이번 시간엔 외부 강사님이 오셔서 트랜스포머나 self attention의 원리에 대해 설명해주는 시간이었다. 우선은 트랜스포머 이전, 즉 RNN류 모델들의 시대에 대해 이야기해보자.
1. RNNs
RNN류 모델들은 문장과 같이 입력값의 길이가 가변적인 경우에 효과적으로 작동했다. 고정된 벡터를 이용해 순차적으로 정보를 입력받고, 저장하고, 처리하는 방식이었다. 하지만 순차적으로 정보를 처리하는 방식은 병렬 처리가 힘들었다. 또한, 직접적으로 장기적으로 정보가 잘 전달되도록 하는 방법이 없었다. LSTM이든 GRU든 결국 그래디언트 배니싱 문제를 일부 해결한 것이지 깔끔하게 자유로워진 느낌은 아니었다. 이와 더불어서, 모델을 좀 쌓고 싶어도, 위에서 언급한 두 문제로 많이 쌓을 수 없었다. NLP에서는 다른 방법을 찾아야 했다.
2. CNN
이미지에서 활용하는 CNN은 어땠을까? 병렬 처리도 쉽고, 지역정보를 활용하기 때문에, 근접 시점의 단어들을 엮어서 사용이 가능하다. 하지만, CNN은 고정된 시점의 정보만 한번에 처리하게 된다. 필터의 크기만큼만 한번에 처리할 수 있기 때문이다. 문장에서 장기 의존성을 포착하기 위해서는 매우 긴 시점의 정보를 한번에 잡아내야 하는데, 이를 위해선 레이어를 많이 쌓아야 했다.
3. Attention
어텐션은 기계 번역에서 만들어진 개념이다. 인코더가 정보를 압축하고, 디코더가 현재의 정보와 가장 유사한 인코더 한 시점의 정보를 활용해 문장을 생성해낸다. 이를 조금 비틀어서, 어텐션을 representation에 활용할 수 없을까? 즉, 인코더 내부에서 어텐션이 돌아갈 수는 없을까?
4. Self-Attention
그렇게 탄생한 self attention이다.
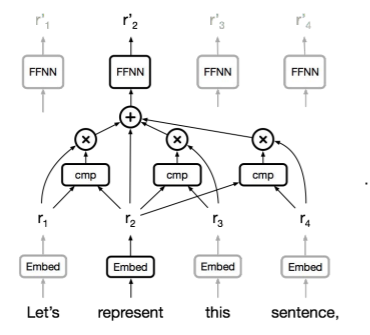
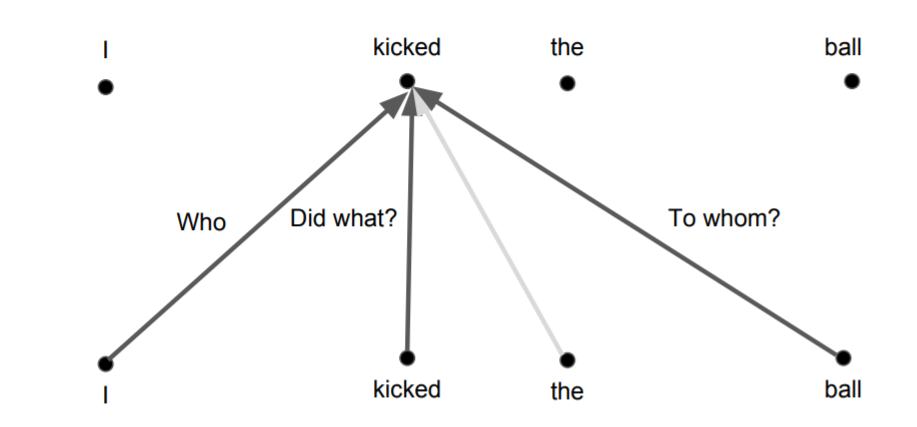
기본적인 구조는 위와 같다. represent라는 단어를 representation vector로 만들고 싶다면, represent의 벡터와 다른 모든 벡터의 유사도를 측정하고, 이를 가중치로 하여 가중합을 구한다. 그리고 이렇게 구한 벡터를 representation으로 활용한다.
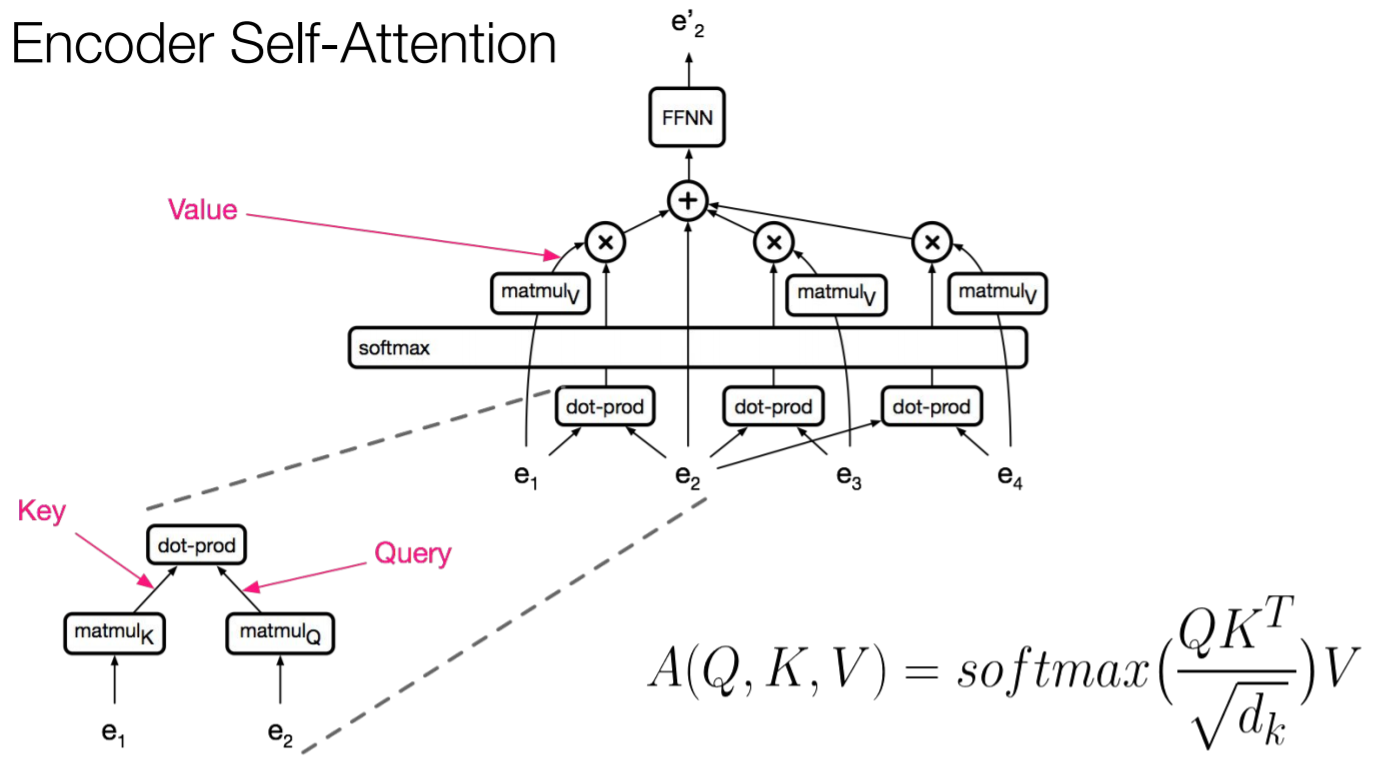
인코더에서는 아래 그림과 같이 모든 시점에 대해 이뤄지게 된다.
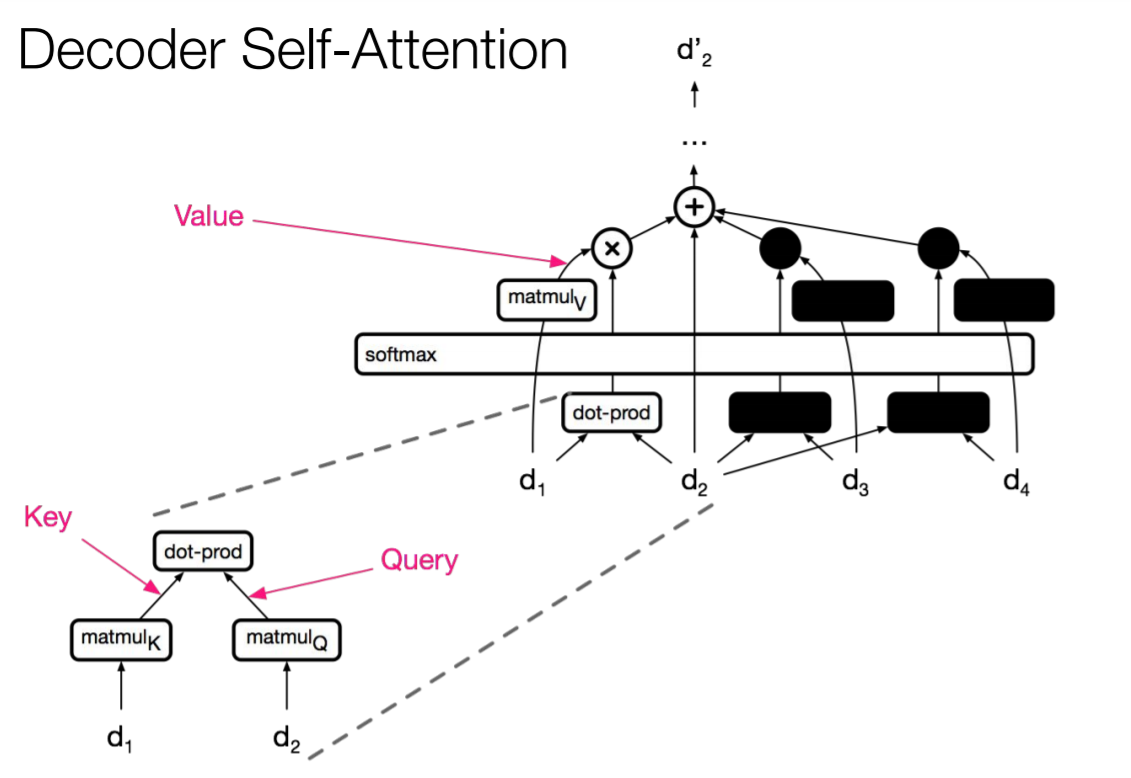
디코더에선 현재 시점 이후의 정보는 활용할 수 없으므로 마스킹된다.
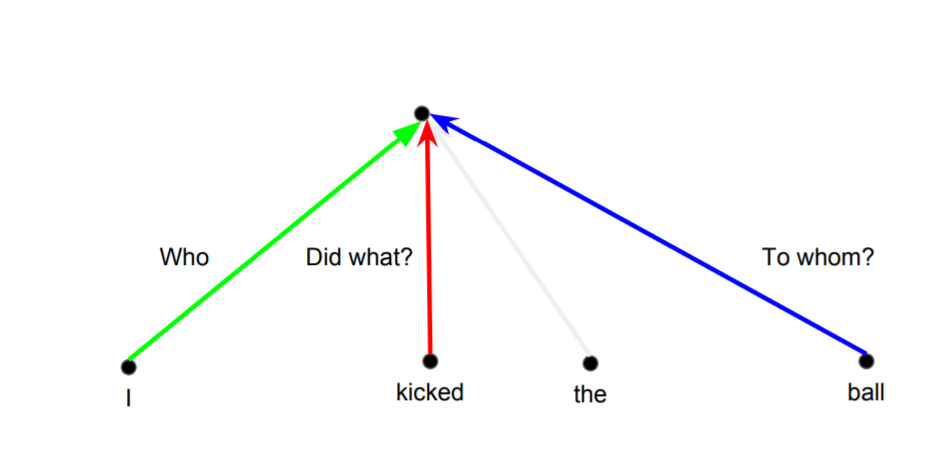
4-1. Why Attention is so Good?
어텐션의 장점은 무엇보다 계산량이 적다는 점에 있다.

무조건 다른 모델에 비해 계산량이 적지는 않다. 하지만 연산량이 차원수에 큰 영향을 받지 않게 된다.

RNN보다는 당연하게도 연산량이 적고, 컨볼루션 보다도 연산량이 적어진다.
4-2. Multi-head Attention
기존의 컨볼루션 연산은 위와 같이 작동한다. 각각의 필터가 다른 정보를 잡아내게 된다. 어떤 필터는 주어를 중심으로, 어떤 필터는 행동을 중심으로, 어떤 필터는 대상을 중심으로 정보를 잡아낸다.
하지만 self-attention은 하나의 정보만 잡아낼 수 있다. 가중치가 한번밖에 안구해지기 때문이다. 이를 해결하고자, multi-head가 도입되었다. 각각의 head들마다 다른 정보를 잡아내는 역할을 하게 되는 것이다.
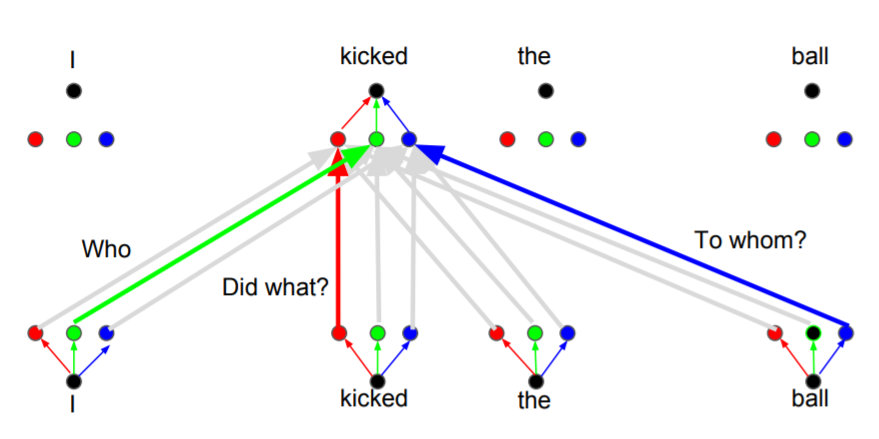
또한, 이렇게 multi-head로 만들경우, 병렬처리를 통해 정보를 처리할 수 있다는 점에서 매력적이다.
5. Residual
트랜스포머 모델은 self-attention이나 ffnn에 residual connection을 두고 있다. 단순히 정보가 잘 전달되기 위해서라고 생각했지만, 보다 구체적인 이유가 있었다.
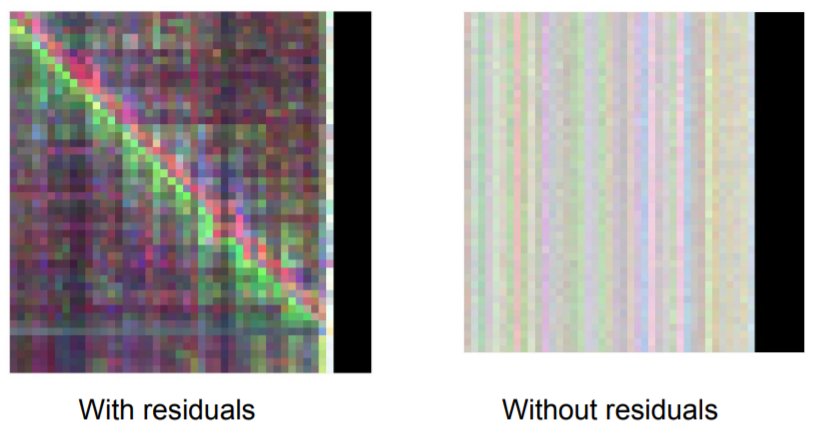
위 그림은 sub layer의 output의 시각화된 그림이다. 왼쪽은 residual connection이 있는 경우이고, 오른쪽은 없는 경우이다. 물론 정보들이 잘 전달되었기에 색이 진하기도 하다. 하지만 더 중요한 것은, 시간 정보가 전달되고 있다는 점이다. 결국 본래 트랜스포머는 번역 태스크를 기반으로 개발된 모델이기 때문에, sequential modeling이 기반이다. 이는 입력값에 대한 시간 정보, positional encoding이 사라지면 안된다는 이야기이다. 하지만 residual connection이 없으면, 레이어 하나를 지났는데도 시간 정보가 어디로 갔는지 감쪽같이 사라지고 만다. 하지만 residual connection은 시간 정보를 잘 살려서 대각선의 정보(positional encoding 벡터를 더한 모습은 이와 같다)가 잘 살아있는 모습이다.
6. Self similarity in Images
그렇다면 트랜스포머를 다른 분야에도 적용할 수 있을까? 혹은 트랜스포머의 핵심 개념 중 하나인 self-attention을 다른 분야에도 적용할 수 있을까? 결국 self-attention하는 것은 비슷한 정보들을 찾아서 이를 활용하는 것 뿐이다. 그렇다면 이미지에선 self-similarity할 수 있을 것이다. 이미지에선

위와 같이 자연물의 패턴이나,

아름다운 반고흐 작품에 나타나는 비슷한 모습들이 self-silmliarity로 잡아낼 수 있을 것이다.
강연한 사람은 특히 이미지 생성에 집중한 것 같다. 이미지 생성은 본래 픽셀 단위의 분포를 모델링하는 태스크인데, 이를 sequence modeling으로 전환한 것이다. 실제로 RNN과 CNN이 sota 모델을 이루고 있고, CNN이 속도 면에서 앞서고 있던 상황이었다고 한다. 이미지 생성에서 어려웠던 부분은, 서로 거리가 먼 곳의 의존성을 파악하고, 이미지가 커짐에 따라 덩달아 커져야 하는 레이어와 커널의 수였다고 한다. 특히, 레이어가 많아져야 먼 거리의 의존성이 잡히기 때문에 여기서 문제가 많았던 것 같다.
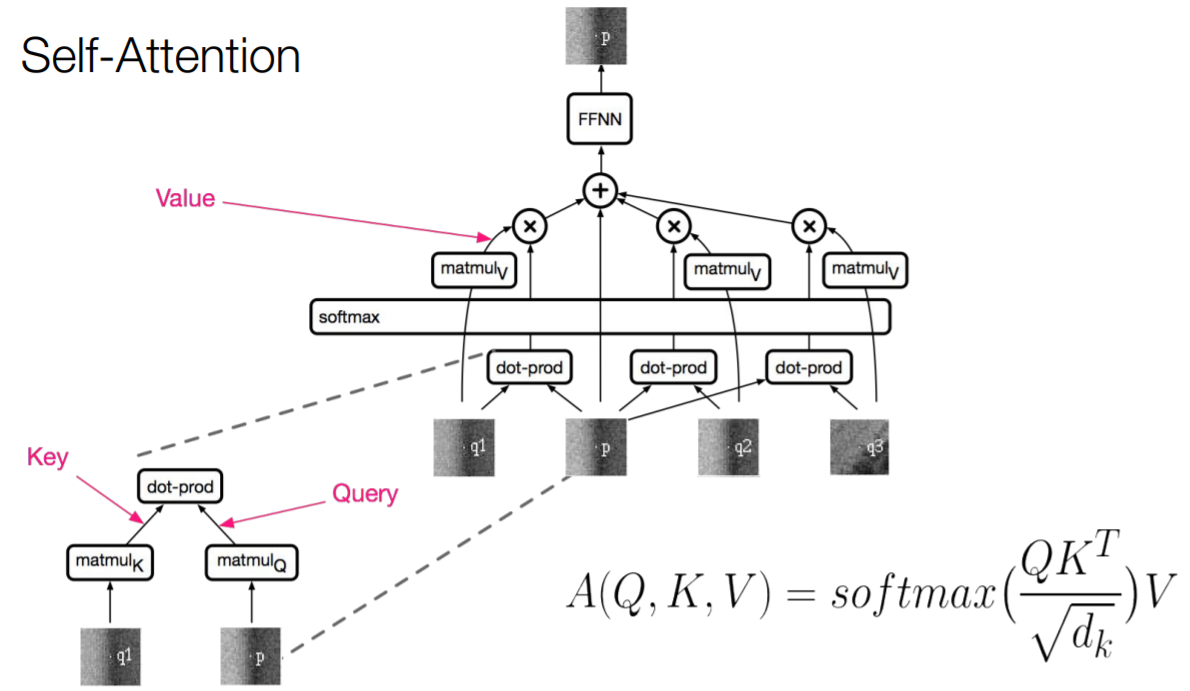
방법은 생각보다 간단하다. 위의 그림에 나온 것처럼, 입력값으로 픽셀값을 사용하면 된다. 기존에 임베딩 벡터에서 픽셀 하나의 값 혹은 여러 픽셀의 값이 사용되는 것으로 바뀐 것 뿐이다. 모델 구조가 거의 변하지 않고, modality 확보가 가능해지는 것이다.
근데 문제가 있었다.
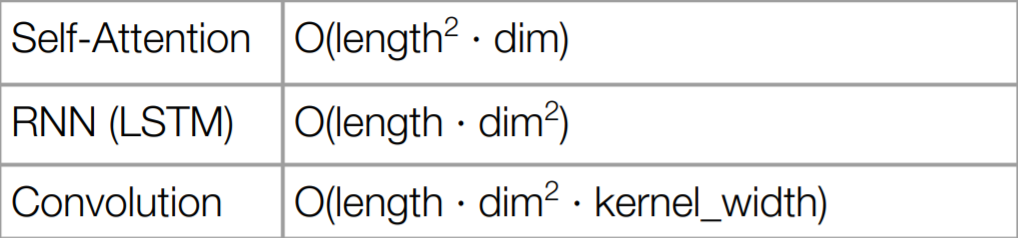
위에서 이야기 했듯이, self-attention은 입력값의 길이에 큰 영향을 받는다. 그런데 이미지는 2차원이기 때문에, 입력값이 기하급수적으로 커질 수 밖에 없어, 연산량에 제약이 필요했다. 그래서, 전체 이미지를 사용하지 않고, attention window로 self-attention에 사용될 입력값을 제한 한 것이다. 특히, 이미지는 공간적 정보가 전달되는 구조이기 때문에, 이런식으로 제한하는 것이 괜찮았다고 한다.
그 제약에는 두가지 방식이 있다.
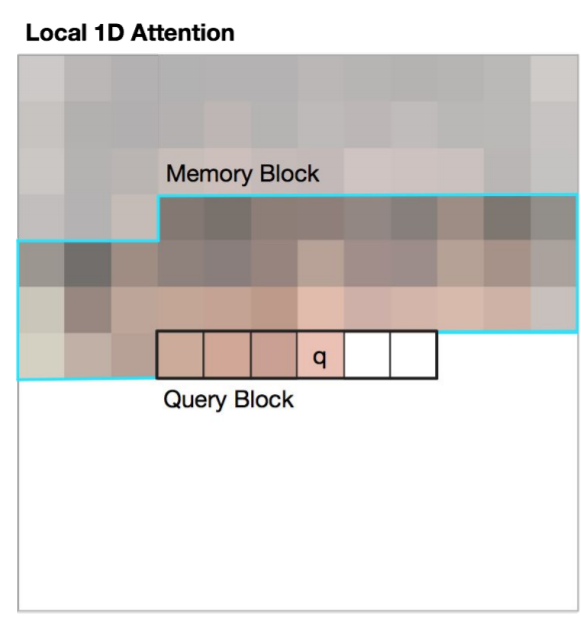
첫번째 방식은 위와 같이 1d로 memory block과 query block을 정하는 것이다.
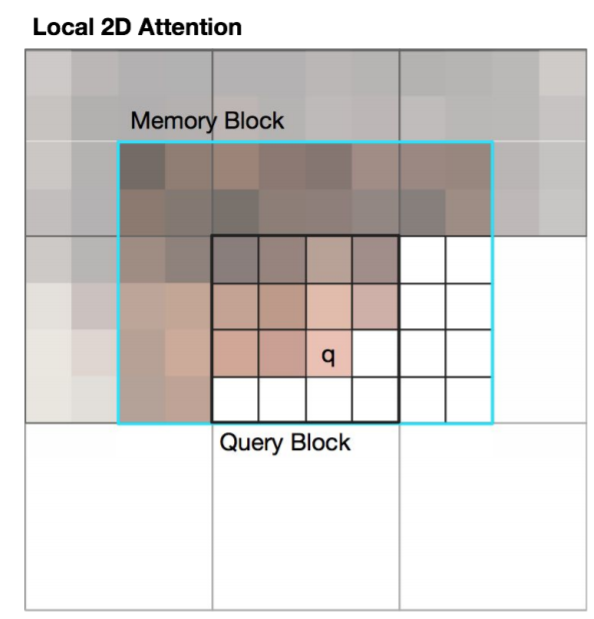
두번째 방식은 이미지가 2d니 만큼 memory block과 query block도 2d로 구성하는 것이다.
conditional & unconditional image generation에 활용했다고 한다.
unconditional image generation은 CIFAR-10 데이터를 이용해서 만들었는데, 그 샘플은 아래와 같다. 재밌는 점은 구조화된 이미지를 잘 만든다는 점에 있다. 선박이나 자동차, 대형 트럭과 같이 부분적인 구조가 명확한 이미지들은 비교적 잘 만들어진 모습을 하고 있다. 아마, self-similarity가 높아서 그렇지 않을까?

conditional image generation은 super resolution과 image completion 태스크를 수행했다고 한다.

super resolution의 결과는 위와 같은데, 저 정도의 제한된 정보로 저렇게 실제 이미지와 비슷하게 만드는 것을 보고 좀 놀랐다... 사람보다 이 분야에선 훨씬 나은 것 같다

image completion은 위 샘플들이 있다. 가장 오른쪽이 원래 이미지인데, 진짜 잘 만드는 것 같다. 주어진 정보 내에서 최대한 정확한 이미지를 만들고 있는 모습이다.
7. Self-similarity in Music
음악에서 self-similarity는 흔하게 보인다고 한다.
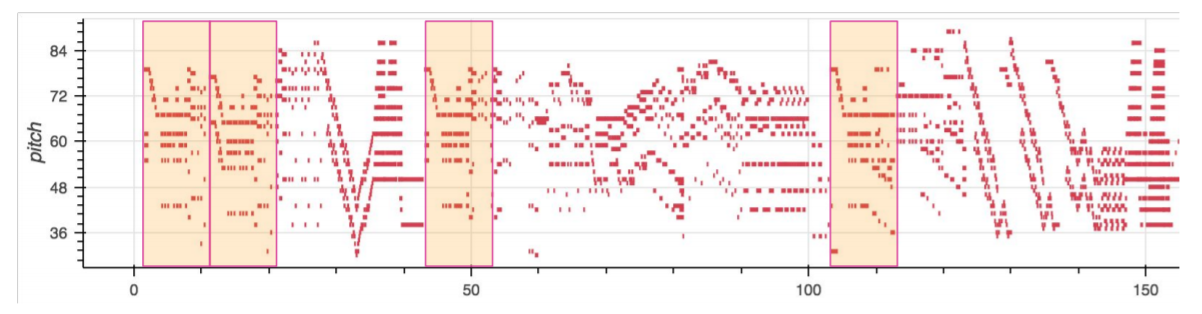
위 그림에서 반복되는 부분은 음악의 테마 멜로디이다. 우리가 음악을 생각할 때 자주 떠올리는 멜로디가 있다. 임창정의 소주한잔에서 "여보세요 나야~"로 시작하는 부분 같은 곳 말이다. 이러한 곳도 self-similarity가 돋보일 부분이다.
그 다음 강연자로 나선 분은 본래 트랜스포머가 사용되던 언어와 음악을 비교하면서 강의를 시작하셨다.
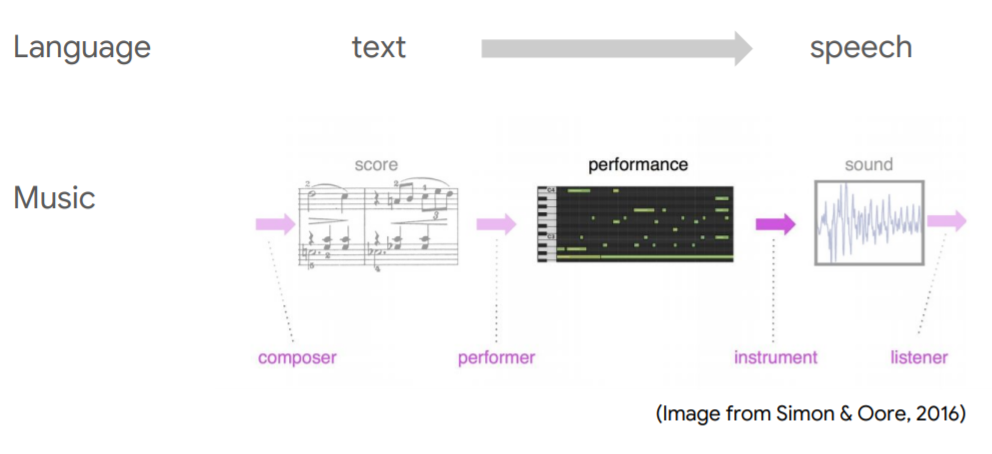
글자를 사람이 읽으면 발화가 되고, 이것이 음성으로 변환되는 과정이다. 음악도 이와 비슷한데, 악보가 있고, 이를 연주자가 악기에 입력하면 악기에서 신호가 나오면서 음악이 된다. 실제 모델링에 사용되는 부분은 음악의 신호가 아니라, midi 등에 입력되는 악기의 신호라고 한다. 위에서 performance라고 되어 있는 부분 말이다.
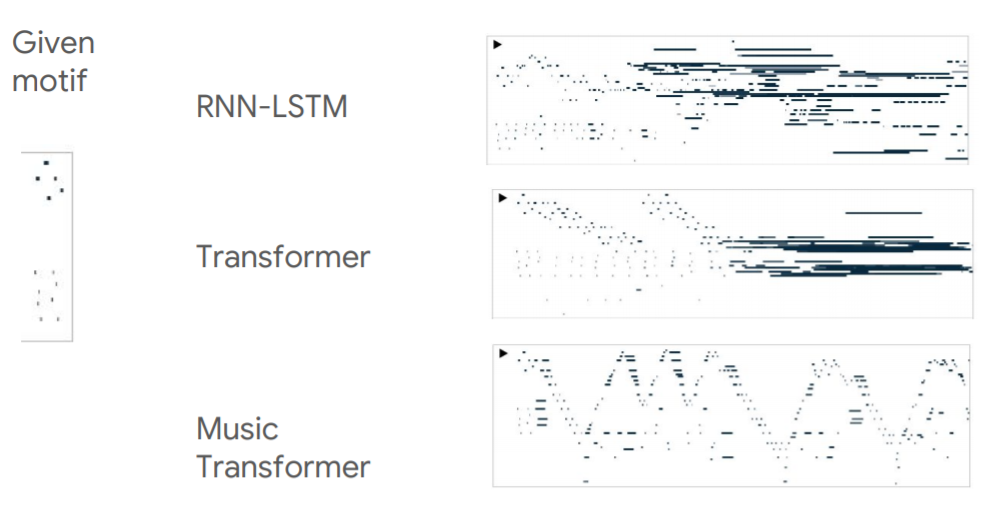
발표자가 쓴 논문은 음악에 트랜스포머 모델을 이용한 것이다. 좀 더 자세히 말하자면 위의 오른쪽에 보이는 것처럼 아주 짧은 모티브를 주고 이것을 이용해 뒤의 음악을 완성하도록 한 것이다. 각각의 모델들이 만든 midi 이미지가 오른쪽에 제시되어 있는데, 실제 강의에서 소리를 들어보면 결과물들이 더욱 극적이다. RNN류 모델은 당연히도 장기 정보를 전달하지 못하는 문제점이 있었다. 음악에서 모티브는 결국 곡 전체에 거쳐 사용되어야 하는 정보인데, RNN은 시간이 지날수록 모티브를 잊어버리고 전혀 다른 멜로디를 만들어내 버린다. 기존의 트랜스포머 모델은 RNN보단 정보를 잘 전달하고 있다. 하지만 훈련에서 사용한 시점보다 길어지면, 이제 점점 엉망이 되는 모습을 보이고 있다. 즉, 제한된 길이에서만 작동한다. 그에비해 음악에 맞추어 개발된 트랜스포머 모델은 전반에 걸쳐 아주 그럴듯한 음악을 만들어낸다. 실제로 들어보면 진짜 사람이 작곡한 음악같은 멜로디를 가지고 있다. 이 글을 누가 읽을지는 모르겠지만(읽는 사람이 없을 거라고 가정하고 지금까지 써오기는 했다.) 꼭 유튜브에서 찾아서 들어보라.
위에선 모티브가 주어진 채 음악이 만들어지는 일종의 conditional generation이었다. 그렇다면 unconditional generation에선 어떤 모습일까?
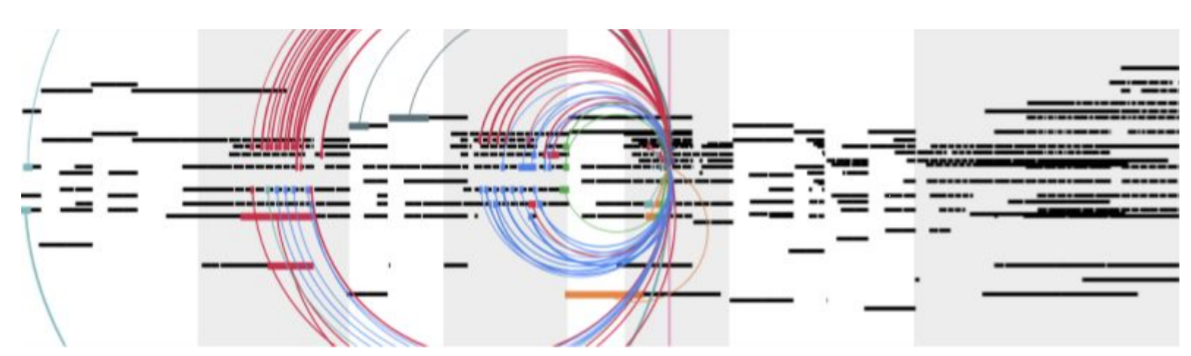
위의 그림은 music transformer가 무작위로 음악을 만들어낸 모습이다. 그중에서 총 3 ~ 4번 정도 반복되는 파트가 존재하는데, 실제로 이 파트에서 이전의 어떤 시점, 어떤 정보에 집중했는지 살펴보면, 놀랍게도 이전에 비슷한 파트에 매우 집중하고 있다. 위의 선들의 굵기가 attention 강도를 의미하고, 색은 head를 의미하는데 진짜 비슷하게 만들어지고 있는 모습이다. 하지만 뒤에 점차 조화가 무너지기 시작하자 점점 이전의 조화가 무너진 시점에 집중하면서 더이상 음악이 아닌 모습이 되어버리기도 한다.
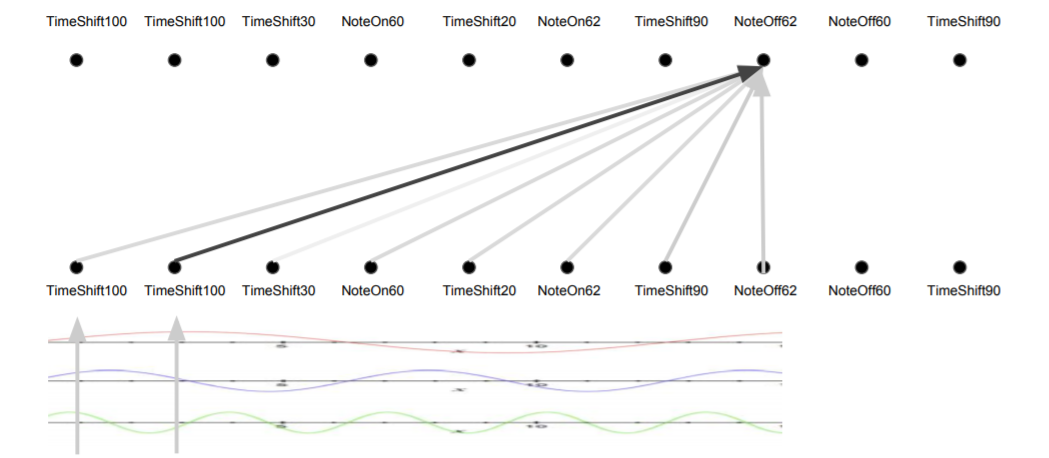
이 강의에서 집중적으로 설명하는 부분은 attention이 길이에 영향을 받지 않는다는 점이다. RNN이나 Convolutional layer 모두 근처 시점의 정보만 집중적으로 활용하는데 비해, self-attention은 먼 시점의 정보도 직접 가져올 수 있게 된다. 왜냐하면 positional encoding을 통해 시간 정보를 벡터에 직접 삽입하고, 이를 이용해 내적하기 때문이다. 위 그림에서도 TimeShift100이 꽤 먼거리에 있음에도 바로 정보를 가져오고 있는 것을 볼 수 있다.
7-1. Relative Attention
하지만 이렇게 하면 무시되는 것이 있다. 실제론, 그래도 가까이에 있는 정보들이 더 중요할 수도 있다. convolutional layer에서 하는 것처럼 말이다. 즉, 지역 정보를 활용하는 방안이 어느정도는 사용될 필요가 있다. 이를 반영하는 것이 Relative attention이다.
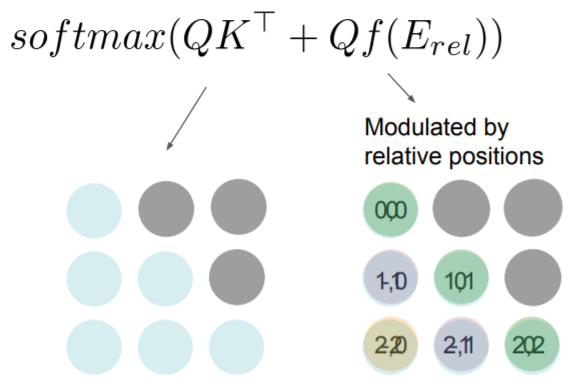
relative attention에선 그래서 기존의 attention 식에 positional embedding 벡터를 사용한다. 이를 통해 현재 시점과 가까울 수록 큰 값을 가지도록 하여 가까울수록 더 attend할 수 있도록 만든다. 일종의 attention + convolution이라고 한다.
이러한 relative attention은 길이가 길 때 효과적이라고 한다. 길이가 짧으면 사실 정보가 가까이 있든 멀리 있든 거리가 큰 차이가 없는데, 그 길이가 커지면 중요해지기 때문일 것이다. 실제 문장 번역 시엔 그 길이 100 ~ 150 정도 밖에 되지 않기 때문에, 큰 의미가 없을 수도 있다. 실제로 영어-독어 번역에선 기존의 트랜스포머 모델에 비해 BLEU가 1.3나아졌지만, 영어-불어에선 0.2만 나아지는 모습을 보이기도 했다.
하지만 음악은 길이가 2000에 달하는 매우 긴 모델이다. 그렇기 때문에 relative attention이 효과적이었다고 한다.
그런데 relative embedding을 넣으려고 하다보니 문제가 생겼다.
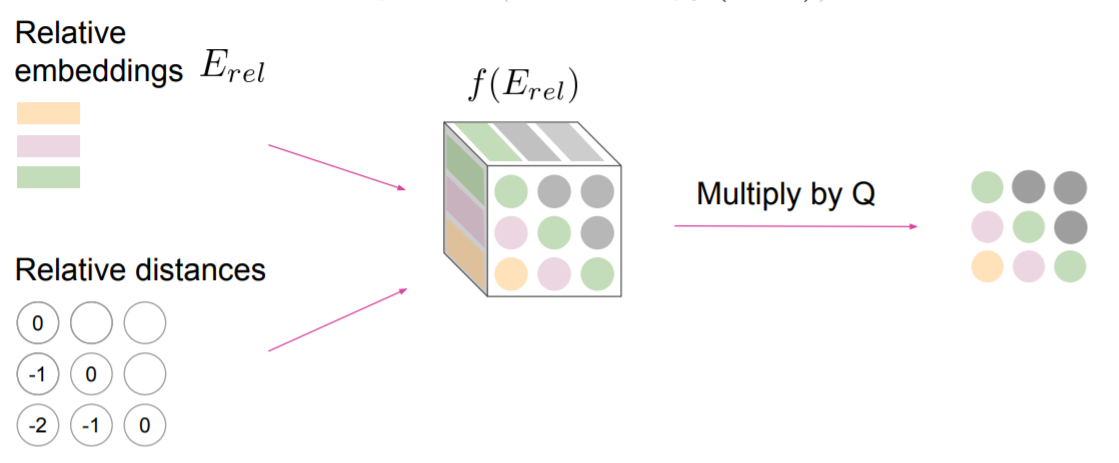
모든 시점의 거리를 계산해서 저장해야 하다보니, 위 그림과 같이 무척 큰 3d 텐서를 레이어마다 만들고 저장해야 했다. 위 텐서의 크기는 (2048, 2048, 512)이다. 실제로 한 레이어당 8.5gb가 필요하다.
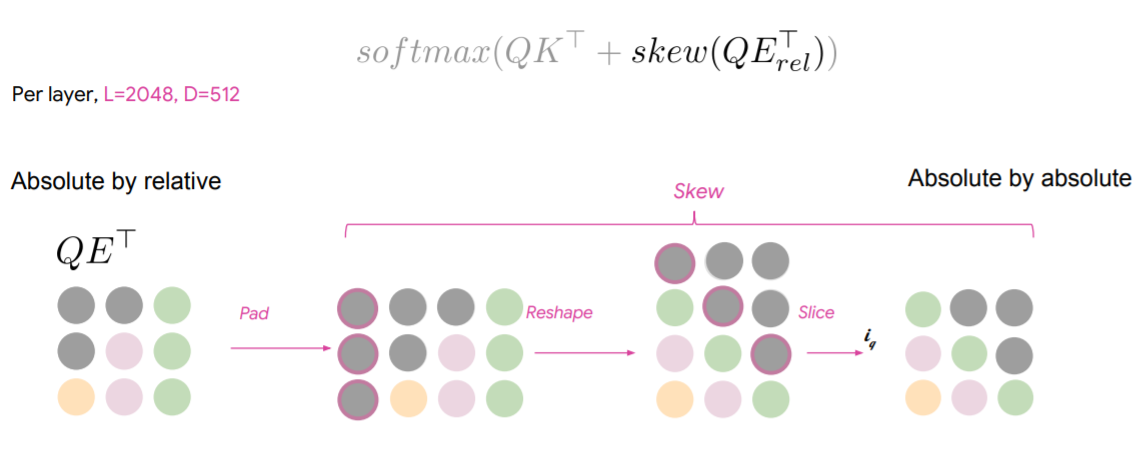
이를 약간의 트릭을 통해 극복하는데, 기존에는 Relative embedding을 맵핑하는 레이어가 별도로 있었다면, 이번엔 그냥 이를 Q에 행렬곱하고, 패딩을 붙이고, reshape하여 모양을 맞추고 잘라서 해결한다. 즉, 현재 시점에 필요한 임베딩 값만 가져와서 트릭을 만든 것이다. 이를 통해 레이어당 4.2Mb면 해결됐다고 한다. 복잡도로 봐도 에서 O(LD)로 획기적으로 줄어든다.
이는 이미지에서도 효과적인데, 이미지는 근접한 픽셀간의 상관관계가 매우 높은 데이터다. 흔히 지역적 정보라고 이야기하는 것인데, CNN은 이 지역적 정보를 잘 잡아내기 때문에 이미지에서 효과적으로 작동하는 모델이다.
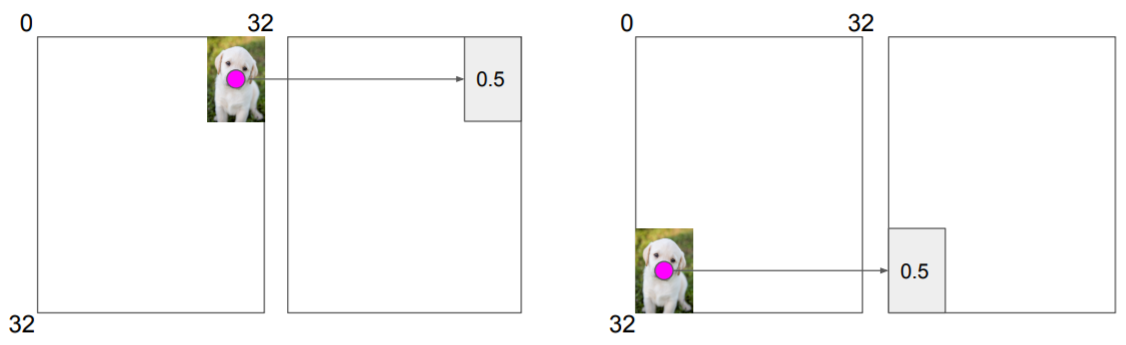
지역적 정보란, 예를 들어서 강아지 사진이 어디에 있든, 이를 잡아내는 필터라면 위치에 상관없이 잡아낼 수 있는 것을 의미한다. 왜냐하면 강아지를 나타내는 필터들은 필연적으로 서로 근처에 있게 되고, 필터는 이 근처에 있는 필터로부터 활성화되기 때문이다. 그런데, relative attention 역시 근처 픽셀값에 일종의 가중치를 주기 때문에 이러한 지역적 정보를 잘 잡아낼 수 있는 것이다.
