0. The problem of Sequential Modeling
언어는 연속적이라는 가정아래 RNN류 모델들은 hidden state 등을 이용해 이전의 단어들을 고려한 모델링을 한다. 물론 순방향만 의미가 있지는 않으니 역방향으로도 수행하여 BiLSTM 등의 모델들이 존재한다. 여기서 문제가 발생한다.
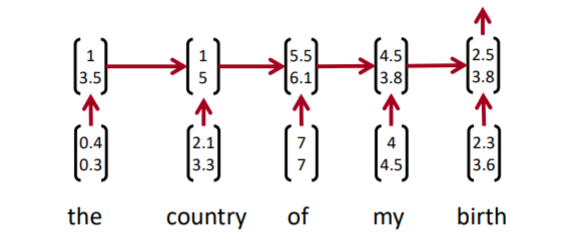
위와 같은 모델에서 of my birth라는 단어의 representation을 얻고 싶다고 하자. 어느 hidden state을 가져와야 하는가? 모호하다. of, my, birth 어느 시점의 hidden state도 이를 가지고 있지 않기 때문이다. birth의 hidden state는 문장의 처음부터 정보를 가지고 있고, 이마저도 birth의 정보를 제일 많이 가지게 된다. 즉, 각 문장의 하위 요소들에 대한 정보를 가지고 올 방법이 RNN류 모델엔 없다.
attention 매커니즘을 사용해도 마찬가지이다. hidden state은 결국, 모든 이전 시점의 정보를 포함하고 있기 때문에, 우리가 원하는 특정 시점들의 representation만 가져올 수 없다. 그래서 CNN을 사용하게 되었다.
1. CNN
1-1. Basics
CNN은 본래 이미지나 음성에 적용되던 모델이다. 필터니, 스트라이드니, 패딩이니, 채널이니 하는 CNN의 기본적인 요소들은 이미 알고 있다는 가정 하에 여기선 조금만 설명해보자.
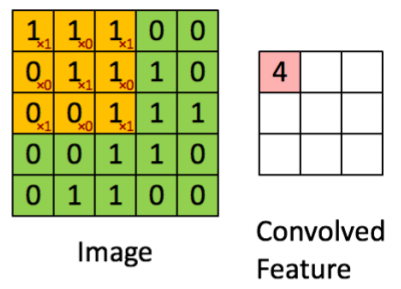
CNN은 동일한 weight를 슬라이드하면서 행렬에 곱하는 것이 핵심이다. 이미지에선 똑같은 이작은 요소라도 이미지 내의 위치, 회전, 밝기 등에 따라 다르게 표현된다. 그리고 하나의 필터는 하나의 특징을 잡아내는 역할을 한다. 어떤 필터는 대각선을, 어떤 필터는 밝은 색을, 어떤 필터는 원형을 잡아내는 식이다. 그래서 하나의 이미지에 하나의 필터가 통과하여 만들어지는 행렬은 그 이미지가 해당 특징을 어느 정도로 가지고 있는 지에 대한 일종의 분포라고 할 수 있다(우연히도 저번 주 김광수 교수님의 사회과학과 인공지능 수업에서 해당 설명이 있어서 처음 들을 수 있었다. 이전엔 깊게 생각해보지 않았는데, 정말 맞는 말인 것 같다.). 그래서 하나의 이미지에 다수의 필터를 적용하게 된다. 하나의 필터는 하나의 특징 맵을 만들게 되고, 여러 개의 특징 맵이 묶여서 새로운 채널을 이루게 된다. 즉, 하나의 이미지에 여러 필터가 통과되어 나온 특징 맵들은, 해당 이미지가 가지고 있는 특징들의 표현이다.
1-2. CNN for NLP
1-2-1. Filters
문장을 이미지로 보려면 어떻게 해야할까?
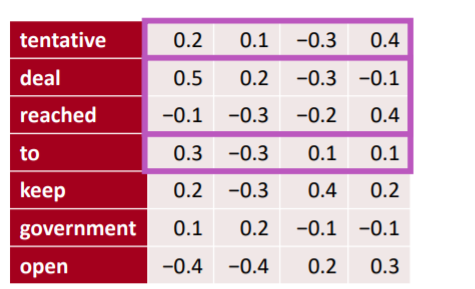
위와 같이 각 토큰의 임베딩 벡터를 수직으로 concatenate하면 될 것이다. 그렇게 하면 각 임베딩 차원이 다른 특징을 가지고 있는 꼴이 된다. 그리고 이를 임베딩 차원의 크기를 가지는(위에선 4)필터를 이용해 통과시키면
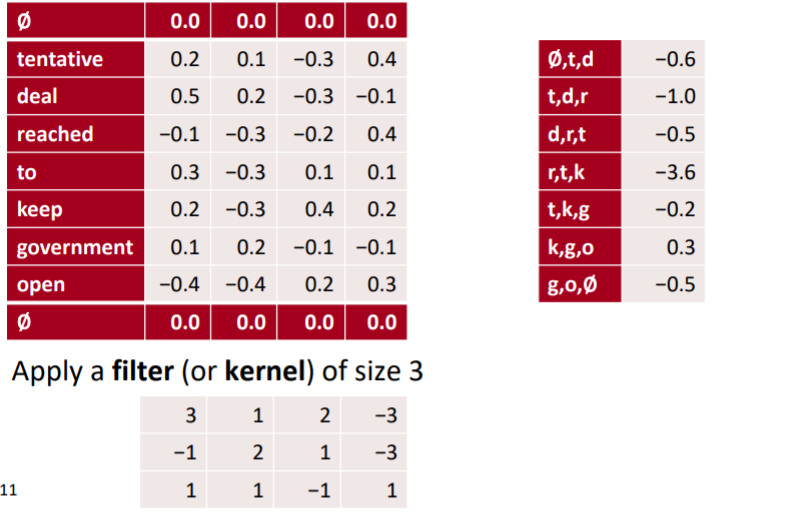
위와 같이 세개의 단어에 대한 하나의 필터가 가지는 특징 맵이 만들어진다. 패딩에 대한 설명은 생략한다.
그리고 당연하게도 하나의 필터는 하나의 특징밖에 잡아내지 못한다. NLP에선 공적 언어인지, 음식에 대한 주제를 가지는지, 구어체인지 등에 대한 정보일 것이다. 여러 정보를 잡아내기 위해 다수의 필터를 적용한다.
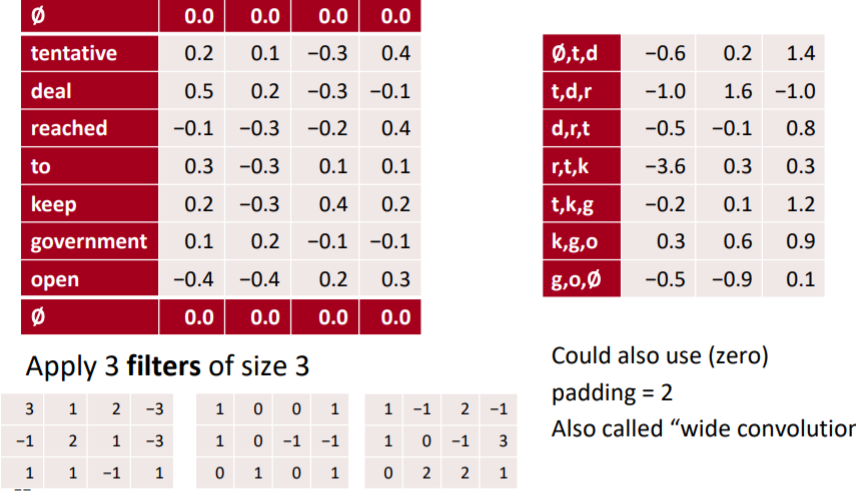
1-2-2. Pooling over Time
하지만 NLP에서 우리가 하고자 하는 것은 전체 문장의 맥락을 파악하고자 한다. 즉, 개별적인 길이가 3인 토큰들의 특징을 위에서 잡아냈다면, 이젠 그 토큰들이 이루는 전체 문장의 특징들을 잡아내보자. 그렇게 하기 위해선 풀링이 사용된다. 이미지에서도 특징을 좀 더 큰 범위에서 잡아내고자 하는 것처럼, NLP에서도 마찬가지이다. 또한, NLP에서의 pooling은 이미지와 달리 시간에 따라 연산된다. 토큰 단위의 평균이나 최대값이기 때문이다. 토큰의 흐름 = 시간의 흐름인 것은 당연하다.
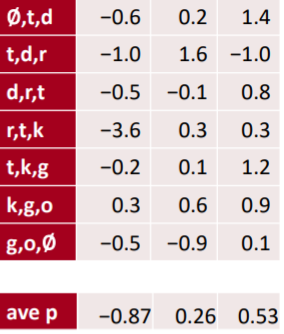
max pooling의 경우, 전체 문장에서 가장 해당 특징을 잘 나타낸 토큰들의 값을 의미하게 된다. 음식에 대한 주제라고 한다면, 사실 문장에서 음식에 대한 토큰은 많지 않을 것이다. 어제 나는 은혜와 함께 삼계탕을 먹었다. 라는 문장이 있다면, 음식에 대한 부분은 삼계탕과 먹다 정도이다. 이 두개를 캐치하기 위해선, max pooling이 적절하다. 먹다와 삼계탕에서 해당 값이 가장 클 것이기 때문이다. mean pooling은 전반적인 정보를 파악하고자 할 때 적당하다. 전체의 정보를 평균내기 때문이다.
1-2-3. Make Feature Map Smaller
Convolutional 레이어를 통과한 피쳐맵이 너무 크다면 여러 방법을 통해 더 줄일 수도 있다.
1) stride : 필터가 건너 뛸 정도를 의미한다. 스트라이드가 커질 수록 동일 필터를 이용할 때, 피처맵의 크기는 작아진다.
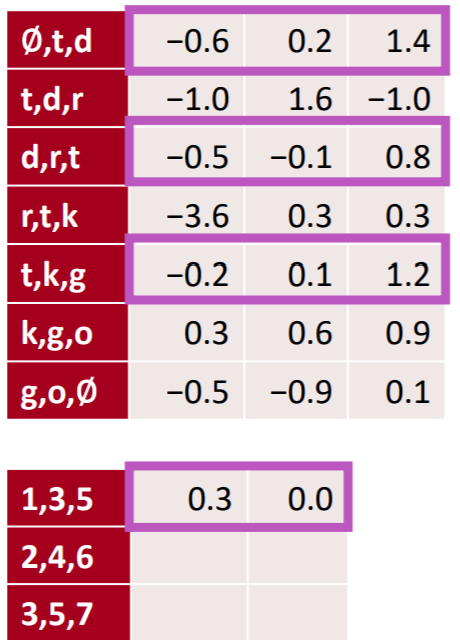
2) local pooling : pooling over time을 하지 않고, 고정된 시점 단위로 풀링하는 것을 의미한다. 이를 통해 고정된 시점의 정보를 압축할 수 있다.
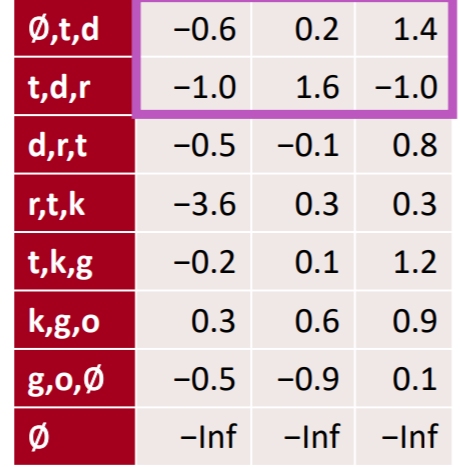
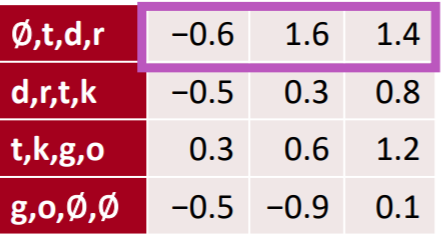
두 시점의 정보를 local pooling을 통해 압축한 모습이다. 피처맵이 절반이 된 것을 알 수 있다.
3) k-max pooling : max pooling 시 제일 큰 값만 가져오는 것이 너무 적은 정보를 가져온다고 생각한다면, 상위 k 개의 값을 가져올 수도 있다. 이때, 가져오는 순서는 피쳐맵의 크기 순으로 가져오는 것이 아니라, row 순대로 가져오게 된다. 피쳐맵의 row 순서는 곧 어순 혹은 시점을 의미하기 때문에, 해당 정보를 어느정도는 보존할 필요가 있기 때문이다.
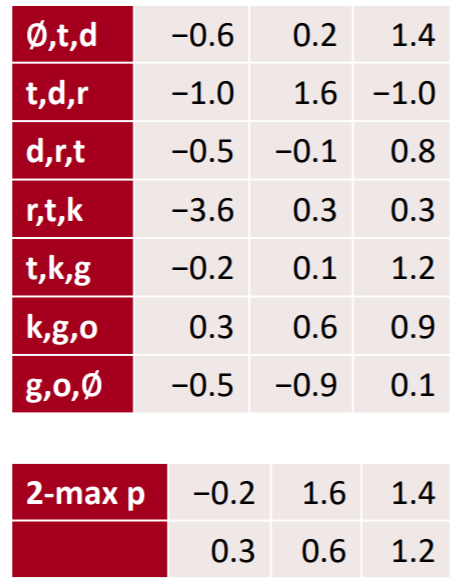
4) dilation : 피처맵에 대해 한번 더 conv 레이어를 적용할 때, 건너 뛰면서 피처맵을 적용할 수도 있다. 직관적으로 왜 이렇게 하는지 이해가 되지는 않는데, 더 넓은 정보를 확인할 수 있는 방법이라고 한다.
5) more conv layer : 기존 CNN처럼 conv net을 계속 쌓을수도 있다. 위에서 언급한 방법들 모두 점점 한번에 보는 토큰의 숫자는 많아지게 된다. 피처맵이 작아질 수록 더 많은 토큰을 한번에 처리하고 있는 것이기 때문이다.
2. Conv for Sentence Classification
2-1. Sentence Classification
문장 분류 태스크 중 가장 대표적인 태스크는 감성 분류일 것이다. 단일 문장이 긍정인지 부정인지 분류하는 태스크이다. 이외에도 주제를 찾거나, 질문의 요지가 무엇인지 분류하는 태스크 등이 있다. 즉, 말그대로 문장을 이용해 분류하는 태스크이다.
2-2. Model Architecture
위에서 언급한 내용이 그대로 반복되지만, 실제 예측까지 어떻게 이루어지는 지 살펴보도록 하자. 수업에서는 유명한 논문인 Yoon Kim (2014): Convolutional Neural Networks for Sentence Classification. EMNLP 2014 이용하고 있다.
-
input
입력값으론 각 토큰의 임베딩 벡터를 단순히 concatenate하고 있다. 이때, 해당 논문에선 하나의 임베딩 벡터를 사용하기 보단, 두개의 동일한 임베딩 벡터를 만들고, 하나만 update하고, 다른 하나는 freeze하고 있다. 이를 통해 fine tuning과 freeze의 이점을 모두 취하고자 한다.
-
filter
필터 역시 벡터로 입력되는데, 연산 상 편의를 위해서인 것 같아. CNN 구현 시 약간의 트릭을 통해 벡터로 연산하면 좀 더 편하기 때문이다.
하나의 필터가 전체 문장을 통과하는 모습은 다음과 같다.
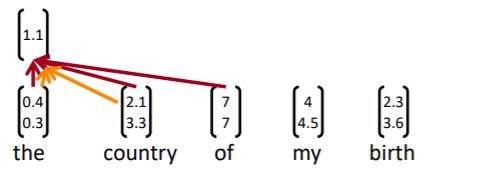
-
activation function
당연하게도 활성화 함수를 통과하여 비선형성을 추가한다. 이때, 필터를 통과한 값을 적용하게 된다.
위 식에서 는 i번째 필터의 피처맵 값(용어가 이게 맞는지 모르겠다)은 필터 w와 i부터 h만큼의 길이까지의 토큰을 연산하고 bias를 더한 후 활성화함수를 통과한 값이다. -
zero padding
문장의 길이가 다 다르고, 문장의 마지막 지점에선 정해진 길이보다 짧은 토큰만 남게 되는데, 이는 문장의 마지막에 0 패딩을 추가하여 해결하였다.
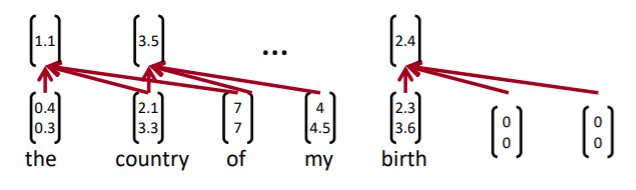
-
feature map
최종적인 피쳐맵은 다음과 같이 만들어진다.
-
pooling over time
pooling over time을 적용하여 하나의 필터에 대한 값을 만들게 된다.
-
multiple filters
당연하게도 여러 필터를 사용하게 된다. 이때 NLP의 n-gram처럼 3, 4, 5의 여러 크기의 필터를 사용한다. -
softmax
각각의 필터에 대해 max pooling over times를 통과한 값들을 concatenate하여 벡터를 만들고 이를 softmax 함수에 넣어 최종적인 분류를 하게 된다.
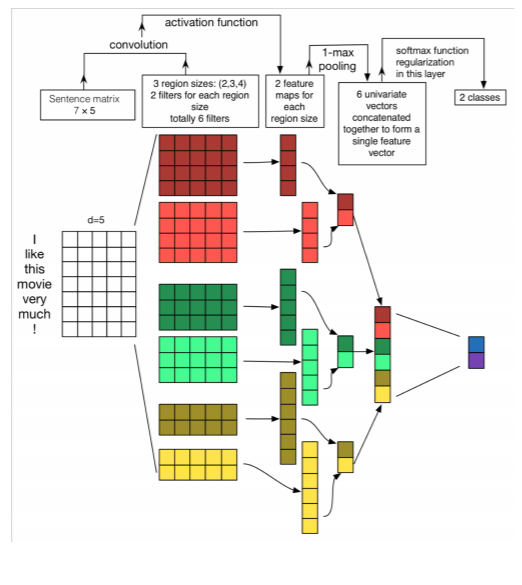
모델의 최종적인 모습은 위와 같다. 여러 요소가 있는 것 같지만 1-D CNN이라는 점을 생각하면 사실 엄청 단순한 모델이다. 여기서 필터의 사이즈를 세개를 한번에 사용하고, max pooling over times를 통해 스칼라값으로 크기를 동일하게 하여 사용한다는 것이 기존의 2-D CNN과 가장 큰 차이점이 아닐까 싶다.
2-3. Regularization
이 모델 역시 제약을 두고 있는데, drop out을 사용하고 있다. 많이 사용하고, 이전에도 많이 접한 방법론이기 때문에 특별한 것이 있지 않지만, 처음 알게 된 사실은 inference 때 모든 노드를 사용해서 값이 커지는 것을 방지하기 위해 확률 p로 스케일링 해준다는 점이다.
훈련 시에는 아래와 같은 식을 통해 순전파가 이루어진다.
여기서 r은 p 확률의 베르누이 분포를 따르는 벡터이다. 이를 통해 노드를 잠근다.
예측 시에는 아래와 같은 식을 통해 레이어를 통과한 값이 과하게 커지지 않도록 한다.
3. Other Tricks
여기선 NN에 사용되는 수많은 방법론들에 배우게 된다.
3-1. Gated units used vertically
LSTM은 정보를 싣고 지우는 게이트라는 개념을 도입했고, 실제로 이것이 성공했다. 이를 수직적으로 즉, 레이어 간에 적용하려는 시도들이 있었다고 한다. 그 중 가장 유명한 것은 resnet에 사용된 residual block이다.
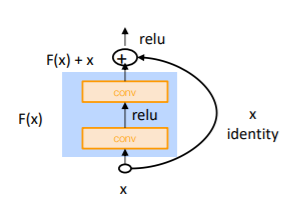
Residual Block은 다음과 같은 식으로 이루어진다.
이 식에서 F(x)는 conv -> relu -> conv로 구성되어 있는데, 당연하게도 conv는 패딩을 이용해 input과 output의 사이즈를 동일하게 해준다. 그래야 x와 elment-wise로 덧셈이 가능하기 때문이다. 여기서 메인은 사실 F(x)가 아니라 x다. 그러니까 x가 기본이고, F(x)는 x에 얼마만큼 더하고 빼야 하는지를 결정할 따름이라는 것이다. 만약 x가 더이상 변환이 필요없다면, F(x)는 그냥 0일 것이다. 이전까지 F(x)를 중심으로 생각해서 도대체 x가 어떻게 더해질 수 있는지 의아했는데, 이런 식으로 이해하니 훨씬 편했다.
Highway Block은 Residual Block과 똑같은 개념이지만 조금 다른 식을 가지고 있다.
위 식에서 T(x)와 C(x)는 LSTM의 게이트 역할이라고 한다. 이 구조를 만든 연구진이 LSTM을 만들었다고 하는데, 그래서 개념을 그대로 가져온 것 같다. 겉보기에는 좀 더 정교한 구조를 가져서 얘가 residual block보다 좋을 것 같지만, 사실 resicual block이 훨씬 낫다고 한다.
그 이유는 highway block으로 하려는 건 모두 residual block으로 할 수 있다. x가 기본이기 때문에 highway block에서 얼마나 더하고 빼고 하든, F(x)를 통해 모두 할 수 있다. F(x) 자체가 기본적으로 비선형 함수이기 때문에 가능한 것일 거다. 즉, 복잡하다고 좋은게 아니고 얼마나 수학적으로 기능을 할 수 있는지 이것을 고민하고 모델을 설계해야 한다.
3-2. Batch Normalization
우리는 지금까지 수없이 많이 일정한 범위 내의 레이어 출력에 대해 이야기 했다. weight initializatoin도 결국 weight가 너무 튀면 레이어 출력이 튀기 때문에, ReLU도 z가 너무 크면 레이어 출력이 너무 튀기 때문에, RNN도 레이어 출력이 너무 튀어서 발산해버린다. 즉, 레이어 출력의 크기를 조절해 줄 필요가 있다. 그리고 batch norm은 정확히 이를 수행해준다.

논문에 등장하는 batch norm의 알고리즘은 위와 같다. x라고 되어 있지만 이는 batch norm을 레이어로 보았을 때 이야기다. 즉, x는 다른 레이어의 출력값이다. 하나의 미니 배치 내에서 동일 레이어의 모든 출력값의 평균과 분산을 계산하고 이를 이용해 normalization 해주는 것이 전부이다. 이때, z 분포보다 더 좋은 분포가 있을 수 있기 때문에 파라미터인 와 를 두고있다.
생각보다 간단한 개념인데, 처음 들으면 머리속에 잘 그려지지 않는다. 그리고 이게 왜 잘 작동하는지 알려면 역전파, relu, weight initalization에 대해 이해가 되어야 할 것 같다.
3-3. 1x1 Convolution
기본적인 Conv layer의 흐름은 다음과 같다.
1) a 필터가 모든 채널에 대해 연산을 수행하여 각 채널마다 결과값이 만들어진다.
2) 채널수만큼 만들어진 결과값들을 더하여 최종적인 feature map을 만든다.
3) feature map에 relu등 비선형 함수를 적용하여 최종 output을 낸다.
이때 1x1짜리 conv layer를 적용하면 어떻게 될까?
동일한 가중치 하나가 모든 채널에 똑같이 곱해지고, 그 값들이 더해져서, input과 동일한 사이즈를 가진 output이 만들어진다. 곱하고 더한다. 즉, 이다.
여기서 우항은 우리가 ffnn에서 자주 보던 식 아닌가? 조금 다른 점이 있다면 가중치가 모두 똑같다는 것이다. 대신 conv의 필터 수를 늘리면 그만큼 가중치도 늘어나는 효과를 가질 수 있다. 즉, 1x1 Convolution을 하면 이미지는 동일하게 가져가면서 FFNN을 하는 결과를 가질 수 있다. 연산량을 줄이면서도 비선형성을 추가할 수 있는 것이다.
3-4. CNN for Translation
최초의 기계번역 시도는 seq2seq이 아니었다고 한다. 실제로는 2013년에 발표된 CNN을 인코더로 하는 모델이라고 한다. 이 모델은 문장을 Conv 레이어를 여러겹 통과시켜 sentence encoding을 하고, 이를 RNN류 모델을 디코더로 하여 번역을 시도했다고 한다.
3-5. Very Deep Convolutional Networks for Text Classification
2017년은 컴퓨터 비전 분야에 있어서 변화의 시기였다. Residual Connection의 발견으로 엄청 깊은 네트워크를 설계할 수 있었기 때문이다. NLP에서는 그에 비해 3, 4겹의 LSTM을 쌓는 수준이었으니, 당시 연구자들은 좀 다른 시도를 통해 깊은 네트워크를 쌓고자 했다고 한다.
3-5-1. Convolutaional blcok in VD-CNN
하나의 블록은 다음과 같이 구성된다.
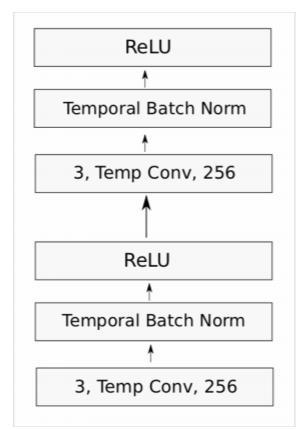
필터의 사이즈는 3으로 고정되고(이미지가 아닌 텍스트므로 1-D CNN임을 기억하자), batch normalization을 통과한 후 ReLU를 통과하는 과정을 두번 반복하게 된다. 또한 패딩을 통해 전체 크기는 보존한다. 그리고 residual connection이 있어서 블록의 입력값과 출력값이 연결되어 있다.
3-5-2. Model Structure
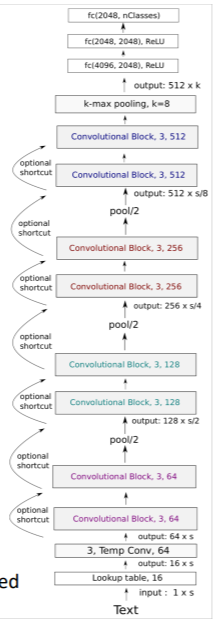
전체 모델의 구조는 위와 같이 되게 길다. 깊게 쌓다보니 이렇게 되었는데, 기본적으로 resnet과 비슷한 구조를 하고 있다.
1) 문자 단위로 16차원의 차원을 가지도록 임베딩한다 이때, 전체 문장의 길이는 1024문자로 통일한다. 이보다 긴 문장은 자르고, 짧은 문장은 제로 패딩을 가해 똑같은 입력값을 가지도록 해준다. CNN 기반이기 때문에 입력값의 크기는 항상 동일해야 하기 때문이다.
2) 이후 블록을 지날 때마다 채널은 2배가 되고, 크기는 절반이 된다. 풀링 레이어가 중간에 끼어 있기 때문이다.
3) 최종적으로 ffnn 레이어와 softmax 레이어를 통과하면 끝이다.
이를 통해 긍부정 분류 태스크를 수행했다고 한다.
3-5-3. Experiments
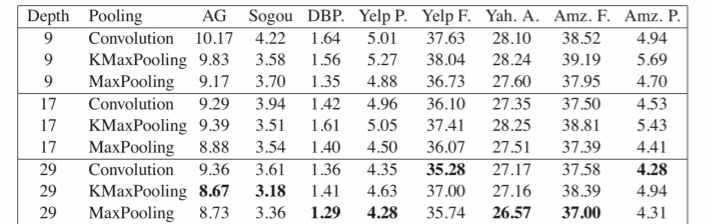
실험 결과 매우 좋은 결과를 보였다. 한가지 특이한 점은, 네트워크를 깊게 쌓는다고 더 좋아지지는 않았다는 것이다. 이는 데이터 수나 NLP의 특징 때문일 수도 있다. 또한, Maxpooling을 적용한 경우가 가장 좋은 성능을 보이거나, 그에 비등한 성능을 보이는 모습을 볼 수 있다.
4. RNNs are Slow
딥러닝은 엄청난 연산량을 자랑하고, 병렬처리가 핵심으로 GPU 사용을 거의 강요한다. 그런데 RNN류 모델은 GPU 사용이 불가능하다. 이전 시점의 정보를 처리해야 다음 시점의 연산을 할 수 있다는 점 때문이다. 사실 강의에서는 Quasi-Recurrent Neural Network라는 모델을 소개하고 있다. 한 시점씩 데이터를 미뤄서 일종의 이전 시점의 정보를 반영한 모델링을 하면서도 병렬처리를 가능하게 한 것 같은다.
Conclusion
CNN을 이용한 자연어 모델링 방법론을 배웠다. 기존에도 알고 있던 내용들이 많았지만, Conv net이 이미지와 자연어에서 어떻게 다르게 처리해야 하는지 고민해볼 수 있는 시간이었던 것 같다. 이외에도 나중에 따로 포스트로 다뤄야 할 내용들이 많아진 것 같아서 나름의 숙제를 받은 기분이다. 좀 더 준비하고 다듬어 보자.
