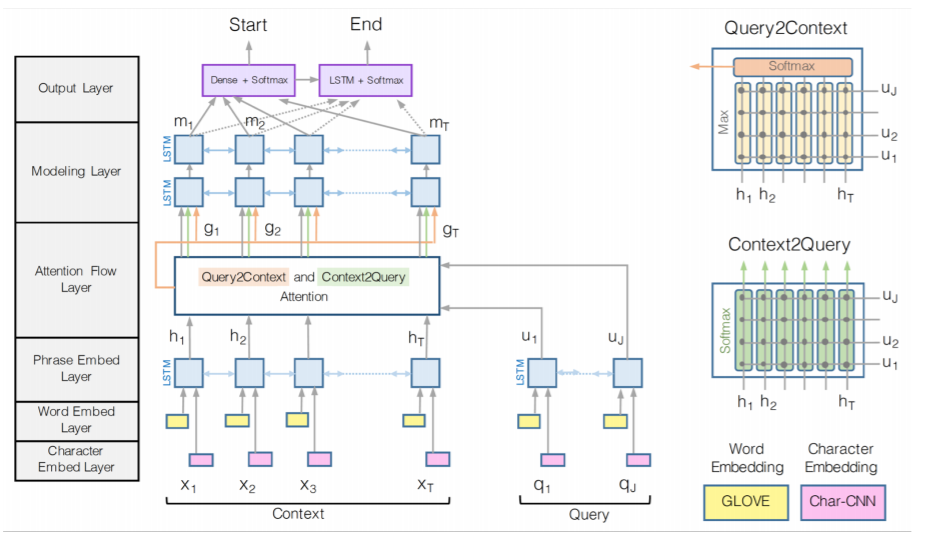
위의 도표가 BiDAF 모델의 전체 구조이다. 전반적으로 Stanford Attentive Reader의 구조를 참고했다고 한다. 여기서도 역시 차이점에 대해서만 살펴보자.
4-1. Input
여기선 특이하게 두가지 임베딩을 사용하고 있다. 이전에 사용하던 word level embedding과 더불어 character level embedding을 사용하고 있다. 요새 드는 생각엔 한국어도 음절단위로 문자가 사용되는데, 이를 임베딩하면 좀 더 언어적 특징을 잘 캐치하지 않을까 싶은데, 영어는 어차피 알파벳 단위로 구성되니 알파벳 단위로 임베딩한 것이다. 그리고 question과 passage 모두 BiLSTM에 넣고 hidden state을 구한다.
4-2. Attention Flow
BiDAF의 핵심 아이디어는 어텐션이 question에서 passage를 비교할 뿐만 아니라 passage에서 question을 비교해야 한다는 것이다. 즉, 양 방향으로 attention을 비교하는 것이다. 이것이 모델의 가운데 있는 query2context와 context2query다. (query가 passage, context가 question이다.)
그리고 이러한 attention score를 S 행렬을 통해 표현한다.
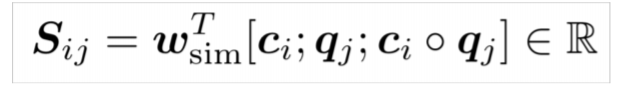
위의 식이 S 행렬의 하나의 element를 구성하는 식인데, 보면, passege에서 온 hidden state, question에서 온 hidden state, question과 passge에서 온 hidden state의 아다마르 곱으로 구성되어 있다. lstm에서 이미 접한 아다마르 곱이지만, 교수님의 설명은 조금 달랐다. 아다마르 곱은 element-wise product이다. 즉, 모델에게 직접 두 개의 representation에서 여러 차원의 유사도를 비교하도록 해주는 역할을 한다고 한다. 물론, 모델이 이를 학습하도록 만드는 것이 목표이지만 종종 직접 이를 내부적으로 구현하는 것이 더 효과적일 것이다. 예전에 시계열 모델링할때, ma 등의 값을 직접 구해서 변수로 삽입했더니 성능이 좋아진 것과 일맥상통하는 부분일 것이다.
그리고 위에서 언급한 세 가지 벡터()를 weight matrix(선형 변환하는거다)에 곱하여 attention score를 구하게 된다.
이때, 양방향으로 attention을 비교한다고 했으니 S 매트릭스를 두개의 축 모두에서 softmax를 취하고, 이를 question이나 passage의 hidden state에 곱하여 사용하게 된다.
아래 식은 context2question attention이다.
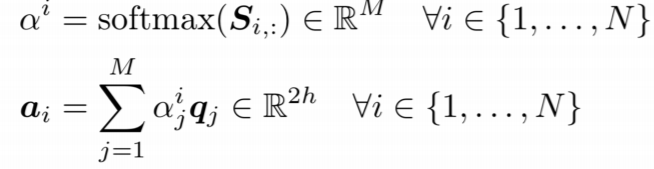
하지만 question2context에선 조금 다르게 진행이 된다. 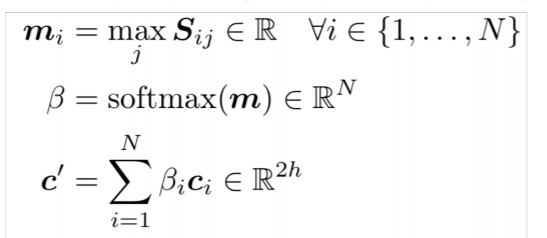
말로 설명해보자면, passage의 i번째 토큰의 attention score는 i번째 토큰과 question의 토큰의 어텐션 값 중에 가장 큰 값을 선택하게 된다. 즉, passage의 i번째 토큰과 가장 유사한 question의 토큰과의 어텐션 값이 passage의 i번째 토큰의 유사도가 되는 것이다. 이를 다시 passge의 어텐션 분포로 사용하여 softmax에 통과시킨 후 최종 벡터를 구하게 된다. 의미적으론, passage의 토큰들이 question에서 얼마나 유의미하게 비슷한지 그 정도를 보겠다는 것 같다. 결국 passage의 모든 토큰이 question에 등장하지는 않으니(역은 성립한다. passage가 더 길고 questioin은 passage의 내용을 뽑고자 하니깐), question에 등장한 passage의 내용을 뽑고자 하는 것 같다.
이렇게 만들어진 벡터들을 한번 정리해보자.
- : passage의 각 토큰들의 lstm 레이어 속 hidden state 벡터
- : question 토큰과 passage 전체 토큰 간의 attention 매커니즘을 이용해 구한 question에 대한 attention vector
- c' : passage 토큰과 가장 유사한 question 토큰과의 attention을 통해 구한 attention vector
그리고 이를 다시 아다마르 곱 등을 이용해 concatenate 시켜주면 최종적인 입력값이 완성된다.
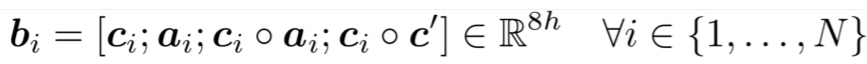
그리고 이후엔 passage의 hidden state를 다시 최종 BiLSTM의 입력값으로 넣는 등의 작업이 남아있다.
4-3. attention variation
기본적인 어텐션은 다음과 같은 내적이다.
이를 변형하여 비선형 레이어를 추가할 수도 있다.
하지만 이러면 연산량이 너무 많아지니까, 선형 변환만 할수도 있다.
그런데 선형변환 = 행렬을 곱하는 것 = 행렬을 분해해서 곱하면 더 계산량이 줄수도...? 의 흐름을 타면 다음과 같은 가중치 행렬의 분해가 가능해진다.
근데 이건 너무 선형적이다... 비선형성이 성능을 개선시킨다는 것을 우리는 알고 있다.
W를 분해하는 것은 행렬 분해 기법을 통해 이룬 것 같은데,,,
ReLU를 추가하는 것이 어떻게 말이 되는지 논문을 봐야 알 수 있을 것 같다.
5. Conclusion
모델이 점점 말도 안되게 복잡해지는 과정을 보는 것이 이번 수업이었지 않나 싶다. 보면서 느낀점은 너무 자세한 부분에 집중하고 이를 통해 성능개선을 이끌어 낸다는 것이었다. 물론 수많은 실험과 연구를 통해 개발된 모델들이겠지만, 아마 트랜스포머라는 거대한 변화 직전이라 더더욱 이렇게 복잡한 모델들이 개발된 것이 아닌가 싶다. 무엇보다 attention의 계산량을 감소하기 위해 고유값 분해나 스펙트럴 분해를 이용한 모습을 본 것 같은데, 선대 공부한게 조금이나마 더 보람이 있어지는 시간이었던 것 같다.
