
인덱스로 쿼리 속도 개선하기!
지난번에 겪었던 카드사 고객사의 성능 개선 삽질기를 풀어볼까 해요. 비슷한 경험 있으실 거예요... 분명 예상했던 곳이 아닌 다른 곳에서 병목이 터져버리는... 😩저도 이번에 애 좀 먹었습니다. "상담 이력 다운로드" 때문에 성능 문제가 터질 거라고 예상했는데...


브랜치 정책을 만들어가는 여정 (릴리즈)
이전 글에서는 고객사 사이트 소스에 대한 브랜치 전략을 다뤘다면, 이번에는 제품 개발에 대한 브랜치 전략을 이야기해볼까 합니다.

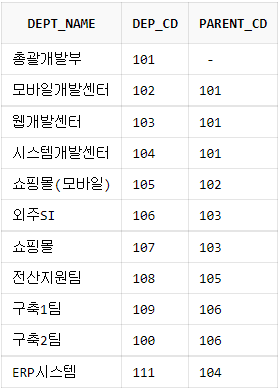
Collation - 일본어 정렬
Collation은 문자열 데이터의 정렬 순서와 비교 방법을 정의하는 규칙입니다. 일본어 데이터를 PostgreSQL에서 기본 ORDER BY로 정렬할 때, 현지에서 기대한 순서와 다르게 나오는 문제를 발견하여 이에 대해 조사한 내용을 공유하려고 합니다.





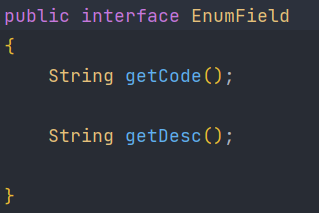
Enum과 AttributeConverter
이 글의 배경 JPA를 사용하면서 필드중 하나를 enum타입으로 사용하려고 했다. 위는 ServerType이라는 enum클래스이다. code와 desc 두 개의 필드를 가지고있고, 현재 DB의 컬럼에는 code가 저장되어 있다. 따라서 DB에 저장할 때도 code로
JPA - OSIV
spring.jpa.open-in-view: true (default)\-> 장점 : API호출이 끝나는 시점까지 커넥션을 들고있어서(영속성 컨텍스트가 살아있어서) 컨트롤러 또는 view단에서도 LAZY로딩이 가능하다. \-> 단점 : 커넥션을 계속 들고있게되면 로직이
JAVA 8 - 메소드 레퍼런스
람다가 하는일이 기존 메소드 또는 생성하는 호출하는 거라면, 메소드 레퍼런스를 사용해서 매우 간결하게 표현할 수 있음.compareToIgnoreCase는 현재 인스턴스와 파라미터로 들어오는 문자열을 대소문자 상관없이 비교하여 문자열파라미터가 작은경우 0보다 큰 값 반