Paper
1.Oscar Paper Review

Oscar Paper Review - ECCV 2020
2.Attention Is All You Need Paper Review
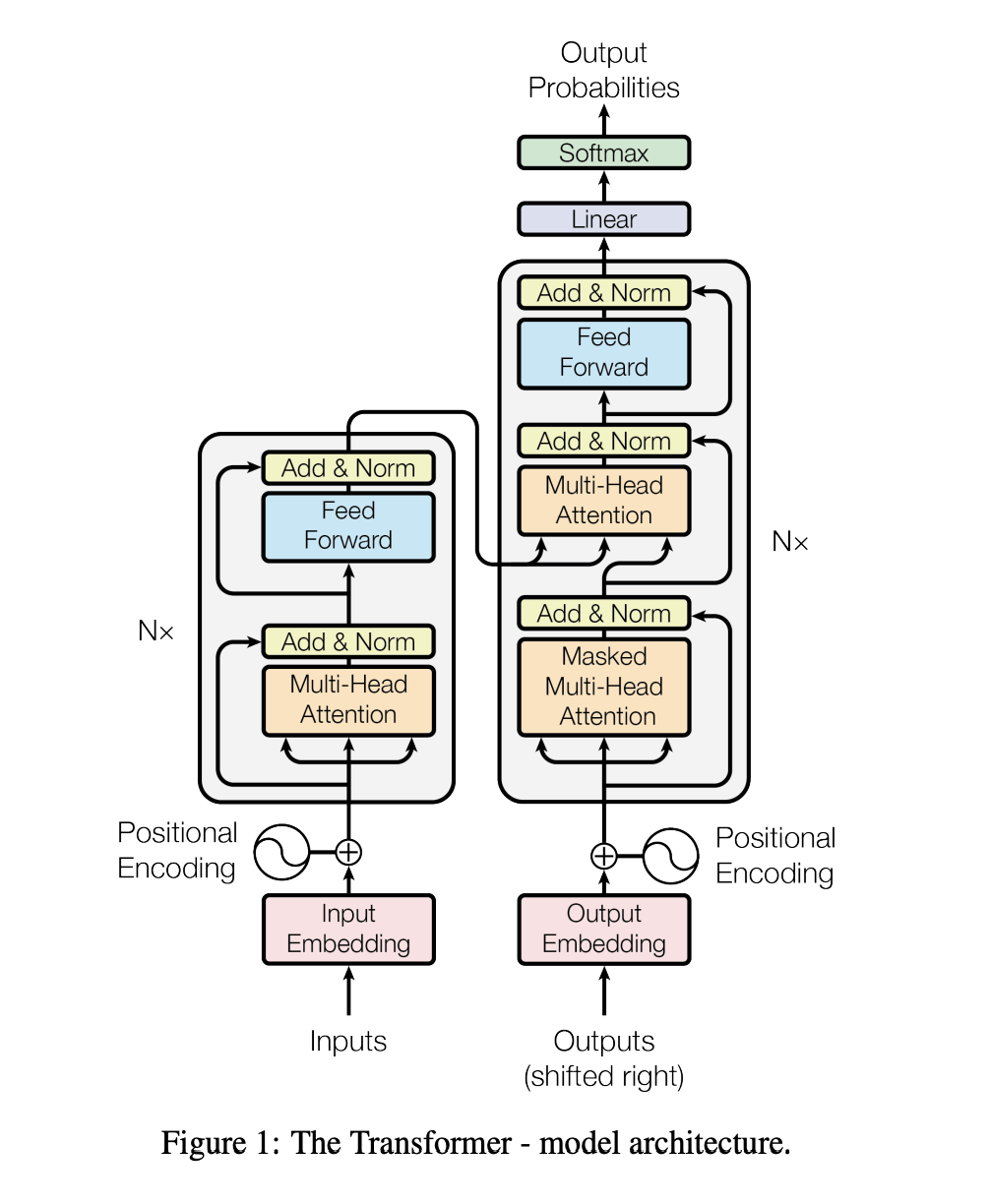
기존의 sequence transduction model은 attention mechanism을 사용하여 복잡한 CNN, RNN 모듈이 들어간 Encoder+Decoder 구조로 이루어져 있다.본 논문에서는 이러한 복잡한 모듈들을 전혀 사용하지 않고 오로지 attent
3.ViLT Paper Review
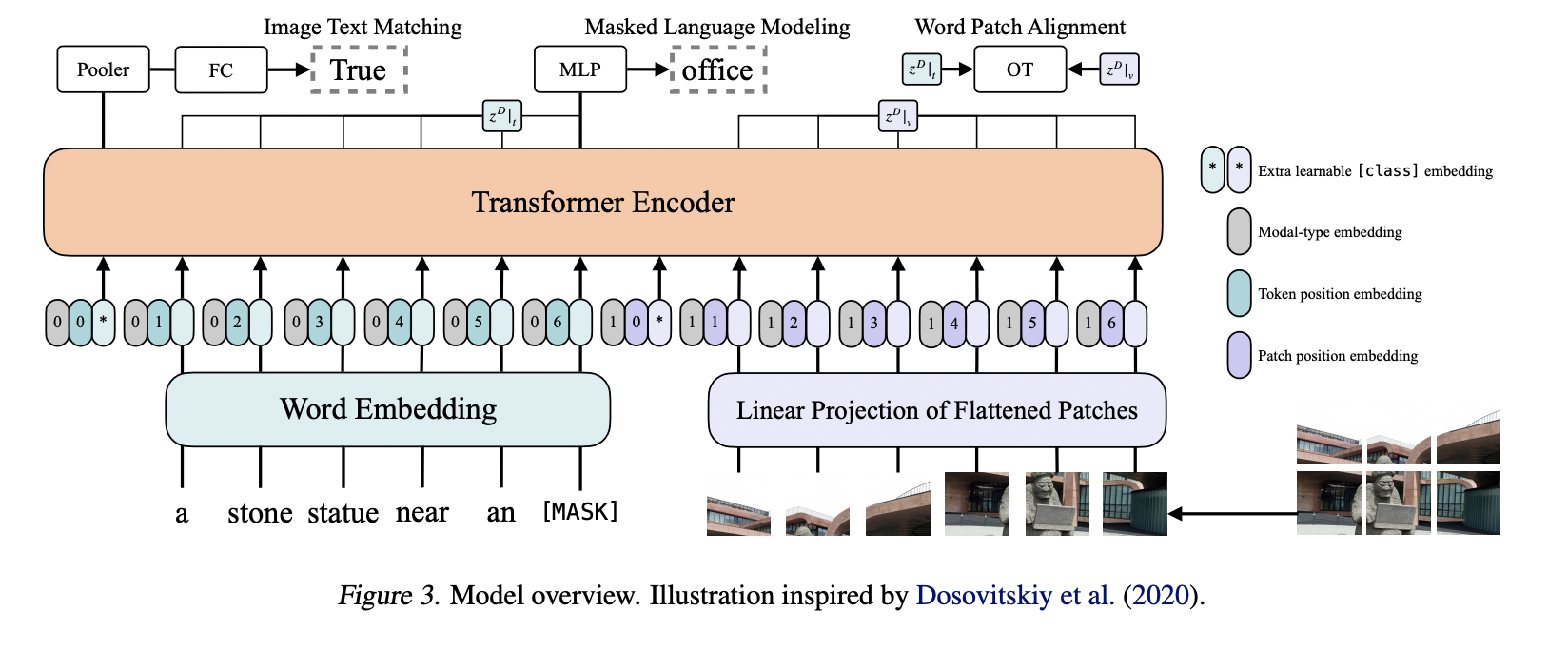
기존의 VLP model들은 대부분 visual feature extraction을 하기 위해, CNN architecture나 region supervision (object detector)를 사용했다. 본 논문에서는 image를 patch 단위로 자르고, ViT를
4.ClipCap Paper Review
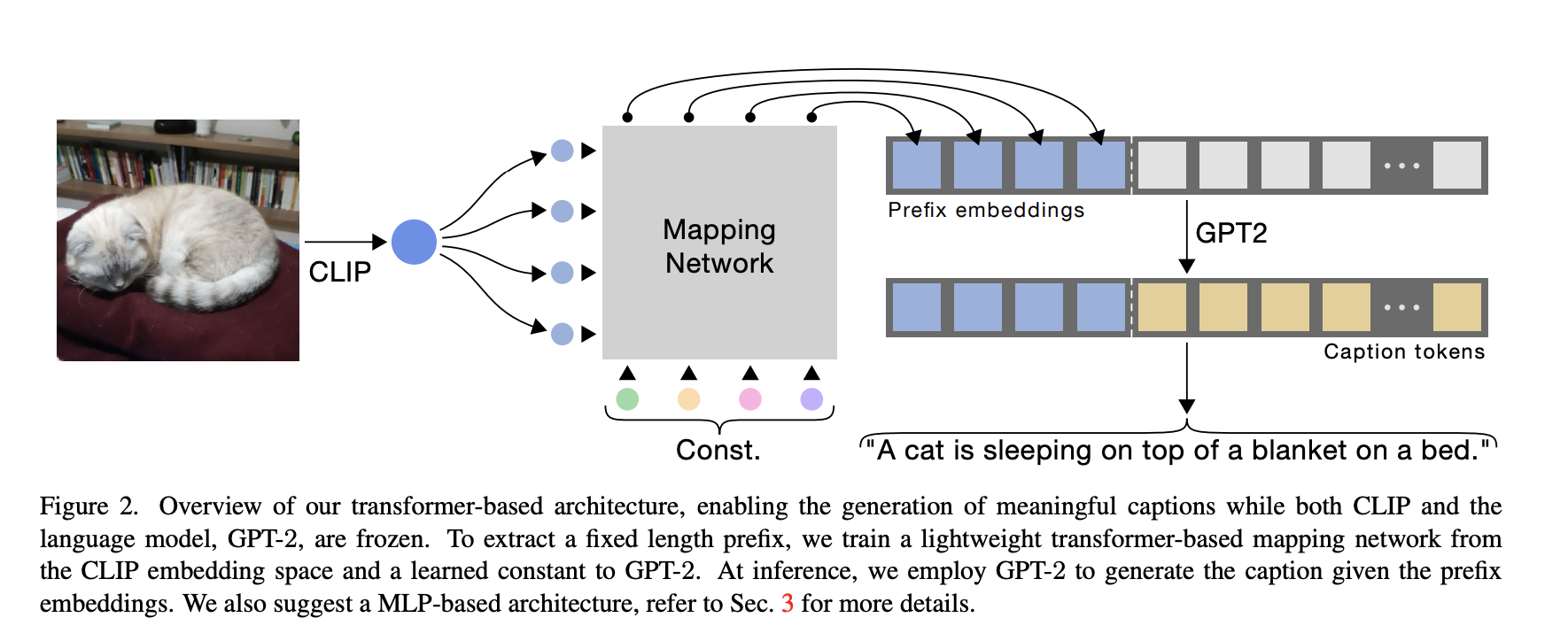
vision-language model인 clip과 Language model인 GPT-2를 활용하여 적은 cost, 빠른 training으로 image captioning task에서 SOTA model과 비슷한 성능을 내었다. 다음과 같은 과정을 거친다.우선 CLI
5.GAN Paper Review
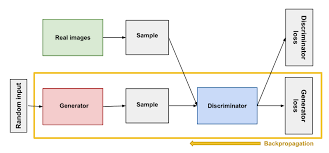
본 논문은 두 모델을 동시에 학습하는 생성 모델 GAN을 제안한다.
6.CoOp Paper Review
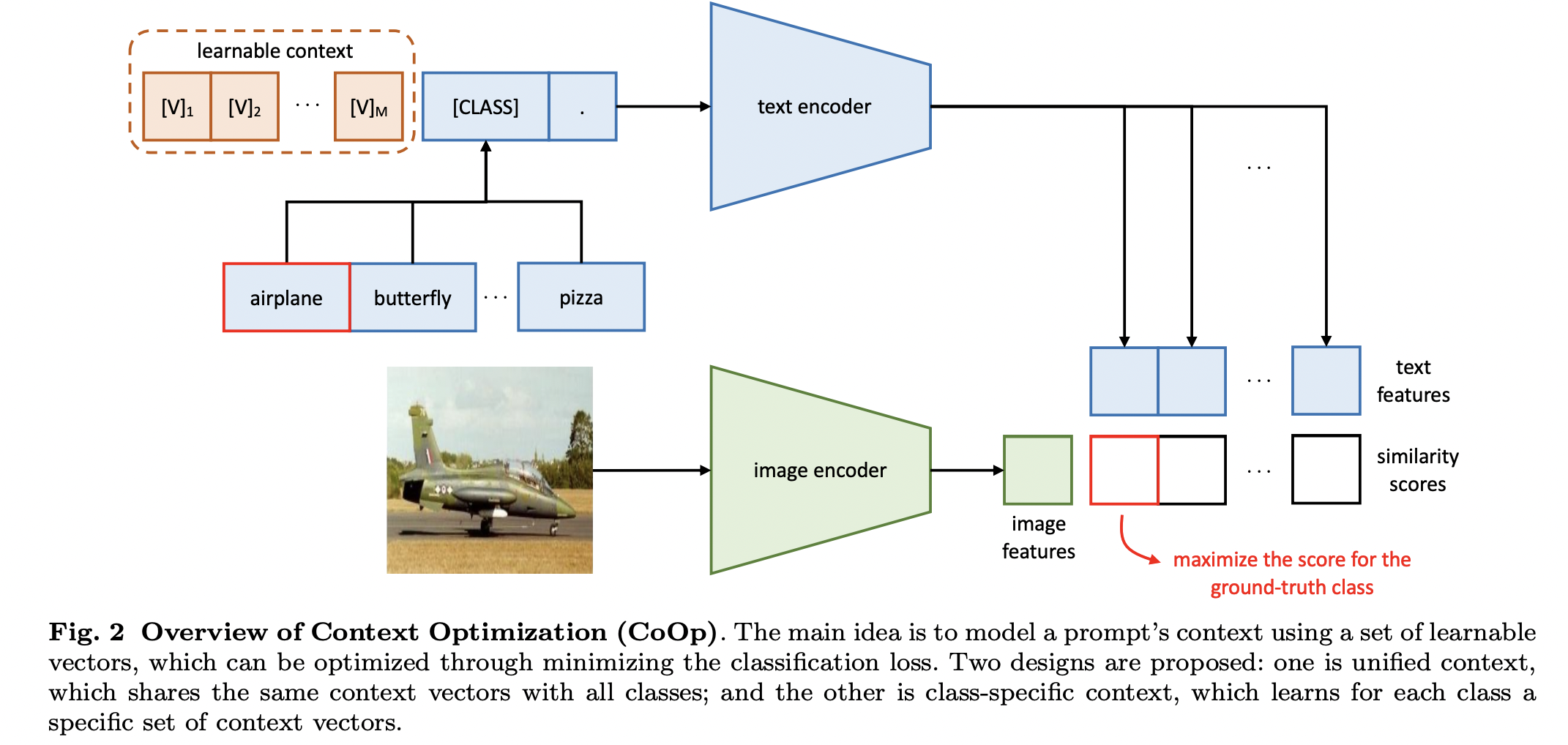
NLP에서 성능 향상에 도움이 되는 prompt learning을 다양한 vision-language task를 수행하는 CLIP-like model에 도입하였다. CoOp은 pre-trained 된 parameter는 고정시킨 채로, prompt의 context wo
7.SeqGAN Paper Review
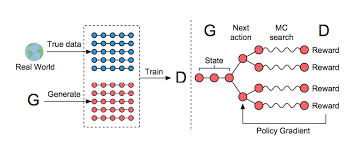
생성 모델의 새로운 시대를 연 GAN은 discriminative model D와 generative model G로 이뤄져 있다. 그런데 image와 같은 continuous data는 잘 생성해내는 반면에, discrete한 tokens의 sequence를 생성하는
8.VirTex Paper Review
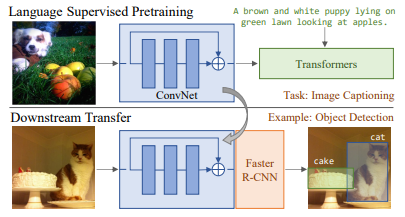
기존에는 imagenet과 같은 supervised image dataset을 사용해서 model을 학습하였다. 이러한 방법은 다양한 vision task에서 좋은 성능을 보였지만, 인간이 수동으로 annotation을 만들어줘야 한다는 점에서 scalability가
9.ALIGN Paper Review
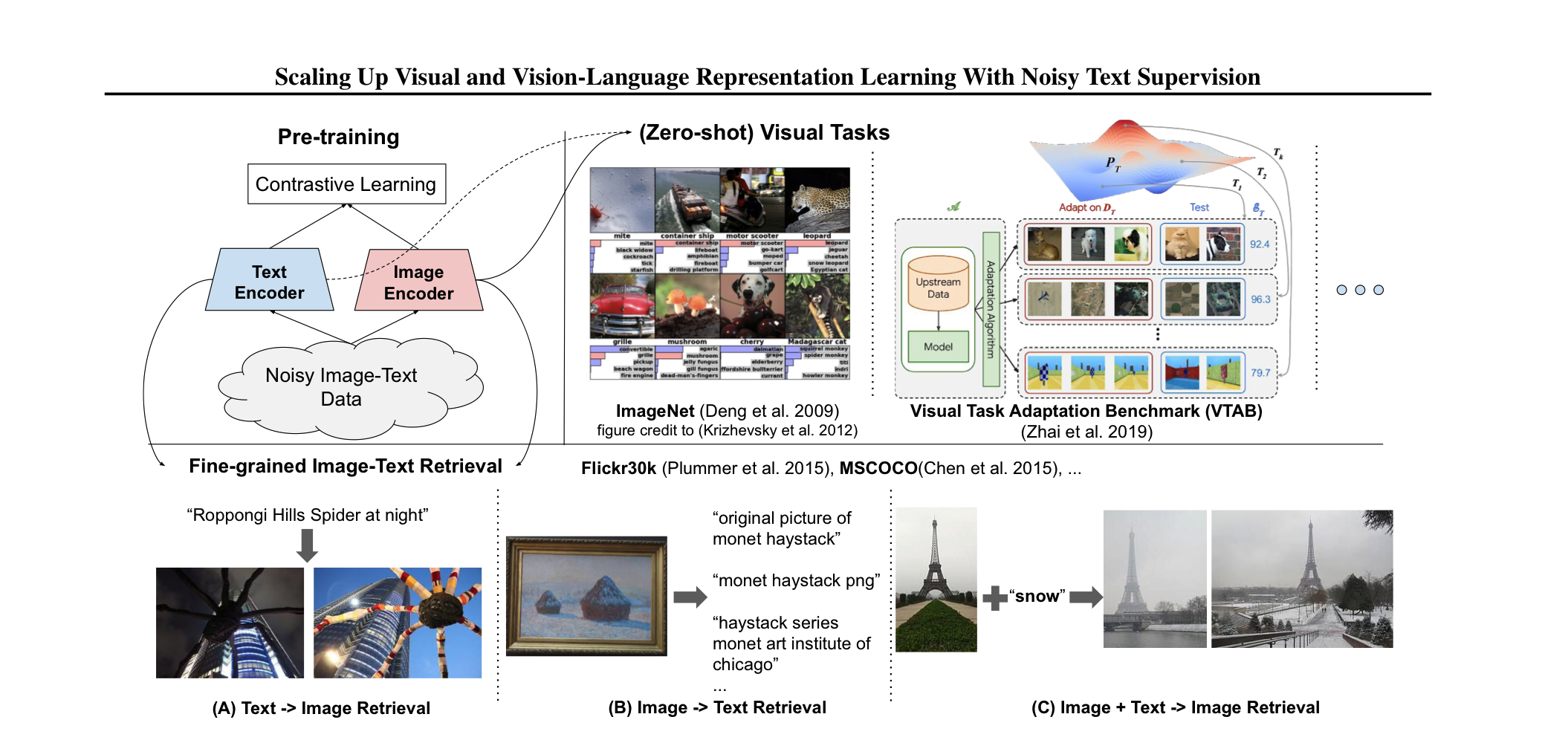
Summary pre-trained model에는 많은 데이터를 필요로 한다. 이 과정에서, costly한 annotation 과정이 필요한데, 이는 필연적으로 학습에 사용되는 데이터셋의 크기를 줄인다. 본 논문에서는 별도의 후처리 없이 noisy한 1billion
10.BLIP Paper Review
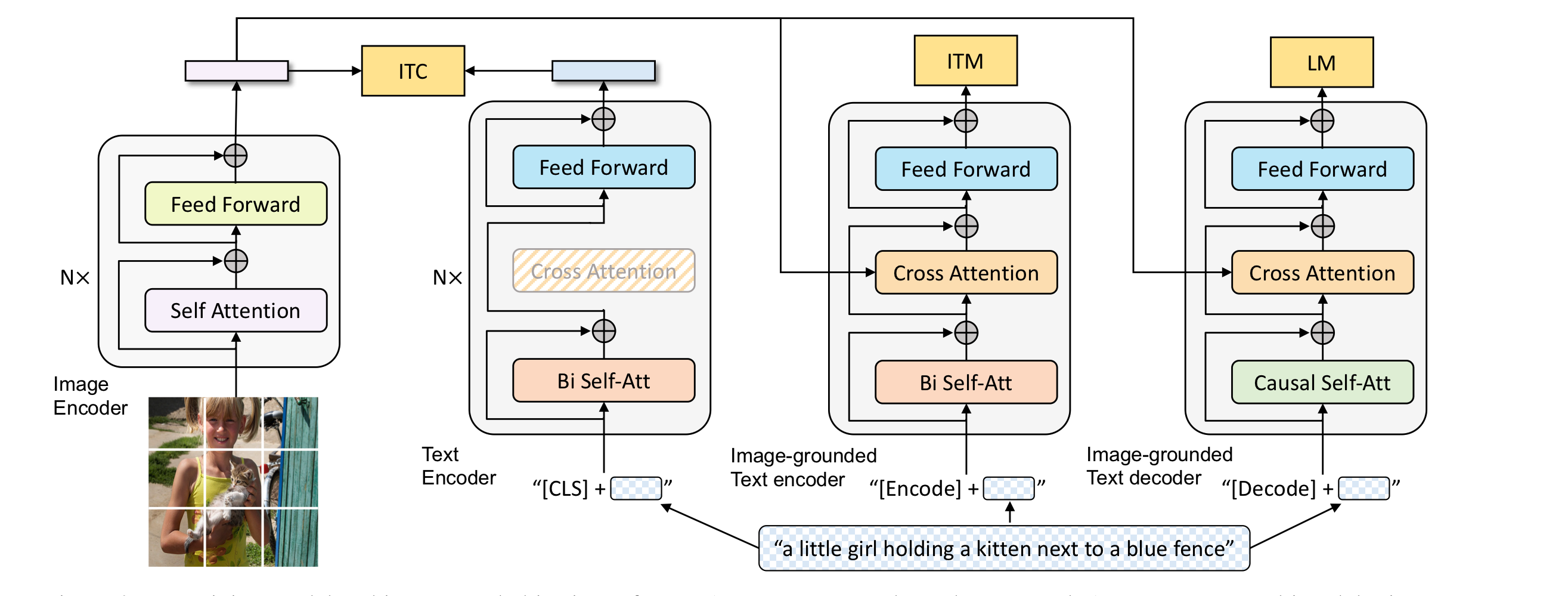
Vision-Language Pre-training은 많은 V-L task을 발전시켰다. 최근 V-L 모델들은 웹상에 존재하는 noisy하고 거대한 데이터로 학습을 진행하였는데, 이것은 suboptimal하다. 본 논문은 nosiy web data를 caption을 b
11.ALBEF Paper Review
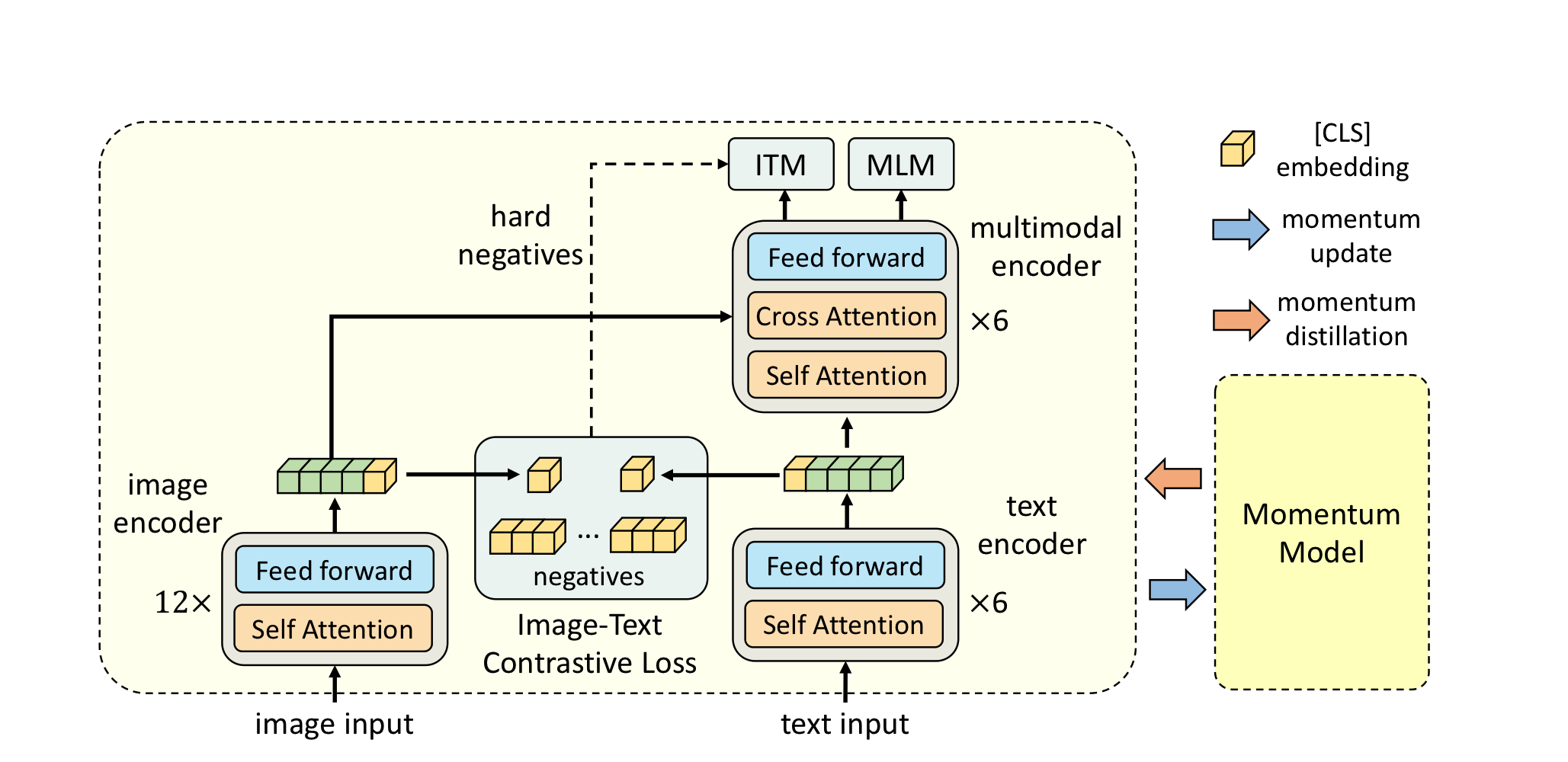
transformer 기반의 multimodal encoder는 model이 visual, text tokens을 함께 학습하도록 한다. visual, word tokens들이 unaligned되어있기 때문에 multimodal encoder가 image-text in
12.OFA Paper Review
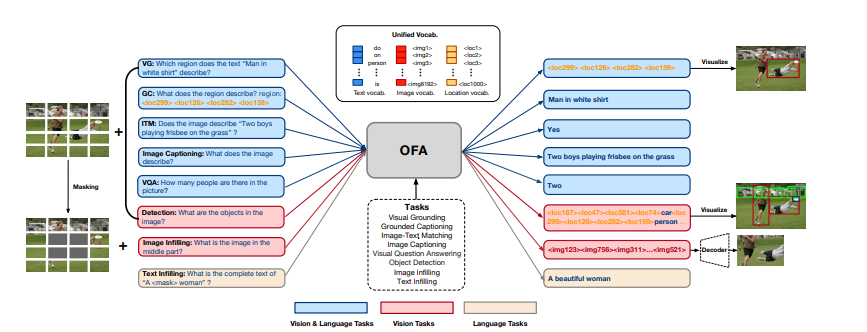
복잡한 task/modality-specific customization 없이 multimodal pretraining을 위한 단일화된 패러다임을 제안한다. OFA는 unified multimodal pretrained model인데, 많은 modality와 task를
13.TCL Paper Review
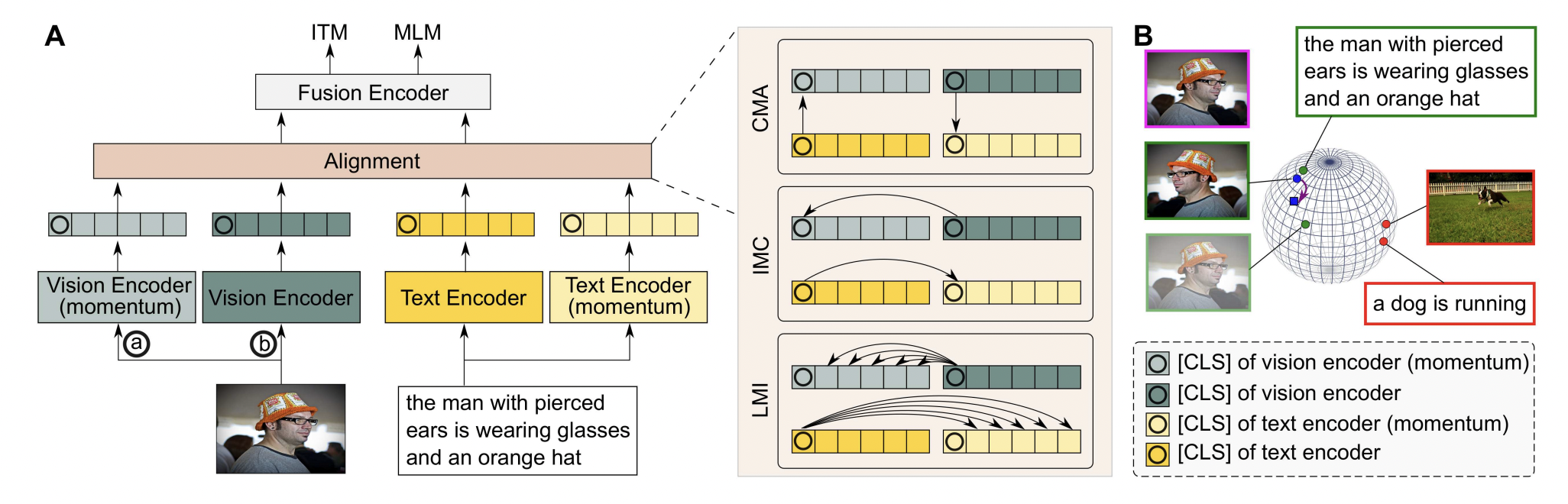
visual-language pretraining은 대부분 image-text alignment를 contrastive loss를 통해 진행되었다. alignment하면서 생기는 이득은 image와 그에 매칭되는 text들간의 상호간의 정보 (Mutual Informa
14.BioBERT Paper Review
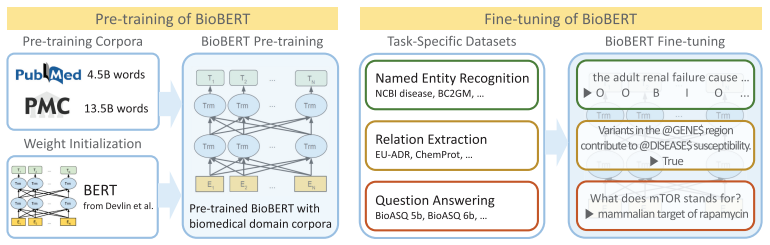
deep learning을 활용하여 NLP 연구를 활발하게 진행하고 있다. 하지만 지금까지의 biomedical domain에서의 deep learning을 활용한 text mining 연구는 좋은 성과를 거두지 못했는데, word distribution이 일반적인 N
15.Automated Generation of Accurate & Fluent Medical X-ray Reports Paper Review
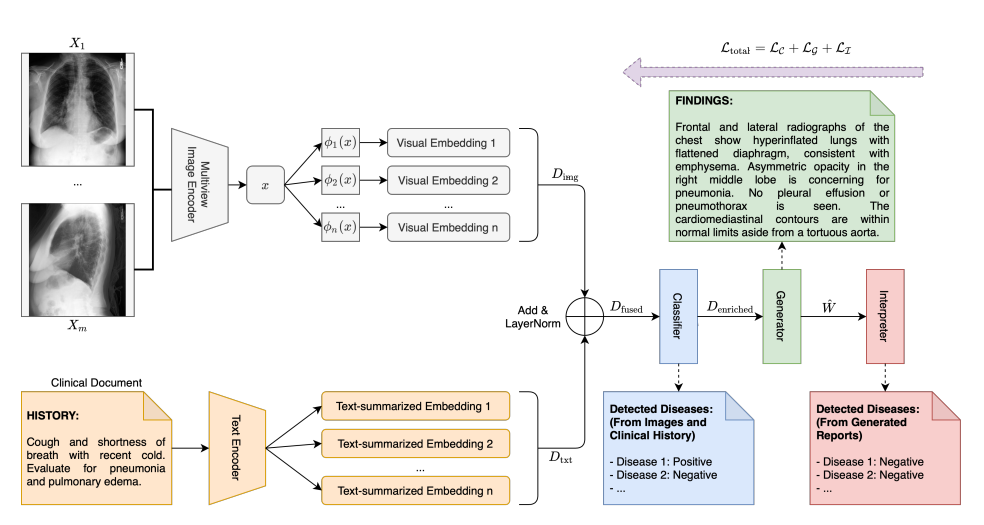
JRC 2022 Paper Review, 22/03/18 Seongyun, Leeimage-based captioiningperform reasonably well in addressing the language fluency aspectbut, less satisfa