1. 오늘 할 것
이어서 직렬화를 계속 작업을 해볼 것인데
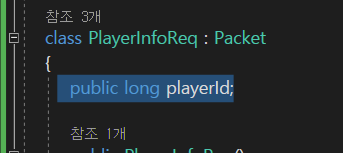
그래서 이런 고정된 사이즈의 데이터가 아니라
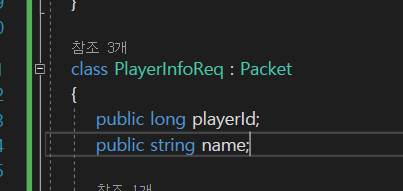
string같은 가변적인 사이즈의 데이터를 갖는 것에 대해서
어떻게 처리를 할것인지를 알아볼 것이다.
즉, 어떻게 넘기고 어떻게 추출을 할 것인지
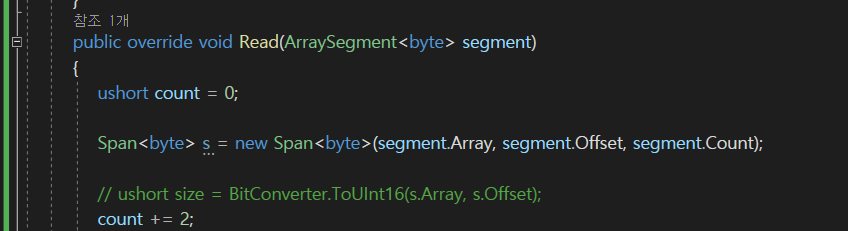
그전에 잠깐 수정을 하자면 count += 2;가 아니라
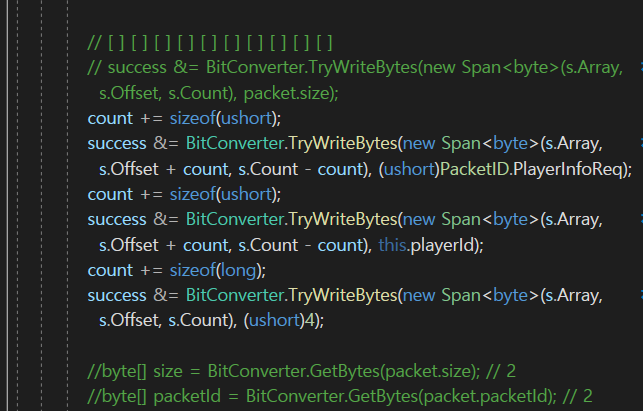
이렇게 하자.
그리고
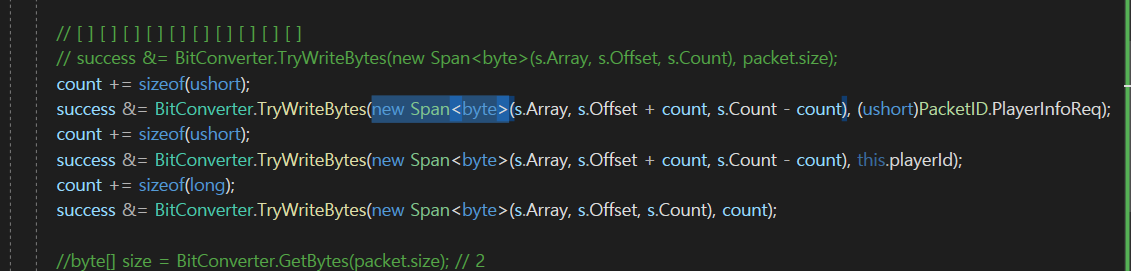
이런식으로 new Span< byte >를 이용을 해서 데이터를 넣어주어도
크게 잘못된 방식은 아니지만
Slice를 이용한 방법도 있다고 했다
그래서 이방법을 보여주자면은
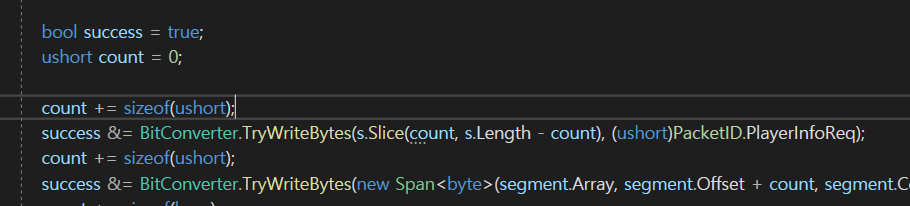
시작 offset은 count가 될 것이고 Length같은 경우에는
s.Length - count가 될 것이다.
그래서 packetId, playerId를 넣을때는
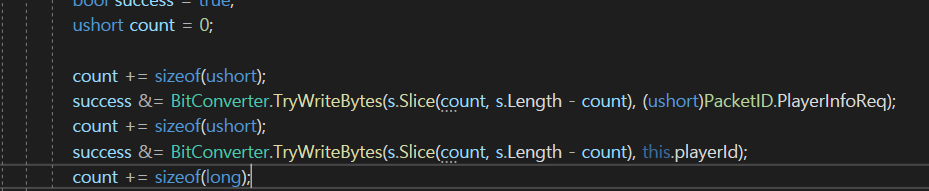
이렇게 Slice를 할 것이고
마지막 경우에는 원본을 넣는 것이니까
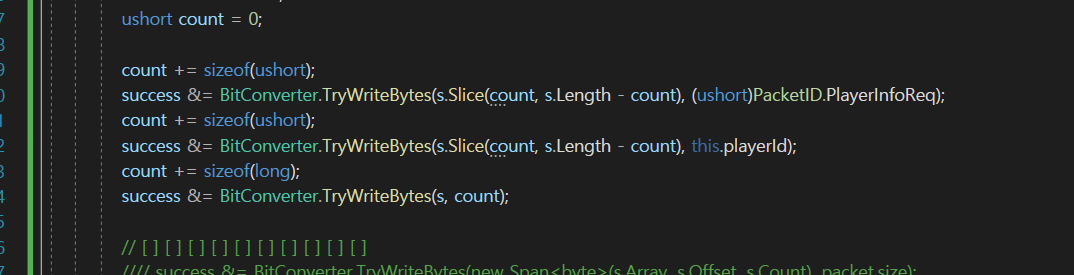
그래서 이렇게 수정을 해줄 수 있을 것이다.
Read()도 고쳐 주도록 하자.
이렇게 만들어 주자.
이녀석~
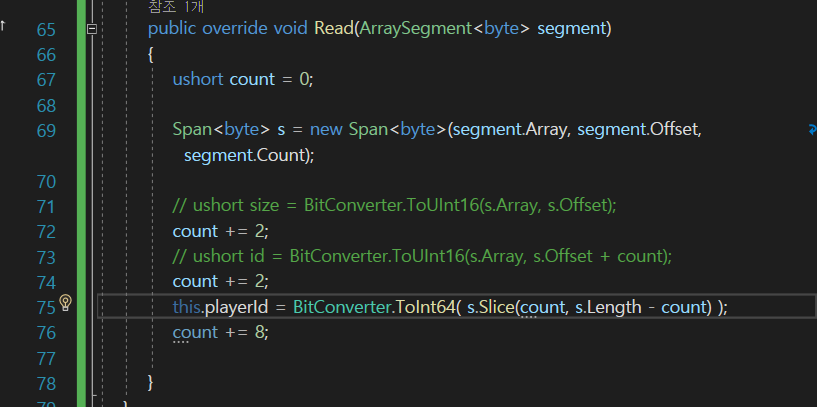
이렇게 바꿔주자.
그래서 수정한 부분 클라세션에도 똑같이 복사를 해주고
테스트를 해보도록 하자.
그러면
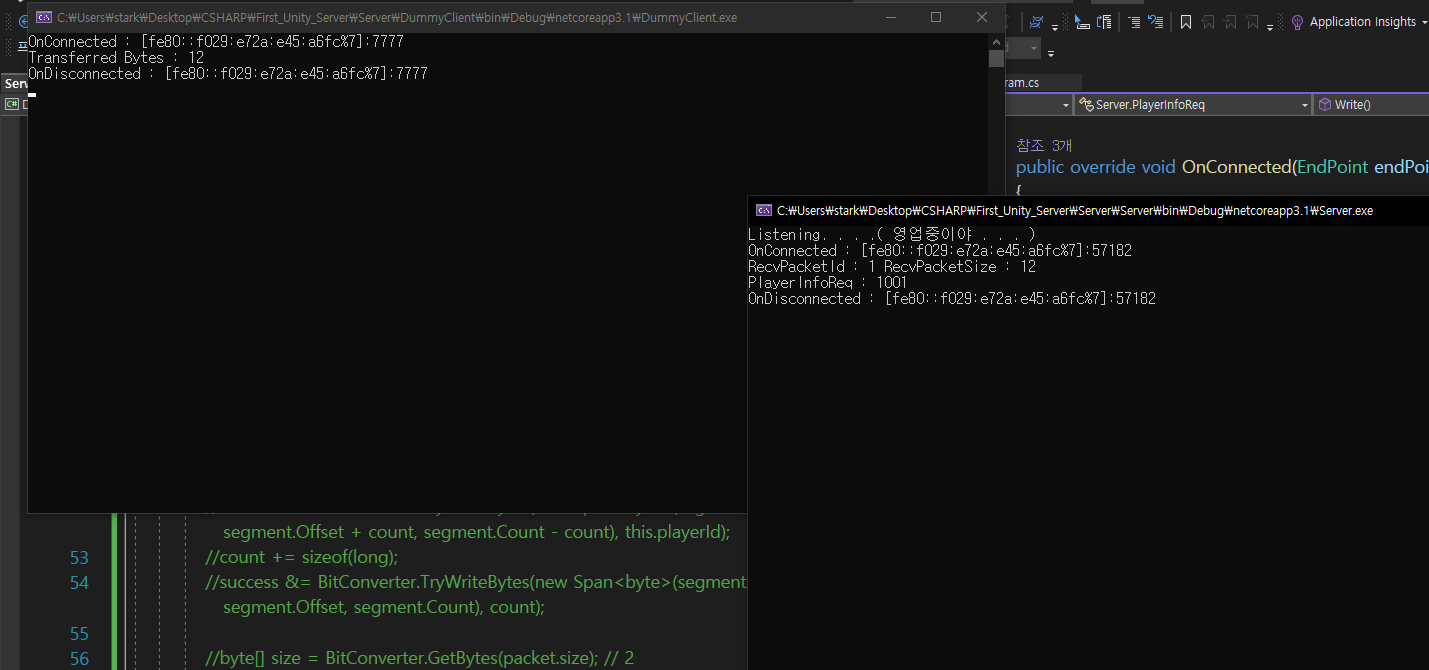
잘된다
이까지 수정을 조금 해보았다
2. 오늘 할 것 시작
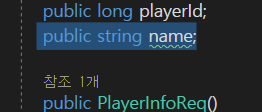
그러면 이제
string타입을 어떻게 직렬화를 해서 보내주고 받을 지 생각을 해보자.
그러면 먼저 UTF-8 || UTF-16을 사용할 것인지 정해줘야 한다.
C#에서는 기본적으로 UTF-16을 사용하기 때문에
이녀석을 굳이 8로 변환해서 다시 보내주기 보다는
그냥 16을 사용하자.
그래서 16으로 보내준다음에
파싱을 하는게 조금더 수월 할 것이다.
그런데 16을 사용한다고 해서 이게 몇바이트 짜리인지 알 수 없다.
근데 이게 C++문자열 이라고 한다면
끝에 항상 NULL로 끝나니까 ( 0x00 00 이런식으로 끝나니까 )
문자열이 끝났는지 아직 남았는지를 판별 할 수 있었는데
C#은 c++처럼 NULL로 끝나지 않는다.
그래서 string을 보낼때 통째로 바이트 배열로 만든 다음에 보내는 것이 아니라
2바이트 크기로 이 string의 크기가 어느정도인지를 먼저 보내고
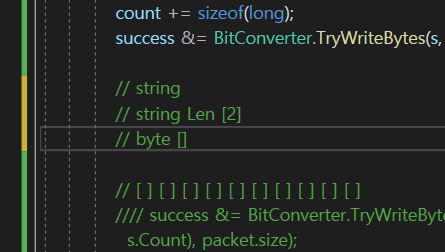
그다음 해당하는 크기의 데이터를 바이트 배열로 보내면 좋을 거같다! 라는 생각이 든다.
그래서 두단계로 보내는데 ( 경합 조건 발생안하나??)
string이 갈것인데 Length로 크기가 얼마얼마 짜리가 갈것이다! 라고 보내고
그다음에 실제로 그 크기만큼을 바이트 배열로 보내는 것이다.
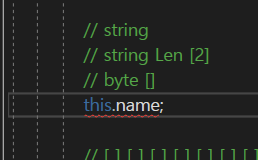
그래서 this.name을 보내는데
일단 name을 바이트 배열로 바꾸어야 한다.
예를들어
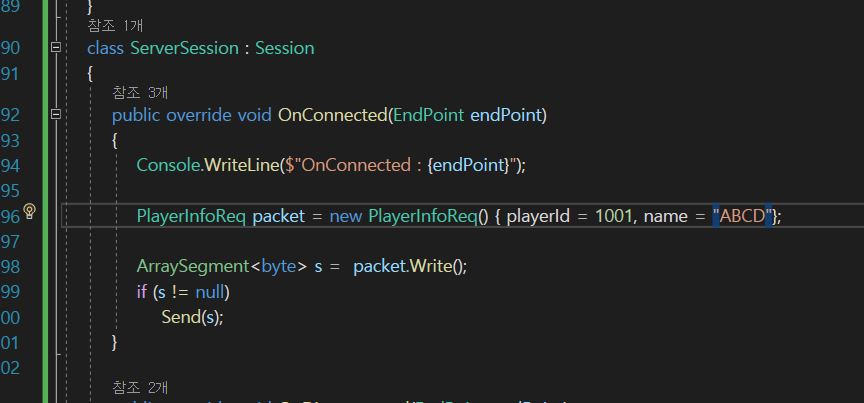
이렇게 보낼 때
name = "ABCD"라고 하면 문자열의 길이는 4가 될 것이다.
그런데 this.name.Length를 바이트 배열로 변환을 하면은
4바이트가 아니라 8바이트가 나오게 될 것이다.
(왜 =>
)
( 이전 수업 시간에 UTF-16은 문자 하나를 2바이트로 한다고 했었다.
그래서 A = 2byte 이런식이라 ABCD -> 8byte가 됨 )
그래서 길이는 4가 나오는데 UTF-16이라 바이트 배열로 바꾸면 8바이트가 나옴.
그래서 this.name 크기대로의 바이트 배열로 나타낼 수 있는 방법이 없을까?
라는 생각을 하게된다.
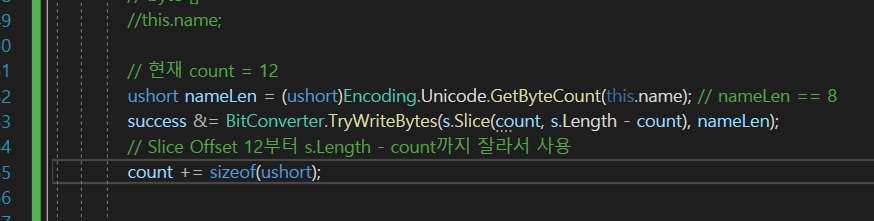
당연히 그런게 다 마련이 되어있다.
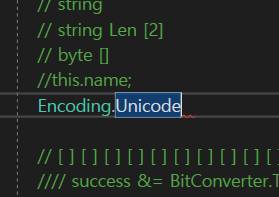
이게있는데 default가 UTF-16이다.
이렇게하면 name을 바이트 배열로 변환 되었을 때의 길이를 나타내게된다.
(즉, 8이 나올 것이다)
이것을
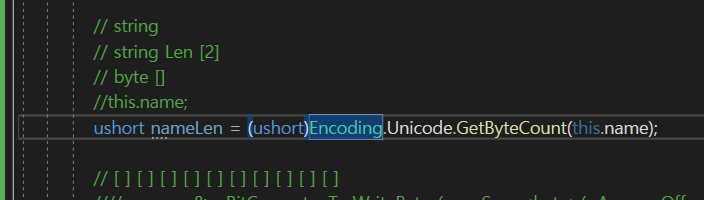
이렇게 받아주자.
그리고 이까지 작업을 한다음에
진짜로 데이터를 넣어주기 시작해야 된다.
질문
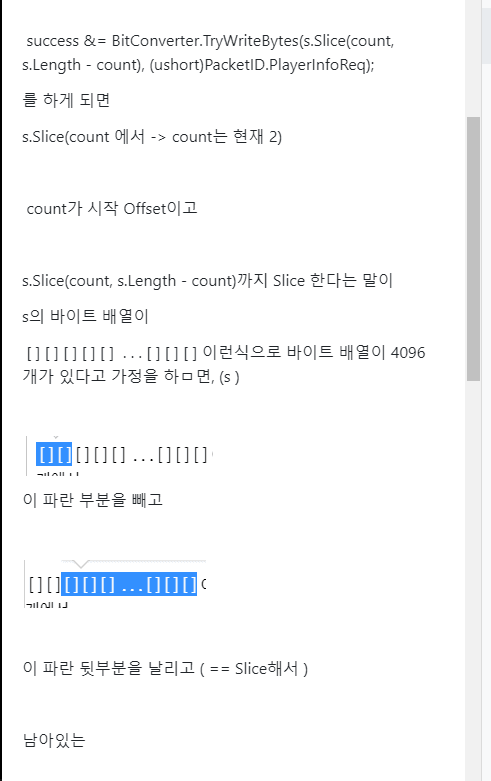
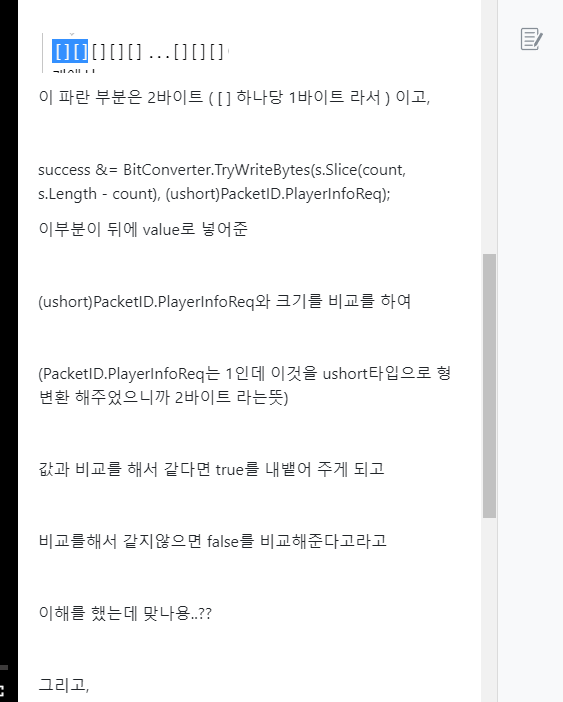
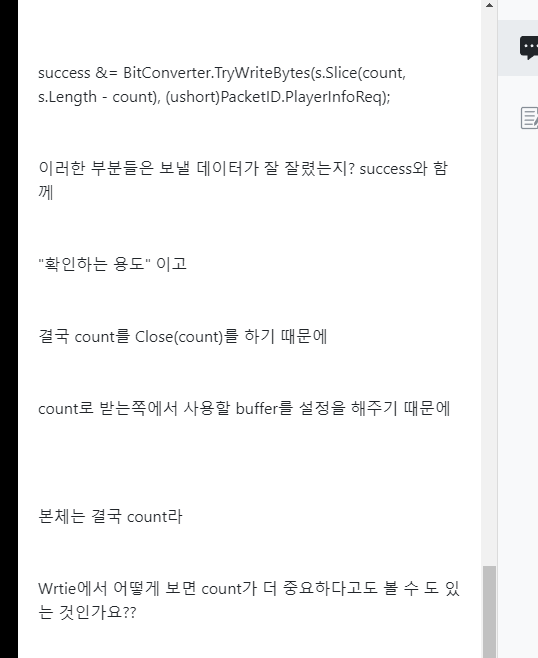
이다음 부터 진짜로 데이터를 넣어주기 시작한다.
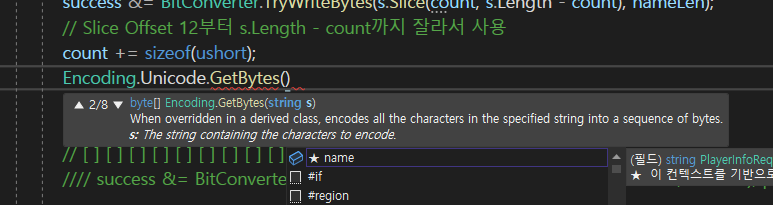
그래서 GetBytes에 string -> bute[]로 뱉어 주는게 있는데
그럼 name -> byte[]로 변환 가능
그래서 이녀석을 받아와서
Array.Copy로 복사를 해주면 될 것이다.

이렇게 복사를 segment에다가 하는데
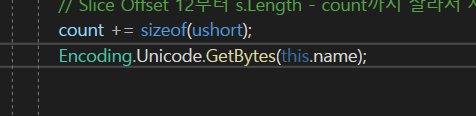
source는 Encoding.Unicode.GetBytes(this.name);의 offset 0번부터이고
목적지는 segment.Array이의 offset은 count번째 부터
nameLen만큼 (바이트 크기는 2) 숫자는 8이기 때문에
8만큼 복사를 해서 넣겠다! 라는 뜻이다.
즉, 8이라는 크기만큼 this.name을 바이트 배열로 변환한(변환하면 8바이트) 것을
segment의 offset = count부터 처 넣겠다! 라는 말이다.
그래서
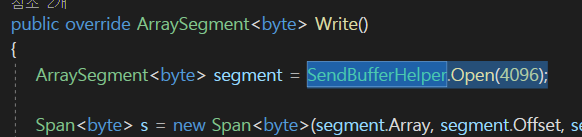
여기 에다가 할당한 공간에다가
복사를 해주게 되는 것이고
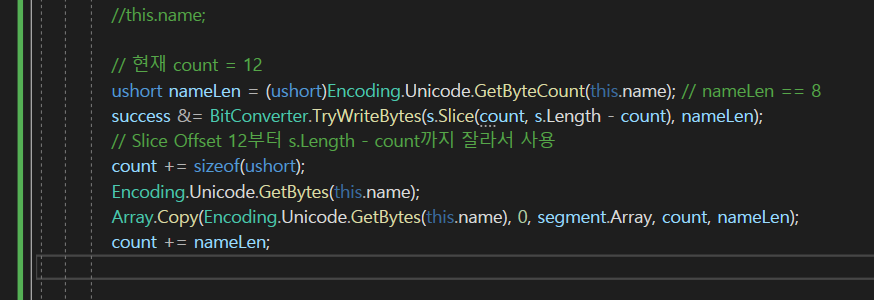
이렇게 count늘려주면 될 것이다.
그래서 이렇게 보내는 것이 가장 단순하면서도 효과적인 방법이라고 볼 수 있다.
그런데
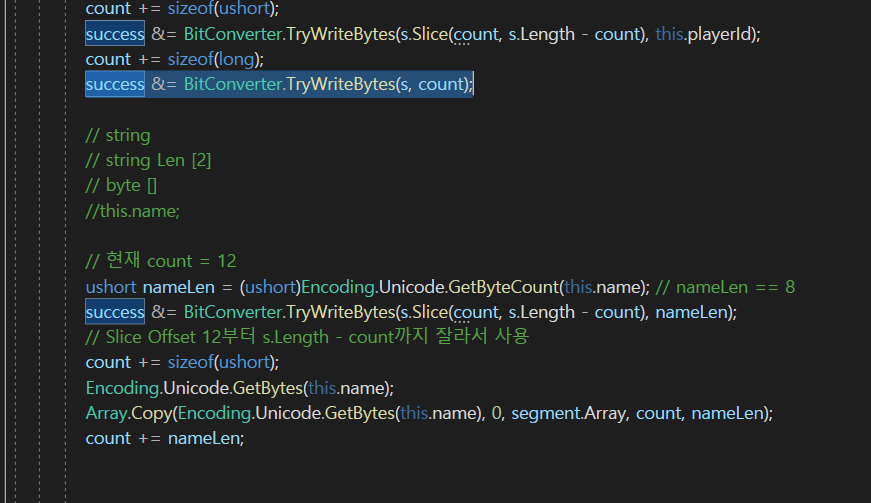
지금 Bitconverter.TryWriteBytes(s, count); 이부분이 제일 아래로 와야 할 것이다.
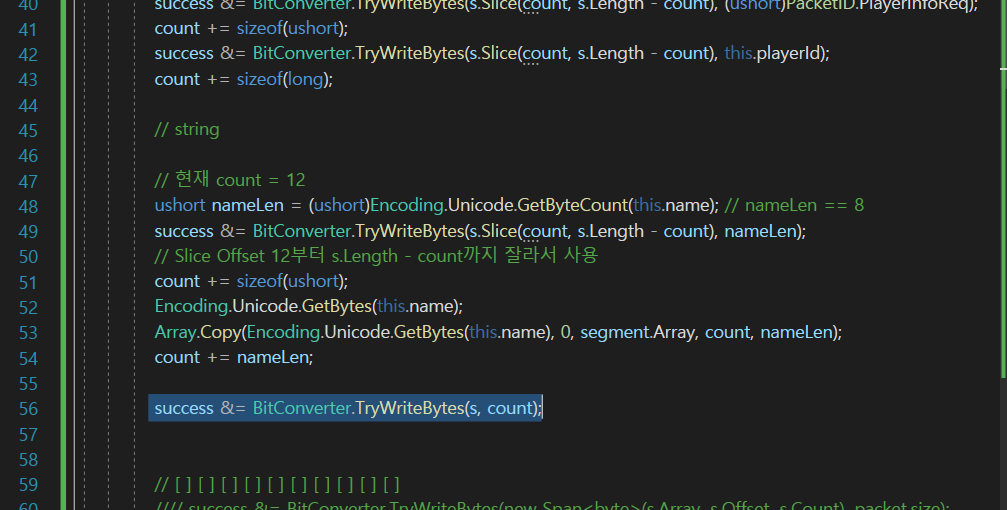
이렇게 옮겨주자.
그래서 최종 count를 제일 밑에 기입을 해주는 것이다.
그리고 이제 Read도 수정을 해주는데
count부분
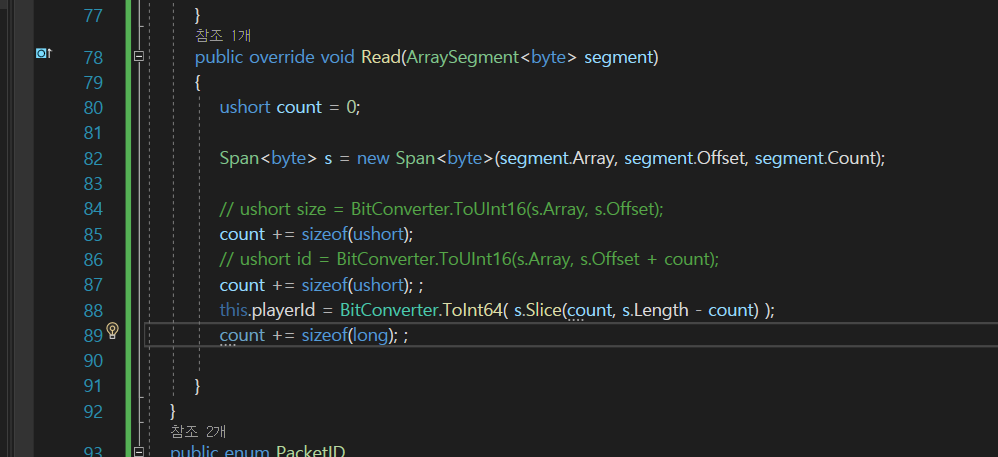
이렇게 살짝 수정을하고
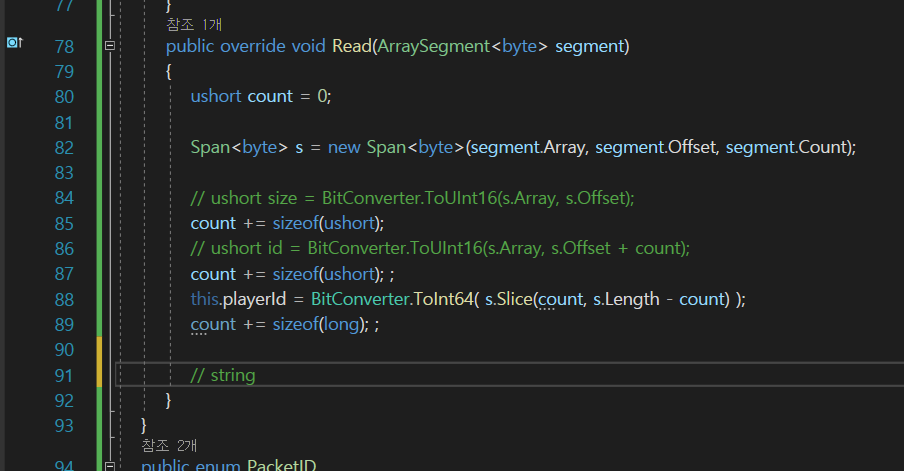
그래서 이제 밑에서 string이 와야한다.
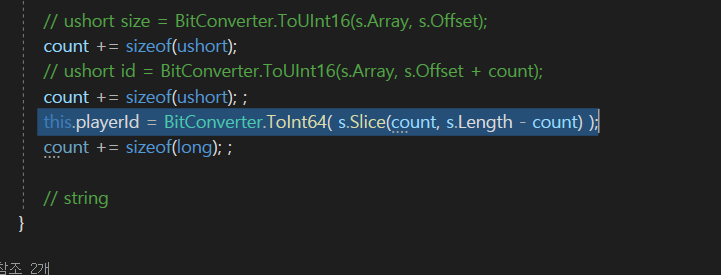
playerId를 여기서 읽어주고 있었고
그다음에 name을 파싱을 해야한다.
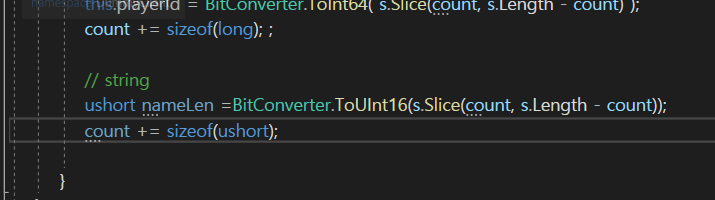
그래서 받아온 string의 길이를 nameLen으로 구하고
받아온 바이트 배열을 UTF-16으로 바꿔주는 작업을 해야한다.
Write에서 string을 바이트 배열로 바꿀때는

이런식으로
Encoding.Unicode.GetBytes를 사용했었다.
글면 Encoding.Unicode로 가보면 반대의 작업도 당연히 있을 것이다.
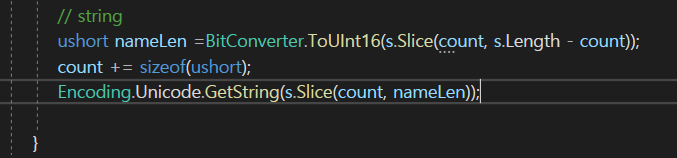
그럼 Getstring이라는게 있는데
index는 count번부터 시작을 해서 크기는 정확하게 nameLen만큼 잘라서 넘겨 주도록 하자.
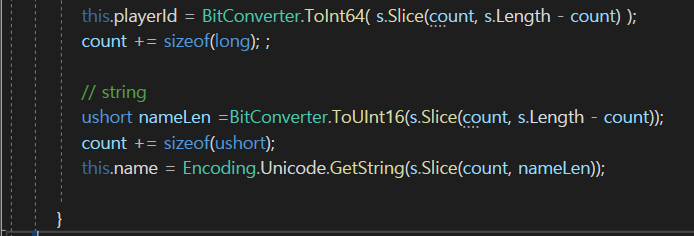
그래서 이렇게 하면 추출한 ABCD를 받아 올 수 있을 것이다.
그래서 갱신된거 복사해서 클라세션에도 똑같이 복붙을 해주자.
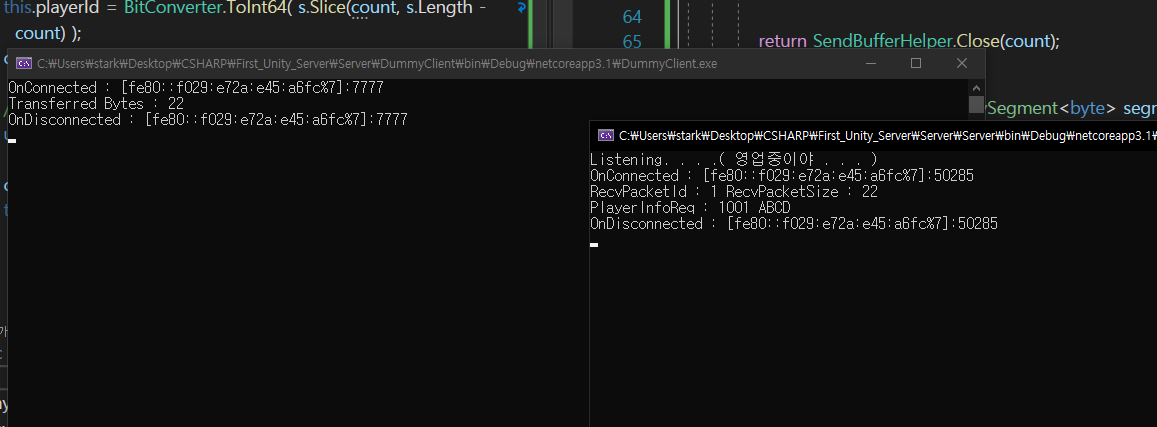
테스트 해보면 ABCD제대로 다 받아 온 것을 볼 수 있다.
그리고 만약 해킹을 당했다는 가정하에
Write부분에서 패킷을 어마어마하게 큰 값으로 넣으면 나중에
try & catch에서 에러를 잡아 낼 것이다.
그래서 이제
나중에 string뿐만아니라 바이트 배열도 보내야 하는 상황이 오는데
string을 처리를 할 줄 알면 바이트 배열도 유사하게 처리를 나중에 할 수 있을 것이다.
그래서 가장 중요했던 게
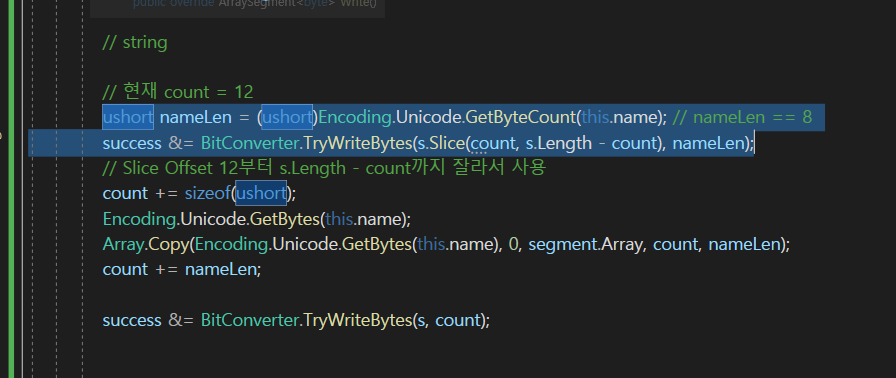
이렇게 두단계로 나뉜다음에 크기를 먼저 받고
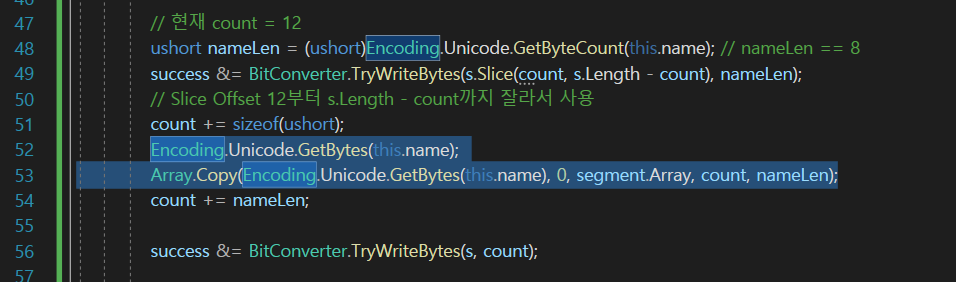
그다음에 이렇게 원본 데이터를 받는 방식으로 하면은
어느정도 처리가 될 것이다.
그래서 결국
Write에서 count를 계속 늘려줘가지고
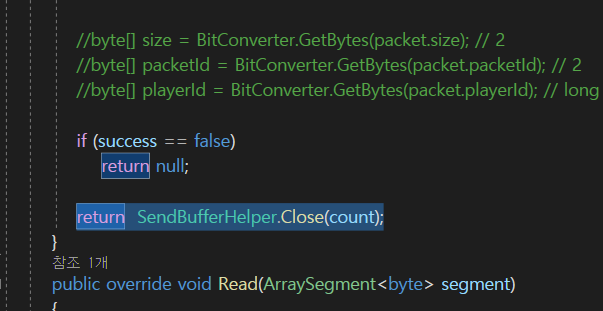
이렇게 return을 할 패킷의 최종 크기로 결정이 된다.
그래서 이녀석도 write하면서 같이 갱신이 되는 것도 알 수 있다.
3. 개선 할 부분
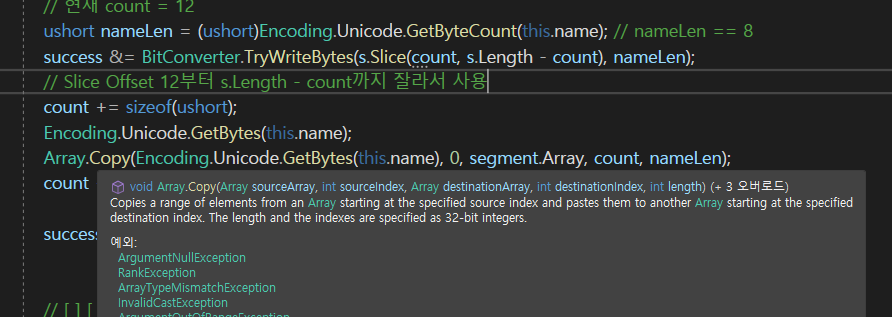
nameLen을 뽑아와서
Array.Copy로 바이트 배열을 복사를 해서 붙여주고 있었는데
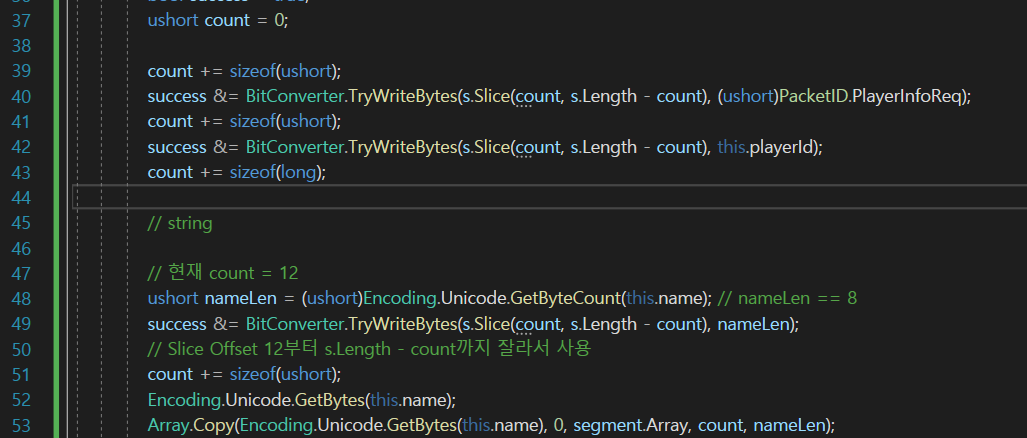
이전에는 TryWriteBytes를 이용을 해서 s에다가 바로 데이터를 집어넣었는데
Copy는 nameLen을 뽑고 그다음에 바이트 배열을 만들어서 복붙을 해주고 있었다.
이부분이 비효율적이라
바로 s에다가 넣는 방법은 없을까??
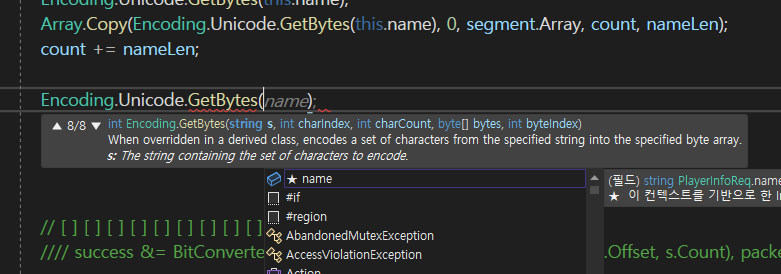
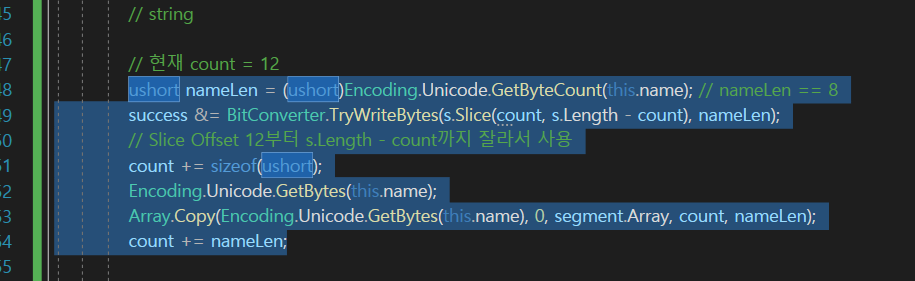
이버젼이 흥미로운데 (사용)
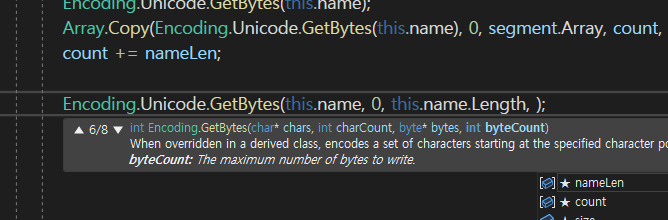
그래서 name의 처음부터 전체를 다 복사를 할 것인데
그렇다면 대상은 뭐냐?
대상은 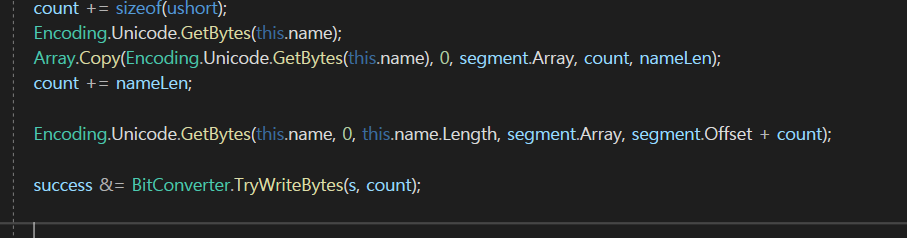
segment 배열에다가 offset은 Offset + count로 넣어주면 된다.
그르면 최종적으로 뱉어주는게 nameLen만큼 뱉어 준다는 것이다.
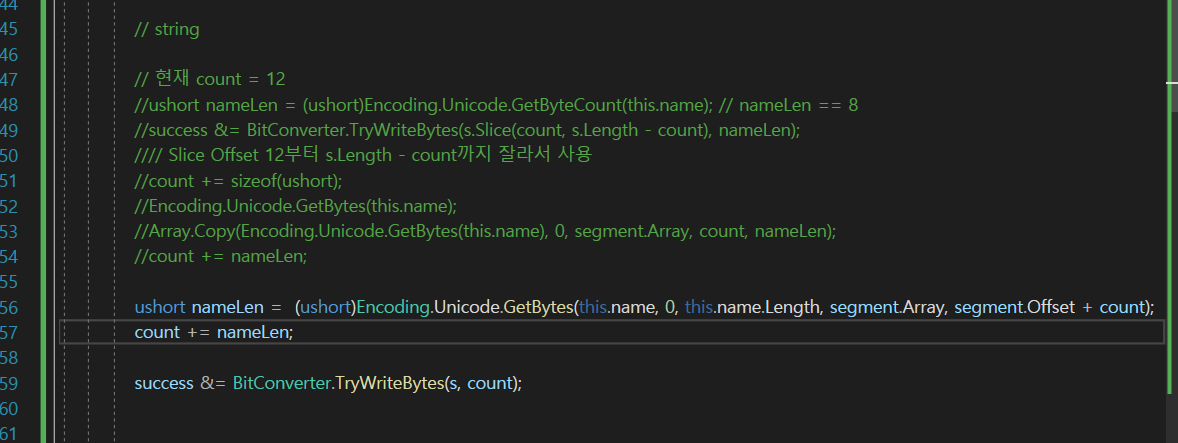
그래서
이렇게 두번에 걸친 동작을 한방에 해결을 할 수 있다는 얘기가 될텐데
이렇게 되는데
이전에는 nameLen을 먼저 뽑고 데이터 복사 이렇게 진행햇는데
지금은 반대로 했다.
즉, 지금은 데이터 복사를 먼저한 것이다
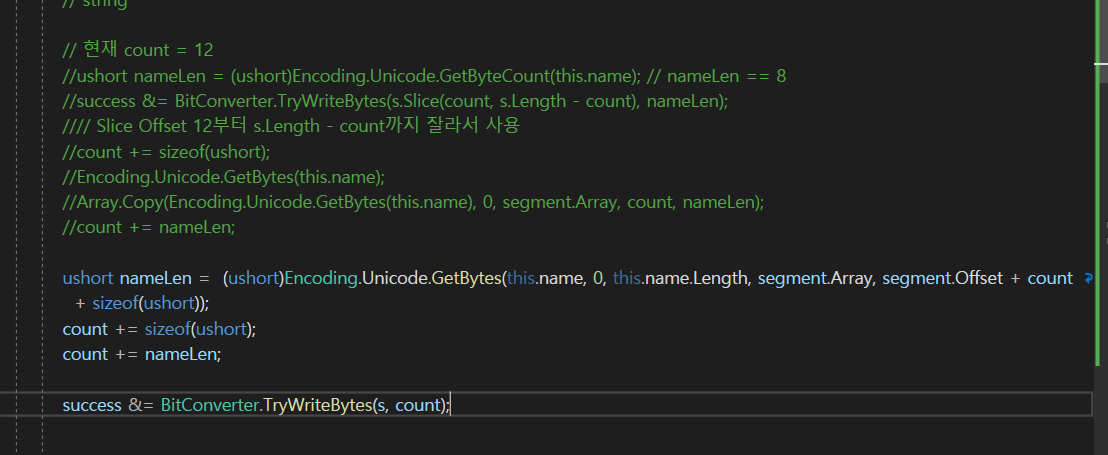
그래서 2바이트를 띄워서 + 해주고
이 작업을 끝내자 마자
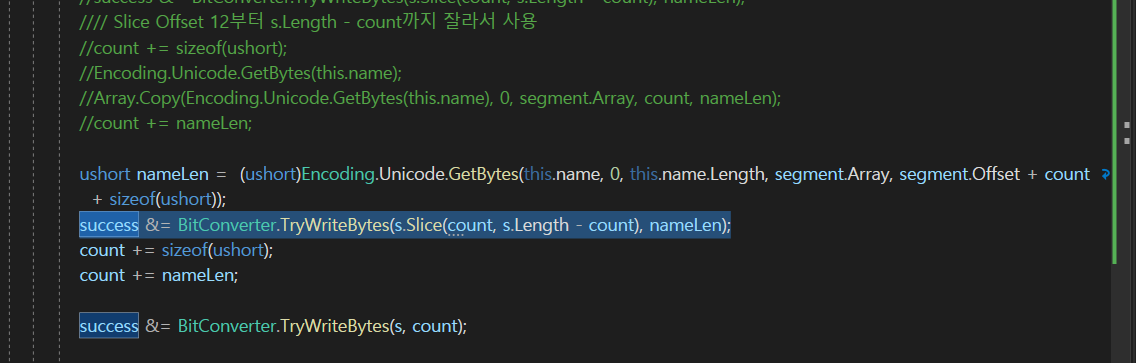
nameLen을 복사를 해주는 부분을 넣어주면 될 것이다.
그래서 이게 더 효율적이다.
그래서 나중에 이미지 같은 것을 보낼때 ( == 바이트 배열로 보내야함 )
그러면 string을 보냈던 것처럼
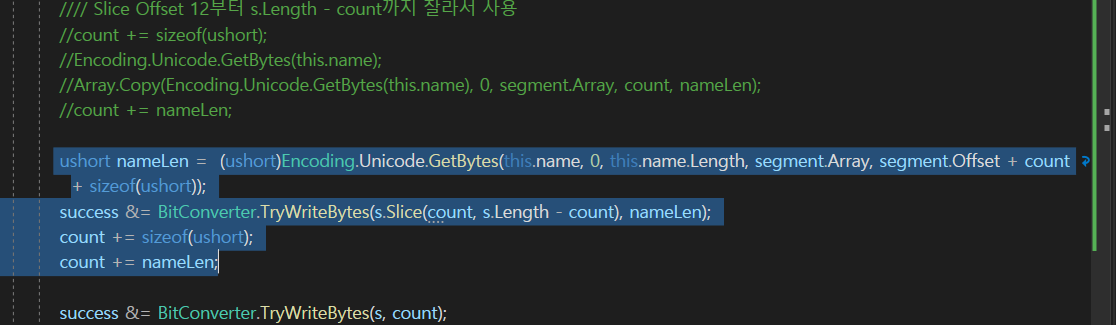
이런 방식이랑 비슷하게
ushort nameLen을 먼저 보낸다음에
실제 데이터를 보내는 방식이 좋을듯
