JRC 2022 Paper Review, 22/03/18 Seongyun, Lee
Prior works
image-based captioining
perform reasonably well in addressing the language fluency aspect
but, less satisfactory in terms of clinical accuracy
- closely tied to the textual characteristic of medical reports, which typically consists of many long sequences describing various disease related symptoms and related topics in precise and domain-specific terms
- lack of full use of rich contextual information that encodes prior knowledge. these information include for example clinical document of the patient describing key clinical history and indication from doctors, and multiple scans from different 3D views - information that are typically existed in abundance in practical scenarios, as in the Open-I, MIMIC-CXR
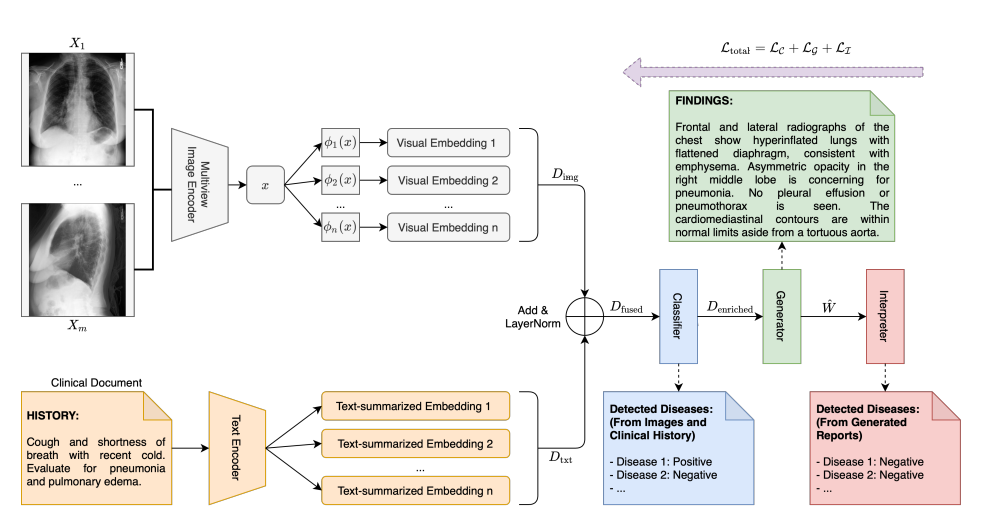
Framework
- classifier
- read multiple CXR images and extracts the global visual feature representation via a multi-view image encoder
- they are disentangled into multiple low-dimensional visual embedding
- text encoder reads clinical documents (doctor indication), summarize
- visual, text-summarized embeddings are entangled via add&layer norm → contextualized embedding in terms of disease-related topic
- generator
- enriched disease embedding as input → generates word by word
- interpreter
- generated text → fine-tuning to align to the checklist of disease-related topic from the classifier
Classifier
- Multi-view Image Encoder
- m CXR images → (multi-view latent features). x have c-dimension, c is # of features via a shared DenseNet-121 image encoder.
- multi-view latent features x can be obtained by max-pooling, m=1 ⇒ multi-view encoder → single-image encoder
- 여기서는 CXR image가 여러 각도에서 촬영된 것을 multi-view로 표현. 각각의 각도에서 촬영된 CXR images에서 각각 latent vector를 추출하고 이를 encoding
- Text Encoder
- text document has length → ,
- transformer encoder가 를 로 encoding
- ,
- , representing n disease related topics (pneumonia), to be queried from document
- , is text-summarized embedding
- Contextualized Disease Embedding
- , image encoding, , is # of diseases
- entanglement of visual and texttual information allows our model to mimic the hospital workflow, to screen the disease’s visual representations conditioned on the patients’ clinical history of doctors’ indication
- but, this embedding by itself is insufficient for generating accurate medical reports, this lead us to conceive a follow-up enriched representation below
- Enriched Disease Embedding
- 를 가지고 각각의 n개의 질병에 대해 k개의 disease state중 하나로 classification한다.
- disease state =
- if traning phase else ,
- finally eenriched disease embedding
- is disease names
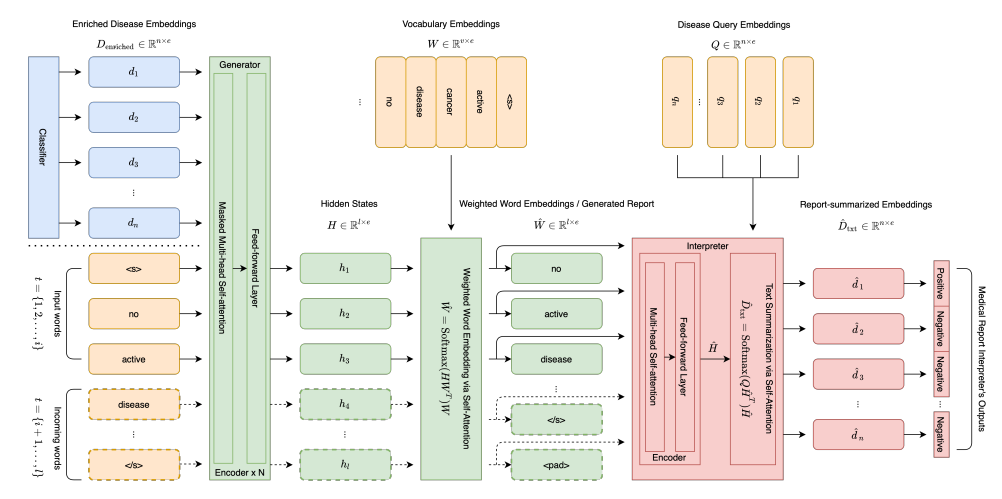
Generator
hidden state for each word = , masked multi-head attention, feed-forward layer를 N번 반복
여기서 는 medical report를 의미함, 는 .
weighted word embedding, generated report =
Interpreter
generated reports are often distorted in the process, such that they become inconsistent with the original output of the classification module - the enriched disease embedding that encodes the disease and symptom related topics
fully differentiable network module to estimate the checklist of disease-related topics based on the generator’s output and to compare with the original output of the classifcation module
this provides a meaningful feedback loop to regulate the generated reports which is used to fine-tune the generated report
, is ’s hidden state, is quried diseases
is predicted disease label of interpreter
is groud truth disease label
guide to force the word representations, force the generator to move toward producing a correct word representations
Experiments
- Datasets
- MIMIC-CXR
- 227,385 medical reports of 65,379 patients, associated with 377,100 images from multiple view → AP(anterior-posterior), PA(posterior-anterior), LA(lateral), including comparison, clinical history, indication, reasons for examination, impression, and findings
- this paper utilizes multi-view image, adopt as contextual information the concatenation of the clinical history, reason for examination, and indication sections
- for consistency, this paper only focus on generating findings
- Open-I
- 3,955 radiology studies that correspond to 7,470 frontal and lateral chest X-rays
- some radiology studies are associated with more than one chest X-ray image
- Each study typically consists of impression, findings, comparison, and indication section
- this paper utilize multi-view images and indication section
- for generating medical reports, concatenating the impression and the findings sections as the target output
- MIMIC-CXR
- Results
- Language Generation Performance
- 모든 metric에서 SOTA를 차지하였다. 특히 MIMIC-CXR의 경우 single view image만 사용한 모델 조차 기존 SOTA를 압도하는 것이 인상적. 또한 interpreter module의 사용이 많은 이득을 가져다 줌을 확인할 수 있었다.
- Clinical Accuracy Performance
- to evaluate the clinical accuracy of the generated reports, they use the LSTM CheXper labeler as a universal measurement. F1, precision, recall metrics on 14 common diseases. and they also use macro, micro scores. high macro score means the detection of all 14 diseases is improved. high micro score implies the dominant diseases are improved
- 모든 metric에서 SOTA를 차지 하였다.
- Language Generation Performance
Ablation study
- Enriched disease embedding
- enriched disease embedding 쓰는게 좋다
- Contextualized embedding
- contextualized embedding 쓰는게 좋다
Conclusion
본 논문은 three module approach로 X-ray image와 환자의 증상정보가 담긴 clinical document를 동시에 사용하여 기존 SOTA 모델에 비해 높은 성능을 얻을 수 있었고, interpreter를 사용해서 생성된 medical report를 다시 한번 fine-tune하면서 language fluecy뿐만 아니라 clinical accuray도 향상시킬 수 있었다.

2개의 댓글

The automated generation of accurate and fluent medical X-ray reports represents a significant advancement in healthcare technology. This paper review delves into the efficacy of such systems in improving diagnostic accuracy and streamlining report generation processes. By leveraging machine learning algorithms and natural language processing techniques, these systems ensure precise interpretation of X-ray images while facilitating the creation of comprehensive reports. Furthermore, the integration of features like refresh eye drops ustomer service enhances user experience and fosters efficiency in clinical workflows.
Unlock your body's full potential with Profunction.ca physiotherapy https://maps.google.com/maps/dir//Pro+Function+Health+Care+Team+140+Ann+St+Suite+103+London,+ON+N6A+1R3+Canada/@42.9930194,-81.2560469,14z/data=!4m5!4m4!1m0!1m2!1m1!1s0x882ef19d3e70de8d:0x37d7394910fe724e services in 2024. Our expert team is dedicated to restoring your mobility, relieving pain, and enhancing your overall well-being. Whether you're recovering from an injury, managing a chronic condition, or seeking to optimize your athletic performance, we tailor our treatments to meet your unique needs.
At Profunction.ca, we blend cutting-edge techniques with compassionate care to ensure you receive the highest quality of treatment. From manual therapy and therapeutic exercises to state-of-the-art modalities, we employ a comprehensive approach to help you achieve your goals.
Experience personalized care and unparalleled expertise at Profunction.ca. Let us guide you on your journey to a healthier, more active life. Take the first step towards optimal health and vitality – schedule your appointment with Profunction.ca physiotherapists today.