CS224N
1.[CS224N] Lecture1-Introduction and Word Vectors

투빅스에서 텍스트 세미나에 참여하게 되면서, 스탠포드 대학교의 유명한 자연어 처리 강의인 CS224N을 듣고 리뷰하는 과정을 시작하게 되었다. 다시한번 내가 아는 자연어 처리 내용을 정리하고, 더 많은 것들을 배울 수 있는 좋은 기회인 것 같다. 1주차 내용을 시작해보
2.[CS224N] Lecture 2 - Word Vectors and Word Senses

저번 시간엔 자연어 처리에서 가장 기본적인 입력값(x)이라 할 수 있는 워드 임베딩의 기본적인 개념에 대해서 배웠다. 워드 임베딩의 장점은 명시적으로 보이는 의미 관계뿐만 아니라 단어 간의 복잡한 의미 관계를 벡터 공간에 표현할 수 있다는 것이다. (정확하게는 임의의
3.[CS224N] Lecture 3 - Neural Networks
다중 분류 문제를 푸는 가장 간단한 모델은 아마 소프트맥스일 것 같다. 해당 모델은 다음과 같이 생겼다. $p(y \\mid x) = {exp(W+y, x) \\over \\sum^C\_{c = 1}exp(W_c, x)}$그리고 이를 다시 풀어서 써보면 다음과 같다.
4.[CS224N] Lecture 4 - Backpropagation
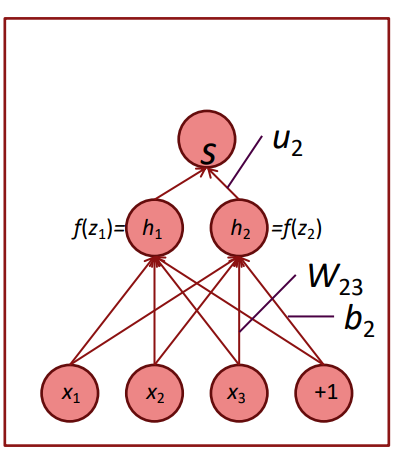
이번 강의에선 역전파 과정을 하나씩 살펴본다. 위와 같은 모델에서 W에 대한 편미분은 다음과 같이 진행된다.${\\partial zi \\over \\partial W{ij}}= {\\partial \\over \\partial W{ij}}(W_ix + b_i)$${\
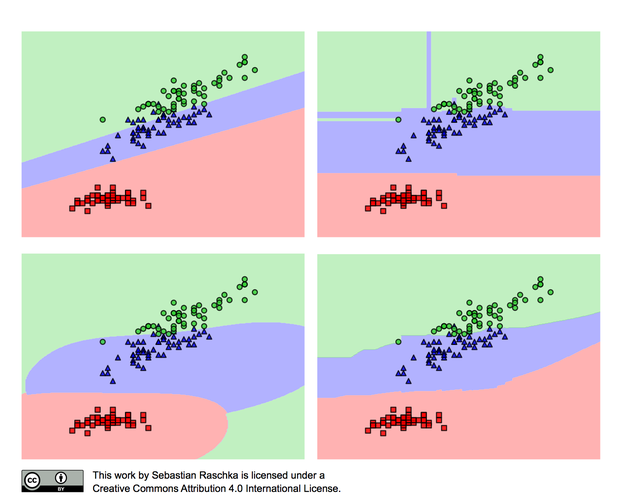
5.[CS224N] Lecture 5 - Dependency Parsing

이번 수업에선 컴퓨터 공학이나 수학에 대한 이야기보단, 인간이 언어를 사용하는 방식에 대해 주로 다루게 된다. 사실 언어마다 구조가 다르기 때문에, 한국어와 영어는 전처리 방식도 다르고, 분석 방식도 달라지게 되는데, 본 강의는 영어를 기준으로 하고 있다. the la
6.[CS224N] Lecture 6 - Language Models and RNNs
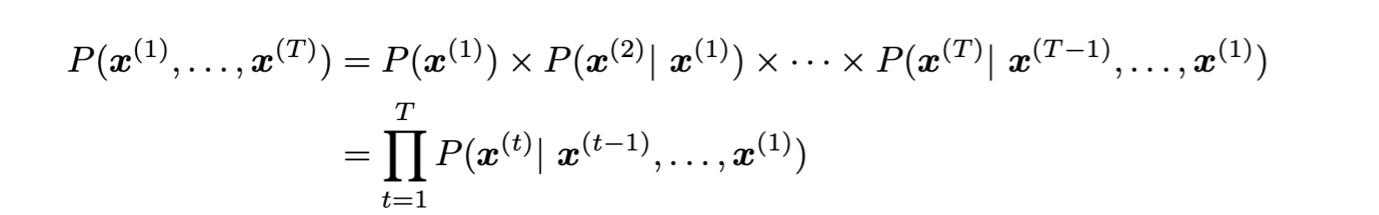
언어 모델링(번역이 맞는지 모르겠다)는 다음에 올 단어를 맞추는 모델을 구축하는 것을 말한다. the students opened their \_\_\_ 위와 같은 문장이 주어졌을 때, 사람은 당연히 books, laptops, exams, minds 등이 문맥 상 올
7.[CS224N] Lecture 7 - Vanishing Gradients, Fancy RNNs
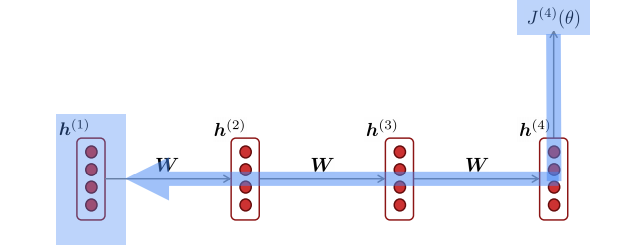
rnn 모델에서 위와 같이 역전파를 시킬 때를 생각해보자. 체인 룰을 이용해 $h_1$에 대한 미분을 계산하면, 다음과 같은 식이 된다. ${\\partial J_4 \\over \\partial h_1} = {\\partial J_4 \\over \\partial h
8.[CS224N] Lecture 8 - Translation, Seq2Seq, Attention
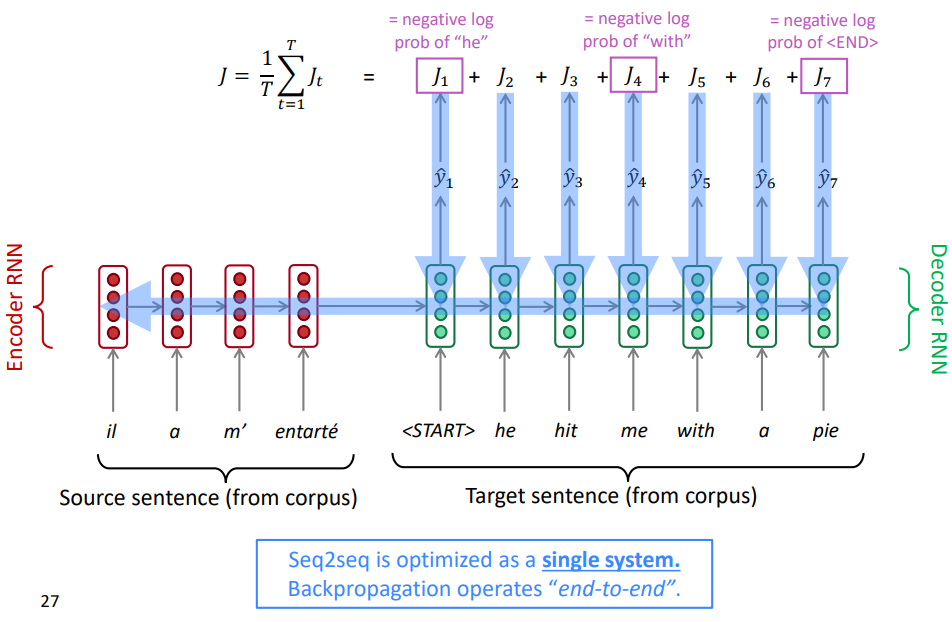
Pre-Neural Machine Translation 기계번역(Machine Translation): 특정 언어의 문장을 다른 언어의 문장으로 번역하는 태스크. 1. Rule Based(1950s) 최초의 시도는 1950년대 초반 러시아어를 영어로 번역하여 냉전에서
9.[CS224N] Lecture 10 - Question Answering
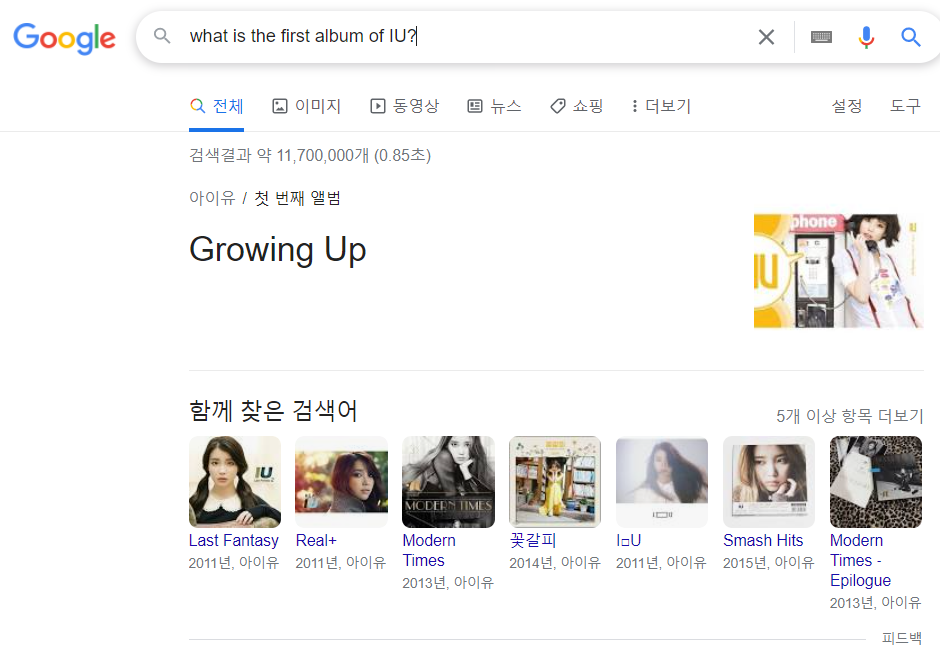
이번 수업에서 다룰 태스크는 Question & Answering입니다. 구글에 What is the first album of IU? 라고 검색하면, 아이유의 첫 앨범을 보여줍니다. 질문에 대한 해답을 보여주는 해당 칸은 단순히 입력된 쿼리와 비슷한 페이지를 찾아주는
10.[CS224N] Lecture 11 - Convolutional Networks for NLP
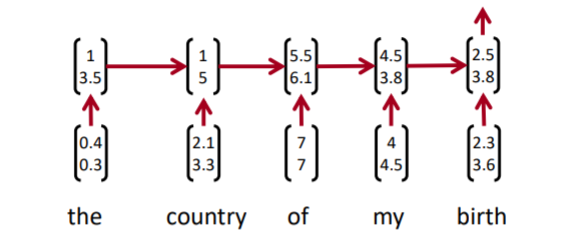
언어는 연속적이라는 가정아래 RNN류 모델들은 hidden state 등을 이용해 이전의 단어들을 고려한 모델링을 한다. 물론 순방향만 의미가 있지는 않으니 역방향으로도 수행하여 BiLSTM 등의 모델들이 존재한다. 여기서 문제가 발생한다. 위와 같은 모델에서 of m
11.[CS224N] Lecture 12 - Subword Models
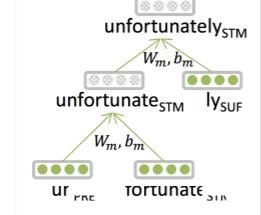
이전의 수업들에선 단어 단위로 입력을 생각했다. 자연어 처리 분야에서 흔히 토큰이라고 부르는 것은 가장 작은 의미의 단위로 영어에선 띄어쓰기 단위로, 한국어에선 형태소 단위로 자르고, 정규화하여 만들어진다. 하지만 언어의 가장 작은 의미의 단위가 실제로 단어 하나일까?
12.[CS224N] Lecture 13 - Contextual Word Embeddings
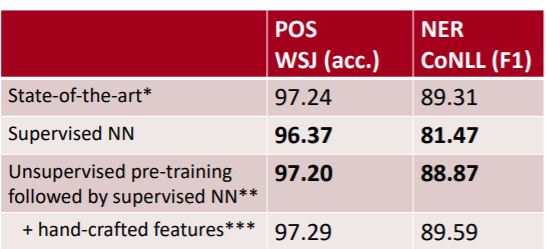
지금까지 배운 내용을 정리해보자면, 2011년 이전까진 NN을 이용한 자연어 처리 기법들은 사실 각광을 받지 못했다. Feature Engineering을 통한 모델들보다 성능이 좋지 못했고, 그럼에도 학습에 오랜 시간이 걸렸기 때문이다. 위 표는 NN을 이용한 모델들
13.[CS224N] Lecture 14 - Transformers and Self-Attention
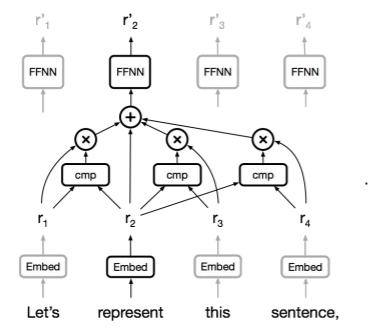
이번 시간엔 외부 강사님이 오셔서 트랜스포머나 self attention의 원리에 대해 설명해주는 시간이었다. 우선은 트랜스포머 이전, 즉 RNN류 모델들의 시대에 대해 이야기해보자. RNN류 모델들은 문장과 같이 입력값의 길이가 가변적인 경우에 효과적으로 작동했다.
14.[CS224N] Lecture 15 - Natural Language Generation
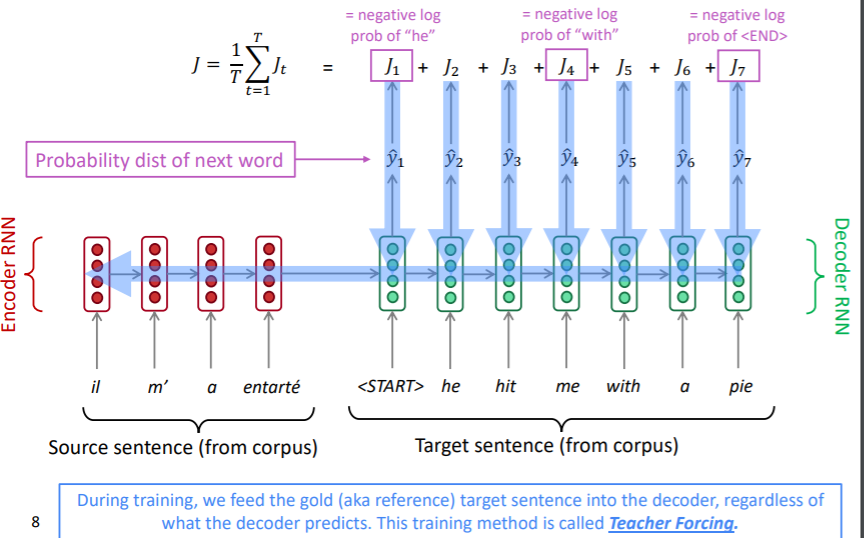
NLG라는게 워낙 넓은 분야이다 보니, 이 강의에선 전반적인 개념과 태스크들, 최근 모델들에 대해 설명하고 있다. NLG는 입력값이 있든 없든, 그 종류가 무엇이든 상관없이 출력으로 텍스트 시퀀스를 만드는 태스크이다. 그래서 NLG는 많은 NLP 분야의 하위 파트로 사
15.[CS224N] Lecture 18 - Constituency Parsing, TreeRNNs

딥러닝이 각광받기 시작하면서 BOW 모델들이 많이 개발되었다. 이 모델들은 모두 단어 벡터를 가지고 입력값과 hidden layer, 출력값을 다루게 된다. 하지만 딥러닝 이전에는 언어학적 지식이 CS 분야에 많이 활용되었다. 촘스키 위계를 이용하거나 여러 문법적 구조