Summary
deep learning을 활용하여 NLP 연구를 활발하게 진행하고 있다. 하지만 지금까지의 biomedical domain에서의 deep learning을 활용한 text mining 연구는 좋은 성과를 거두지 못했는데, word distribution이 일반적인 NLP에 사용되는 것과 biomedical domain에서 사용되는 것이 많이 다르기 때문이다. 따라서 본 논문은 large-scale의 biomedical corpora로 pre-training한 domain-specific LM, BioBERT를 소개한다.
BioBERT는 이전에 존재하던 biomedical text mining task의 SOTA model과 BERT와 비교했을 때 압도적인 성능을 보인다. task는 크게 3가지로, biomedical NER, biomedical RE, biomedical QA이다. 모든 task에서 이전의 방법론과 original BERT를 압도한다.
기존의 SOTA NLP method를 그대로 biomedical NLP task에 적용하면 문제점이 발생한다.
- biomedical text의 word representation이 general domain text와는 다르다, 이는 일반 NLP model에서의 biomedical task 성능이 떨어지는 요인이 된다
Method
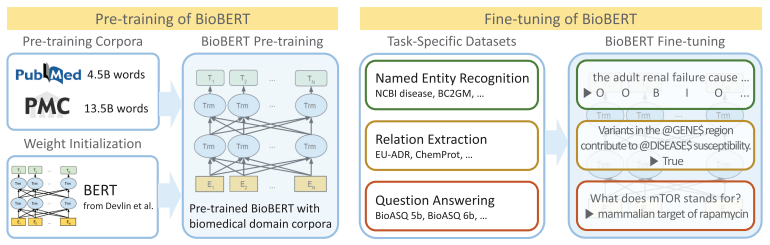
따라서 위와 같은 문제를 해결하기 위해, 본 논문은 BioBERT를 제안한다. 이름에서 드러나는 것처럼, BioBERT는 general corpus로 pre-trained된 BERT의 가중치로 초기화한다. 그 후 BioBERT는 biomedical domain corpora로 pre-trained한다. 성능을 확인하기 위해, BioBERT는 biomedical NER, RE, QA에 fine-tuning한다.
BioBERT는 general domain Corpus (English Wikipedia, BooksCorpus)와 더불어, biomedical domain corpus (PubMed Abstracts, PMC Full-text articles)로 pretraining을 진행하였다.
Results
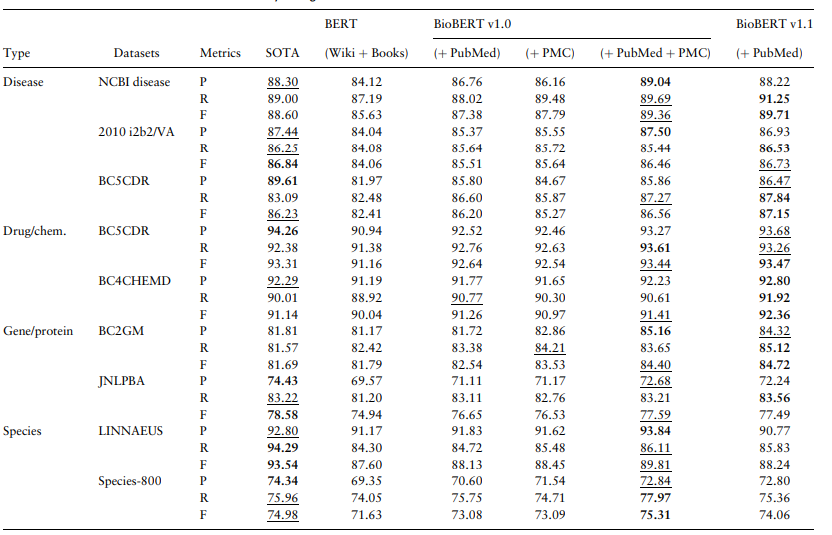
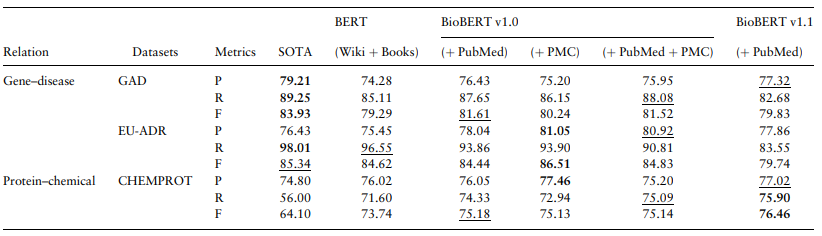
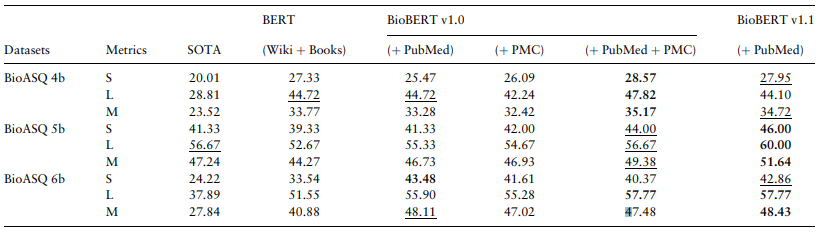
세 task 모두에서 SOTA보다 좋은 성능을 내었다.
Discussion
dataset의 크기가 1b일때 가장 효율적이었지만, 4.5b까지 늘렸을 때 성능은 더 높아졌다. pre-training step을 늘릴 수록 성능은 높아졌다. dataset을 최대로 사용했을 때 성능은 더 높아졌다.
Conclusion & Comments
biomedical corpora에 BERT를 학습한 BioBERT를 제안한다. BioBERT는 최소한의 task-specific한 구조적 수정을 필요로 하면서 다른 biomedical text mining task에서 기존 방법론을 압도하는 모습을 보였다.
특정 도메인에 LM을 적용한 초기 사례 중 하나다. 일반적인 언어 지식과는 다르게 특정 도메인에서만 사용하는 언어를 사전학습하여 그 도메인에 맞는 task를 잘 수행해 내는 것을 확인할 수 있었다. radiology report를 generating하는 task에 LM으로 BioBERT를 사용하여 더 좋은 성능을 올릴 수 있는 모델이 만들어 질 수 있지 않을까 생각이든다.
