투빅스에서 텍스트 세미나에 참여하게 되면서, 스탠포드 대학교의 유명한 자연어 처리 강의인 CS224N을 듣고 리뷰하는 과정을 시작하게 되었다. 다시한번 내가 아는 자연어 처리 내용을 정리하고, 더 많은 것들을 배울 수 있는 좋은 기회인 것 같다. 1주차 내용을 시작해보자.
인간은 지속적으로 지식을 전달하고 발전시키는 존재이다. 아마, 이게 대부분의 동물과 인간을 구별짓는 큰 차이라고 생각한다.
강의에선 첫 날이라 그런지 자연어 자체에 대한 이야기를 많이 한다. 그 중에서 가장 기억에 남는 것은, 인간은 결국 언어를 통해 지식을 전달한다는 점이다. 인간은 다른 인간들과 네트워크를 형성하고, 자신이 가진 지식을 다른 사람과 교환한다. 이런 언어는 결국 인간이라는 종이 지구 상에서 가장 발전된(사실 논란의 여지가 많은 말일 수도 있다.) 종족으로 우뚝 서게 만들었다. 지식이 교환되며 발전되고, 선대의 지식은 후대에 전해지며 계속 이어진다.
하지만 언어는 휘발성이 강하다. 소리는 에너지가 작아 멀리 가지 못하고, 인간의 기억력 역시 그렇기 때문이다. 그래서 문자가 탄생했다. 언어를 기록하고 멀리도 보낼 수 있도록. 언어가 멀리 갈 수 있게 되자, 멀리 떨어진 로마의 상품이 신라까지 오게 되고, 그 과정에서 신뢰가 쌓이고, 이전과 비교할 수 없을만큼 많은 정보가 훨씬 오래, 멀리 전달될 수 있었다.
그래도 시간은 흘렀고, 정보가 광랜을 통해 전달되는 현대에 와서, 이렇게 지금 블로그에 작성되는 글자처럼, 문자를 통해 전달되는 정보는 한계가 명확했다. 정보이론의 관점에서 보면, 인간의 언어는 정말 비효율적이다. 복잡한 정보를 담을 수 있지만, 구조 역시 복잡해서 한눈에 들어오지도 않고, 필요없는 정보도 담겨 있어서 쓸데없이 정보만 많다. 일기 예보를 정형 데이터로 받는 것과 날씨 예보 방송을 보는 것을 생각해보면 쉽게 알 수 있을 것 같다.
그럼 언어에 대해 조금 더 자세히 살펴보자.
하나의 단어가 어떻게 의미를 표현할까?
단어는 의미가 담겨있다. 어떤 사람이 "의자"라는 단어를 말하면, 네개의 다리가 달리고, 앉을 곳이 있고, 등받이가 있을 수도 있는 어떤 사물을 나타낸다. 그리고 "의자"라는 단어는 책상, 공부, 도서관 등 다양한 단어들과 일종의 관계를 가지고 있다. 즉, 단어들은 거미줄처럼 복잡한 관계를 가지고 있고, 이러한 관계를 바탕으로 우리는 단어들을 엮어서 복잡한 의미를 전달하는 것이다.
이를 표현한 것이 Wordnet이다. 단어들의 관계를 상하위 관계로 나타낸다. 하지만 이렇게 언어의 관계를 표현하면, 여러가지 문제가 생긴다.
- 언어는 뉘앙스를 가지고 있다. 하지만 워드넷은 너무 분명한 관계를 표현한다.
"너 참 잘생겼다"라는 문장은 정말 미남을 보고 하는 말일 수도 있지만, 못생긴 사람이 잘생긴 척 한다고 비꼬는 말일 수도 있다. 이때, "잘생기다"라는 단어는 워드넷에 의해 의미를 파악할 수 없다. - 새로운 단어를 워드넷에 포함시키기 힘들다.
수많은 단어의 관계를 포함한 워드넷에 하나의 단어를 추가하는 것은 꽤 번거로운 일일 수밖에 없다. 하지만 수많은 단어가 새로 생기는데, 이를 다 업데이트 할 수 없다. - 주관적이다.
- 시간과 비용이 많이 소모된다.
- 흔히 자연어 처리에서 사용하는 유사도 비교가 불가능해진다.
그러면 어떻게 해야 단어 간 관계를 잘 표현할 수 있을까? 가장 기본적으로 흔하게 접하는 one hot encoding이 있다. 
이렇게 하나의 단어가 하나의 column이 되도록 표현하는 것인데, 무척 직관적이고, 전처리도 무척 간단하다. one hot encoding에선 하나의 단어를 하나의 구별되는 사물로 간주한다. 하지만 이 역시 치명적인 문제점이 있다.
- 단어 벡터들이 모두 직교한다. 즉, 모든 단어들의 유사도가 0이다. 하지만 비슷한 단어들은 분명 수없이 많은데, 이를 알 수가 없어진다.
위에서도 호텔과 모텔은 매우 유사하지만, 전혀 반영하지 못하고 있는 모습이다. 이를 해결하기 위해선, 아예 인코딩을 통해 단어 벡터들의 유사도를 학습하여 벡터를 만들어볼 수 있지 않을까?
이러한 아이디어를 기반으로 탄생한 것이 분산 표상이다. 분산 표상란, 한 단어의 의미는 자주 같이 사용되는 단어들에 의해 정해진다는 것이다. 이 아이디어가 현재 자연어 처리의 기본을 이루는 매우매우매우매우매우매우 핵심이다.
이를 이용해 단어 벡터를 구하게 되면, 다음과 같이 매우 dense하고 비교적 적은 차원으로 단어들을 표현할 수 있게 된다.
Banking = [0.286, 0.325, 0.32, -0.3, -0.236]
사실 5차원보다 큰 차원을 이용하지만(보통 100차원 단위를 이용하는 것 같다) 어쨋든 one hot vector보단 작아진다. 이를 이용하면, 벡터 내적을 이용해서, 단어 간의 유사도를 계산할 수 있게 된다.

위 그림은 단어들의 유사도를 2차원 공간에 표현한 것이다. 표면, 실제로 be 동사들끼리 모여있고, 분사로 만드는 조사인 have가 모여있는 등 실제로 비슷한 의미나 역할을 하는 단어들이 근처에 위치해있는 것을 알 수 있다.
Word2vec
그러면 어떻게 단어를 분산 표상을 이용해서 나타내게 될까? Mikolov가 발표한 word2vec은 분산 표상을 실제 알고리즘으로 구현한 것이다. 그 기본적인 아이디어는 다음과 같다.
- 무척 큰 텍스트 데이터가 있다.
- vocab 안에 있는 모든 단어는 벡터를 통해 표현된다.
- 문장을 지나가면서 중심단어 c와 주변단어 o가 만들어진다.
- 벡터를 이용해 c와 o의 유사도를 측정하게 된다.
- c가 등장했을 때, o가 등장할 확률을 올리도록 벡터를 조정한다.
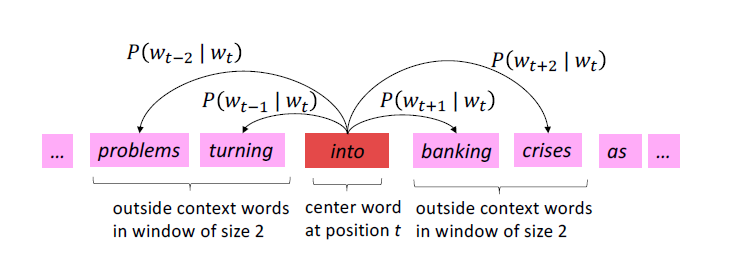
위 사진에선 into가 중심 단어이고, 주변의 4개의 단어가 주변 단어이다. into가 등장할 때 주변 단어들이 등장할 확률을 최대화하도록 하는 것이다. (사실 확률은 아니긴 하다. 가능도다)
그래서 word2vec의 가능도는 다음과 같아진다.
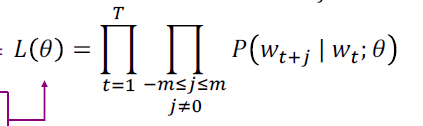
문장을 지나가면서 각 중심단어가 등장할 때, 주변단어가 등장할 확률의 곱이다. 이때, 파라미터 는 벡터이다.
그리고 이를 목적함수로 바꾸면, 단순히 negative log liklihood가 된다.

여기서 우리가 모르는 항은 하나다. 어떻게 를 구할 수 있을까? 사실 딥러닝에서 이를 자주 구하는 방법이 있다. 소프트맥스 함수를 이용하는 것이다. 즉,
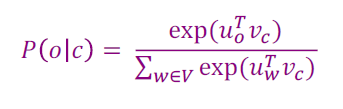
이 식이 될 것이다. u,v 두 벡터가 비슷하다면, 내적 값은 커지고, 다르다면 내적 값은 달라질 것이다. 두 단어의 의미가 비슷하면, 두 단어의 내적이 커지고, 역시 커지게 된다.
- exponential 함수의 사용은 모든 u, v 조합의 내적을 양수로 만들어서 확률이 될 수 있도록 한다. summation 함수 역시 확률 꼴로 만들기 위해 사용한 것이다. normalize 해준다.
softmax 함수의 뜻을 풀어서 설명해주셨는데, soft는 아무리 작은 확률이라도, 확률을 보여준다는 뜻이고, max는 확률이 제일 큰 값을 내보낸다는 뜻이라고 한다.
이를 optimization 하는 과정은 딥러닝에서 자주 볼 수 있는 Gradient Descent를 사용한다. 이는 자주 배워왔으니, 설명을 생략하고자 한다(사실 쓰면 너무 길어지고, 이 스터디가 그 정돈 알고 시작했을 것이라 생각한다.). 하나 유념해야 할 것은 모든 단어는 벡터가 두가지라는 것이다. 하나는 중심단어일 때 사용하는 벡터이고, 다른 하나는 주변단어일 때 사용하는 벡터이다.
손실함수를 에 대해 미분하는 방법은 다음과 같다.

