NLG라는게 워낙 넓은 분야이다 보니, 이 강의에선 전반적인 개념과 태스크들, 최근 모델들에 대해 설명하고 있다.
0. Recap
0-1. NLG is subcomponent of...
NLG는 입력값이 있든 없든, 그 종류가 무엇이든 상관없이 출력으로 텍스트 시퀀스를 만드는 태스크이다. 그래서 NLG는 많은 NLP 분야의 하위 파트로 사용되고 있다. 그 예시로는 다음과 같은 분야들이 있다.
- 기계 번역
- 요약
- 대화
- 창작(시나 소설)
- 자유 질의응답(지식 기반이나 주어진 문장에서 뽑는 질의응답이 아니다.)
- 이미지 캡션
0-2. Language Modeling
LM은 다음 단어를 만드는 태스크이다. 다르게 이야기하면, 생성되는 단어들의 분포를 파악하는 태스크이다. 이를 식으로 타나내면 다음과 같다.
이전에 등장한 단어를 조건으로 이번에 등장할 단어 분포를 계산한다.
그리고 이때 RNN 모델을 활용한다면 RNN-LM이 된다.
0-3. Conditional LM
조건부 LM은 문장 생성 시, 입력 문장 혹은 입력 데이터가 존재하는 경우이다. 즉, 어떠한 조건 하에서 문장이 만들어지는 태스크이다. 식은 다음과 같다.
Conditional LM이 사용되는 태스크는 다음과 같다.
- 기계 번역(x = 원 문장, y = 번역 문장)
- 요약(x = 원 문장, y = 요약 문장)
- 대화(x = 이전 대화 기록, y = 다음 대화)
0-4. Conditional RNN-LM
RNN-LM 즉, Seq2Seq로 된 모델을 학습시키는 과정은 아래 그림과 같다.
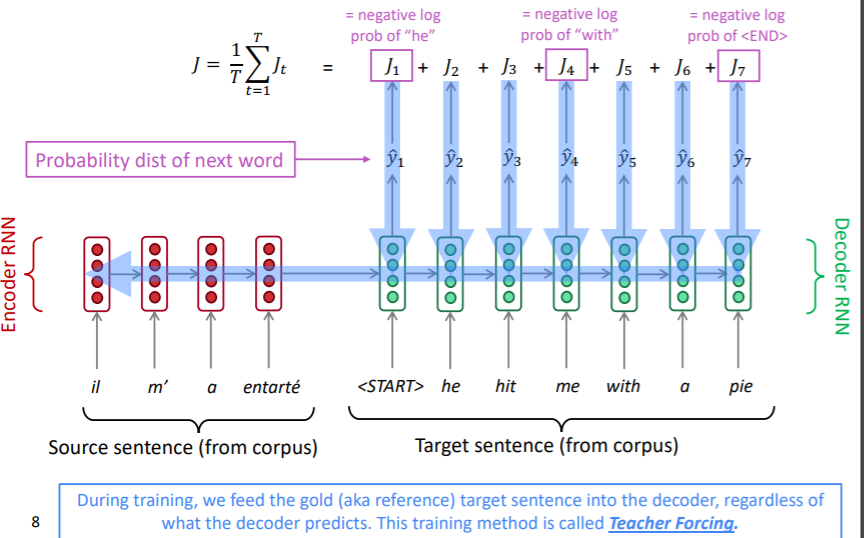
이때 중요한 점은 디코더의 입력값이 학습과 추론 과정에서 다르다는 점이다. 이를 teacher forcing이라 한다. 학습 과정에선 원래 문장 토큰이 들어가게 되고, 추론 과정에선 이전 시점의 출력값이 현재 시점의 입력 토큰이 된다. 학습 과정에선 워낙 예측 결과가 좋지 않기 때문에, 추론 시와 동일하게 입력값을 사용하면 안정적인 학습이 불가능하기 때문에 이런 방식을 사용한다. 물론 학습과 추론 시 과정이 달라 불안정하다는 단점이 있기는 하다.
0-5. Decoding Algorithms
seq2seq에서 LM을 이용해 문장을 생성해내는 알고리즘을 디코딩 알고리즘이라고 한다. 지금까지 강의에선 greedy decoding과 beam search 알고리즘을 배웠다.
greedy decoding은 단순히 매 시점마다 가장 높은 score를 기록한 토큰을 선택하는 것이다. 하지만 모델이 매 시점마다 가장 적절한 단어에 score를 제일 높게 준다고 확신할 수 없다. 한 시점에서 잘못된 토큰을 뽑을 경우, 그 이후 시점은 모두 어그러진 결과를 뽑을 수 밖에 없다.
이를 고려한 알고리즘이 beam search 알고리즘이다. 빔 서치 알고리즘은 매 시점마다 k개의 후보 문장을 만드는 알고리즘이다. 이때 결국 softmax 값을 이용하기 때문에, 가장 확률이 높은 문장 시퀀스 k개를 선택해서 계속 탐색하는 것이라고 이해할 수도 있다.
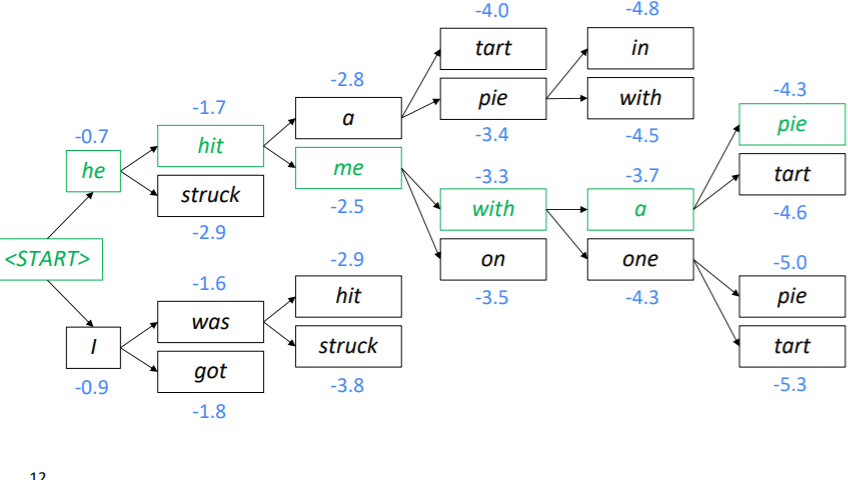
실제로 이전 수업에서도 이런 식으로 선택하는 모습을 보여줬다.
0-6. Beam Search Algorithms
k값에 따라서 빔서치 알고리즘은 꽤 다른 값들을 가지게 된다.
- k = 1
k가 1이면 간단하다. 그리디 알고리즘과 같아진다. 결과물은 문법적으로도 맞지 않고, 자연스럽지도 않고, 문맥에 맞지도 않고, 문장 자체도 아예 잘못되버릴 가능성이 높다. - k가 적당히 크다면
k가 적당한 값을 가지게 된다면, 그리디 알고리즘의 많은 문제점들이 해결된다. 그럴듯하고 정확하고 문법에도 맞는 문장을 만들 여지가 많아진다. - k가 많이 크다면
k가 적당히 크면 그럴듯한 문장을 만든다고 했으니, 무작정 키우면 더 그럴듯한 문장을 만들게 될까? 정답은 그렇지 않다. 여기엔 두가지 문제가 있는데, 우선은 너무 계산량이 많아진다. k = 3이면, 현재 가진 3세개의 시퀀셜마다 각각 3개씩 후보 토큰을 뽑는다. 그러면 9개의 토큰이 생기고, 여기서 다시 가능성 혹은 점수를 계산하고, 그 중 상위 3개를 고르게 된다. 즉, k = n일때, 만큼의 계산이 발생하게 된다.
이보다 큰 문제는 k가 커질수록 BLEU 점수가 커진다는 점에 있다. BLEU는 전에도 다뤘지만 문장이 짧을수록 점수가 높은 경향이 있다. 아무리 BLEU 내부적으로 문장 길이에 패널티를 준다하더라도, 이 경향은 바뀌지 않는다. 하지만 빔 서치에선 문장의 길이가 짧을수록 점수가 높다. 즉, k가 클수록 짧은 문장을 최종 선택하게 되고, 최종적으로 만들어진 문장은 생성된 문장의 품질과 관계없이 BLEU가 커지는 경향을 가지게 된다.
만약 다음과 같은 대화가 있다고 해보자. '
I mostly eat a fresh and raw diet, so I save on groceries.
여기서 k에 따라 나오는 답변은 다음과 같다.
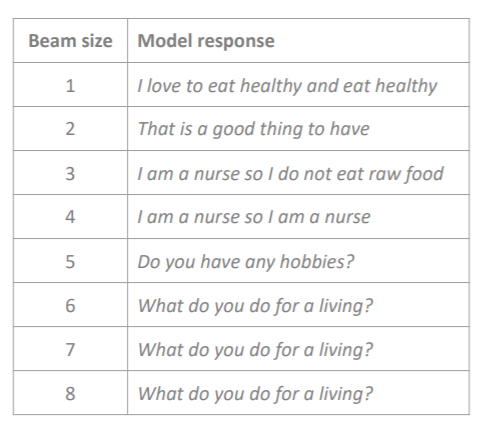
잘 살펴보면 k가 작을수록 말은 안되지만, 맥락에 적절한 대화를 뽑아주는 것을 알 수 있다. 다르게 말해보자면, conditional LM에서 조건에는 충실히 따르지만, LM이 조금 약한 결과물들이 나온다. k가 커질수록 그럴듯한 말이 나오지만, 너무 일반적인 문구라서 맥락과 관련이 없어진다. 다르게 말하면 conditional LM에서 조건과 독립적이지만 LM은 강한 결과물이 생긴다. 하지만 완벽히 이 trade-off 관계를 해결할 k값은 없다고 한다(이젠 놀랍지도 않다). 그저 실험을 통해 그나마 좋은 값을 찾을 수 있을 뿐이다.
0-7. Sampling-based Decoding
이번엔 그냥 뽑아보자는 아이디어다. 여기에도 두가지 방법이 있다.
0-7-1. Pure Sampling
이 방법은 매우매우 단순하다. 사실 이 방법은 사용되지 않을 것 같다. 매 샘플마다, softmax를 통과한 확률분포 를 따르도록 하나를 뽑는 것이다. 이 방법은 greedy decoding이 매 스텝마다 argmax를 이용해 가장 확률이 큰 토큰을 뽑았던 것과 비교하면 그냥 argmax를 안쓴다는 점에서 다르다. 이런 식으로 직접적으로 가장 확률이 큰 토큰을 사용하는 그리디 서치나 상위 k개를 사용하는 빔서치 외에 확률 분포를 사용하여 단어를 뽑도록 하면 좀 더 자연스러운 문장이 나올 수 있다고 한다.
0-7-2. Top-k Sampling
이번엔 조금 말이 되는 방법이다. 똑같은 확률분포 에서 가장 높은 확률을 가지는 상위 k개의 토큰 중에서 하나를 뽑는 것이다. 이건 확률 분포를 잘라서 사용하는 것이라 생각할 수 있다. 만약 k = 1이라면 greedy search가 될 것이고, n = V라면 pure sampling이 될 것이다.
k를 키울 수록 더 확률이 낮은 단어들이 뽑힐 수 있어서 다양한 표현이 나올 수 있지만, 문장이 이상해질 우려가 크다. k가 작을 수록 일반적인 표현들이 나오겠지만, 그래도 그럴듯한 문장이 만들어질 것이다.
0-8. Softmax Temperature
매 시점마다 각 토큰에 해당하는 보캡 사이즈의 벡터인 스코어는 소프트 맥스 함수를 통과하여 확률의 꼴을 가지게 된다. 이를 식으로 써보면 다음과 같다.
sotfmax temperature는 여기에 하나의 항을 더한다.
여기서 가 바로 온도에 해당하는데 표현이 재밌다. 결국 소프트 맥스 함수는 지수 함수를 안에 가지고 있다. 지수 함수는 입력값이 작을수록 작은 값을 토해내게 된다. 그리고 지수 함수의 미분값은 지수함수 꼴로 작아진다. 즉, 큰 값일수록 그 변화가 더 크다.

이를 이용해서 온도로 나눠주면 소프트맥스를 통과한 분포가 조금 더 평평해진다. 다른 말로 하면 온도가 오를수록 분포가 녹아서 더 균일해진다. 온도가 내려가면 분포는 얼어서 더 뾰족해진다. 균일한 분포에선 더 다양한 표현들이 나올 수 있고, 뾰족한 분포에선 더 일반적인 표현들이 나오게 될 것이다.
물론 softmax temperature가 디코딩 알고리즘은 아니지만, 내부에서 활용할 수 있다. 이를 이용하면 trade-off 관계를 어느정도 완화할 수 있지 않을까?
2. NLG tasks and Nerual Approaches
이제 NLG 태스크를 하나씩 살펴보도록 하자.
2-1. Summarization
2-1-1. Definition
요약 태스크는 주어진 텍스트 x를 이용해 주요 정보를 가지고 있되 길이가 짧은 텍스트 y를 생성하는 태스크이다. 이는 입력 문장 x를 기준으로 크게 두 가지로 나눠진다.
- Single Document : 이는 주어진 텍스트 x가 하나일 경우다. 즉, 하나의 글만 요약하여 y를 생성하면 된다.
- Multi-document : 이는 주어진 텍스트 x가 공통의 주제를 가지는 여러 개의 텍스트일 경우이다. 예를 들어 동일한 주제로 작성된 복수의 신문 기사를 이용해 요약문 y를 생성하는 것이다.
또한 생성하는 방식에 따라 두가지로 나눠진다.
- Extractive Summarization : 주어진 텍스트에서 중심 문장을 선택하는 태스크이다. 비교적 쉬운 태스크이지만, 기존의 문장들을 활용하기 때문에 요약 성능이 떨어지고 제한적이다.
- Abstractive summarization: 주어진 텍스트를 이용하기 보단, NLG를 이용하여 새롭게 문장을 작성하는 태스크이다. 비교적 어려운 태스크이지만, 훨씬 유용하고 요약이 잘 된 문장을 생성할 수 있다.
2-1-2. Dataset
- Gigaword : 신문 기사를 이용해 한문장 혹은 두 문장으로 요약하는 데이터셋이다. 보통 헤드라인을 생성하는 태스크라고 간주할 수 있다고 한다.
- LCSTS : 중국 마이크로 블로그에서 작성된 문서와 요약문을 가지고 처리하는 것으로 중국어 데이터셋이라고 한다.
- NYT, CNN/DailyMail : 뉴스 기사를 이용해 복수의 요약문을 생성하는 데이터셋이다.
- Wikihow : 비교적 최근에 만들어진 데이터셋으로 노하우들이 담긴 텍스트 x를 이용해 요약문을 작성하는 것이다. 다른 데이터셋이 주로 뉴스를 다루는데 비교하여 다른 주제의 텍스트라고 한다.
이와 더불어 sentence simplification이라고 하는 비슷한 태스크가 있다. 주어진 문장을 좀 더 간결한 구조 혹은 단어를 사용해 바꾸는 것이라고 한다.
- Simple Wikipedia : 기존의 위키피디아 문서를 이용해 더 간단한 버전으로 문서를 생성하는 데이터셋이다.
- Newsela : 이는 실제로 서비스되고 있는 데이터셋인데, 기존의 뉴스 데이터를 아이들을 위한 뉴스 데이터로 변형한 데이터셋이라고 한다.
2-1-3. Pre-neural Summarization
NN을 도입하기 이전의 요약 기술이라 함은 대부분 추출적 요약(extractive summarization)에 초점이 맞추어져 있다고 한다. 기계번역처럼 대부분 파이프라인 통해 구성되었다고 한다. 파이프라인의 대략적인 순서는 다음과 같다.
- Content Selection : 전체 문장 중에서 어떠한 문장을 요약에 사용할 지 선택한다.
- 여기엔 또 두가지 대표적인 방법이 있다.- Sentence scoring function : 각각의 문장들이 얼마나 중심문장인지 점수를 매겨주는 일종의 함수를 이용하는 것이다. 이때는 tf-idf같은 방법을 이용해 중심 단어의 빈도수를 세거나 전체 문서 내에서 문장의 위치를 이용한다.
- Graph-based Algorighms : 문서를 일종의 문장들의 집합으로 본다. 문장들은 노드를 이루고, 문장 간의 유사도가 간선의 세기를 의미하게 된다. 이를 이용하여 중심 문장을 선택한다.
- Information Ordering : 선택된 문장들이 어떠한 순서로 놓여야 하는지 결정한다.
- Sentence Realization : 문장들이 자연스럽게 이어지도록 단순화, 일부 제거, 접속사 추가 등의 작업을 한다.
2-1-4. ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
기계 번역에서 봤던 BLEU처럼 rouge도 n-gram을 기반으로 하는 평가지표이다. 전체 식은 다음과 같다.
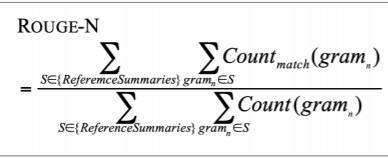
ROUGE가 BLEU와 다른 점은 다음과 같다.
- Brevity penalty가 없다. : ROUGE는 어차피 요약 태스크이다. 즉, 문장이 짧아서 문제가 될 것이 없다.
- Recall에 기반하고 있다. : 요약 태스크에서 reference들에 들어있는 단어들은 중요 단어들이라고 볼 수 있다. 즉, 기준으로 삼아야 하는 문장은 reference에 들어있는 n-gram 단어들이다. 이는 BLEU가 precision을 이용하여서 생성된 텍스트를 기준으로 하였던 것과는 다르다.
결국 요약 태스크는 짧되 중심 단어들이 모두 들어있는 문장을 만들고자 하는 태스크이다. 그래서 brevity penalty도 없고, recall에 기반하고 있는 것이다. 하지만, 종종 f1 score를 기반으로 만들기도 한다.
또한 BLEU가 4개의 n-gram을 종합하여 하나의 점수로 나온 것과 달리 ROUGE는 각각의 n-gram 마다 다른 점수가 나온다. 즉, 다음과 같은 분류가 가능하다.
- ROUGE-1 : unigram을 활용한 것과 같다.
- ROUGE-2 : bigram을 활용한 것과 같다.
- ROUGE-L : n-gram에서 n을 고정하지 않고, 단어의 등장 순서가 동일한 빈도수를 모두 세는 방식이다. 예를 들어 다음과 같은 reference와 요약문장이 있다고 해보자.
ref : police killed the gunman
System-1: police kill the gunman
여기서 ROUGE-L은 3/4이 나온다. 왜냐하면 police, the gunman이 어순에 맞게 일치했기 때문이다. 만약 kill gunman the police 라고 등장했다면, 1/4이 될 것이다. gunman만 일치하고 다른 단어들은 순서가 다르게 등장했기 때문이다.
2-1-5. Neural Summarization
이제 NN을 이용한 요약 모델들을 살펴보도록 하자. 2015년에 Rush를 비롯한 여러 사람이 최초로 NN을 이용한 요약 모델을 발표했다고 한다. 당시 seq2seq 모델을 이용했으며, single doeument abstractive summarization이었다고 한다. 이를 번역 태스크로 간주하여 seq2seq + attention NMT 알고리즘을 사용했다.
이후에 수많은 방법론들이 개발되었는데 주요 아이디어들은 다음과 같다.
- 복사를 쉽게 만들자. : 결국 요약 태스크는 일부분 단어나 문구가 원문에서 그대로 가져와야 한다. 그래서 이를 의도적으로 가능하게 만들고자 했다.
- 너무 복사되지는 않도록 하자. : 하지만 결국 요약은 요약이다. 원문을 너무 가져오게 될 경우 요약이 아닌 말 그대로 복사에 지나치지 않기 때문에 이를 방지해야 했다.
- Hierarchical/multi-level attention : 위계를 나누어 어텐션을 적용하고자 했다. 이를 통해 저레벨과 고레벨에서 하는 역할을 분류하고자 했다. 이외에도 여러 방법론이 있다고 한다.
2-1-6. Copy Mechanism
복사 매커니즘이 등장한 중요한 이유는 seq2seq+attention만 사용할 경우 생성된 문장이 그럴듯하기는 하지만 자주 등장하지 않는 단어들이 주요 단어일 경우에 이를 제대로 잡아내지 못한다는 문제점이 있었다. 그래서 복사 매커니즘에선 입력 문장에서 복사해야할 쉽게 문구나 단어를 포착해서 문장을 생성하게 된다. 이를 조금 다르게 생각해보면 추출적 요약과 추상적 요약을 하이브리드한 기법이라고 생각할 수도 있다.
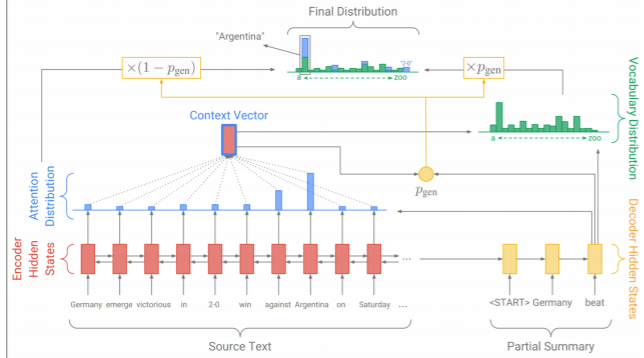
가장 기본적인 카피 매커니즘을 사용한 모델은 위와 같다. 어텐션 분포를 이용하여 context vector를 만든다. 그리고 이를 디코더의 hidden state와 같이 처리하여 을 만든다. 은 디코더의 이번 시점에서 문장을 어느정도 비율로 생성할지 결정하게 된다. 그리고 디코더를 통해 만들어진 토큰의 분포가 와 곱해지고, 인코더의 어텐션 분포와 (1- )이 곱해지게 되어 일종의 가중합된 두 분포를 더해서 최종적인 이번 시점의 토큰 분포를 만들게 된다. 그리고 여기서 최종적인 토큰을 뽑는 것이다. 이렇게 하면 토큰을 그대로 복사할지 아니면 새로 생성해야 할지 좀 더 유연하게 결정할 있다고 한다. 혹은 을 0 또는 1의 discrete한 값으로 설정하여 아예 복사하거나 생성하도록 할 수도 있다고 한다.
하지만 복사 매커니즘은 문제가 분명했다.
- 너무 자주 복사해버린다. 긴 문구나 심지어는 전체 문장을 그대로 복사해서 가져와 버린다고 한다. 이러면 추상적 요약이라기보다 추출적 요약에 가까워져버린다.
- 전반적인 정보를 선택하는데 어려움을 겪었다. 특히 입력 문장이 길 경우에 전체 문장을 제대로 파악하고 여기서 요약문을 만들기 시작해야 하는데, 요약문이 recursive하게 만들어지다 보니 그렇지 못했다고 한다.
다시 NN 이전의 방법론들을 생각해보면 당시엔 파이프라인으로 태스크를 나눠놨었다. 첫번째로 요약에 사용할 문장들을 고르고, 거기서 문장을 다음었다. 하지만 현재 이야기하고 있는 seq2seq+attention에선 이 두 스테이지가 서로 섞여 있다. 디코더에서 단어 단위로 문장을 생성하기도 하고, 요약에 사용할지 고르기도 해버린다.
이를 개선한 방법론으론 Bottom-up summarization이 있다. NN 이전의 방법론을 차용한건데, 두 단계로 나누어 모델을 구성하였다.
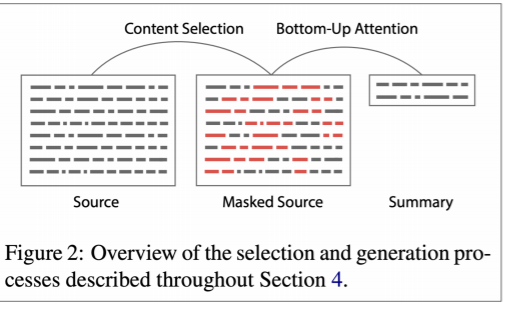
- Content Selection : 이 단계에선 sequence-tagging 모델을 활용하여 각 단어들마다 요약에 사용할지, 사용하지 않을지 이진 태깅을 한다.
- Bottom-up Attention : 태깅을 통해 요약에 사용할 단어들만을 이용하여 실제 요약문을 생성하는 인코더-디코더에 넣게 된다.
단순한 방법론이지만 그 성능은 꽤 괜찮았다고 한다. 그 이유로는 태깅을 통해 전체 문장 중 일부 단어만 선택되었기 때문에 애초에 전체 문장을 그대로 복사할 수도 없었고, 요약에 필요한 단어만 선택하다보니 처리해야할 정보의 양도 줄었기 때문이다.
2-1-7. Reinforcement Learning
강화학습에도 딥러닝이 적용이 가능하다. 강화학습에 대해선 거의 몰라서 해당 부분은 잘 이해를 못했지만, 요약 태스크에 강화학습을 적용한 메인 아이디어는 다음과 같았다.
기존의 머신러닝 기법들은 ROUGE-L이 미분이 되지 않아서 직접 손실함수로 사용하지 못했는데, 강화학습으로 직접 ROUGE-L을 높이려고 해보면 어떨까?
그 결과는 다음과 같았다.

강화학습에서 목적함수가 현실하고 동떨어져 있으면 우리가 원하는 방향으로 모델이 학습하지 않고 손실함수 값만 낮추려고 학습이 된다. 대충 걷는 모델을 만드려고 a에서 b까지 가는 시간을 손실함수로 설정했더니 그냥 넘어지는 모델이 만들어지는 식이다. 여기서도 비슷한 일이 발생했다. LOUGE-L 값은 SOTA를 보이는데, 정작 사람이 읽기에는 형편없는 모델이 나온 것이다. 그래도 하이브리드 방식을 사용할 경우 사람에 있어서도 SOTA를 기록했다.
2-2. Dialogue
대화 태스크는 여러가지 세부 분야로 나눠진다. 우선 태스크 중심의 대화로는 다음과 같이 분류할 수 있다.
- Assistive : 특정 태스크를 수행하는 사람을 보조하는 대화시스템이다. 콜센터에서 상담사분들이 사용하는 챗봇이나 책을 구매하는 사람을 보조하는 대화 시스템 등이 있다.
- Co-operative : 두 에이전트가 하나의 태스크를 대화를 통해 해결한다고 한다.
- Adversarial : 두 에이전트가 하나의 태스크에 대해 대화로 경쟁한다고 한다.
사회적 용도를 가지는 대화 시스템으론 다음과 같이 있다.
- Chit-chat : 단순히 재미를 위한 챗봇이다. 얼마 전에 출시되었다 사라진 이루다가 해당한다.
- Therapy : 상담 및 치료 용도로 사용되는 챗봇이다.
2-2-1. Pre and Post Neural Dialogue
NLG에서 아예 새로 문장을 만드는 어려움은 상당히 높아서 NN 이전의 대화 시스템은 대부분 규격화된 템플릿이 있고, 거기에 알맞은 콘텐트를 삽입하여 문장을 완성했다고 한다. 혹은, 정해진 대답 코퍼스에서 고르는 방식이었다고 한다.
그러다 2015년 경 seq2seq으로 대화 시스템을 구현하고자 했고, 이를 통해 문장을 새로이 만드는 대화 시스템이 본격적으로 연구되기 시작했다고 한다. 하지만 NN 기반의 모델에서도 문제점들이 발생하기 시작했다.
- Genericness : 너무 일반적인 반응만 내놓는다. 인격이 없는 느낌의 대화가 되어버리는 것이다 .
- Irrelevant reponses : 문맥에 관련이 없는 반응을 내놓는다.
- Repetition : 하나의 문장 안에서도 반복이 발생하고, 이전에 말한 문장을 그대로 말하기도 했다.
- Lack of context : 이전의 대화를 모두 고려해야 문맥에 적당한 반응을 할 수 있을텐데, 이게 쉬운 일이 아니다.
- Lack of consistent persona : 하나의 인격체로서 대화하는 느낌이 전혀 없다. 아까는 중국에 산다고 했는데, 지금 다시 물어보면 뉴욕에 산다고 하는 식이다.
2-2-2. How to solve the problems?
그렇다면 문제점들을 어떻게 해결할 수 있을까? 하나씩 살펴보도록 하자.
2-2-2-1. Irrelevant Response Problem
이 문제를 좀 더 구체화하면 두가지 경우로 나눌 수 있다.
- 너무 일반적인 대답만 하는 경우 ex) I don't know.
- 갑자기 대화 주제를 바꾸려고 하는 경우
이에 대한 해결책으론 MMI가 있다. 이는 최근에 style transfer 관련 논문을 찾아보다가 나왔는데, 수업에서 보니 좀 더 이해가 잘 되었다. 식은 다음과 같다.
기존의 조건부 확률의 분모에 다른 조건을 추가한 것이라고 볼 수도 있다. 이를 풀어서 T를 구하는 식을 세우면 다음과 같다.
이 식의 의미는 결국 S라는 사용자의 말에 대해 T라는 문장을 만들어야 하는데, 그 문장이 너무 일반적이면 패널티를 부과하겠다는 이야기가 된다. 일반적인 문장일수록 LM인 가 커질 것이기 때문이다.
2-2-2-2. Genericness
일반적인 대화의 문제의 가장 간단한 해결책은 자주 등장하지 않는 단어의 가중치를 높여서 빔서치를 하거나 이전에 언급했떤 다양한 샘플링 디코딩 방법을 사용하는 것이다. 이외에도 추가적인 정보를 디코더의 조건으로 삽입하는 방법이나 사용자가 미리 작성한 대화를 수정하는 방식으로 모델을 조정할 수 있다.
2-2-2-3. Repetition
반복은 사실 쉽게 해결할 수 있다고 한다. 그냥 빔서치할 때 반복되는 n-gram을 사전에 막으면 그만이다. 좀 더 정교하게 하고 싶다면, 반복 문제가 발생하는 주요 이유는 특정 단어에 반복해서 집중하기 때문이므로 이를 방지하거나 반복하여 생성하는 단어나 문장에 대해 패널티를 주는 방식이 있다.
3. NLG Evaluation
지금까지 자연어 생성의 메트릭들로 BLEU나 ROUGE 등을 봤었다. 모두 n-gram 기반의 지표들이었다. 그래서 이 지표들이 훌륭한가?라고 물어본다면 그럴 수 없다. 번역 태스크에서 위 지표들은 모두 참고용으로 사용되지 절대적인 평가지표로 사용되지 못한다. 지표는 높은데 사람이 보니 엉망인 문장들이 많기 때문이다. 그럼 어떤 지표가 좋은 지표일까?
결론부터 말해보자면, 그런 지표는 없다. 심지어 대화나 요약 태스크로 넘어온다면, 전무하다.
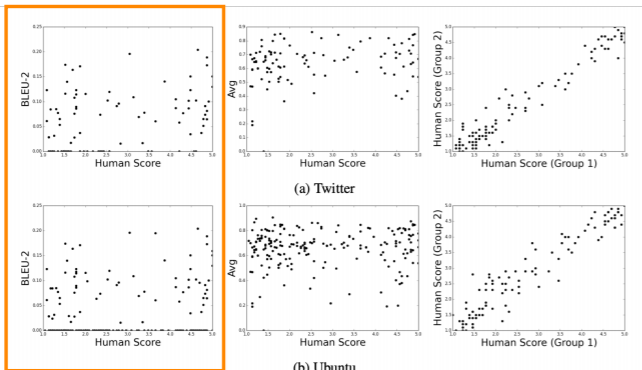
아래표의 주황색 부분은 사람의 평가와 BLUE 스코어 간의 scatter plot이다. 전혀 상관관계가 없어보인다. 즉, BLEU는 전혀 평가지표로서 역할을 하지 못하고 있다. 그렇다고 perplexity로 돌아갈 순 없다. perplexity는 단순히 얼마나 LM이 잘 만들어내는지 보여줄 뿐이지 생성된 문장이 얼마나 좋은 문장인지는 알지 못한다. 그래서 각각 평가하고 싶은 세부 요소에 따라 다른 평가지표를 사용해야 한다.
- 유창함(fluency) : 잘 훈련된 LM으로 계산한 확률로 알 수 있다.
- 정확한 스타일 : 타겟 코퍼스로 학습시킨 LM으로 계산한 확률로 알 수 있다.
- 표현의 다양성 : 드문 단어가 얼마나 등장하는지, n-gram의 개별성을 통해 알 수 있다.
- 입력값과 연관성 : 의미적 유사도를 측정할 수 있는 임베딩 벡터의 유사도 등을 통해 알 수 있다.
- 길이와 반복 정도
3-1. Human Evaluation
사람이 평가하는게 그럼 제일 좋지 않을까? 어차피 우리는 사람이 사용할 챗봇, 소설 생성기를 만들고자 하는데, 사람이 그 성능을 평가하면 될 것 같다. 실제로 사람 평가는 가장 표준적인 지표로 사용된다. 유일한 단점이라고 생각되는 것은 느리고, 비싸다는 점이다. 근데 정말 그것만 단점일까? 사람이 평가하면 다른 평가지표가 가지는 문제점들이 모두 해결될까? 당연히 아니다.
사람은 일정하지도 않고, 비논리적이며, 집중력이 일정하지도 않고, 평가 시 요구 사항을 잘못 이해하기도 하고, 그들이 그렇게 평가한 이유를 스스로 모르기도 한다.
실제로 강의한 head tutor의 페르소나 챗봇 프로젝트에서 여러 문제점들이 있었다고 한다. 사람 평가 시 다음과 같은 질문이 있었다고 한다.
- 얼마나 대화가 잘 진행되고 있나요?
- 이 사용자는 얼마나 적극적으로 대화하고 있나요?
- 두 사용자 중 어떤 사용자가 좀 더 그럴듯한 반응을 보이나요?
- 이 사용자가 사람일까요? 챗봇일까요?
그런데 문제점이 생겼다. 질문을 잘못 이해해서, 챗봇이 매번 다시 말한 내용을 물어보니 적극적으로 대화하고 있다고 여기거나, 사람마다 다른 기대수준을 가지고 있거나, 배경지식에 따라서 이정도면 챗봇치고 잘했다고 여기는 등의 문제점이 있었다.
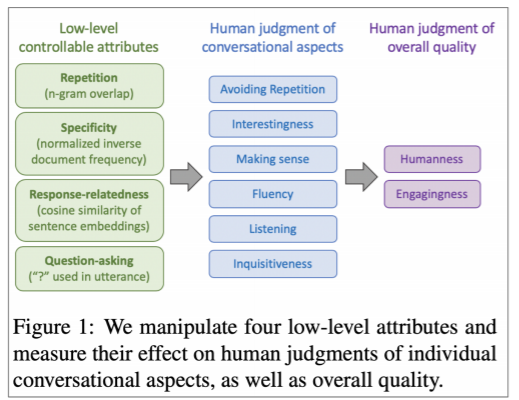
그래서 평가 지표를 위와 같이 세분화해서 진행할 수 밖에 없었다고 한다. 그 결과 발견한 내용은 다음과 같다.
- 반복을 제어하는 것은 모든 사람 평가에서 주요했다.
- 질문을 많이 하는 것이 좀 더 적극적으로 평가되었다.
- 구체적으로 질문하는 것이 적극성, 호감, 인지된 듣기 능력을 향상시켰다.
그런데 웃긴 것이 있다. 정작 사람들은 실제 대화에서 자기 이야기를 하는 것을 좋아하지 남의 이야기를 좋아하지 않아서 사람보다 챗봇이 종종 더 사람같이 여긴다는 것이다. 즉, 사람들이 타인에게 기대하는 대화의 자세와 실제로 자신이 대화에 임하는 자세가 달라서, 평가가 왜곡되어버린다.
NLG는 사실 잘 모르는 분야이다. NLP 중에서도 개인적으론 가장 안쪽에 위치한 분야가 아닐까 싶다. 인코딩과 디코딩 뿐만 아니라 데이터 자체도 상당히 정교하게 짜여져야 할 것 같다. 더군다나 컴퓨터가 여러 대화의 맥락을 이해하고 답변을 한다는게 토니 스타크를 넘어 일반 대중에게도 근시일내에 가능할 것이라는 생각이 별로 들지 않는다. 아마 NLG는 강인공지능에 가까운 태스크이지 않을까 싶다. 앞으로 어떤 연구 분야를 잡고 생업으로 삼게 될지는 모르겠다. NLG 역시 매력적인 분야인 것 같기 때문이다. 어려운 만큼 보람이 있지 않을까. 그런데 평가지표로서 볼만한 것이 너무 많고, 그 중에 최우선적으로 볼만한 것이 없다는 건 조금 슬프다. 결국 주관적인 평가가 가장 좋은 평가가 된다는 이야기인 것 같다. 사람들이 평가하게 할 때 발생한 문제는, 내 전공분야와 연관이 있어 보인다. 설문조사를 하는 방법론을 많이 배웠는데, 그때 주의하라고 한 내용들이었기 때문이다. 결국 NLG를 평가한다는 것은 어떤 인격체의 지적 수준을 평가하고자 하는 것이 아닐까 하는 생각도 든다(터무늬없는 생각이라는 것도 안다.).
