Pandas 로 Data와 친해지기
모든 머신러닝 프로젝트의 가장 첫 단계는 data와 친해지는 단계이다.
우리는 Pandas library로 데이터와 친해져보자.
Pandas : 데이터 사이언티스트가 데이터를 탐색하고 조작하는데 사용하는 기본 도구
코드상에서 대부분은 다음과 같은 명령어로 pandas를 pd로 축약해서 사용한다.
import pandas as pdPandas library의 가장 중요한 부분은 DataFrame이다.
DataFrame : 우리가 표(table)로 표현할 수 있는 데이터의 유형을 나타냄
(마치 Excel의 스프레드 시트나 SQL 데이터베이스의 table과 유사함)
예를 들어, 호주 멜버른의 주택 가격에 대한 데이터를 살펴보자.
(실습에서는 아이오와의 주택 가격이 있는 새 dataset에 같은 방법을 적용)
예제 데이터(멜버른)의 파일 경로 : ../input/melbourne-housing-snapshot/melb_data.csv
다음 명령어로 이 데이터를 불러오고 살펴보자.
-
파일 경로(주소)가 복잡하므로, 접근이 더 쉽도록 새로운 변수로 지정해서 저장
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv' -
데이터를 읽어오고 DataFrame에 melbourne_data라는 이름으로 저장
melbourne_data = pd.read_csv(melbourne_file_path) -
Melbourne 데이터의 요약 살펴보기 :
describe()melbourne_data.describe()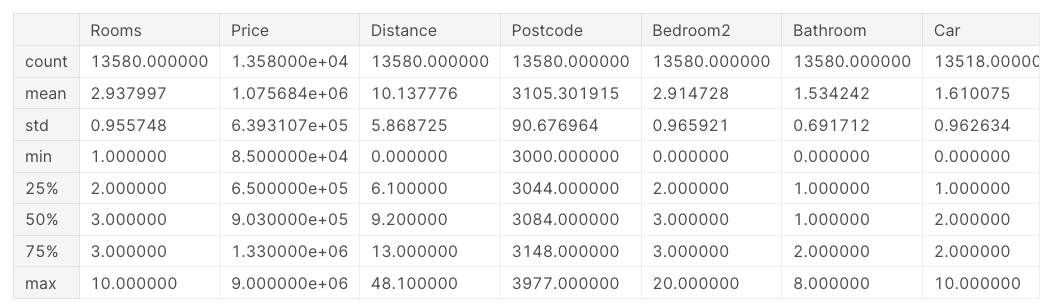
Data 해석하기
결과에는 원본 dataset의 각 열에 대해 8개의 숫자가 표시된다.
-
count(개수) : 누락되지 않은 값이 있는 행의 수
* 결측값은 여러 가지 이유로 발생함 :
EX) 침실 1개가 있는 집을 조사할 때 침실 2개의 크기는 수집되지 않음. -
mean : 평균
-
std : 표준 편차. 값이 얼마나 수치적으로 퍼져(분산돼) 있는지
-
min, 25%, 50%, 75%, max : 설명 생략
실습
데이터 파일을 읽고, 데이터에 대한 통계를 이해하는 능력을 시험해볼 수 있다.
뒤의 실습에서는 데이터를 필터링하고, 기계학습 모델을 구축하고, 모델을 반복적으로 개선한다.
course 예제로는 Melbourne의 데이터를 이용했다.
스스로 확실히 연습하기 위해 다른 데이터셋(Iowa의 주택 가격 포함)으로도 연습해야 함!
Google의 colab과 같은 Notebook 환경을 사용하는데, 이에 익숙하지 않은 사람을 위해 90초짜리 소개 영상도 준비해주는 친절한 캐글..
실습환경 확인 (set up code-checking)
실습 환경이 잘 되는지 확인하기 위한 코드 :
# Set up code checking
from learntools.core import binder
binder.bind(globals())
from learntools.machine_learning.ex2 import *
print("Setup Complete")Step1. Loading data(데이터 불러오기)
아이오와 데이터 파일을 home_data라는 이름의 Pandas Dataframe으로 불러오자.
import pandas as pd
# 파일 읽을 경로
iowa_file_path = '../input/home-data-for-ml-course/train.csv'
home_data = pd.read_csv(iowa_file_path)
Step2. Review the data(데이터 확인하기)
home_data.describe()
Think About Your Data
우리가 살펴본 데이터의 최신 집은 그리 최신 자료가 아님. 왜일까? 다음 두 가지 가정을 해볼 수 있음.
-
이 데이터가 수집된 곳에 새로 집을 짓지 않았음
-
이 데이터는 아주 옛날에 수집된 데이터임. 데이터 수집 이후에 지어진 집들의 데이터는 나타나있지 않음.
위의 가정들이 사실이라면 구축한 모델의 신뢰성에 어떤 영향을 미칠까?
어떤 설명이 더 진실에 가까운지(그럴듯한지) 확인하기 위해 데이터를 어떻게 분석할 수 있을까?
이에 대한 다른 사람들의 아이디어를 보거나 내 생각을 올리고 싶으면 캐글의 Discussion Thread를 확인해보면 된다.
