모델링을 위한 데이터 선택하기
데이터셋에는 너무 많은 변수들이 있음.
이 많은 양의 데이터를 이해할 수 있을 정도의 데이터로 어떻게 압축할 수 있을까?
- 직관 이용하기
( 이후 변수의 우선순위를 자동으로 지정하는 통계 기술 이용할 것)
변수 또는 열(column)을 선택하려면, 데이터셋의 모든 열 목록을 확인해야 함.
-
DataFrame 의 columns 속성 이용하기
import pandas as pd # csv파일로 melbourne_data 라는 dataframe 만들기 melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv' melbourne_data = pd.read_csv(melbourne_file)path) # DataFrame의 columns 속성 melbourne_data.columns결과 :
Index(['Suburb', 'Address', 'Rooms', 'Type', 'Price', 'Method', 'SellerG', 'Date', 'Distance', 'Postcode', 'Bedroom2', 'Bathroom', 'Car', 'Landsize', 'BuildingArea', 'YearBuilt', 'CouncilArea', 'Lattitude', 'Longtitude', 'Regionname', 'Propertycount'], dtype='object') -
dropna(axis=)
참고로, 이 Melbourne 데이터에는 누락된 값이 있다. (일부 변수에 대한 기록이 없는 몇몇 주택들)
이 누락된 값들을 처리하는 방법은 이후 튜토리얼에 나옴
(아이오와 데이터에는 사용하는 열에 대한 누락된 값이 없음)
따라서 지금은 가장 간단한 선택지인, 데이터에서 결측치(누락된 값)에 대한 집들은 drop(제거)을 할 것임
이는 결측치를 제거하는 dropna 함수를 이용하면 된다.
이 때, dropna 의 na = "not available"
axis = 0 : 행 방향으로 제거
axis = 1 : 열 방향으로 제거
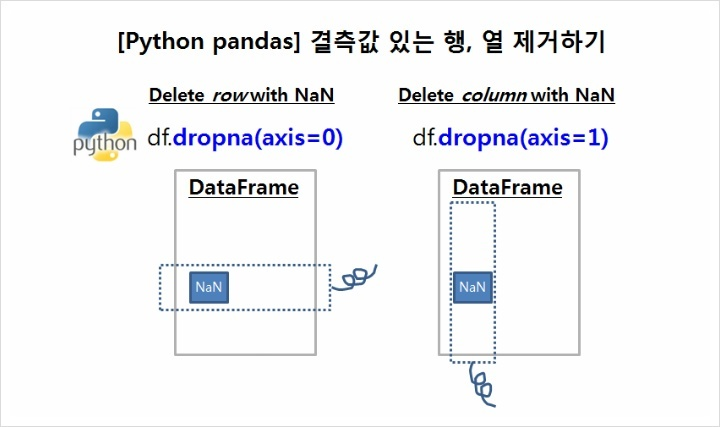
melbourne_data = melbourne_data.dropna(axis=0)
가지고 있는 데이터셋의 부분셋을 선택하는 방법은 많지만,
이번엔 두 가지 접근법에 집중해보자.
1. Dot notation : "예측 대상(Prediction target)" 선택
2. column list 선택하기 : "features" 선택
Selecting the Prediction Target
dot-notation
dot-notation을 이용하여 변수를 꺼낼 수 있다.
< Series >
DataFrame과 비슷하지만, 2차원인 DataFrame과 달리, 1차원의 단일 열만 가지고 있는 데이터는 Series 가 있다.
DataFrame의 열들은 Series로 이루어져 있다고 생각하면 되는데, 그러므로 선택하려는 column인 Series 데이터를 이용하면 된다.
dot-notation을 이용하여 예측 대상(예측하려는 열, 타겟 열, prediction target)을 선택하자.
보통 예측 대상은 y라고 함
우리는 멜버른 데이터를 통해 집값을 예측할 것이므로 집값이 타겟이 된다.
멜버른 데이터의 주택 가격(Price)을 예측 대상으로 지정하여 저장하는 코드 :
y = melbourne_data.PriceChoosing "Features"
column list 선택
features :
모델에 입력되고 예측에 사용되는 columns
앞서 예측 대상을 Price로 지정했고,
집값을 결정하는데 사용되는 열을 features로 지정하면 된다.
features는 데이터셋에 있는 모든 열이 될 수 도 있고(예측 대상 제외),
몇몇개의 열들만 features가 되는게 더 좋을 수도 있음.
이번엔 일부 열만 뽑아서 features로 만들고 모델을 구축해보자.
(나중에 다른 features로 모델 만들기를 반복하고 비교하는 방법을 살펴볼 것임)
여러 column을 features로 선택하기 위해 column 이름을 [] 내분에 넣어 리스트 형태로 데이터프레임 이름 뒤에 붙일 수 있음.
각 열의 이름은 따옴표("")를 포함한 문자열 형태여야 함("열 이름")
- features로 선택할 column list 만들기 :
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
보통 이렇게 feature로 지정된 데이터를 X 라고 함
- features list로 X 데이터 만들기
X = melbourne_data[melbourne_features]
describe()함수와 head()함수로 빠르게 X 데이터를 확인해보자.
-
describe()
X.describe()[ 결과 ]
Rooms Bathroom Landsize Lattitude Longtitude count 6196.000000 6196.000000 6196.000000 6196.000000 6196.000000 mean 2.931407 1.576340 471.006940 -37.807904 144.990201 std 0.971079 0.711362 897.449881 0.075850 0.099165 min 1.000000 1.000000 0.000000 -38.164920 144.542370 25% 2.000000 1.000000 152.000000 -37.855438 144.926198 50% 3.000000 1.000000 373.000000 -37.802250 144.995800 75% 4.000000 2.000000 628.000000 -37.758200 145.052700 max 8.000000 8.000000 37000.000000 -37.457090 145.526350 -
head()
X.head()[결과]
Rooms Bathroom Landsize Lattitude Longtitude 1 2 1.0 156.0 -37.8079 144.9934 2 3 2.0 134.0 -37.8093 144.9944 4 4 1.0 120.0 -37.8072 144.9941 6 3 2.0 245.0 -37.8024 144.9993 7 2 1.0 256.0 -37.8060 144.9954
Butilding Your Model
scikit-learn 라이브러리로 모델을 만들자
(코드 상으로는 sklearn)
Scikit-learn
DataFrame에 저장된 데이터로 모델링하는 가장 유명한 라이브러리
모델 구축(모델링) 과정 :
- Define : 어떤 모델을 사용할지 결정 (ex. Decision Tree, Random Forest, 등등). 모델에 따라 파라미터도 지정된다
- Fit : 모델링의 핵심. 데이터에서 패턴을 파악한다.
- Predict : 모델 예측
- Evaluate : 모델의 예측이 얼마나 정확한지 평가
scikit-learn으로 Decision Tree로 모델을 결정하고, features와 target 변수로 fitting해보자.
from sklearn.tree import DecisionTreeRegressor
# 모델 지정(정의)하기
# random_state에 번호를 지정하여 모든 실행이 같은 결과를 내도록 한다.
melbourne_model = DecisionTreeRegressor(random_state=1)
# Fit model
melbourne_model.fit(X, y)[결과]
DecisionTreeRegressor(random_state=1)✓ 참고
- random_state = 1
많은 머신러닝 모델들은 모델의 학습에 randomness(임의성)을 허용한다.
random_state에 숫자를 지정하면 각 실행마다 같은 결과를 낼 수 있다.
지정하는 숫자가 뭐든 상관없이 같은 기능을 하니까 아무 숫자나 넣자!
이제, 예측에 사용할 수 있는 적합한 모델(fitted model)이 생겼다.
이미 가격을 알고 있는 주택보다는 시장에 나오는 새 주택에 대한, 말 그대로 미래를 "예측" 하고 싶겠지만,
예측 함수가 어떻게 작동하는지 확인하기 위해 training 데이터의 처음 몇 행에 대한 예측을 해볼 것이다.
print("다음 5개의 집값에 대한 예측을 하자:")
print(X.head())
print("========================") # 구분선 넣기
print("예측값:")
print(melbourne_model.predict(X.head()))[결과]
다음 5개의 집값에 대한 예측을 하자:
Rooms Bathroom Landsize Lattitude Longtitude
1 2 1.0 156.0 -37.8079 144.9934
2 3 2.0 134.0 -37.8093 144.9944
4 4 1.0 120.0 -37.8072 144.9941
6 3 2.0 245.0 -37.8024 144.9993
7 2 1.0 256.0 -37.8060 144.9954
========================
예측값:
[1035000. 1465000. 1600000. 1876000. 1636000.]아래 주소로 IOWA 데이터로 실습을 진행하며 확인해볼 수 있다
