
이거 3가지 다 성능 ㅎㅌㅊ임.
Astar에서 OpenList를 관리를 할 때, PQ를 사용을 해서 관리를 했는데
질문중 하나가 C#의 List (C++로 치면은 std::vector)의 sort함수를 사용해서 OpenList를 관리를 하면되는데 왜 PQ를 사용해서 관리를 하느냐?
이게 자알을 모르면 이런 질문을 한다.
기본적으로 PQ는 O (log n)을 가진다.
Astar에서 OpenList에 넣고 매번 std::sort()를 사용한다면 엄청 느리다 (사람을 체감을 잘 못하겠지만)
데이터가 엄청나게 많을 경우
반면에 BST나 PQ는 삽입이 O(log N)이기 때문에
std::sort보다 훨씬 빠르다.
그래서 Astar에서 OpenList를 PQ로 관리를 하는것이다.
Bubble Sort
먼저 한번 쭉 정렬한 뒤 K를 제외하고
3 5 J 9에 대해서 다시 정렬 쭉한다.
이게 버블 정렬임.
버블 정렬이 O(N^2) 인 이유

처음 실행때는 N-1, N-2 ... 2 + 1이기 때문에
등차수열의 합으로 계산을 하면은 N * ( N - 1) / 2 => 가장 큰수만 보기 때문에
시간 복잡도가 O(N^2)가 되는 것이다.
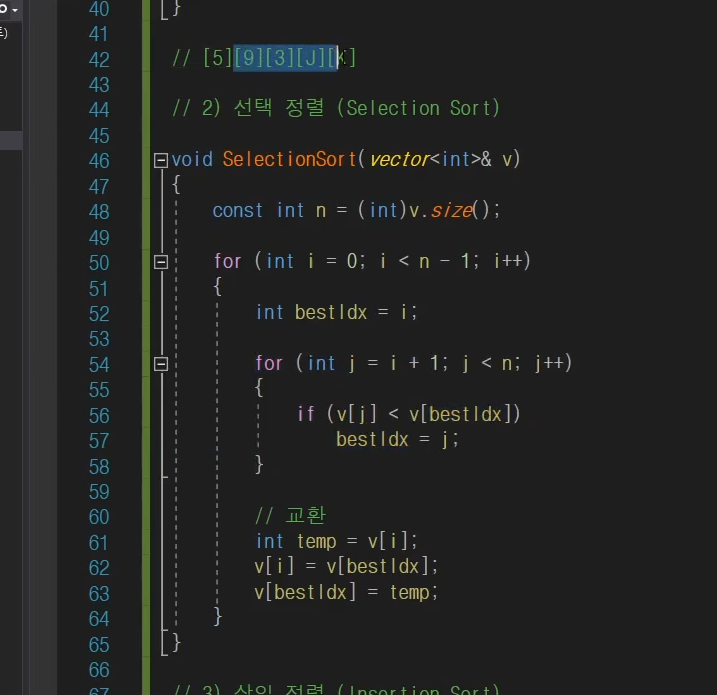
Selection Sort
쭉 스캔해서 눈때중으로 승자를 골라준다.
쭉 스캔해서 가장 작은애부터 제일 앞에 위치시킨다.
Insertion Sort ❗
삽입정렬 조금 중요하다.
자체로 의미가 있는 것은 아닌데 코딩 면접에서 사용하는 개념자체가 은근히 자주 나오는 경우가 많다.
특히나 문자열 관련해서 연관성이 많다.
새로운 슬롯을 파주고


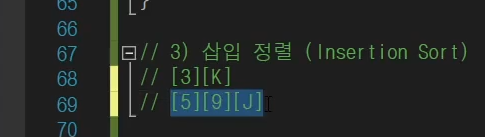
이런식으로 삽입하는 형태로 정렬하는 것임.
구현 ❗
삽입정렬을 구현하기 위한 임시벡터를 만들어서 원본에서 받아 와야하는 것 아니냐? 생각할 수 있는데
이부분이 중요함.
하나의 벡터를 가지고 영역을 구분을 해서 정렬을 하는 것이다.
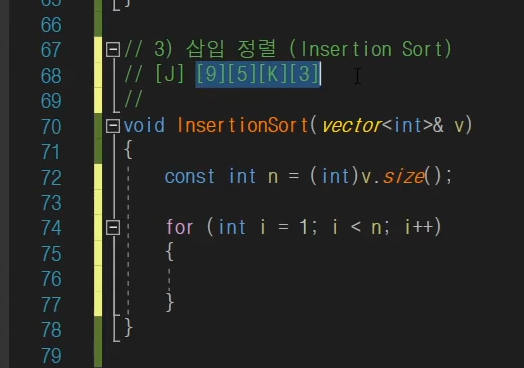
먼저 이상태로 i = 0;일경우는 스킵을 하고 1부터 보는 것이다.
0번 인덱스는 정렬된 부분 1~4는 정렬안된 부분으로 나누는 것이다.
