Intro
BERT와 GPT 이후에 수많은 사전학습 모델이 쏟아져 나왔다. 제각기 다른 데이터셋과 다른 목적함수, 모델 구조를 가지고 학습이 되었지만 한가지 동일한 것이 있었다. Pretrain -> Finetune으로 이어지는 프레임워크였다.
이는 사전학습 시에 가능한 대량의 코퍼스로 학습하여 모델은 일반화 성능을 확보하고, 다운스트림 태스크에 대해 추가적인 학습을 진행하여 각 태스크에 맞게 모델을 수정한다는 개념이었다.
하지만 의료, 법률, 논문, 금융 등 다양한 도메인에서 사전학습 모델을 사용하려고 하자 문제가 발생한다. 사전학습으로 일반화 성능을 확보한 줄 알았던 모델이 해당 도메인에 대해 제대로 성능을 내지 못하는 것이다. 즉, 기존의 사전학습된 모델은 아무 도메인에나 finetune만으로 충분한 성능을 내지 못한다.
그래서 다양한 트릭들이 연구되어 왔고, 논문화되지 않더라도 이 논문이 발표되던 2020년 당시 사람들이 전반적으로 가지고 있던 생각은 "모델을 좀 더 도메인에 적합하게 사전학습 시킬 필요가 있다" 라는 점이었다고 한다(주워들은 이야기임 오피셜 아님).
이 논문은 사실 내용은 단순하다. pretrain -> adaptive pretrain -> finetune으로 모델을 도메인 혹은 태스크에 한번 더 사전학습 시켜서 좀 더 finetune 시 성능을 높이자는 내용이다. 하지만 이것이 작동하는 이유와 과정에 대해 다양한 실험으로 구조화한 것이 주요한 포인트라 할 수 있을 것 같다. 실제로 그 덕분에 이 논문은 2020 ACL에서 Honorable Mention for Best Overall Paper 상도 탔다. 왜 그렇게 좋은 논문이라 평가받는지 하나씩 살펴보자.
Setting

이 논문에선 위와 같은 가정을 가지고 시작한다. 즉, 본래 사전학습 시 모델이 학습한 도메인이 있고, 우리가 학습시키고자 하는 다운스트림 태스크의 도메인이 있다. 그리고 우리는 해당 도메인에서 데이터를 구성하여서 finetune 데이터셋을 만들기 때문에 해당 데이터셋에 해당하는 영역(밝은 회색)도 존재하게 된다. 그리고 해당 도메인에서 특정 태스크(분류, 회귀, NER 등등)에 따라 또 부분집합이 형성된다.
여기서 중요한 점은 기존의 모델이 사전학습을 통해 알고있는 도메인과 타겟 도메인이 온전히 포함관계에 있지 않고, 부분집합을 형성한다는 점이다. 위 그림처럼 우리가 수행하려는 태스크 혹은 가지고 있는 해당 도메인의 데이터셋은 해당 도메인의 부분집합이기 때문에 당연히 본래 사전학습 도메인과 부분집합의 관계를 가지게 될 것이다. 타겟에서의 관계를 정리하면 다음과 같다.
Target Domain > Target Dataset > Target Task
Model
사전학습 모델로는 RoBERTa를 사용하고 있다. 이때 한가지 짚고 넘어갈 점은 RoBERTa 는 160GB의 사전학습 데이터로 학습한 모델이다. 즉, 이미 충분히 거대한 데이터로 학습했기 때문에, 이미 RoBERTa로 어느 도메인이든 커버가 가능하지 않을까? 라는 질문이 생길 수 있다.
하지만 이 논문에서 이야기하고자 하는 것은 모델이 사전학습 과정에서 학습한 도메인 여부가 중요한 것이 아니라, 각 태스크를 수행하고자 할 때 모델을 해당 도메인의 데이터로 다시 학습하여 파라미터를 아래 그림처럼 더 좁은 영역 혹은 사전학습과 다른 영역으로 가져갈 필요가 있다는 것이다.
Domain & Data
Domain 별 MLM Loss
이 논문은 특정 도메인에서 사전학습 모델의 성능을 높이는 것을 목적으로 하기 때문에 4가지 도메인을 선정하고 각 도메인 당 2개의 데이터를 이용하여 분류 태스크를 수행한다. 구체적인 도메인은 다음과 같다.
- Biomedical
- computer science publications
- news
- reviews
biomedical과 CS 논문이야 당연히 도메인이 좁고, 모델이 제대로 학습이 안되어 있다고 하자. 하지만 news와 review를 과연 모델이 사전학습 과정에서 학습이 안되었다고 할 수 있나? 라는 의문이 들 수 있다. 다시 이야기하지만, 모델의 파라미터를 (파라미터가 학습하는 공간 상에서) 더 태스크와 도메인에 적합한 좁은 영역으로 옮길 필요가 있다. 그리고 밑에서 보겠지만, 생각보다 아래 두 데이터 역시 사전학습 데이터와 비교하여 Out-Of-Domain으로 볼 수 있다.

각 도메인 별 데이터의 크기와 각 데이터 별 RoBERTa의 MLM loss를 보여주는 표이다. 살펴보면 알 수 있지만, RoBERTa의 사전학습 데이터가 가장 크며, 당연하게도 MLM loss도 더 낮다. 여기서 은 사전학습된 RoBERTa를 그냥 가져와서 MLM을 측정한 것이고, 는 이후 소개할 DAPT 방법론을 적용하여 모델을 해당 데이터에 적합시킨 후의 MLM loss이다. 특징들은 다음과 같을 것이다.
- RoBERTa의 사전학습 데이터에서 loss가 상당히 낮게 나온다.
- News에서 오히려 사전학습 데이터보다 loss가 낮다.
- News는 오히려 DAPT를 진행하고 나서 loss가 올라가는 모습을 보인다.
여기서 주목할 점은 News를 제외하면 사전학습 데이터보다 훨씬 나쁜 성능을 보이고 있다는 점이다. 즉, 기존에 사전학습된 데이터와 각 도메인의 분포가 상당히 다르다는 점을 알 수 있다.
Domain 별 Vocabulary 분포

위 그림은 stopword를 제외하고 빈도 수 기준 상위 10,000개의 단어에서 각 데이터가 얼마나 중복(overlap)되는지 보여주고 있다. 여기서 PT는 RoBERTa가 학습한 사전학습 데이터와 비슷한 데이터이다(RoBERTa는 코퍼스를 공개하지 않았다.). 위에서 발생한 도메인 별 성능 차이의 원인을 일부 여기서 찾아볼 수 있다. 각 도메인 별로 등장하는 단어들이 매우 상이하다는 점이다. 특히 상위 10,000개의 단어를 뽑았는데도 불구하고 절반이 넘는 단어가 사전학습과 다르게 나타나는 것은 생각보다도 각 도메인 별로 등장하는 단어들이 다르고, 이는 모델이 해당 도메인에 충분히 성능을 내기 힘들다는 것을 의미한다. 반대로 말하면 사전학습 데이터와 더 차이가 큰 도메인에서 더 큰 성능향상을 기대할 수 있을 것이다. 즉, 사전학습 모델을 해당 도메인에 그대로 사용하면 안된다.(당연한 이야기다.)

Resource 상황에 따른 구분

논문에서는 한가지 상황을 더 가정한다. 즉, 도메인 별로 사용할 수 있는 데이터 크기(5000 건 기준)에 따라 high resource와 low resource로 구분한 것이다. 이는 사전 학습 모델을 사용할 때 중요한 것이라 할 수 있다. 우리가 실험하고자 하는 도메인이 매우 좁은데, 데이터가 부족할 때와 충분할 경우에 수행할 수 있는 훈련 방법이 달라질 수 있기 때문이다.
Domain-Adaptive Pretrain(DAPT)
논문에서 제시하는 첫번째 방법론은 DAPT이다. 한마디로 설명하면 다음과 같다.
해당 도메인의 label이 없는 대량의 데이터가 존재할 때, 이 데이터로 pretrain(MLM)을 추가적으로 진행하는 것.
좀 더 자세히 설명하면, 예를들어 review 데이터의 경우 label이 없는 데이터가 50,000건이 추가적으로 존재하기 때문에, 해당 데이터로 MLM(Masked Language Modeling)을 추가적으로 진행하는 것이다. 해당 논문에선 모든 도메인에 대해 12,500 step을 더 진행했다고 한다.

여기서 비교하는 지표는 분류 성능이다. ROBA는 사전학습된 RoBERTa를 이용하여 바로 분류했을 때의 지표이고, DAPT는 해당 데이터를 이용하여 DAPT를 진행하고 나서의 성능, not DAPT는 해당 도메인 외의 다른 도메인에 DAPT를 적용했을 때의 성능이다. 이때 다른 도메인은 위의 vocabulary 장표에서 각 도메인별로 가장 낮은 값을 보인(vocab 분포가 가장 다른) 도메인을 선택했다고 한다. 이를 통해서 알 수 있는 것은 다음과 같다.
- DAPT의 효과는 도메인을 가리지 않고, resource의 크기를 가리지 않고 보인다.
- AGNews 데이터는 사전학습 데이터와 유사한 분포를 보이고, MLM loss에서도 떨어지지 않는 모습을 보였듯이, DAPT의 효과 역시 거의 없다.
- HyperPartisan은 news 데이터 임에도 DAPT 효과를 보여주고 있다. (뇌피셜 : HyperPartisan 데이터셋은 정치 편향 뉴스 데이터셋이어서 이러한 DAPT가 효과를 발휘한 것 같다. 즉, vocabulary 분포는 비슷할 수 있지만, class 별로 분명한 차이를 보였을 것.)
- not DAPT는 확연히 성능 저하를 보인다. RoBERTa를 그냥 가져다 쓴 것보다도 성능이 좋지 않은 경우가 많다. 즉, 아무 데이터로 DAPT를 진행한다고 성능이 좋아지는 것이 아니라 수행하고자 하는 태스크와 비슷한 데이터로 DAPT를 진행해야 한다.
- not DAPT로 성능향상이 불가능한 것은 아니다. SC 분야의 데이터셋은 공통적으로 not DAPT가 RoBERTa 보다 성능이 좋았다. NEWS와 REVIEW는 40%의 unigram overlap을 가지고 있지만, NEWS에 DAPT를 진행할 경우 REVIEW에 대해 성능 향상을 보였다. 즉, 우리가 막연히 이야기하는 데이터 분포 혹은 도메인 데이터의 정의는 상당히 모호한 개념이며 이에 대한 추가적인 연구가 더 필요하다.
Task-Adaptive Pretraining
DAPT가 label이 없지만 태스크와 동일한 도메인의 데이터로 사전학습을 추가적으로 진행하는 것이라 했다. 하지만 동일한 도메인에서도 태스크에 따라 데이터 분포가 달라질 수 있다. 가령 동일한 뉴스 데이터라 하더라도 가짜뉴스 판별 태스크와 뉴스 카테고리 분류 태스크는 전혀 다른 데이터 분포를 가지게 될 것이다. 가짜뉴스 판별 태스크는 매우 특정한 주제(정치, 경제 등)에서 주로 추출한 뉴스 데이터로 구성되어 있는 반면, 뉴스 카테고리 분류 태스크는 매우 넓은 주제에서 추출한 뉴스 데이터로 구성되어 있을 것이다.
다운스트림 태스크를 수행하기 위해 수집한 데이터를 이용하여 진행하는 사전학습을 TAPT라 정의하고 있다.
TAPT는 태스크에 매우 적합한 데이터만 선별해야하는 특성 상 DAPT보다 훨씬 데이터셋의 크기는 작지만, 태스크와 매우 밀접한 분포를 가지는 데이터라는 점에서 일종의 trade-off 관계를 가지게 된다. 여기서 발생하는 장점이 데이터셋이 작다보니 연산량이 적다는 것이다.
논문에서는 TAPT를 몇가지로 나눠서 실험을 진행하는데 하나씩 살펴보도록 하자.
TAPT, DAPT + TAPT

TAPT만 진행할 경우와 DAPT를 진행하고 TAPT를 진행할 경우(DAPT + TAPT)를 비교해보도록 하자. TAPT는 우선 RoBERTa보다 모든 데이터셋에서 성능이 좋았다. 특히 RoBERTa의 사전학습 데이터셋에도 일부 포함되어 있는 NEWS 데이터에서도 성능이 좋았다. 즉, 사전학습 시에 학습한 도메인이라 할 지라도, 다운 스트림 태스크 수행 전에 TAPT를 진행하면 성능향상을 기대할 수 있다.
DAPT + TAPT는 당연하게도 TAPT만 진행한 경우보다 전반적으로 성능이 향상되는 모습을 보여주고 있다. 하지만 만약 레이블된 데이터가 많은 경우(REVIEWS, AGNEWS, RCT) 에서는 TAPT만 진행한 경우와 성능 차이가 크지 않았다.
일반적으로 태스크를 위해 수집된 데이터는 레이블을 달아야 하기 때문에 많아야 1만건 내외인 반면, DAPT에 사용하는 해당 도메인 데이터셋은 훨씬 크다는 점을 감안하자. 즉, 모델 학습을 위해 필요한 연산량 차이를 고려하면 TAPT의 성능 향상폭이 상당하다는 것을 알 수 있다.
만약 TAPT를 먼저 진행하고 DAPT를 진행하면 어떻게 될까? 논문에서는 따로 결과를 정리해두지는 않았다. 하지만 TAPT를 먼저 진행하면 catastrophic forgetting(새로운 태스크를 학습하면서 기존에 학습한 태스크에 대한 성능이 급격히 떨어지는 현상)이 발생했다고 한다. 해당 태스크에 대한 성능이 떨어지고 MLM에 대한 성능만 확보되는 것을 의미한 것 같은데, 자세히 서술되어 있지 않아서, 확신할 수가 없다.
Cross-Task Transfer
그렇다면 동일 도메인 내에서 A 태스크 데이터를 이용해 TAPT를 진행하면 B 태스크에 대해서 성능이 어떻게 될까? 이를 실험한 것이 cross-task transfer이다.

그 결과는 RoBERTa와는 직접적으로 무엇이 났다고 할 수 없지만, TAPT보다는 확실히 성능이 저하되는 모습을 보였다.
즉, 동일 도메인이라 하더라도 태스크마다 데이터 분포의 차이가 크다. 또한, 대량 코퍼스를 이용한 사전학습만으로는 특정 도메인에 적합한 모델이 될 수 없다.
한가지 의문은 여기서 도메인과 태스크를 상당히 애매하게 정의하고 있는데 반해, 이 부분의 서술은 너무 확신에 가득차서 정말 그렇다고...? 라는 의문이 든다.
Augmentation for TAPT
태스크를 위해 준비된 데이터는 사실 극소량이고, 대부분의 도메인 데이터들은 레이블이 없는 상태이다. 그런데 연산량이나 학습 데이터셋의 크기를 고려할 때 TAPT가 DAPT만큼이나 혹은 그 이상 효과가 좋다면, TAPT를 위해 태스크 데이터를 좀 더 확보할 수 없을까? 이 논문에서는 두 가지 방법을 제안하고 있다.
Human Curated-TAPT
사람이 직접 annotation하는 것은 가장 직관적인 방법일 것이다. 즉, 해당 도메인의 데이터 중에 태스크와 직접적으로 관련이 있는 데이터를 사람이 선별하여 이 데이터를 이용하여 TAPT를 진행하는 것이 Human Curated-TAPT이다.
논문에서는 annotation을 진행하기보다 아래와 같이 환경을 설정하여 실험을 진행한다.
- RCT : RCT는 기본적으로 180000 건의 태스크 데이터가 있는데, 이 중에서 500 건만 샘플링하여 기본 TAPT로 간주하고 전체 데이터를 사용할 경우를 Human Curated-TAPT로 간주한다.
- HYPERPARTISAN : 두가지 버전의 데이터가 있는데, 이때 515건의 레이블이 존재하는 데이터를 기본 TAPT로 간주하고 5000건의 레이블이 없는 태스크 데이터를 Human Curated-TAPT로 간주한다.
- IMDB : 여기서만 추가적으로 데이터를 수집하고 이에 대해 annotatoin을 진행한다. 이때 기존의 IMDB 데이터와 동일 분포를 유지했다고 한다.
결과는 아래와 같다.
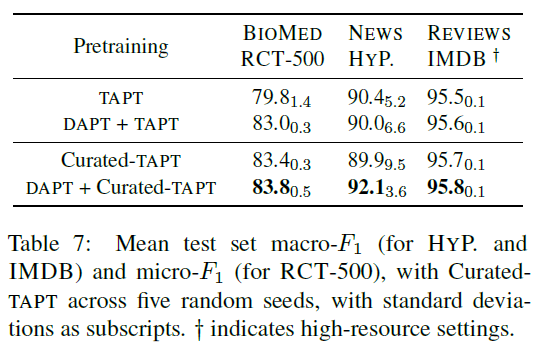
데이터가 많을수록, 태스크 분포와 가까울수록 성능이 점차 높아지는 모습을 보여주고 있다. 또한, 기본적으로 태스크 데이터와 많은 IMDB의 경우 성능 향상 폭이 크지 않은 것을 알 수 있다.
Automated Data Selection for TAPT
하지만 실제 상황에서는 추가적으로 annotation을 진행하는 것이 쉬운 일은 아니다. 도메인이 일치하는 대량의 데이터셋을 구하는 것이 가능하다는 보장도 없고, DAPT를 수행하기 위한 컴퓨팅 자원 역시 만만치 않다. 이때 자동화된 방법으로 태스크 데이터와 분포가 가까운 레이블이 없는 데이터를 선별할 수 있는 방법은 무엇일까?
해당 논문에서 제안하는 방식은 상당히 단순하다. 도메인 데이터와 태스크 데이터를 모두 하나의 임베딩 공간에 넣고, 여기서 태스크 데이터와 가까운 도메인 데이터를 TAPT에 추가적으로 사용하는 것이다.
이때 임베딩은 VAMPIRE(Gururangan et al., 2019)이라 하는 빠르고 단순한 BoW 방식의 LM 모델을 사용했다.
그 순서는 다음과 같다. 컴퓨팅 자원이 부족한 상황이라는 가정 하에 진행된다는 점을 유의하자.
- VAMPIRE를 대량의 도메인 데이터셋을 이용해 사전학습 시킨다.
- 사전학습한 VAMPIRE를 이용하여 도메인과 태스크 데이터의 임베딩 벡터를 얻는다.
- 1) knn을 이용하거나 2) 랜덤하게 도메인 데이터를 샘플링하여 TAPT를 진행한다. Knn을 이용하는 것은 태스크 데이터와 가까운 데이터를 샘플링한다는 의미이다.
그 결과는 다음과 같다.
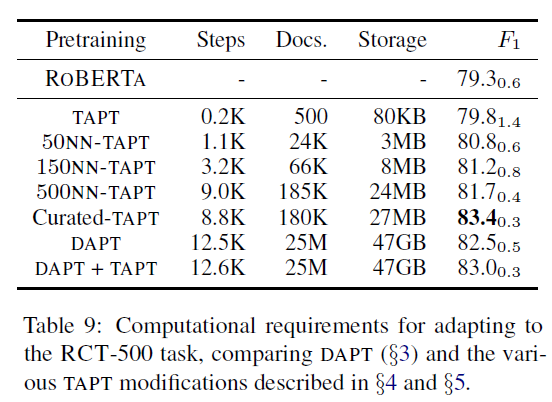
전체 결과를 살펴보면 knn-TAPT가 기존의 TAPT보다 항상 성능이 좋다는 것을 보여준다. 이는 기존의 TAPT가 데이터가 부족한 한계점을 가지고 있고, 태스크 데이터와 비슷한 분포를 가지는 추가 데이터를 가지고 오면 성능이 향상된다는 것을 보여준다.
특히 k의 값이 커지면 커질수록(추가적인 데이터가 많아질 수록) TAPT의 성능은 점차 DAPT 성능에 가까워지는 것을 볼 수 있는데, TAPT와 DAPT의 step 수나 데이터 사이즈의 차이를 고려하면 놀라운 성능 개선이라고 할 수 있을 것 같다.
Conclusion
결론을 내보자면, 우리가 단순히 데이터라고 뭉뚱그려 이야기하는 것은 사실 여러 층위를 이루고 있고, 이 계층 구조를 잘 살펴서 pretrain 및 finetune을 진행해야 한다가 핵심인 것 같다.
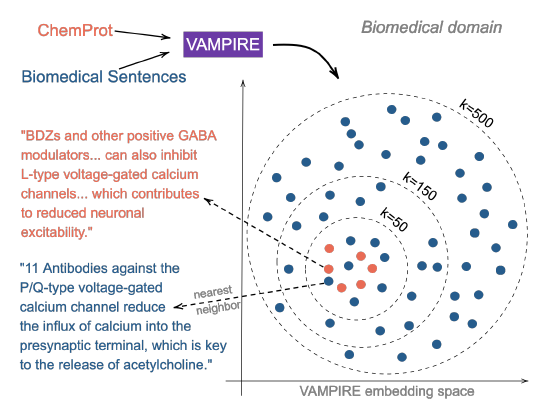
특히 논문에서 knn-TAPT를 위 그림처럼 묘사하고 있는데, 같은 도메인 데이터에서도 태스크와 관련된 데이터가 저런 식으로 분포하고 있다면 정말로 TAPT나 DAPT는 유의미한 작업이라 생각한다. 논문이 전반적으로 특별한 내용을 이야기하고 있지는 않지만 초반에 제시하고 있는 사전학습 데이터, 도메인 데이터, 태스크 데이터의 그림이 상당히 의미하는 바가 큰 것 같다. 논문을 읽어보지 않은 사람이라면, 한번쯤 읽어보는 것도 좋을 것 같다.

글 잘 읽었습니다!