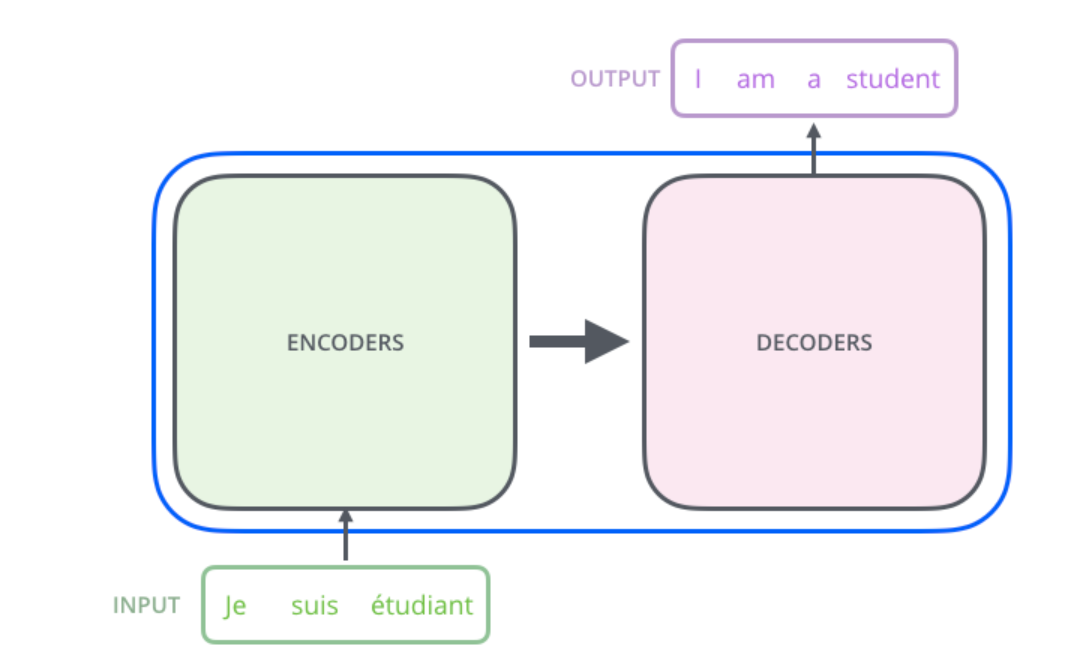
본격적인 트랜스포머 구현에 앞서 다시한번 모델 구조를 정리하고, 하이퍼 파라미터로 무엇들이 있는지 살펴보고자 한다. 전반적인 모델 구조는 이전의 게시물들을 통해 알아보자.
핵심
- seq2seq Encoder-Decoder 구조
- Encoder와 Decoder를 연결하는 구조
- Senquence Length : 512
- 각 블록 간 구조는 동일, but weights are not shared + learnable
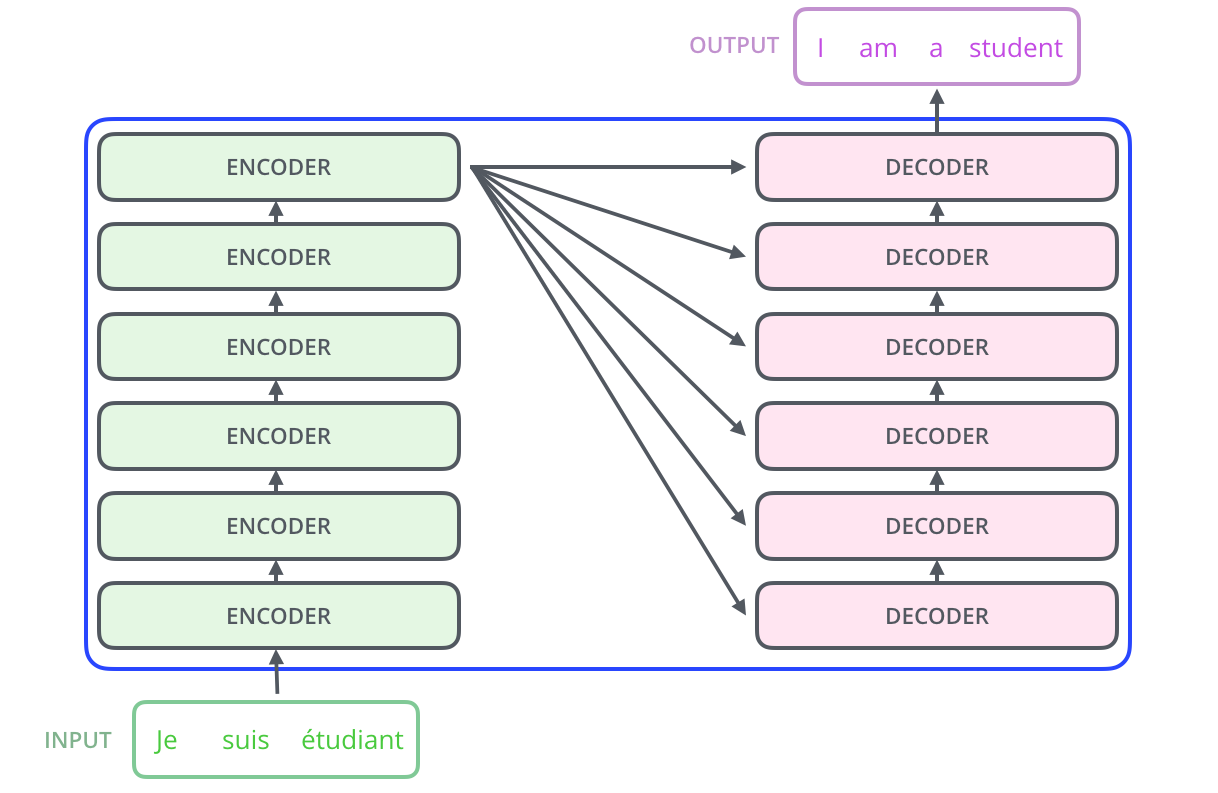
Encoding Component
- Stack of Encoding Stack
- 6 stack
- Unmasked
Encoder Stack
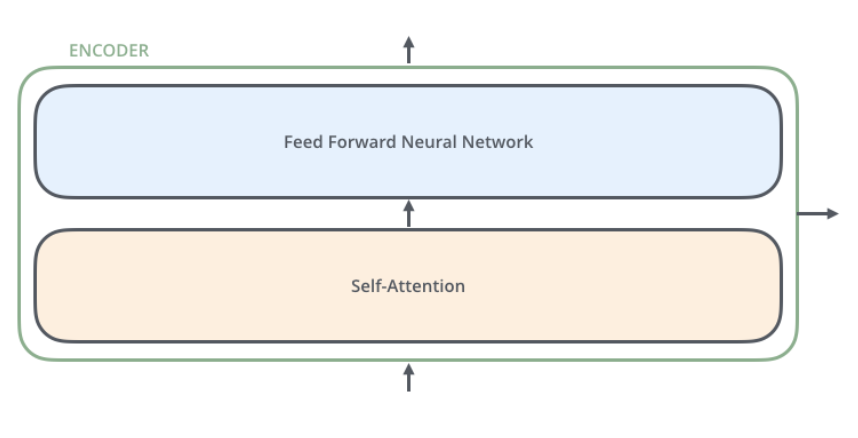
-
Self Attention -> FFNN
-
Self Attention Layer
: 토큰 혹은 하나의 단어가 처리될 때, 함께 주어진 input sequence의 단어들을 얼마나 중요하게 볼지 계산 -
FFNN
: 각 포지션마다 동일한 FFNN이 적용됨(Q, K, V를 나누는 이유) -
model_dim = 512
-
num_head = 8
-
FC Layer num_node = 2048
Decoding Component
- Stack of Decoding Stack
- 6 stack
- Masked
Decoder Stack
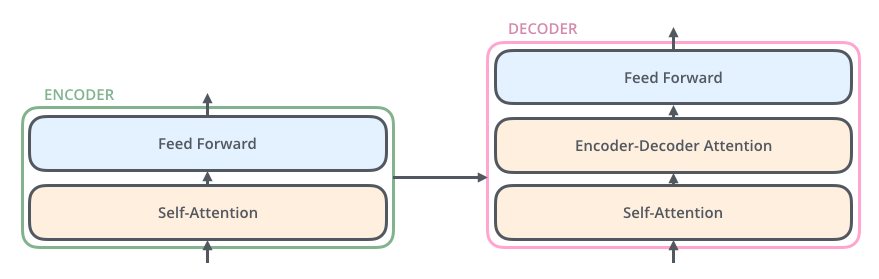
- Masked Self Attention -> Encoder-Decoder Self Attention -> FFNN
- Masked SElf Attnetion
: 다음 시점의 토큰을 예상할 때 이후 포지션의 정보는 활용하지 않도록 masking 처리. - Encoder-Decoder Self Attention
: 인코더에서 온 정보를 디코더의 정보와 attention을 수행
-FFNN
: Encoder Stack과 동일
실제 모델 구조
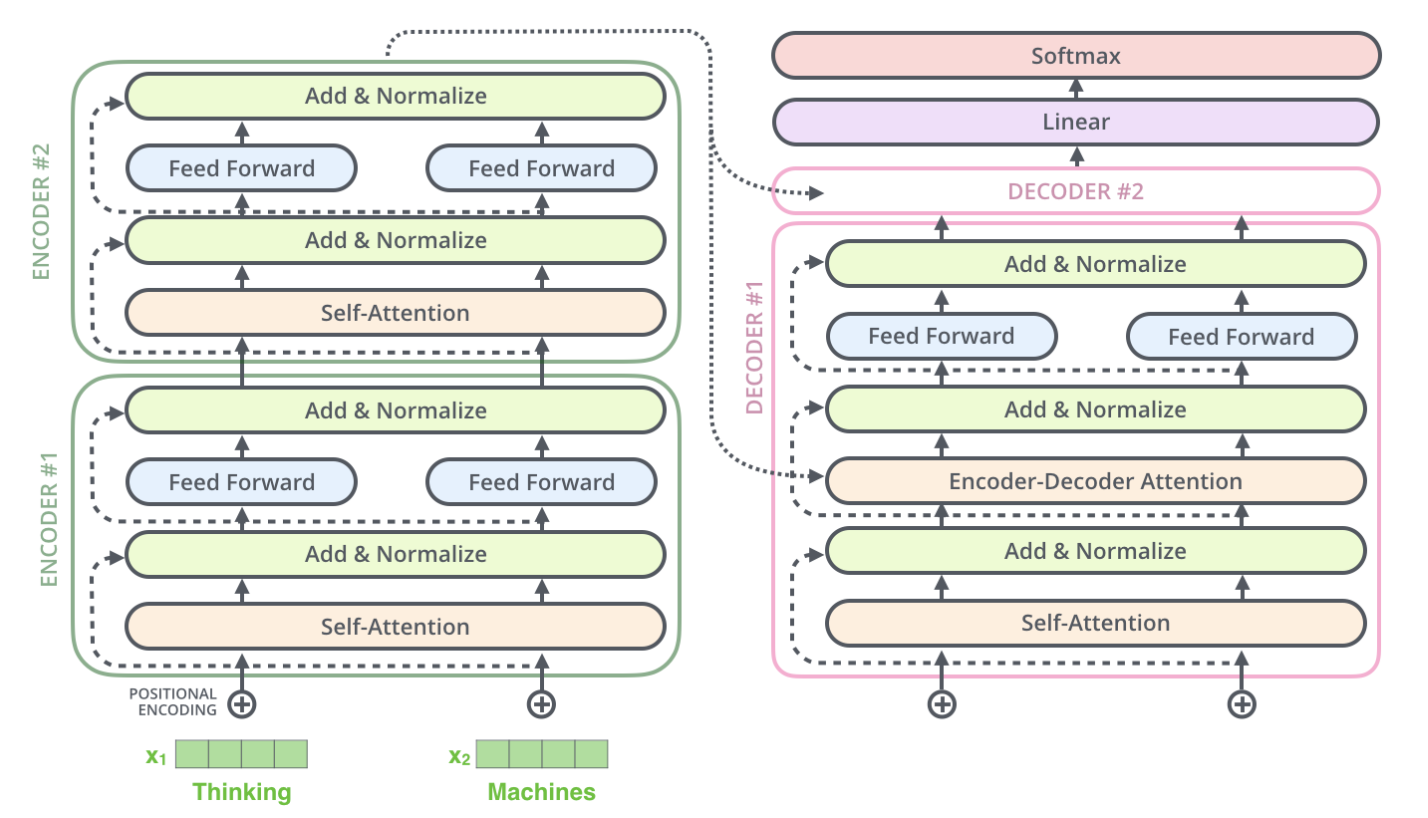
Encoder
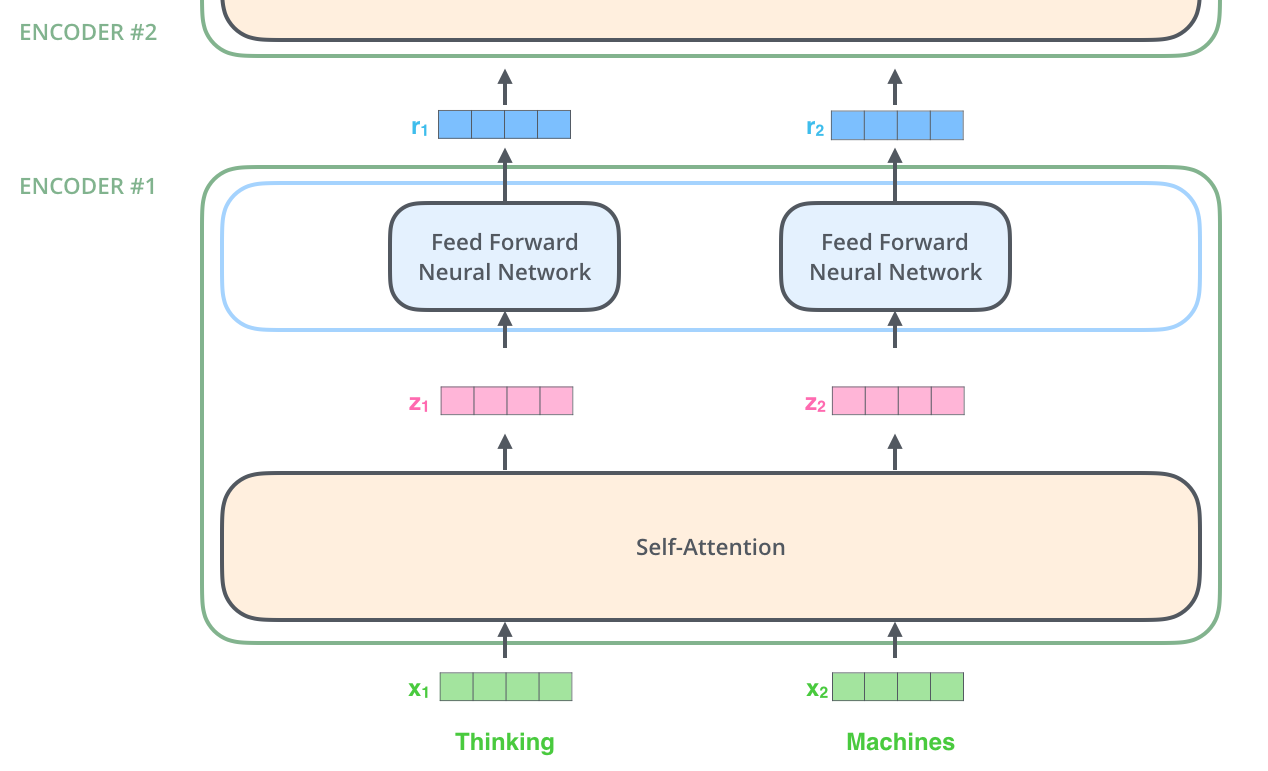
각 인코더에서 Stack으로 입력된 입력값은 input -> mapping -> Multi-head Attention -> Feed Forward -> Residual Connection & Normalization 순으로 거치게 된다.
Input
- 임베딩 벡터
: 가장 첫번째 인코더의 input 역할(pretrained 사용 가능) - 이후 인코더
: Encoder Stack의 output의 모양은 input과 동일
-> 이전 Encoder Stack의 output이 다음 Encoder Stack의 Input으로 사용됨
Positional Encoding
-
기존의 RNN류 모델은 Sequential하게 토큰을 input으로 받음
-
Transformer류 모델은 Parallel하게 토큰을 input으로 받음
=> 토큰의 위치 정보가 손실되어 버림
: Positional Encoding을 통해 위치 정보를 삽입 -
concat이 아닌 element-wise 덧셈
-
(sequence_len, embedding_dim) + (embedding_dim) 형태가 됨.
positional encoding이 가져야 하는 두가지 성질
positional encoding의 크기가 위치에 관계없이 동일해야 한다. (벡터의 크기)
포지션이 멀어질수록 거리도 비례해 늘어나야 한다.
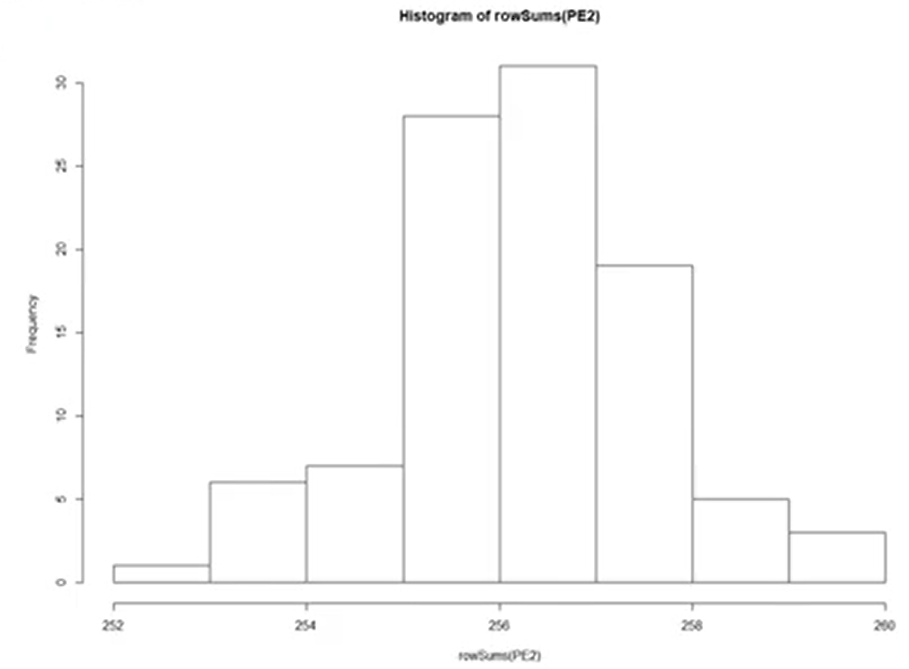
positional encoding 벡터의 l2 norm을 히스토그램으로 나타낸 것.
언뜻 벡터 크기가 차이가 큰 것으로 보이지만 평균은 256.25, 표준편차는 1.35로 벡터들의 크기가 거의 차이가 나지 않는다. 즉, 첫번째 성질을 가지고 있는 것을 볼 수 있다.
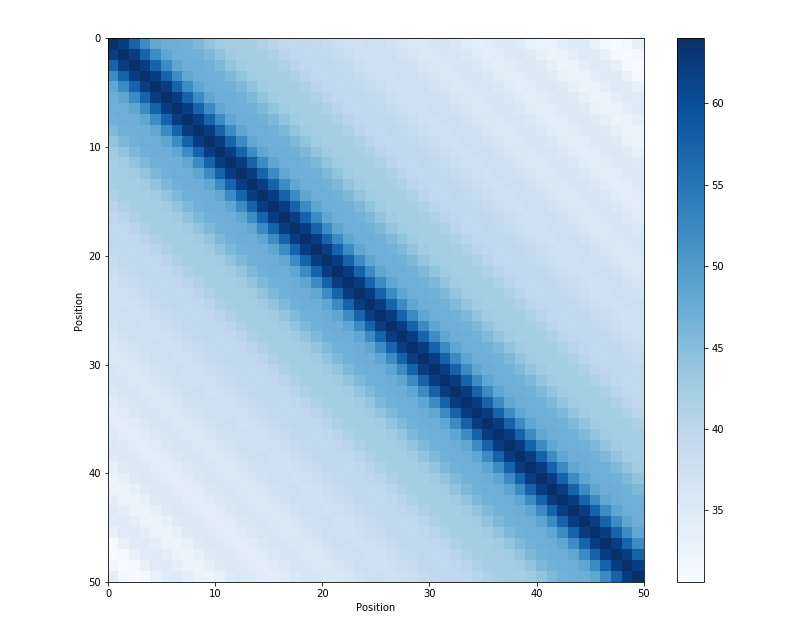
각 포지션 별 positional encoding 벡터의 거리 시각화.
색이 옅을 수록 거리가 멀다는 뜻인데, 대각행렬성분이 자기 자신과의 거리를 의미하니 대각 행렬 성분에서 멀어질수록 점차 옅어지는 모습을 보이고 있다.
Self-head Attention
이때 Self-attention layer는 dependency가 있다. 즉, 각 토큰 간 연산이 이루어지기 때문에, 각 토큰을 연산할 때 다른 토큰을 이용하게 된다. 하지만 Feed Forward layer는 각 토큰마다 동일한 FC layer를 이용하기 때문에 다른 토큰을 이용하지 않아 dependency가 없다. 이때 동일한 FC layer는 가중치가 동일한 layer라는 뜻이다. 인코더의 Stack을 통과한 각 포지션은 입력값의 각 포지션과 동일한 포지션을 의미하게 된다.
각 토큰은 self attention을 통해 다른 토큰을 이용하여 처리되어 동일한 포지션으로 나오게 되고, 이는 동일한 FC layer를 이용하여 동일한 포지션으로 최종적으로 나오게 된다.

it이라는 토큰의 attention 가중치를 시각화 한 모습이다. it은 the animal에 강하게 집중하고 있는 모습이다.
Query, Key, Value
Self-Attention은 Q, K, V 세가지 벡터를 이용해 연산이 이루어지게 된다. 이때 벡터라고 하는 것은 각 토큰마다 세가지 벡터를 가진다는 뜻이고, 입력값 전체로 보자면 (sequence_length, model_dimension) 모양의 세가지 행렬이 된다. 각각의 역할은 다음과 같다.
1. Query : 현재 기준으로 삼을 단어의 representation을 의미한다.
2. Key : Query와 비교할 각 토큰의 representation을 의미한다.
3. Value : 실제로 attention 매커니즘을 통해 가져올 각 토큰의 representation을 의미한다. Q, K, V는 하나의 input vector로 만들게 된다. 일반적으로 input vector의 차원보다 Q, K, V의 차원이 낮게 되는데, 이는 Multi-head Attention의 각 head에서 연산된 결과를 concat하여 최종적인 산출물을 만들기 용이하도록 의도한 것이다. 이때 만들어지는 과정은 input vector에 Q, K, V 각각의 weight matrix를 이용해 선형 변환 혹은 mapping을 통해 만들어진다(생각보다 너무 단순한 것 같은데 트랜스포머는 사실 뜯어보면 다 단순한 아이디어다.).
Multi-head Attention
Attention을 여러 번 수행하면, 각각의 head가 다른 식으로 문장을 보게 된다. 동일한 input vector가 선형 변환을 통해 각 head마다 다른 값을 가지게 되기 때문이다.
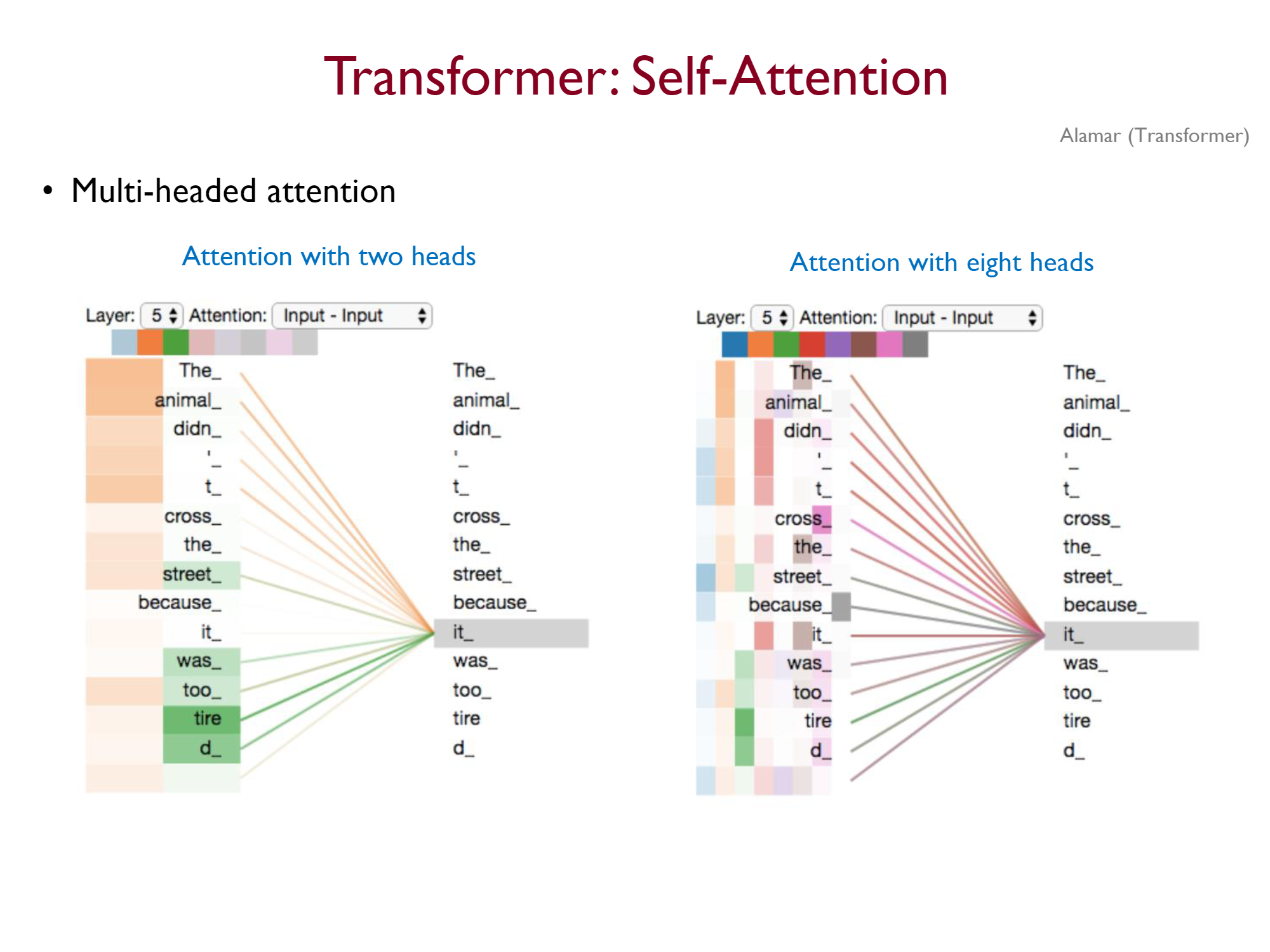
위 그림은 headr가 2개일 때와 8개일 때를 시각화한 것이다. 8개일 때를 보게 되면 it에 대해서 어떤 head는 행동을, 어떤 head는 부정을, 어떤 head는 동일한 객체에 집중하고 있는 것을 볼 수 있다.
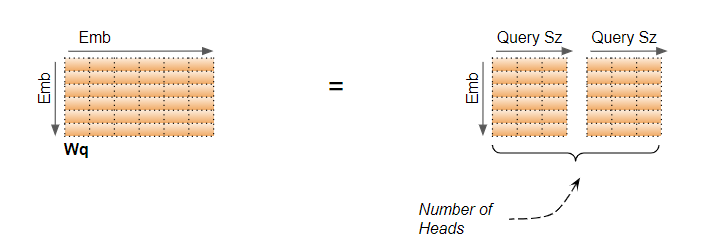 실제로 구현할 때는 input*weight_q를 통해 mapping이 이루어지고 그 결과물을 slicing하여 각 head로 사용하게 된다.
실제로 구현할 때는 input*weight_q를 통해 mapping이 이루어지고 그 결과물을 slicing하여 각 head로 사용하게 된다.
Feed Forward Layer
Self-Attention 을 통과한 벡터는 동일한 Feed Forward layer를 통과하게 된다. 즉, 각 토큰을 독립적으로 동일한 FC layer에 통과시키는 것이다.
이걸 강필성 교수님은 1d-Conv로 보셨는데,
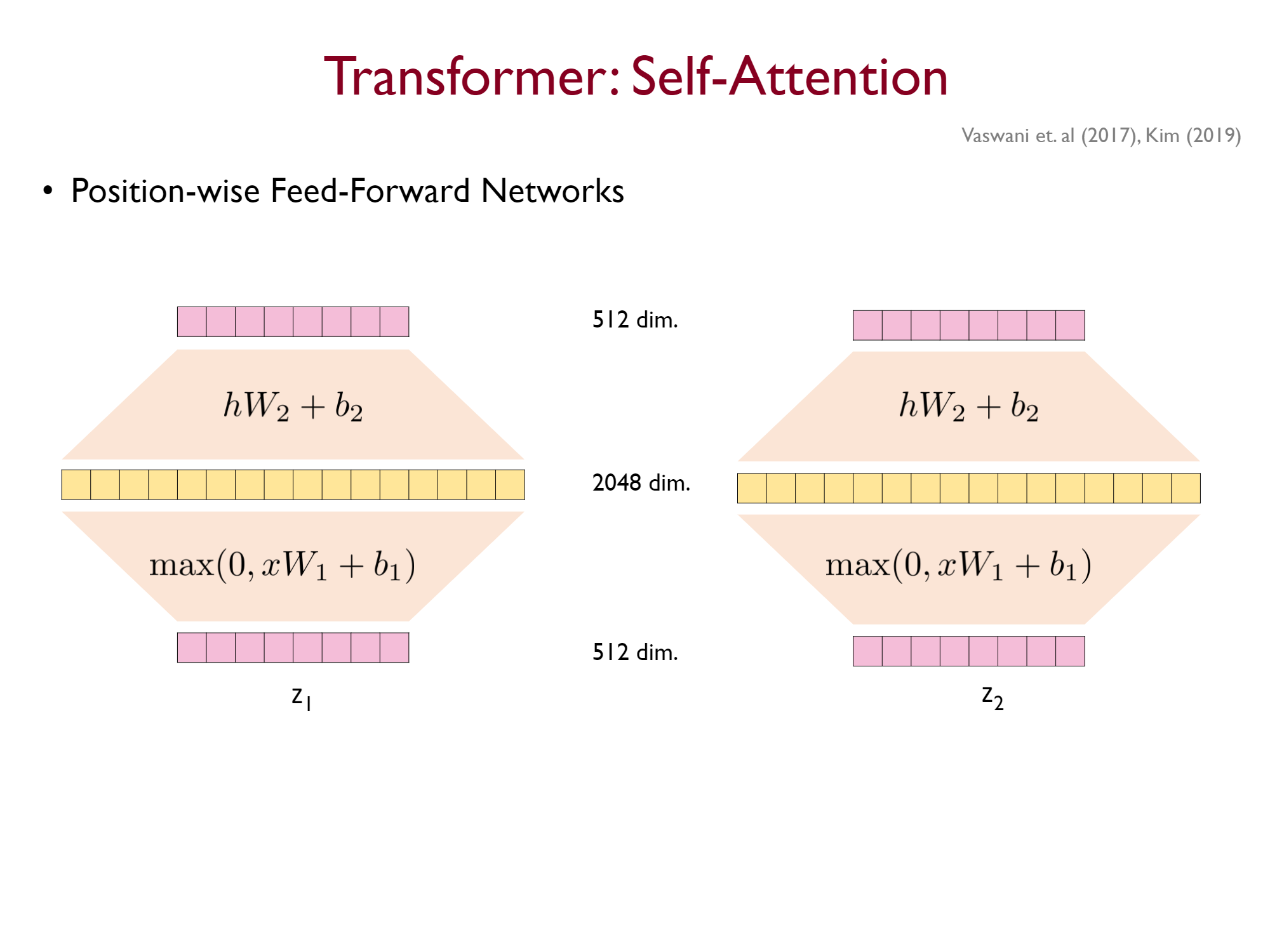
기존의 FC layer로 생각하면 위와 같은 구조를 가지게 되지만
FC layer의 input을 (sequence_length, model_dim)의 이미지로 보게 되면 아래와 같이된다.
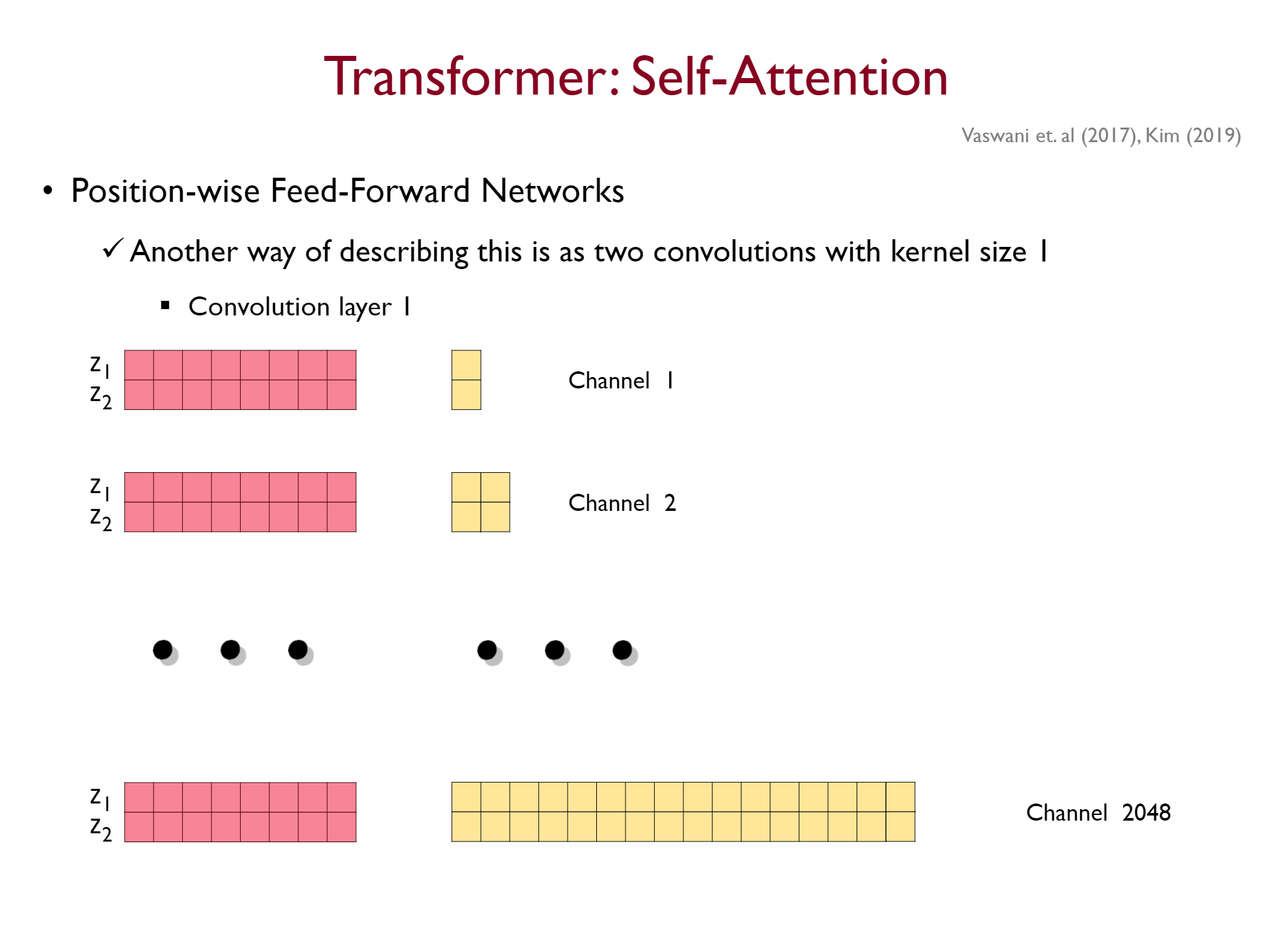
즉, 커널 사이즈가 (1, model_dim)인 CNN 과정을 거치는 것이라 할 수도 있는 것이다.
Residual Connection
residual connection은 resnet에서 제안된 구조인데, 그래디언트가 잘 전파될 수 있도록 레이어의 출력값으로 x + f(x)을 사용한다. 이를 통해 미분값이 1 + f'(x)가 되어, 최소한 그래디언트가 1이 되어 역전파가 원활히 이루어지도록 한다.
layer normalization
LM은 Batch Normlaization처럼 각 레이어의 입력값을 안정화시켜 학습이 원활하게 이루어지도록 만드는 장치이다. 구체적으로 batch norm은 배치 단위로 이루어지는 반면에 layer norm은 각 레이어의 노드를 단위로 정규화가 이루어지게 된다.
여기서 의문이 생기는 것이 RNN류의 모델은 순환하는 모델 구조로 인해 BM의 적용이 어려워서 LM을 사용했지만, 트랜스포머는 병렬처리가 가능하도록 만들어놓고 왜 굳이 LM을 사용했는지 의문이 든다. 이 부분에 대해서는 당장 해답을 찾을 수 없어서 조금 더 찾아봐야 할 것 같다.
결국 각 Stack은 Self-Attention sublayer와 fully-connetecd sublayer 각각의 출력에 residual connection과 layer norm을 거쳐 input과 정확히 동일한 shape의 output을 산출하게 된다.
Decoder
디코더와 인코더는 거의 동일한 구조를 가지고 있지만 두가지가 다르다. Attention과 Masked Multi-head Attention인데, 이를 보자면 다음과 같다.
Masked Multi-head Attention
디코더는 이전의 정보만 활용하여 다음 토큰을 예측해야한다. 즉, teach-forcing을 사용한다 하더라도, 각각의 시점은 이전 시점의 정보만 활용해야 한다. 이는 디코더의 Self-Attention에 각 시점마다 이후 시점의 토큰에 -inf를 attention으로 가지도록 masking하여 해결한다(혹은 각 이후 임베딩 벡터에 0을 곱하여서도 할 수 있다.).
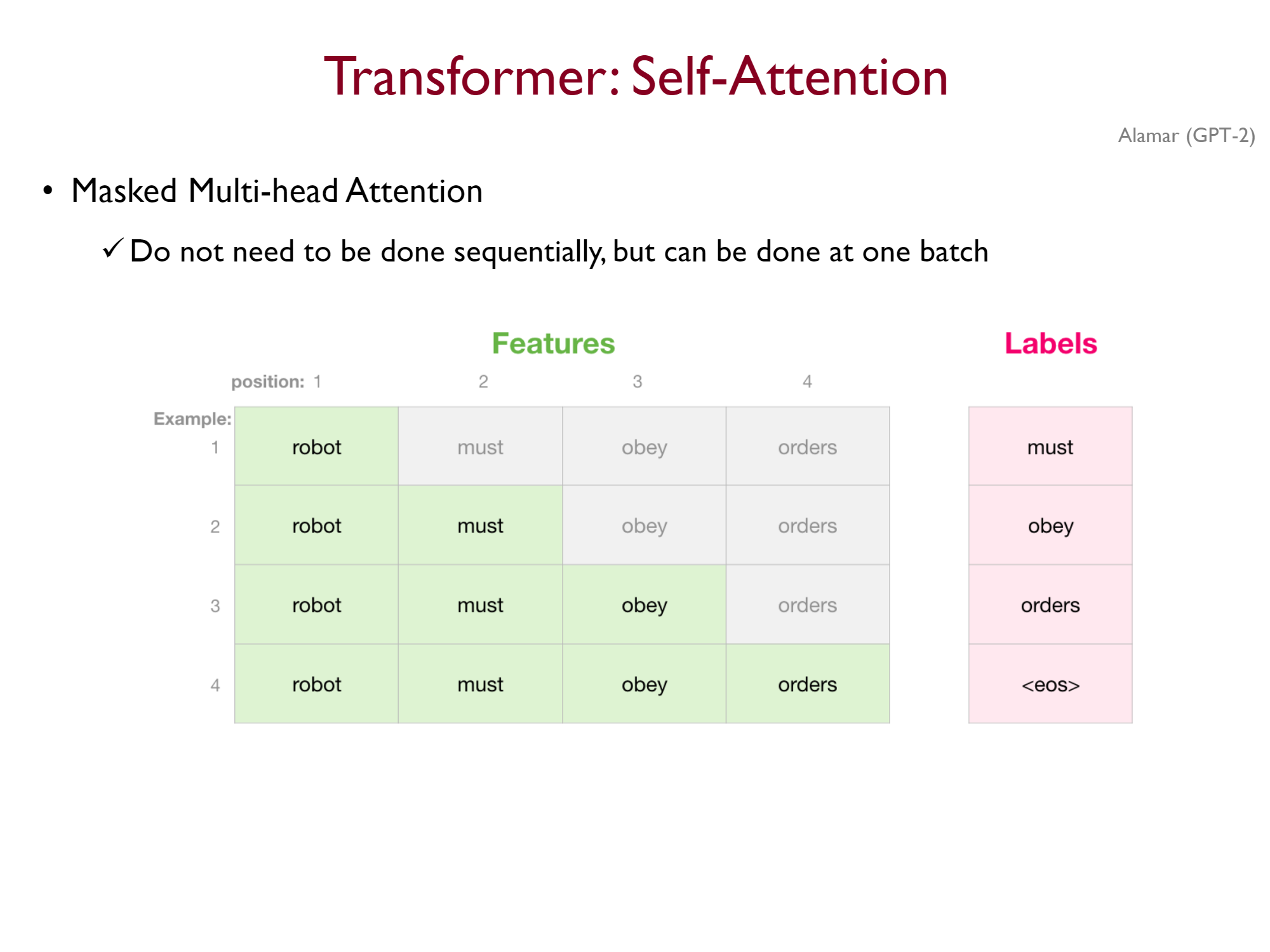
단순하게 생각하면 디코더는 sequencial하게 처리되어야 한다고 생각할 수 있다. 하지만 teach-forcing을 하게 되면 결국 masking을 통해 행렬로 연산이 가능해진다.
Multi-head Attention with Encoder Output
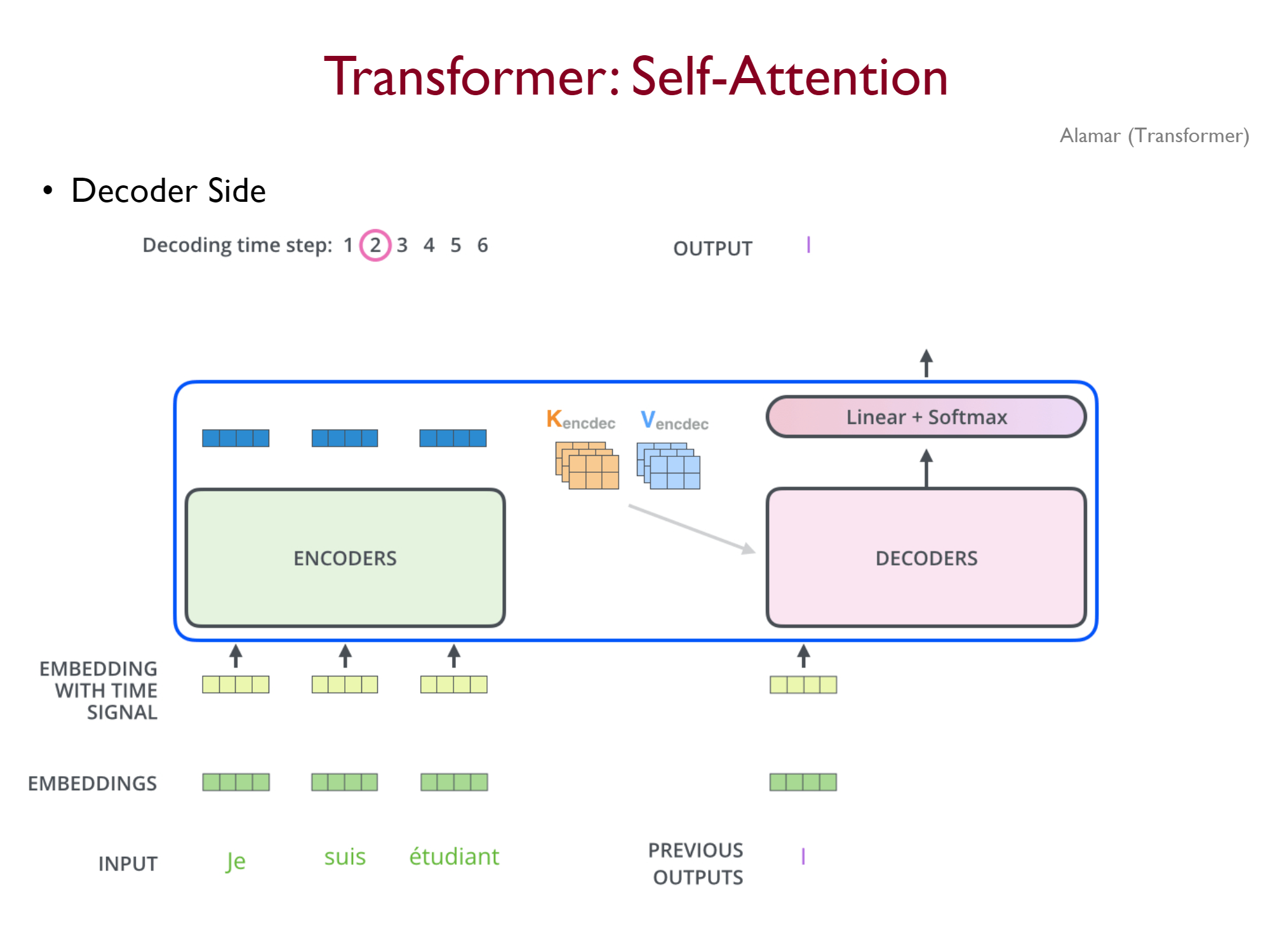
디코더는 masked self-attention sublayer를 통과한 이후 인코더를 최종적으로 통과한 결과를 이용해 Attention을 수행하게 된다. 이때 인코더의 각 벡터가 K와 V가 되고, 디코더의 self attention을 통과한 벡터가 Q가 되게 된다.
참고
Jay Alammar의 Transformer 설명 글
고려대학교 DSBA 강필성 교수님 Transformer 설명 영상
Attention Is All You Need
Amirhossein Kazenejad의 PE 설명 글
Ketan Doshi의 설명 글(개인적으론 best)
